Learning Optimization Proxies for Sequential Contextual Stochastic Programs: An Order Fulfillment Application
Pith reviewed 2026-06-25 21:18 UTC · model grok-4.3
The pith
A neural network trained on solver labels approximates solutions to sequential stochastic fulfillment decisions, replacing slow per-epoch optimization with a fast forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a learning-based optimization proxy consisting of a scenario-embedded neural network trained offline on C-SAA labels, paired with a feasibility decoder, can replace the per-epoch solve of a two-stage contextual stochastic program for omnichannel order fulfillment. On data from a calibrated simulator, the proxy delivers decisions in a single forward pass that achieve lower realized fulfillment costs than the online C-SAA reference while satisfying the sub-second response requirement.
What carries the argument
Scenario-embedded neural network trained with a composite loss of label imitation, constraint-violation penalty, and self-supervised cost alignment, paired with a decoder that enforces feasibility.
If this is right
- Decision latency drops by roughly 2800 times compared with solving the finite-sample C-SAA online at each epoch.
- Realized fulfillment cost improves by 3.3 percent over the online C-SAA reference.
- Total realized cost falls by at least 10.7 percent relative to established fulfillment policies.
- Late-delivery rate is reduced by roughly half compared with those policies.
Where Pith is reading between the lines
- The same proxy architecture could be applied to other sequential contextual stochastic programs in logistics or resource allocation if an accurate simulator for label generation is available.
- Periodic retraining on fresh simulator data would likely be needed if underlying demand or delivery distributions change over time.
- Direct deployment would require an additional layer of safety checks or fallback solves to handle any residual generalization failures on live data.
- The approach illustrates how imitation of offline optimization can trade a modest amount of solution quality for orders-of-magnitude gains in decision speed.
Load-bearing premise
The neural network trained offline on C-SAA labels from the calibrated simulator will generalize to produce high-quality feasible decisions on new unseen order sequences without substantial degradation from distribution shift or simulator-reality mismatch.
What would settle it
Collect a set of real operational order sequences, solve the C-SAA online on each to obtain reference decisions and costs, run the trained proxy on the same sequences, and check whether the proxy's realized costs exceed the reference by more than a few percent or produce frequent infeasible assignments.
Figures





read the original abstract
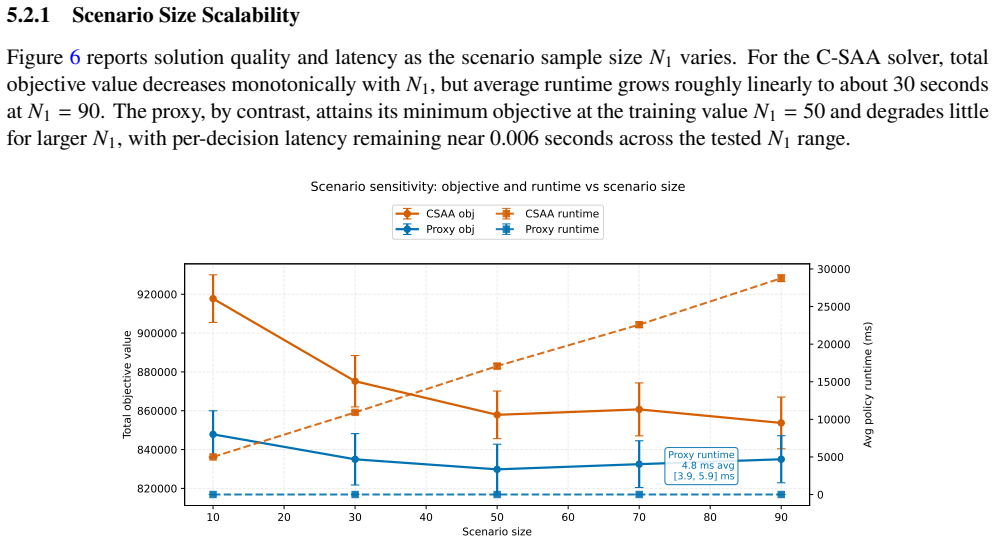
Sequential contextual stochastic programs model real-time decision systems in which each time epoch commits to an action under uncertainty whose consequences propagate into future decisions. In many practical contexts, these programs require obtaining solutions rapidly as new information becomes available. These problems can be represented through scenario approximations to be solved by off-the-shelf optimization solvers, which achieve high decision quality offline but typically run in seconds to minutes per instance, falling short of the sub-second responses that peak periods of planning require. This paper develops a learning-based optimization proxy: a scenario-embedded neural network trained offline on solver-generated labels, paired online with a decoder that enforces feasibility, replacing the per-epoch solve with a single forward pass. The framework is specialized to omnichannel order fulfillment, where each arriving order requires a sub-second assignment of products to distribution centers and carrier services under stochastic delivery times and future demand. A two-stage contextual stochastic program is introduced to formulate this problem, and its contextual sample average approximation (C-SAA) supplies the offline labels, while a composite training loss combines label imitation, a constraint-violation penalty, and self-supervised cost alignment. In a calibrated simulator built from JD.com transactional records, a detailed computational study is provided. The proxy reduces decision latency by roughly 2800x relative to the online finite-sample C-SAA reference and improves over it by 3.3% in realized fulfillment cost. Relative to established fulfillment policies, the proxy lowers total realized cost by at least 10.7% and roughly halves the late-delivery rate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a learning-based optimization proxy for sequential contextual stochastic programs, consisting of a scenario-embedded neural network trained offline on labels from contextual sample average approximation (C-SAA) together with a feasibility-enforcing decoder. The approach is specialized to omnichannel order fulfillment, where each order must be assigned to distribution centers and carriers under stochastic delivery times and future demand. In a simulator calibrated to JD.com data, the proxy is reported to achieve roughly 2800x lower decision latency than online C-SAA while improving realized cost by 3.3% and outperforming established policies by at least 10.7% with halved late-delivery rates.
