OneRetrieval: Unifying Multi-Branch E-commerce Retrieval with an Editable Generative Model
Pith reviewed 2026-06-27 05:19 UTC · model grok-4.3
The pith
OneRetrieval unifies multi-branch e-commerce retrieval into one generative model that preserves the inverted index's real-time editability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
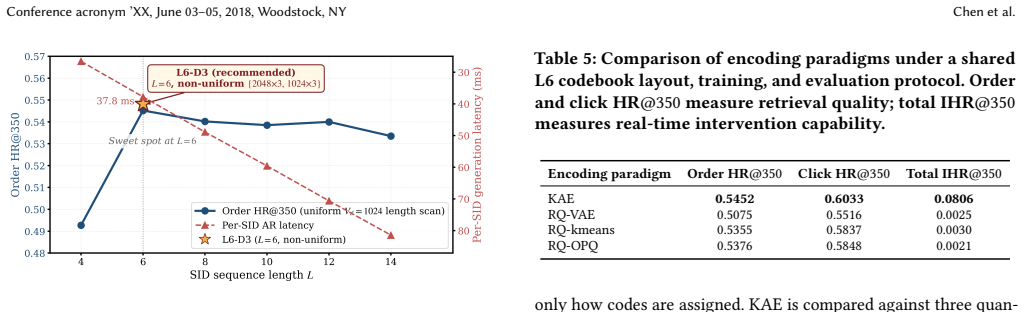
OneRetrieval is the first editable generative retrieval method that pairs competitive recall quality with the editability of the inverted index, achieved via Keyword-Aligned Encoding that ties each identifier position to an interpretable attribute word. An information-theoretic merging organizes 18 attribute categories into six codebook groups with non-uniform capacity; reserved slots in each codebook can be bound to new words after deployment without retraining; and a four-stage fine-tuning pipeline secures quality and editability jointly. On five million real-traffic requests it matches the deep recall of the strongest generative baseline while delivering an intervention hit rate over an o
What carries the argument
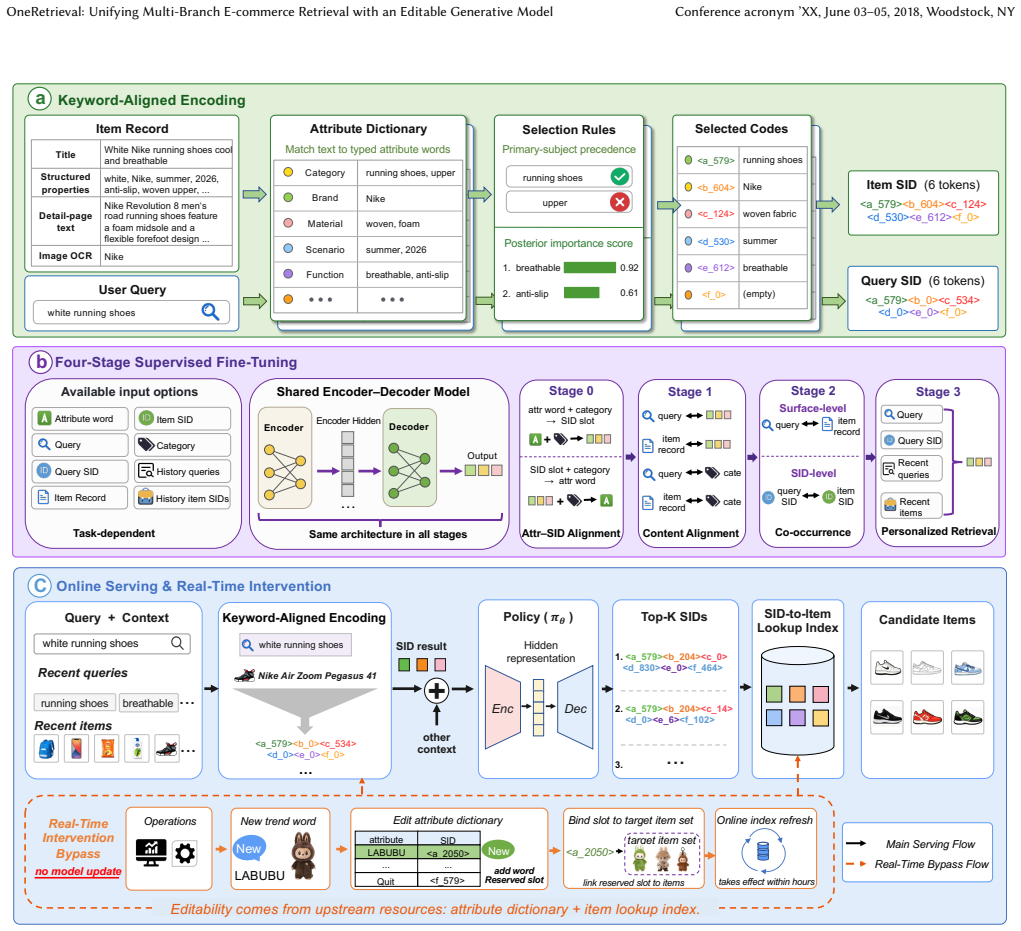
Keyword-Aligned Encoding (KAE), which ties each identifier position to an interpretable attribute word and uses reserved slots in codebooks to support post-deployment binding of new words.
