VOID: Defeating Unauthorized Mimicry in Latent Diffusion Models
Pith reviewed 2026-06-27 10:12 UTC · model grok-4.3
The pith
VOID defeats unauthorized mimicry in latent diffusion models by creating persistent semantic corruption via pipeline perturbations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VOID is a defense framework that overcomes the restoration mechanism in LDMs by manipulating intrinsic stochasticity: it amplifies latent encoding errors to shatter an image's semantic structure and counteracts target guidance signals to suppress the model's restoration capabilities, producing semantic corruption that thwarts unauthorized mimicry while confining perturbations to human-imperceptible regions.
What carries the argument
Amplification of latent encoding errors combined with counteraction of target guidance signals in the diffusion pipeline.
If this is right
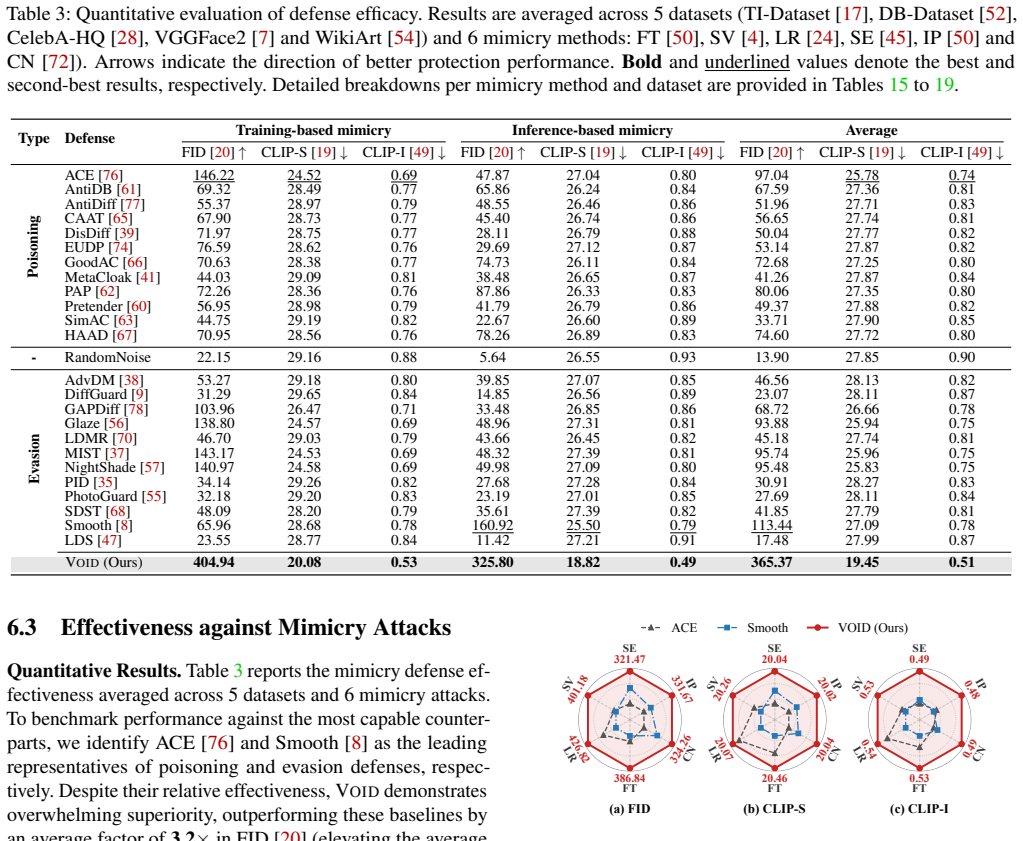
- Increases average FID from 113 to 365 against mimicry attacks.
- Achieves a 223% improvement over the strongest prior defense.
- Maintains effectiveness across 10 mimicry attacks on 5 datasets.
- Preserves visual utility of protected images by keeping changes imperceptible.
Where Pith is reading between the lines
- The same pipeline manipulation approach could be tested on non-latent diffusion generative models.