Significance. If the reported generalization holds, the work supplies a practical route to sub-second, high-quality decisions for sequential stochastic programs that are otherwise too slow for real-time use. The composite training loss (label imitation + constraint penalty + self-supervised cost alignment) and the explicit feasibility decoder are concrete technical contributions that could be reused in other contextual stochastic settings.
major comments (3)
- [computational study] Computational study section: the headline performance figures (2800x latency reduction, 3.3% cost improvement over C-SAA, 10.7% vs. baselines) are presented without stating the number of test instances, number of independent simulation runs, variance estimates, or any statistical significance tests. This omission makes it impossible to judge whether the reported margins are robust or sensitive to simulator calibration choices.
- [framework and computational study] Training and online deployment description: the central claim that the offline-trained network produces high-quality feasible decisions on unseen order sequences rests on an untested generalization assumption. No out-of-distribution experiments, temporal hold-out splits, or simulator-reality gap tests are described, so any mismatch between the training distribution of contexts and future sequences directly undermines the claimed online gains.
- [two-stage contextual stochastic program formulation] C-SAA label generation: the finite-sample C-SAA used to produce training labels is itself an approximation whose quality depends on the number of scenarios; the manuscript does not report how label quality varies with scenario count or how this propagates into proxy performance.
minor comments (2)
- [training loss] Notation for the composite loss function should be introduced with an explicit equation number rather than inline description.
- [computational study] The abstract states performance numbers to one decimal place; the computational study should include a table that reports the same metrics with standard deviations across runs.
Simulated Author's Rebuttal
Thank you for the referee's constructive comments. We address each major point below and outline the revisions we will incorporate.
read point-by-point responses
-
Referee: [computational study] Computational study section: the headline performance figures (2800x latency reduction, 3.3% cost improvement over C-SAA, 10.7% vs. baselines) are presented without stating the number of test instances, number of independent simulation runs, variance estimates, or any statistical significance tests. This omission makes it impossible to judge whether the reported margins are robust or sensitive to simulator calibration choices.
Authors: We agree that the computational study would benefit from explicit reporting of these details. In the revision we will add the number of test instances, the number of independent simulation runs performed, variance or standard-error estimates, and any statistical significance tests conducted. revision: yes
-
Referee: [framework and computational study] Training and online deployment description: the central claim that the offline-trained network produces high-quality feasible decisions on unseen order sequences rests on an untested generalization assumption. No out-of-distribution experiments, temporal hold-out splits, or simulator-reality gap tests are described, so any mismatch between the training distribution of contexts and future sequences directly undermines the claimed online gains.
Authors: The reported results are obtained on order sequences generated inside the calibrated simulator that were not seen during training, which constitutes an in-distribution hold-out evaluation. We acknowledge that explicit out-of-distribution or temporal-split experiments and simulator-reality gap analysis are not currently described. We will revise the manuscript to clarify the existing train-test protocol and add a dedicated discussion of generalization limits. revision: partial
-
Referee: [two-stage contextual stochastic program formulation] C-SAA label generation: the finite-sample C-SAA used to produce training labels is itself an approximation whose quality depends on the number of scenarios; the manuscript does not report how label quality varies with scenario count or how this propagates into proxy performance.
