Finetuning with Scientific Data Increases Hallucinations: A Multi-domain Factuality Evaluation of LLMs
Pith reviewed 2026-06-26 14:27 UTC · model grok-4.3
The pith
Fine-tuning LLMs on scientific data increases hallucinations across all tested domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
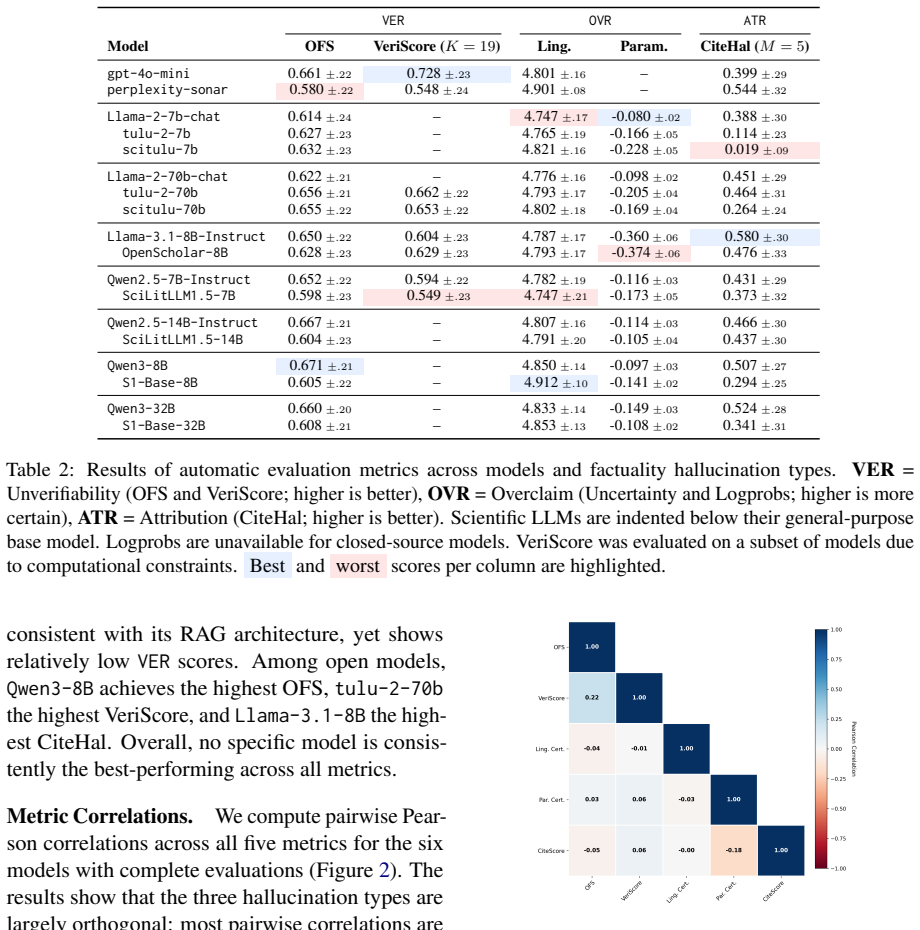
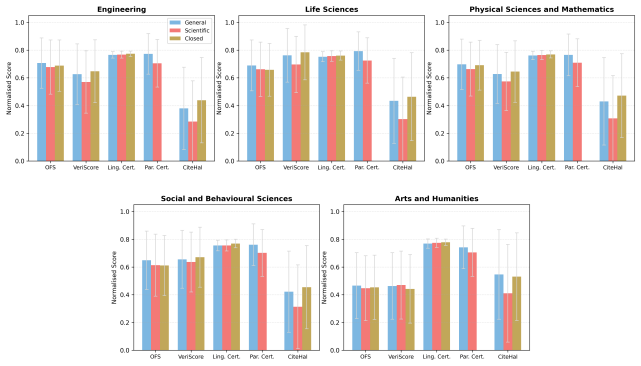
Scientifically fine-tuned models exhibit degraded factual reliability across all hallucination types and scientific domains. Fine-tuned models are internally less confident yet linguistically more assertive.