- Attack methods might evolve to specifically restore or bypass these two forms of perturbation.
- The balance between error amplification and guidance counteraction could be tuned automatically per image.
Load-bearing premise
That amplifying latent encoding errors and counteracting guidance signals will produce semantic corruption that survives the full diffusion process without being restored by the model's mechanisms.
What would settle it
A test showing whether images generated from VOID-protected inputs still closely match the original individual's identity under visual metrics such as FID or human judgment.
Figures












read the original abstract
While Latent Diffusion Models (LDMs) have revolutionized visual synthesis, they are increasingly exploited for unauthorized mimicry of individuals. Existing defenses inject deceptive perturbations to steer the generated images toward irrelevant targets. However, this approach hinges on an ungrounded assumption: subtle perturbations can maintain their deceptive efficacy throughout an LDM's extensive generation process. In reality, the model's innate restoration mechanism will remove such perturbations and cause individual identities to re-emerge in the images generated. We propose VOID, a defense framework that overcomes this conundrum by manipulating an LDM's intrinsic stochasticity. VOID perturbs the diffusion pipeline in two novel ways: 1) amplifying the latent encoding errors to shatter an image's semantic structure, and 2) counteracting the target guidance signals to suppress the model's restoration capabilities. This results in a semantic corruption that thwarts any unauthorized mimicry. Notably, the security gain does not come at the price of visual utility, as VOID simultaneously manages to confine perturbations to human-imperceptible regions of protected images. Our comprehensive evaluation of 24 state-of-the-art defenses against 10 mimicry attacks on 5 datasets demonstrates VOID's unprecedented protection power: it increases the average Frechet Inception Distance (FID) from 113 to 365, a 223% improvement over the strongest defense to date.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VOID, a defense framework against unauthorized mimicry attacks on Latent Diffusion Models. It identifies the failure mode of prior defenses as the LDM's restoration mechanism removing injected perturbations during denoising, and introduces two manipulations of the diffusion pipeline—amplifying latent encoding errors to shatter semantic structure and counteracting target guidance signals to suppress restoration—to induce persistent semantic corruption. The work claims this yields a large empirical gain while confining perturbations to imperceptible regions, with evaluation across 24 prior defenses, 10 attacks, and 5 datasets showing average FID rising from 113 to 365 (223% improvement over the strongest baseline).
Significance. If the reported FID gains are supported by reproducible experimental protocols, statistical controls, and evidence that the induced corruption persists through the full denoising trajectory, the result would constitute a notable advance in protecting against identity mimicry in LDMs. The approach of targeting intrinsic stochasticity rather than direct image-space perturbations is conceptually distinct from prior work. The breadth of the claimed evaluation (multiple defenses, attacks, and datasets) is a strength if the comparison methodology is sound.
major comments (2)
- [Abstract] Abstract: the central empirical claim (FID increase from 113 to 365, 223% improvement) is presented without any description of experimental setup, dataset/attack selection criteria, statistical significance testing, or controls for the comparison against 24 prior defenses, rendering the superiority assertion unevaluated.
- [Abstract] Abstract: the load-bearing assumption that amplifying latent encoding errors combined with counteracting guidance signals produces semantic corruption that survives the full diffusion process (rather than being restored by the model's denoising mechanisms) is asserted without any intermediate analysis, timestep-wise corruption metrics, or ablation showing persistence across the generation trajectory.
minor comments (1)
- The abstract refers to 'human-imperceptible' perturbations and 'comprehensive evaluation' but supplies no details on the imperceptibility metric or additional quantitative results beyond average FID.
Simulated Author's Rebuttal
We thank the referee for highlighting issues in the abstract presentation. We agree the abstract can better contextualize the claims and will revise it to reference the experimental details and persistence analysis from the main text.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (FID increase from 113 to 365, 223% improvement) is presented without any description of experimental setup, dataset/attack selection criteria, statistical significance testing, or controls for the comparison against 24 prior defenses, rendering the superiority assertion unevaluated.