Authors: We agree that sensitivity of label quality to the scenario count in C-SAA is an important missing analysis. The revised manuscript will include experiments that vary the number of scenarios used to generate labels and report the resulting effect on proxy performance. revision: yes
Circularity Check
No circularity: empirical proxy training and simulator evaluation are independent of fitted inputs.
full rationale
The paper trains a neural network offline to imitate finite-sample C-SAA solutions generated by an external solver on a calibrated simulator, then evaluates the resulting proxy online inside the same simulator against the C-SAA reference and baseline policies. No equation or claim reduces a performance metric to a fitted parameter by construction, no self-citation is invoked as a uniqueness theorem, and the reported latency and cost improvements are measured quantities rather than redefinitions of the training loss. The derivation chain consists of standard supervised learning plus a feasibility decoder, with all quantitative claims resting on external simulation runs.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network architecture and training hyperparameters
axioms (2)
- domain assumption C-SAA solver labels provide sufficiently high-quality training targets for the proxy.
- domain assumption The calibrated simulator accurately captures real-world stochastic dynamics and demand patterns.
Reference graph
Works this paper leans on
-
[1]
Manufacturing & Service Operations Management , volume=
Making better fulfillment decisions on the fly in an online retail environment , author=. Manufacturing & Service Operations Management , volume=. 2015 , publisher=
2015
-
[2]
Operations Research & Management Science in the age of analytics , pages=
The fulfillment-optimization problem , author=. Operations Research & Management Science in the age of analytics , pages=. 2019 , publisher=
2019
-
[3]
2019 , publisher=
Andrews, John M and Farias, Vivek F and Khojandi, Aryan I and Yan, Chad M , journal=. 2019 , publisher=
2019
-
[4]
INFORMS Journal on Computing , volume=
Control of dual-sourcing inventory systems using recurrent neural networks , author=. INFORMS Journal on Computing , volume=. 2023 , publisher=
2023
-
[5]
Manufacturing & Service Operations Management , volume=
Machine Learning--Augmented Optimization of Large Bilevel and Two-Stage Stochastic Programs: Application to Cycling Network Design , author=. Manufacturing & Service Operations Management , volume=. 2025 , publisher=
2025
-
[6]
Advances in neural information processing systems , volume=
Task-based end-to-end model learning in stochastic optimization , author=. Advances in neural information processing systems , volume=
-
[7]
arXiv preprint arXiv:2602.20271 , year=
Uncertainty-Aware Delivery Delay Duration Prediction via Multi-Task Deep Learning , author=. arXiv preprint arXiv:2602.20271 , year=
-
[8]
Advances in neural information processing systems , volume=
Exact combinatorial optimization with graph convolutional neural networks , author=. Advances in neural information processing systems , volume=
-
[9]
International Conference on Learning Representations , year=
Categorical Reparameterization with Gumbel-Softmax , author=. International Conference on Learning Representations , year=
-
[10]
2015 , publisher=
Jasin, Stefanus and Sinha, Amitabh , journal=. 2015 , publisher=
2015
-
[11]
Transportation Science , volume=
Scenario Predict-then-Optimize for Data-Driven Online Inventory Routing , author=. Transportation Science , volume=. 2025 , publisher=
2025
-
[12]
INFORMS Journal on Computing , year=
Enabling ultrafast online order fulfillment: Efficient inventory management for in-store microfulfillment centers , author=. INFORMS Journal on Computing , year=
-
[13]
INFORMS Journal on Computing , year=
Learning-based online optimization for autonomous mobility-on-demand fleet control , author=. INFORMS Journal on Computing , year=
-
[14]
Operations Research , volume=
Data-driven sample average approximation with covariate information , author=. Operations Research , volume=. 2025 , publisher=
2025
-
[15]
INFORMS Journal on Computing , volume=
Iterative prediction-and-optimization for E-logistics distribution network design , author=. INFORMS Journal on Computing , volume=. 2022 , publisher=
2022
-
[16]
Transportation Science , year=
Outbound Load Planning in Parcel Delivery Service Networks Using Machine Learning and Optimization , author=. Transportation Science , year=
-
[17]
and Bodur, Merve , journal=