What carries the argument
SciFactCheck benchmark paired with a controlled minimal-pairing design that directly compares each scientifically fine-tuned model to its general-purpose base across three hallucination categories.
Load-bearing premise
The minimal-pairing design and SciFactCheck prompts isolate the causal effect of scientific fine-tuning without selection bias or unrepresentative queries.
What would settle it
A replication on a new collection of fine-tuned models or prompts that finds equal or improved factual reliability after scientific fine-tuning would falsify the central claim.
Figures




read the original abstract
Large language models (LLMs) are increasingly used to communicate and explain scientific concepts, yet their tendency to hallucinate poses significant risks in this high stakes use-case. Prior hallucination evaluation work remains largely restricted to the biomedical domain, treats hallucination as a binary task, and has not examined the growing family of scientifically fine-tuned LLMs. We address these gaps with SciFactCheck, a benchmark of 2,500 prompts across five scientific domains, paired with a modular evaluation framework targeting three factuality hallucination types: unverifiability, overclaim, and attribution. Using a controlled minimal-pairing design, we evaluate 18 LLMs by comparing each scientifically fine-tuned model against its general-purpose base. Our results indicate that 1. Scientifically fine-tuned models exhibit degraded factual reliability across all hallucination types and scientific domains, and 2. Fine-tuned models are internally less confident yet linguistically more assertive. A human pilot study further reveals that current fact-checking tools show only modest agreement with expert judgments on scientific content, and that defining scientifically check-worthy claims remains contested even among human annotators. Our findings fundamentally challenge current methods of domain-specific fine-tuning for factuality and call for developing improved verification infrastructure for scientific content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SciFactCheck, a benchmark of 2,500 prompts across five scientific domains, paired with a modular evaluation framework for three hallucination types (unverifiability, overclaim, attribution). Using a controlled minimal-pair design, it evaluates 18 LLMs by comparing each scientifically fine-tuned model to its general-purpose base. The central claims are that (1) scientific fine-tuning degrades factual reliability across all hallucination types and domains, and (2) fine-tuned models are internally less confident yet linguistically more assertive. A human pilot study reports only modest agreement between current fact-checking tools and expert judgments, along with contested definitions of check-worthy scientific claims.
Significance. If the degradation result holds after addressing measurement concerns, the work would challenge prevailing approaches to domain-specific fine-tuning for scientific applications and underscore the need for improved verification methods. The multi-domain scope and explicit comparison to base models are positive features; however, the paper's own pilot data on evaluator-expert agreement directly questions whether the observed increases in unverifiability/overclaim/attribution reflect genuine effects of fine-tuning or artifacts of the automated scoring.
major comments (3)
- [Abstract / human pilot study] Abstract and human pilot study: the reported modest agreement between fact-checking tools and expert judgments on scientific content is a load-bearing validity threat for the automated scores that produce the headline degradation result. Without stronger validation (e.g., higher inter-rater reliability or explicit error analysis of the modular framework), any cross-model differences in hallucination rates could be driven by evaluator limitations rather than fine-tuning.
- [Abstract] Abstract: the claim that the minimal-pairing design isolates the causal effect of scientific fine-tuning assumes the SciFactCheck prompts are free of selection bias and representative of real scientific queries; the contested definitions of check-worthy claims noted in the pilot suggest this assumption may not hold uniformly across domains.
- [Abstract] Abstract: no details are provided on statistical tests, confidence intervals, or error bars for the reported degradation across hallucination types; given the reliance on automated metrics whose validity is already flagged by the pilot, these omissions prevent assessment of whether the observed differences are robust.
minor comments (2)
- [Abstract] The abstract would benefit from a brief statement of the exact fine-tuning procedures and data sources used for the 18 models to allow readers to assess domain-adaptation details.
