Towards a Dynamic and Fixed-budget Memory Bank for Efficient Streaming Video Understanding
Pith reviewed 2026-06-25 20:53 UTC · model grok-4.3
The pith
CausalMem maintains a dynamic fixed-budget memory bank for streaming videos by estimating token redundancy through an online semantic basis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
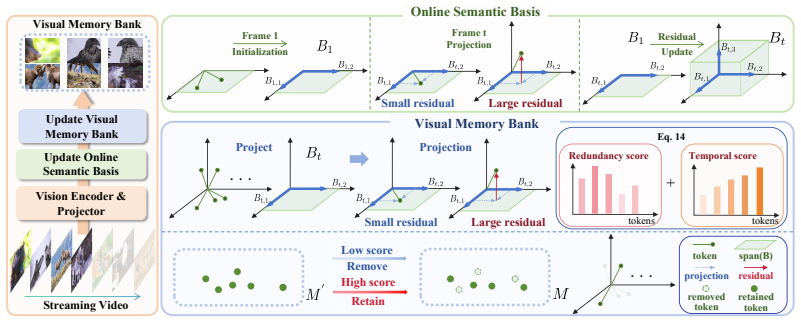
CausalMem constructs a dynamic visual memory update mechanism that estimates the redundancy of visual tokens and updates the memory bank via an online semantic basis modeling the principal semantics of the observed video stream, thereby maximizing retained information within a limited memory space for streaming video understanding.
What carries the argument
The online semantic basis that models principal semantics of the video stream to estimate and prune redundant visual tokens during memory bank updates.
If this is right
- Application to LLaVA-OneVision and Qwen2.5-VL produces +3.2 percent average accuracy gain on streaming benchmarks.
- The same application produces +3.0 percent average accuracy gain on offline benchmarks.
- Hour-long streaming videos are stored using a 12k token budget with more than 20 times visual token compression.
- Storage for such videos occupies about 82 MB.
Where Pith is reading between the lines
- The fixed-budget approach could extend to real-time processing on edge devices where memory is strictly limited.
- Similar redundancy estimation might apply to long audio or text sequences in other multimodal models.
- The method leaves open whether learned rather than training-free basis updates could further improve retention.
Load-bearing premise
Estimating visual token redundancy and updating the memory bank via an online semantic basis will maximize the information retained within the fixed budget.
What would settle it
If replacing the online semantic basis update with uniform or random token selection on the same benchmarks yields equal or higher accuracy and compression ratios.
Figures



read the original abstract
Currently, streaming video understanding is still a daunting task for existing \emph{multimodal large language models} (MLLMs). Its difficulties not only lie in handling the ever-increasing video frames, but also in the unpredictability of future video content and input instructions. In this paper, we study this task from the perspective of constructing a dynamic but fixed-budget memory bank, and propose a novel and training-free approach termed \emph{\textbf{CausalMem}}. CausalMem is dedicated to constructing a dynamic visual memory update mechanism, thereby maximizing the amount of information in streaming video within a limited memory space, much like the human brain. In practice, CausalMem estimates the redundancy of visual tokens and updates the memory bank via an online semantic basis, which models the principal semantics of the observed video stream. To validate CausalMem, we apply it to two representative MLLMs, namely LLaVA-OneVision and Qwen2.5-VL respectively, and conduct extensive experiments on both streaming and offline video understanding benchmarks. The experimental results not only show the great advantages than existing methods under both streaming and offline settings, \emph{e.g.}, $+3.2\%$ and $+3.0\%$ average accuracy gains respectively, but also witness the superior semantic preservation for streaming videos, \emph{e.g.}, using 12$k$ token budgets to memorize hour-long streaming videos, which achieves more than \textbf{20$\times$} visual token compression ratio and only occupies about \textbf{82 MB} storage. \textbf{Our code} is given in \href{https://github.com/hktk07/CausalMem}{CausalMem}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
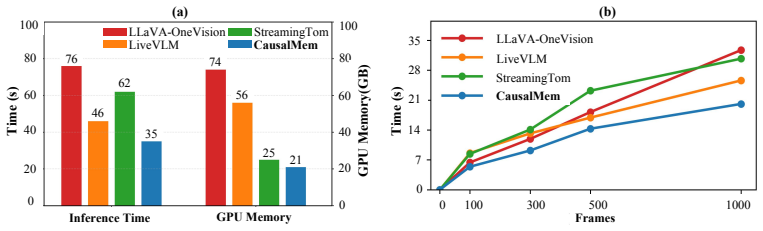
Summary. The paper proposes CausalMem, a training-free method for constructing a dynamic fixed-budget memory bank for streaming video understanding in MLLMs. It estimates redundancy among visual tokens and maintains an online semantic basis that models the principal semantics of the observed stream to decide updates and evictions. When applied to LLaVA-OneVision and Qwen2.5-VL, the method is reported to deliver +3.2% and +3.0% average accuracy gains on streaming and offline benchmarks respectively, while achieving >20× visual-token compression (12k-token budget for hour-long videos, ~82 MB storage).