Dumouchelle, Justin and Patel, Rahul Mihir and Khalil, Elias B. and Bodur, Merve , journal=
-
[18]
IEEE Open Journal of Intelligent Transportation Systems , volume=
Designing lookahead policies for sequential decision problems in transportation and logistics , author=. IEEE Open Journal of Intelligent Transportation Systems , volume=. 2022 , publisher=
2022
-
[19]
Management Science , volume=
A practical end-to-end inventory management model with deep learning , author=. Management Science , volume=. 2023 , publisher=
2023
-
[20]
Operations Research , year=
Integrated conditional estimation-optimization , author=. Operations Research , year=
-
[21]
arXiv preprint arXiv:2405.14973 , year=
Efficiently Training Deep-Learning Parametric policies using Lagrangian Duality , author=. arXiv preprint arXiv:2405.14973 , year=
-
[22]
A survey of contextual optimization methods for decision-making under uncertainty
A survey of contextual optimization methods for decision-making under uncertainty , journal =. 2025 , issn =. doi:10.1016/j.ejor.2024.03.020 , author =
-
[23]
Manufacturing & Service Operations Management , volume=
Real-time delivery time forecasting and promising in online retailing: When will your package arrive? , author=. Manufacturing & Service Operations Management , volume=. 2022 , publisher=
2022
-
[24]
2024 , publisher=
Shen, Max and Tang, Christopher S and Wu, Di and Yuan, Rong and Zhou, Wei , journal=. 2024 , publisher=
2024
-
[25]
arXiv preprint arXiv:2501.03443 , year=
Optimization Learning , author=. arXiv preprint arXiv:2501.03443 , year=
-
[26]
European Journal of Operational Research , volume=
Order Allocation in Online Retail: Classification and Literature Review , author=. European Journal of Operational Research , volume=. 2026 , publisher=
2026
-
[27]
Computational optimization and applications , volume=
The sample average approximation method applied to stochastic routing problems: a computational study , author=. Computational optimization and applications , volume=. 2003 , publisher=
2003
-
[28]
31st Conference on Neural Information Processing Systems (NIPS 2017), Time Series Workshop , address=
A multi-horizon quantile recurrent forecaster , author=. 31st Conference on Neural Information Processing Systems (NIPS 2017), Time Series Workshop , address=. 2017 , note=
2017
-
[29]
Proceedings of the AAAI conference on artificial intelligence , volume=
Melding the data-decisions pipeline: Decision-focused learning for combinatorial optimization , author=. Proceedings of the AAAI conference on artificial intelligence , volume=. 2019 , doi=
2019
-
[30]
arXiv preprint arXiv:2505.17340 , year=
Conformal Predictive Distributions for Order Fulfillment Time Forecasting , author=. arXiv preprint arXiv:2505.17340 , year=
-
[31]
Manufacturing & Service Operations Management , year=
Contextual stochastic optimization for omnichannel multicourier order fulfillment under delivery time uncertainty , author=. Manufacturing & Service Operations Management , year=
-
[32]
Annals of Operations Research , year=
A non-anticipative learning-optimization framework for solving multi-stage stochastic programs , author=. Annals of Operations Research , year=
-
[33]
Journal of Artificial Intelligence Research , volume=
Reinforcement learning from optimization proxy for ride-hailing vehicle relocation , author=. Journal of Artificial Intelligence Research , volume=. 2022 , doi=
2022
-
[34]
Deep Sets , volume =
Zaheer, Manzil and Kottur, Satwik and Ravanbakhsh, Siamak and Poczos, Barnabas and Salakhutdinov, Russ R and Smola, Alexander , booktitle =. Deep Sets , volume =
-
[35]
Management Science , volume=
From predictive to prescriptive analytics , author=. Management Science , volume=. 2020 , publisher=
2020
-
[36]
IEEE Transactions on Power Systems , volume=
End-to-End Feasible Optimization Proxies for Large-Scale Economic Dispatch , author=. IEEE Transactions on Power Systems , volume=. 2024 , publisher=
2024
-
[37]
Stochastic Systems , volume=
Dynamic matching for real-time ride sharing , author=. Stochastic Systems , volume=. 2020 , publisher=
2020
-
[38]
Surveys in Operations Research and Management Science , volume=
Dynamic pricing and learning: Historical origins, current research, and new directions , author=. Surveys in Operations Research and Management Science , volume=. 2015 , publisher=
2015
-
[39]
2025 , howpublished=
Uber Announces Results for Fourth Quarter and Full Year 2024 , author=. 2025 , howpublished=
2024
-
[40]
2020 , howpublished=
Alibaba Generates. 2020 , howpublished=
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.