Authors: We acknowledge the abstract's brevity omits setup details. The full manuscript (Sections 4-5) specifies the 5 datasets, 10 attacks, 24 defenses, multiple random seeds for statistical significance, and controls. We will revise the abstract to concisely note the evaluation scope and direct readers to the paper for protocols and controls. revision: yes
-
Referee: [Abstract] Abstract: the load-bearing assumption that amplifying latent encoding errors combined with counteracting guidance signals produces semantic corruption that survives the full diffusion process (rather than being restored by the model's denoising mechanisms) is asserted without any intermediate analysis, timestep-wise corruption metrics, or ablation showing persistence across the generation trajectory.
Authors: The main text (Section 3.2, Figure 3, and ablations in Section 5) provides timestep-wise corruption metrics and persistence analysis across the denoising trajectory. The abstract summarizes the outcome of this analysis. We will add a brief reference to the persistence results in the revised abstract. revision: partial
Circularity Check
No circularity: empirical defense evaluation stands on external benchmarks
full rationale
The paper proposes VOID as a defense that perturbs LDM stochasticity via latent error amplification and guidance counteraction, then reports empirical FID gains (113 to 365) against 10 attacks on 5 datasets. No equations, fitted parameters, or self-citations are invoked to derive the security claim; the result is measured by direct comparison to prior defenses and is not reduced to a definition or input by construction. The central assumption about persistent corruption is an empirical hypothesis tested via external metrics rather than a self-referential derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LDMs possess an innate restoration mechanism that removes subtle perturbations during generation
Reference graph
Works this paper leans on
-
[1]
Stable diffusion version 2.1
Stability AI. Stable diffusion version 2.1. https://huggingface.co/stabilityai/ stable-diffusion-2-1, 2022
2022
-
[2]
Stable diffusion xl base 0.9
Stability AI. Stable diffusion xl base 0.9. https://huggingface.co/stabilityai/ stable-diffusion-xl-base-0.9, 2023
2023
-
[3]
Stable diffusion 3 medium
Stability AI. Stable diffusion 3 medium. https://huggingface.co/stabilityai/ stable-diffusion-3-medium, 2024
2024
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Deep neural networks for no-reference and full-reference im- age quality assessment.IEEE Transactions on image processing, 27(1):206–219, 2017
Sebastian Bosse, Dominique Maniry, Klaus-Robert Müller, Thomas Wiegand, and Wojciech Samek. Deep neural networks for no-reference and full-reference im- age quality assessment.IEEE Transactions on image processing, 27(1):206–219, 2017
2017
-
[6]
Impress: Evaluating the re- silience of imperceptible perturbations against unau- thorized data usage in diffusion-based generative ai
Bochuan Cao, Changjiang Li, Ting Wang, Jinyuan Jia, Bo Li, and Jinghui Chen. Impress: Evaluating the re- silience of imperceptible perturbations against unau- thorized data usage in diffusion-based generative ai. Advances in Neural Information Processing Systems, 36:10657–10677, 2023
2023
-
[7]
Vggface2: A dataset for recog- nising faces across pose and age
Qiong Cao, Li Shen, Weidi Xie, Omkar M Parkhi, and Andrew Zisserman. Vggface2: A dataset for recog- nising faces across pose and age. In2018 13th IEEE international conference on automatic face & gesture recognition (FG 2018), pages 67–74. IEEE, 2018
2018
-
[8]
Junxi Chen, Junhao Dong, and Xiaohua Xie. Explor- ing adversarial attacks against latent diffusion model from the perspective of adversarial transferability.arXiv preprint arXiv:2401.07087, 2024
-
[9]
June Suk Choi, Kyungmin Lee, Jongheon Jeong, Saining Xie, Jinwoo Shin, and Kimin Lee. Diffusionguard: A robust defense against malicious diffusion-based image editing.arXiv preprint arXiv:2410.05694, 2024
-
[10]
Stable diffusion repository
CompVis. Stable diffusion repository. https:// github.com/CompVis/stable-diffusion, 2022
2022
-
[11]
Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord. Diffedit: Diffusion-based seman- tic image editing with mask guidance.arXiv preprint arXiv:2210.11427, 2022
-
[12]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