Significance. If the central mechanism demonstrably retains more task-relevant information than simpler fixed-budget policies, the approach could meaningfully advance efficient long-video processing in MLLMs without retraining. The training-free design and public code release are concrete strengths that support reproducibility and adoption.
major comments (2)
- [Method] Method section: the claim that the online semantic basis update 'maximizes the amount of information' retained under a fixed budget is load-bearing for the compression and accuracy results, yet the manuscript provides neither an information-theoretic bound, reconstruction guarantee, nor ablation that isolates the basis construction from generic redundancy estimation or simpler eviction policies.
- [Experiments] Experiments section: the reported +3.2% and +3.0% average accuracy gains are presented without baseline tables, standard deviations, number of runs, or controls that rule out prompt-formatting or MLLM-integration effects; this prevents attribution of gains specifically to the proposed memory mechanism.
minor comments (1)
- [Abstract] Abstract: the 82 MB storage figure for 12k tokens would benefit from an explicit statement of the assumed embedding dimension and quantization level.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below, proposing revisions to strengthen the paper where the concerns are valid.
read point-by-point responses
-
Referee: [Method] Method section: the claim that the online semantic basis update 'maximizes the amount of information' retained under a fixed budget is load-bearing for the compression and accuracy results, yet the manuscript provides neither an information-theoretic bound, reconstruction guarantee, nor ablation that isolates the basis construction from generic redundancy estimation or simpler eviction policies.
Authors: We acknowledge that the manuscript does not include a formal information-theoretic bound or reconstruction guarantee for the online semantic basis. The basis construction is motivated by an online approximation to principal component analysis to capture the dominant semantics of the video stream and reduce redundancy, with eviction decisions based on projection onto this basis. While this design aims to retain more representative information than naive policies, we agree that isolating its contribution requires additional evidence. In the revision we will add an ablation comparing CausalMem against simpler fixed-budget baselines (e.g., FIFO, random eviction, and uniform sampling) under identical token budgets to quantify the benefit of the semantic basis. revision: yes
-
Referee: [Experiments] Experiments section: the reported +3.2% and +3.0% average accuracy gains are presented without baseline tables, standard deviations, number of runs, or controls that rule out prompt-formatting or MLLM-integration effects; this prevents attribution of gains specifically to the proposed memory mechanism.