- [Abstract] Notation for the three hallucination types and the modular framework components should be defined more explicitly on first use to improve readability for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each of the major comments below, providing clarifications and indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract / human pilot study] Abstract and human pilot study: the reported modest agreement between fact-checking tools and expert judgments on scientific content is a load-bearing validity threat for the automated scores that produce the headline degradation result. Without stronger validation (e.g., higher inter-rater reliability or explicit error analysis of the modular framework), any cross-model differences in hallucination rates could be driven by evaluator limitations rather than fine-tuning.
Authors: We included the human pilot study specifically to underscore the limitations of current automated fact-checking tools when applied to scientific content, and we agree that this represents an important caveat for interpreting our results. The observed degradation is consistent across all domains and model pairs, which would be unlikely if driven purely by evaluator artifacts that do not systematically differ between base and fine-tuned models. Nevertheless, we will incorporate an explicit error analysis of the modular framework and report inter-rater reliability statistics from the pilot in the revised manuscript to provide greater transparency. revision: partial
-
Referee: [Abstract] Abstract: the claim that the minimal-pairing design isolates the causal effect of scientific fine-tuning assumes the SciFactCheck prompts are free of selection bias and representative of real scientific queries; the contested definitions of check-worthy claims noted in the pilot suggest this assumption may not hold uniformly across domains.
Authors: The minimal-pair design evaluates each fine-tuned model against its corresponding base model using identical prompts, which directly controls for prompt selection and any associated biases. This isolates the impact of the fine-tuning process itself. While the pilot study acknowledges that definitions of check-worthy claims can be contested, this affects the absolute interpretation of hallucination rates but not the comparative differences between base and fine-tuned models, as the same criteria are applied uniformly. revision: no
-
Referee: [Abstract] Abstract: no details are provided on statistical tests, confidence intervals, or error bars for the reported degradation across hallucination types; given the reliance on automated metrics whose validity is already flagged by the pilot, these omissions prevent assessment of whether the observed differences are robust.
Authors: We agree that statistical details are necessary for assessing robustness. The revised manuscript will include appropriate statistical tests, confidence intervals, and error bars for the reported differences. revision: yes
Circularity Check
No circularity: empirical evaluation is data-driven and self-contained
full rationale
The paper reports results from a controlled empirical comparison of 18 LLMs (scientifically fine-tuned vs. base models) on a new 2,500-prompt benchmark across five domains, measuring three hallucination types via the modular SciFactCheck framework plus a human pilot. No equations, parameter fits, or predictions are presented as first-principles derivations; the headline claims rest on observed performance deltas rather than any self-definition, renaming, or self-citation chain. The modest human-expert agreement noted in the pilot is a reported limitation on measurement validity, not a reduction of the evaluation logic to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 2500 prompts across five domains are representative of typical scientific queries and not biased toward cases where fine-tuning harms performance.
Reference graph
Works this paper leans on
-
[1]
InProceedings of the Fifth Workshop on Scholarly Document Processing (SDP 2025), pages 42–56, Vienna, Austria
The ClimateCheck dataset: Mapping social media claims about climate change to correspond- ing scholarly articles. InProceedings of the Fifth Workshop on Scholarly Document Processing (SDP 2025), pages 42–56, Vienna, Austria. Association for Computational Linguistics. Anum Afzal, Juraj Vladika, and Florian Matthes. 2025. FActBench: A benchmark for fine-gra...
2025
-
[2]
Ron Artstein and Massimo Poesio
LLMs as science journalists: Supporting early- stage researchers in communicating their science to the public.arXiv preprint arXiv:2601.05821. Ron Artstein and Massimo Poesio. 2008. Survey article: Inter-coder agreement for computational linguistics. Computational Linguistics, 34(4):555–596. 21https://www.nfdi4datascience.de Akari Asai, Jacqueline He, Rul...
arXiv 2008
-
[3]
Looking for a needle in a haystack: A com- prehensive study of hallucinations in neural machine translation. InProceedings of the 17th Conference of the European Chapter of the Association for Com- putational Linguistics, pages 1059–1075, Dubrovnik, Croatia. Association for Computational Linguistics. Thilo Hagendorff. 2024. Mapping the ethics of gener- at...