Francesco Croce and Matthias Hein. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. InProceedings of the 37th Inter- national Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 ofProceed- ings of Machine Learning Research, pages 2206–2216. PMLR, 2020
2020
-
[13]
Stable dif- fusion x2 latent upscaler
Katherine Crowson and Stability AI. Stable dif- fusion x2 latent upscaler. https://huggingface. co/stabilityai/sd-x2-latent-upscaler , 2023. Model accessed on Hugging Face
2023
-
[14]
Keeping the Bad Guys Out: Protecting and Vaccinating Deep Learning with JPEG Compression
Nilaksh Das, Madhuri Shanbhogue, Shang-Tse Chen, Fred Hohman, Li Chen, Michael E Kounavis, and Duen Horng Chau. Keeping the bad guys out: Protecting and vaccinating deep learning with jpeg compression. arXiv preprint arXiv:1705.02900, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Image quality assessment: Unifying structure and texture similarity.IEEE transactions on pattern analysis and machine intelligence, 44(5):2567–2581, 2020
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P Simon- celli. Image quality assessment: Unifying structure and texture similarity.IEEE transactions on pattern analysis and machine intelligence, 44(5):2567–2581, 2020
2020
-
[16]
The hugging face diffu- sion course - unit 4: Exploring the training script
Hugging Face. The hugging face diffu- sion course - unit 4: Exploring the training script. https://huggingface.co/learn/ diffusion-course/en/unit4/2, 2023. Accessed: 2025-10-21
2023
-
[17]
An image is worth one word: Personalizing text-to- image generation using textual inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to- image generation using textual inversion. InInterna- tional Conference on Learning Representations, 2022
2022
-
[18]
Image style transfer using convolutional neural net- works
Leon A Gatys, Alexander S Ecker, and Matthias Bethge. Image style transfer using convolutional neural net- works. InProceedings of the IEEE conference on com- puter vision and pattern recognition, pages 2414–2423, 2016
2016
-
[19]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free eval- uation metric for image captioning.arXiv preprint arXiv:2104.08718, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[21]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Robert Hönig, Javier Rando, Nicholas Carlini, and Flo- rian Tramèr. Adversarial perturbations cannot reli- ably protect artists from generative ai.arXiv preprint arXiv:2406.12027, 2024
-
[23]
Parameter- efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Ges- mundo, Mona Attariyan, and Sylvain Gelly. Parameter- efficient transfer learning for nlp. InInternational con- ference on machine learning, pages 2790–2799. PMLR, 2019
2019
-
[24]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Rep- resentations, 2021
2021
-
[25]
Chihan Huang, Belal Alsinglawi, and Islam Al-Qudah. DBLP: noise bridge consistency distillation for ef- ficient and reliable adversarial purification.CoRR, abs/2508.00552, 2025
-
[26]
Scope of validity of psnr in image/video quality assessment
Quan Huynh-Thu and Mohammed Ghanbari. Scope of validity of psnr in image/video quality assessment. Electronics letters, 44(13):800–801, 2008
2008
-
[27]
Toward top-down just noticeable difference estimation of natural images.IEEE Transactions on Image Processing, 31:3697–3712, 2022
Qiuping Jiang, Zhentao Liu, Shiqi Wang, Feng Shao, and Weisi Lin. Toward top-down just noticeable difference estimation of natural images.IEEE Transactions on Image Processing, 31:3697–3712, 2022
2022
-
[28]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for im- proved quality, stability, and variation.arXiv preprint arXiv:1710.10196, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[30]
Theodoros Kouzelis, Ioannis Kakogeorgiou, Spyros Gi- daris, and Nikos Komodakis. Eq-vae: Equivariance regularized latent space for improved generative image modeling.arXiv preprint arXiv:2502.09509, 2025
-
[31]
Flux.1-dev
Black Forest Labs. Flux.1-dev. https: //huggingface.co/black-forest-labs/FLUX. 1-dev, 2024
2024
-
[32]
FLUX.2: Frontier Visual Intelli- gence.https://bfl.ai/blog/flux-2, 2025
Black Forest Labs. FLUX.2: Frontier Visual Intelli- gence.https://bfl.ai/blog/flux-2, 2025
2025
-
[33]
Flux.1 kontext: Flow matching for in-context image generation and editing in latent space, 2025
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Do- minik Lorenz, Jonas Müller, Dustin Podell, Robin Rom- bach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context im...