Authors: The reported gains are obtained by applying CausalMem to the unmodified LLaVA-OneVision and Qwen2.5-VL models on the same benchmarks and prompts used for the original models. We agree that the current presentation lacks sufficient statistical detail and controls. In the revised manuscript we will expand the experimental section to include (i) full baseline tables with all compared methods, (ii) standard deviations computed over multiple independent runs where feasible, and (iii) additional controls that isolate the memory mechanism from prompt-formatting or integration artifacts (e.g., by re-running the original models with the same prompt templates used for CausalMem). revision: yes
Circularity Check
No circularity; empirical method with external benchmarks
full rationale
The provided abstract and description present CausalMem as a training-free construction that estimates token redundancy and maintains an online semantic basis, then reports end-to-end accuracy gains on streaming and offline benchmarks when plugged into LLaVA-OneVision and Qwen2.5-VL. No equations, self-citations, or derivations are shown that reduce the claimed compression or accuracy improvements to a fit or definition by construction. The central claim rests on empirical results rather than any self-referential step, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The online semantic basis models the principal semantics of the observed video stream.
invented entities (1)
-
online semantic basis
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Vqa: Visual question answering
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. InProceedings of the IEEE international conference on computer vision, pages 2425–2433, 2015
2015
-
[2]
Microsoft coco captions: Data collection and evaluation server.arXiv preprint arXiv:1504.00325, 2015
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server.arXiv preprint arXiv:1504.00325, 2015
Pith/arXiv arXiv 2015
-
[3]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317–8326, 2019
2019
-
[4]
Ocr-vqa: Visual question answering by reading text in images
Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. Ocr-vqa: Visual question answering by reading text in images. In2019 international conference on document analysis and recognition (ICDAR), pages 947–952. IEEE, 2019
2019
-
[5]
Flashsloth: Lightning multimodal large language models via embedded visual compression
Bo Tong, Bokai Lai, Yiyi Zhou, Gen Luo, Yunhang Shen, Ke Li, Xiaoshuai Sun, and Rongrong Ji. Flashsloth: Lightning multimodal large language models via embedded visual compression. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14570– 14581, 2025
2025
-
[6]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[7]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[8]
Llava- video: Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Llava- video: Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024
Pith/arXiv arXiv 2024
-
[9]
Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
Pith/arXiv arXiv 2024
-
[10]
Qwen2.5-vl technical report,
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report,
-
[11]
URLhttps://arxiv.org/abs/2502.13923
-
[12]
Fit and prune: Fast and training-free visual token pruning for multi-modal large language models
Weihao Ye, Qiong Wu, Wenhao Lin, and Yiyi Zhou. Fit and prune: Fast and training-free visual token pruning for multi-modal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 22128–22136, 2025
2025
-
[13]
Shaobo Ju, Baiyang Song, Tao Chen, Jiapeng Zhang, Qiong Wu, Chao Chang, HuaiXi Wang, Yiyi Zhou, and Rongrong Ji. Forestprune: High-ratio visual token compression for video multimodal large language models via spatial-temporal forest modeling.arXiv preprint arXiv:2603.22911, 2026
Pith/arXiv arXiv 2026
-
[14]
Kele Shao, Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Holitom: Holistic token merging for fast video large language models.arXiv preprint arXiv:2505.21334, 2025
arXiv 2025
-
[15]
Ziyang Fan, Keyu Chen, Ruilong Xing, Yulin Li, Li Jiang, and Zhuotao Tian. Flashvid: Efficient video large language models via training-free tree-based spatiotemporal token merging.arXiv preprint arXiv:2602.08024, 2026. 10
arXiv 2026