Pith/arXiv arXiv 2024
-
[4]
An audit on the perspectives and challenges of hallucinations in NLP. InProceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing, pages 6528–6548, Miami, Florida, USA. Association for Computational Linguistics. Benjamin Newman, Abhilasha Ravichander, Jaehun Jung, Rui Xin, Hamish Ivison, Yegor Kuznetsov, Pang Wei Koh, and Ye...
arXiv 2024
-
[5]
Abhilasha Ravichander, Shrusti Ghela, David Wadden, and Yejin Choi
The state of OA: a large-scale analysis of the prevalence and impact of open access articles.PeerJ, 6:e4375. Abhilasha Ravichander, Shrusti Ghela, David Wadden, and Yejin Choi. 2025. HALoGEN: Fantastic LLM hallucinations and where to find them. InProceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- ...
arXiv 2025
-
[6]
SciFact-open: Towards open-domain scientific claim verification. InFindings of the Association for Computational Linguistics: EMNLP 2022, pages 4719–4734, Abu Dhabi, United Arab Emirates. As- sociation for Computational Linguistics. David Wadden, Kejian Shi, Jacob Morrison, Alan Li, Aakanksha Naik, Shruti Singh, Nitzan Barzilay, Kyle Lo, Tom Hope, Luca So...
Pith/arXiv arXiv 2022
-
[7]
Yuji Zhang, Sha Li, Cheng Qian, Jiateng Liu, Pengfei Yu, Chi Han, Yi R
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Yuji Zhang, Sha Li, Cheng Qian, Jiateng Liu, Pengfei Yu, Chi Han, Yi R. Fung, Kathleen McKeown, ChengXiang Zhai, Manling Li, and Heng Ji. 2025. The law of knowledge overshadowing: Towards un- derstanding, predicting, and preventing LLM halluci- nation. InProceedings of the Eighth Fact Extraction and ...
Pith/arXiv arXiv 2025
-
[8]
Repeated scientific concept
-
[9]
The paper is a subjective opinion piece about the concept rather than a literature review
-
[10]
The paper is not written in English
-
[11]
The paper is a follow-up of another review pa- per and thus does not contain the full context of information
-
[12]
The IEP website is organised into five subsections:
The paper describes a questionnaire (i.e.sur- veyin that sense, which was prevalent in the Social Sciences domains). The IEP website is organised into five subsections:
-
[13]
Metaphysics and Epis- temology, 3
History of Philosophy, 2. Metaphysics and Epis- temology, 3. Philosophical Traditions, 4. Science, Logic, and Mathematics, and 5. Value Theory. We randomly select 100 articles from each subsection, yielding 500 philosophy concepts to represent the Arts and Humanities domain. B.2 Prompt Templates Figure 5 shows the prompt template used for the paragraph ge...
-
[14]
SciL- itIns (Li et al., 2025b), which is described as con- taining general science documents; and 3
SciRIFF (Wadden et al., 2025), which includes 22https://github.com/BerriAI/litellm 23https://huggingface.co/docs/transformers/ main/en/generation_strategies domains such as Material Sciences, Chemistry, Biomedicine, AI, Clinical, and Misc.; 2. SciL- itIns (Li et al., 2025b), which is described as con- taining general science documents; and 3. S2ORC, which...
2025
-
[15]
superior
This conservative rule ensures that valid cita- tions are not penalised due to the failure of a single lookup strategy, for instance, when a citation omits a DOI entirely, which is common for older or non- indexed works. Although citations include additional meta- data, namely year, venue, and authors, these fields are not incorporated into the binary dec...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.