2025
-
[34]
Instant adversarial purifica- tion with adversarial consistency distillation
Chun Tong Lei, Hon Ming Yam, Zhongliang Guo, Yifei Qian, and Chun Pong Lau. Instant adversarial purifica- tion with adversarial consistency distillation. InProceed- ings of the Computer Vision and Pattern Recognition Conference, pages 24331–24340, 2025
2025
-
[35]
Ang Li, Yichuan Mo, Mingjie Li, and Yisen Wang. Pid: Prompt-independent data protection against latent diffu- sion models.arXiv preprint arXiv:2406.15305, 2024
-
[36]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning, pages 12888–12900. PMLR, 2022
2022
-
[37]
Chumeng Liang and Xiaoyu Wu. Mist: Towards im- proved adversarial examples for diffusion models.arXiv preprint arXiv:2305.12683, 2023
-
[38]
Chumeng Liang, Xiaoyu Wu, Yang Hua, Jiaru Zhang, Yiming Xue, Tao Song, Zhengui Xue, Ruhui Ma, and Haibing Guan. Adversarial example does good: Pre- venting painting imitation from diffusion models via adversarial examples.arXiv preprint arXiv:2302.04578, 2023
-
[39]
Disrupting diffusion: Token-level attention erasure attack against diffusion-based customization
Yisu Liu, Jinyang An, Wanqian Zhang, Dayan Wu, Jingzi Gu, Zheng Lin, and Weiping Wang. Disrupting diffusion: Token-level attention erasure attack against diffusion-based customization. InProceedings of the 32nd ACM International Conference on Multimedia, pages 3587–3596, 2024
2024
-
[40]
Rethinking and Red-Teaming Protective Perturbation in Personalized Diffusion Models
Yixin Liu, Ruoxi Chen, Xun Chen, and Lichao Sun. Rethinking and defending protective perturbation in personalized diffusion models.arXiv preprint arXiv:2406.18944, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Metacloak: Preventing unau- thorized subject-driven text-to-image diffusion-based synthesis via meta-learning
Yixin Liu, Chenrui Fan, Yutong Dai, Xun Chen, Pan Zhou, and Lichao Sun. Metacloak: Preventing unau- thorized subject-driven text-to-image diffusion-based synthesis via meta-learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24219–24228, 2024
2024
-
[42]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference.arXiv preprint arXiv:2310.04378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Dreamshaper
Lykon. Dreamshaper. https://huggingface.co/ Lykon/DreamShaper, 2023. Accessed: 2024-05-20
2023
-
[44]
Towards Deep Learning Models Resistant to Adversarial Attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic dif- ferential equations.arXiv preprint arXiv:2108.01073, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[46]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fer- nandez, Daniel Haziza, Francisco Massa, Alaaeldin El- Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Latent diffusion shield- mitigating malicious use of diffusion models through latent space adversarial perturbations
Huy Phan, Boshi Huang, Ayush Jaiswal, Ekraam Sabir, Prateek Singhal, and Bo Yuan. Latent diffusion shield- mitigating malicious use of diffusion models through latent space adversarial perturbations. InProceedings of the Winter Conference on Applications of Computer Vision, pages 1440–1448, 2025
2025
-
[48]
Pieapp: Perceptual image-error assess- ment through pairwise preference
Ekta Prashnani, Hong Cai, Yasamin Mostofi, and Pradeep Sen. Pieapp: Perceptual image-error assess- ment through pairwise preference. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1808–1817, 2018
2018
-
[49]
Learning transferable visual models from natural lan- guage supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sas- try, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural lan- guage supervision. InInternational conference on ma- chine learning, pages 8748–8763. PmLR, 2021
2021
-