-
[16]
What kind of visual tokens do we need? training-free visual token pruning for multi-modal large language models from the perspective of graph
Yutao Jiang, Qiong Wu, Wenhao Lin, Wei Yu, and Yiyi Zhou. What kind of visual tokens do we need? training-free visual token pruning for multi-modal large language models from the perspective of graph. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 4075–4083, 2025
2025
-
[17]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19792–19802, 2025
2025
-
[18]
Yanlai Yang, Zhuokai Zhao, Satya Narayan Shukla, Aashu Singh, Shlok Kumar Mishra, Lizhu Zhang, and Mengye Ren. Streammem: Query-agnostic kv cache memory for streaming video understanding.arXiv preprint arXiv:2508.15717, 2025
arXiv 2025
-
[19]
Shangzhe Di, Zhelun Yu, Guanghao Zhang, Haoyuan Li, Tao Zhong, Hao Cheng, Bolin Li, Wanggui He, Fangxun Shu, and Hao Jiang. Streaming video question-answering with in-context video kv-cache retrieval.arXiv preprint arXiv:2503.00540, 2025
arXiv 2025
-
[20]
Tao Chen, Kun Zhang, Qiong Wu, Xiao Chen, Chao Chang, Xiaoshuai Sun, Yiyi Zhou, and Rongrong Ji. Scaling the long video understanding of multimodal large language models via visual memory mechanism.arXiv preprint arXiv:2603.29252, 2026
arXiv 2026
-
[21]
Tao Chen, Shaobo Ju, Qiong Wu, Chenxin Fang, Kun Zhang, Jun Peng, Hui Li, Yiyi Zhou, and Rongrong Ji. Towards effective and efficient long video understanding of multimodal large language models via one-shot clip retrieval.arXiv preprint arXiv:2512.08410, 2025
Pith/arXiv arXiv 2025
-
[22]
One token per highly selective frame: Towards extreme compression for long video understanding
Zheyu Zhang, Ziqi Pang, Shixing Chen, Xiang Hao, Vimal Bhat, and Yu-Xiong Wang. One token per highly selective frame: Towards extreme compression for long video understanding. arXiv preprint arXiv:2604.14149, 2026
Pith/arXiv arXiv 2026
-
[23]
Yulin Li, Haokun Gui, Ziyang Fan, Junjie Wang, Bin Kang, Bin Chen, and Zhuotao Tian. Less is more, but where? dynamic token compression via llm-guided keyframe prior.arXiv preprint arXiv:2512.06866, 2025
arXiv 2025
-
[24]
Indexing by latent semantic analysis.Journal of the American society for information science, 41(6):391–407, 1990
Scott Deerwester, Susan T Dumais, George W Furnas, Thomas K Landauer, and Richard Harshman. Indexing by latent semantic analysis.Journal of the American society for information science, 41(6):391–407, 1990
1990
-
[25]
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
Pith/arXiv arXiv 2024
-
[26]
Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2022
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2022
Pith/arXiv arXiv 2022
-
[27]
Llava-prumerge: Adaptive token reduction for efficient large multimodal models
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. Llava-prumerge: Adaptive token reduction for efficient large multimodal models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22857–22867, 2025
2025
-
[28]
Zhenyu Ning, Guangda Liu, Qihao Jin, Wenchao Ding, Minyi Guo, and Jieru Zhao. Livevlm: Efficient online video understanding via streaming-oriented kv cache and retrieval.arXiv preprint arXiv:2505.15269, 2025
Pith/arXiv arXiv 2025
-
[29]
Yiweng Xie, Bo He, Junke Wang, Xiangyu Zheng, Ziyi Ye, and Zuxuan Wu. Fluxmem: Adaptive hierarchical memory for streaming video understanding.arXiv preprint arXiv:2603.02096, 2026
arXiv 2026
-
[30]
Xueyi Chen, Keda Tao, Kele Shao, and Huan Wang. Streamingtom: Streaming token compres- sion for efficient video understanding.arXiv preprint arXiv:2510.18269, 2025
arXiv 2025
-
[31]
Video-xl: Extra-long vision language model for hour-scale video understanding
Yan Shu, Zheng Liu, Peitian Zhang, Minghao Qin, Junjie Zhou, Zhengyang Liang, Tiejun Huang, and Bo Zhao. Video-xl: Extra-long vision language model for hour-scale video understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26160–26169, 2025. 11
2025
-
[32]
JHU press, 2013
Gene H Golub and Charles F Van Loan.Matrix computations. JHU press, 2013
2013
-
[33]
Ovo-bench: How far is your video-llms from real-world online video understanding? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18902–18913, 2025
Junbo Niu, Yifei Li, Ziyang Miao, Chunjiang Ge, Yuanhang Zhou, Qihao He, Xiaoyi Dong, Haodong Duan, Shuangrui Ding, Rui Qian, et al. Ovo-bench: How far is your video-llms from real-world online video understanding? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18902–18913, 2025
2025
-
[34]
Streamingbench: Assessing the gap for mllms to achieve streaming video understanding
Junming Lin, Zheng Fang, Chi Chen, Haoxuan Cheng, Zihao Wan, Fuwen Luo, Ziyue Wang, Peng Li, Yang Liu, and Maosong Sun. Streamingbench: Assessing the gap for mllms to achieve streaming video understanding. InICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 12147–12151. IEEE, 2026
2026
-
[35]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025
2025
-
[36]
Longvideobench: A benchmark for long- context interleaved video-language understanding.Advances in Neural Information Processing Systems, 37:28828–28857, 2024
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long- context interleaved video-language understanding.Advances in Neural Information Processing Systems, 37:28828–28857, 2024
2024
-
[37]
Mlvu: Benchmarking multi-task long video understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, et al. Mlvu: Benchmarking multi-task long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13691–13701, 2025
2025
-
[38]
Lvbench: An extreme long video understanding benchmark
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Ming Ding, Xiaotao Gu, Shiyu Huang, Bin Xu, et al. Lvbench: An extreme long video understanding benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22958– 22967, 2025
2025
-
[39]
Streamkv: Streaming video question-answering with segment-based kv cache retrieval and compression
Yilong Chen, Xiang Bai, Zhibin Wang, Chengyu Bai, Yuhan Dai, and Ming Lu. Streamkv: Streaming video question-answering with segment-based kv cache retrieval and compression. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 3120–3128, 2026
2026
-
[40]
Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[41]
Long context transfer from language to vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision. arXiv preprint arXiv:2406.16852, 2024
Pith/arXiv arXiv 2024
-
[42]
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Balakrishnan Varadarajan, Florian Bordes, et al. Longvu: Spa- tiotemporal adaptive compression for long video-language understanding.arXiv preprint arXiv:2410.17434, 2024
Pith/arXiv arXiv 2024
-
[43]
Videollm-online: Online video large language model for streaming video
Joya Chen, Zhaoyang Lv, Shiwei Wu, Kevin Qinghong Lin, Chenan Song, Difei Gao, Jia-Wei Liu, Ziteng Gao, Dongxing Mao, and Mike Zheng Shou. Videollm-online: Online video large language model for streaming video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18407–18418, 2024
2024
-
[44]
Dispider: Enabling video llms with active real-time interaction via disentangled perception, decision, and reaction
Rui Qian, Shuangrui Ding, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Dahua Lin, and Jiaqi Wang. Dispider: Enabling video llms with active real-time interaction via disentangled perception, decision, and reaction. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24045–24055, 2025
2025
-
[45]
Haoji Zhang, Yiqin Wang, Yansong Tang, Yong Liu, Jiashi Feng, Jifeng Dai, and Xiaojie Jin. Flash-vstream: Memory-based real-time understanding for long video streams.arXiv preprint arXiv:2406.08085, 2024. 12
arXiv 2024
-
[46]
Vispeak: Visual instruction feedback in streaming videos
Shenghao Fu, Qize Yang, Yuan-Ming Li, Yi-Xing Peng, Kun-Yu Lin, Xihan Wei, Jian-Fang Hu, Xiaohua Xie, and Wei-Shi Zheng. Vispeak: Visual instruction feedback in streaming videos. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21778–21788, 2025
2025
-
[47]
Timechat-online: 80% visual tokens are naturally redundant in streaming videos
Linli Yao, Yicheng Li, Yuancheng Wei, Lei Li, Shuhuai Ren, Yuanxin Liu, Kun Ouyang, Lean Wang, Shicheng Li, Sida Li, et al. Timechat-online: 80% visual tokens are naturally redundant in streaming videos. InProceedings of the 33rd ACM International Conference on Multimedia, pages 10807–10816, 2025. A Limitations CausalMem is a training-free method that app...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.