[50]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[51]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
2015
-
[52]
Dreambooth: Fine-tuning text-to-image diffusion models for subject- driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine-tuning text-to-image diffusion models for subject- driven generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2023
2023
-
[53]
Stable diffusion v1.5
RunwayML. Stable diffusion v1.5. https://huggingface.co/runwayml/ stable-diffusion-v1-5, 2024
2024
-
[54]
Large-scale Classification of Fine-Art Paintings: Learning The Right Metric on The Right Feature
Babak Saleh and Ahmed Elgammal. Large-scale classi- fication of fine-art paintings: Learning the right metric on the right feature.arXiv preprint arXiv:1505.00855, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[55]
Raising the cost of malicious ai-powered image editing.arXiv preprint arXiv:2302.06588, 2023
Hadi Salman, Alaa Khaddaj, Guillaume Leclerc, An- drew Ilyas, and Aleksander Madry. Raising the cost of malicious ai-powered image editing.arXiv preprint arXiv:2302.06588, 2023
-
[56]
Glaze: Protecting artists from style mimicry by {Text-to-Image} models
Shawn Shan, Jenna Cryan, Emily Wenger, Haitao Zheng, Rana Hanocka, and Ben Y Zhao. Glaze: Protecting artists from style mimicry by {Text-to-Image} models. In32nd USENIX Security Symposium (USENIX Security 23), pages 2187–2204, 2023
2023
-
[57]
Nightshade: Prompt-specific poisoning attacks on text-to-image gen- erative models
Shawn Shan, Wenxin Ding, Josephine Passananti, Stan- ley Wu, Haitao Zheng, and Ben Y Zhao. Nightshade: Prompt-specific poisoning attacks on text-to-image gen- erative models. In2024 IEEE Symposium on Security and Privacy (SP), pages 807–825. IEEE, 2024
2024
-
[58]
Image informa- tion and visual quality.IEEE Transactions on image processing, 15(2):430–444, 2006
Hamid R Sheikh and Alan C Bovik. Image informa- tion and visual quality.IEEE Transactions on image processing, 15(2):430–444, 2006
2006
-
[59]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. De- noising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[60]
Pretender: Universal active defense against diffusion finetuning attacks
Zekun Sun, Zijian Liu, Shouling Ji, Chenhao Lin, and Na Ruan. Pretender: Universal active defense against diffusion finetuning attacks. InThe 34th USENIX Secu- rity Symposium, 2025
2025
-
[61]
Anti-dreambooth: Protecting users from personalized text-to-image synthe- sis
Thanh Van Le, Hao Phung, Thuan Hoang Nguyen, Quan Dao, Ngoc N Tran, and Anh Tran. Anti-dreambooth: Protecting users from personalized text-to-image synthe- sis. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 2116–2127, 2023
2023
-
[62]
Prompt-agnostic adversarial perturbation for customized diffusion models.Advances in Neural Information Pro- cessing Systems, 37:136576–136619, 2024
Cong Wan, Yuhang He, Xiang Song, and Yihong Gong. Prompt-agnostic adversarial perturbation for customized diffusion models.Advances in Neural Information Pro- cessing Systems, 37:136576–136619, 2024
2024
-
[63]
Simac: A simple anti-customization method for protecting face privacy against text-to-image synthesis of diffusion models
Feifei Wang, Zhentao Tan, Tianyi Wei, Yue Wu, and Qidong Huang. Simac: A simple anti-customization method for protecting face privacy against text-to-image synthesis of diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12047–12056, 2024
2024
-
[64]
Image quality assessment: from error vis- ibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error vis- ibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
2004
-
[65]
Perturbing attention gives you more bang for the buck: Subtle imaging pertur- bations that efficiently fool customized diffusion mod- els
Jingyao Xu, Yuetong Lu, Yandong Li, Siyang Lu, Dong- dong Wang, and Xiang Wei. Perturbing attention gives you more bang for the buck: Subtle imaging pertur- bations that efficiently fool customized diffusion mod- els. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24534– 24543, 2024
2024
-
[66]
Harnessing global- local collaborative adversarial perturbation for anti- customization
Long Xu, Jiakai Wang, Haojie Hao, Haotong Qin, Jiejie Zhao, and Xianglong Liu. Harnessing global- local collaborative adversarial perturbation for anti- customization. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 13414– 13423, 2025
2025
-
[67]
An h-space based adversarial attack for protection against few-shot personalization
Xide Xu, Sandesh Kamath, Muhammad Atif Butt, and Bogdan Raducanu. An h-space based adversarial attack for protection against few-shot personalization. InPro- ceedings of the 33rd ACM International Conference on Multimedia, pages 4904–4913, 2025
2025
-
[68]
Toward effective protection against diffusion based mimicry through score distillation, 2024
Haotian Xue, Chumeng Liang, Xiaoyu Wu, and Yongxin Chen. Toward effective protection against diffusion based mimicry through score distillation, 2024
2024
-
[69]
Gradient magnitude similarity deviation: A highly efficient perceptual image quality index.IEEE transactions on image processing, 23(2):684–695, 2013
Wufeng Xue, Lei Zhang, Xuanqin Mou, and Alan C Bovik. Gradient magnitude similarity deviation: A highly efficient perceptual image quality index.IEEE transactions on image processing, 23(2):684–695, 2013
2013
-
[70]
On the ro- bustness of latent diffusion models.arXiv preprint arXiv:2306.08257, 2023
Jianping Zhang, Zhuoer Xu, Shiwen Cui, Changhua Meng, Weibin Wu, and Michael R Lyu. On the ro- bustness of latent diffusion models.arXiv preprint arXiv:2306.08257, 2023
-
[71]
Fsim: A feature similarity index for image quality as- sessment.IEEE transactions on Image Processing, 20(8):2378–2386, 2011
Lin Zhang, Lei Zhang, Xuanqin Mou, and David Zhang. Fsim: A feature similarity index for image quality as- sessment.IEEE transactions on Image Processing, 20(8):2378–2386, 2011
2011
-
[72]
Adding con- ditional control to text-to-image diffusion models
Lvmin Zhang and Maneesh Agrawala. Adding con- ditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023
2023
-
[73]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[74]
Zhengyue Zhao, Jinhao Duan, Xing Hu, Kaidi Xu, Chenan Wang, Rui Zhang, Zidong Du, Qi Guo, and Yunji Chen. Unlearnable examples for diffusion mod- els: Protect data from unauthorized exploitation.arXiv preprint arXiv:2306.01902, 2023
-
[75]
Zhengyue Zhao, Jinhao Duan, Kaidi Xu, Chenan Wang, Rui Zhang, Zidong Du, Qi Guo, and Xing Hu. Can protective perturbation safeguard personal data from being exploited by stable diffusion? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24398–24407, 2024
2024
-
[76]
Boyang Zheng, Chumeng Liang, and Xiaoyu Wu. Targeted attack improves protection against unau- thorized diffusion customization.arXiv preprint arXiv:2310.04687, 2023
-
[77]
Anti-diffusion: Prevent- ing abuse of modifications of diffusion-based models
Li Zheng, Liangbin Xie, Jiantao Zhou, Xintao Wang, Haiwei Wu, and Jinyu Tian. Anti-diffusion: Prevent- ing abuse of modifications of diffusion-based models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 10582–10590, 2025
2025
-
[78]
Haotian Zhu, Shuchao Pang, Zhigang Lu, Yongbin Zhou, and Minhui Xue. Gap-diff: protecting jpeg-compressed images from diffusion-based facial customization. In NDSS, 2025. A Latent Diffusion Models Latent Diffusion Models (LDMs) [31, 50] have become the de facto standard for high-fidelity image synthesis. Struc- turally, LDMs decouple the generative proces...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.