If this is right
- OneRetrieval matches the recall of the strongest generative baseline on five million real-traffic requests.
- It achieves an intervention hit rate more than ten times higher than closed-codebook encodings.
- Replacing the inverted-index branch with OneRetrieval lifts order volume in online A/B tests.
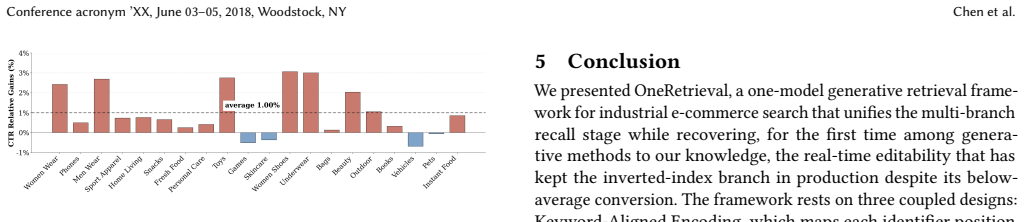
- Extending OneRetrieval to nearly the entire retrieval stage holds conversion rate while raising CTR.
Where Pith is reading between the lines
- The reserved-slot mechanism could be tested in non-e-commerce retrieval settings where vocabulary changes frequently, such as news or social media search.
- Joint optimization across what were previously separate branches may reduce the engineering cost of maintaining hand-tuned fusion rules in other large-scale systems.
- If the attribute-word alignment generalizes, similar encodings might allow generative models to support rapid updates in domains beyond product catalogs.
Load-bearing premise
Tying each identifier position to an interpretable attribute word preserves retrieval quality while allowing new words to bind to reserved slots after deployment without retraining or quality loss.
What would settle it
Measure recall on queries that use a newly bound term before and after binding the term to a reserved slot; if recall on those queries drops below the original multi-branch system, the editability claim does not hold.
Figures

read the original abstract
Industrial e-commerce search serves hundreds of millions of items through a multi-branch retrieval stage fused by hand-tuned merging without joint optimization. Generative retrieval (GR) raises the prospect of collapsing this stage into a single model, yet unification is gated by more than retrieval quality: the inverted-index branch converts below the platform average yet persists because it is almost the only branch where operations can inject a new term within hours without any model update; a one-model substitute must preserve this real-time editability. Existing GR methods structurally lack it: closed-codebook methods fix each slot to a quantized embedding at training, while open-vocabulary methods leave new-term routing to model generalization. We present OneRetrieval, a one-model GR framework built on Keyword-Aligned Encoding (KAE), which ties each identifier position to an interpretable attribute word, pairing competitive recall quality with the editability of the inverted index -- to our knowledge the first editable generative retrieval method. An information-theoretic merging organizes 18 attribute categories into six codebook groups with non-uniform capacity; reserved slots in each codebook can be bound to new words after deployment without retraining; and a four-stage fine-tuning pipeline secures quality and editability jointly. On five million real-traffic requests, OneRetrieval matches the deep recall of the strongest generative baseline, with an intervention hit rate over an order of magnitude above closed-codebook encodings. Online, replacing the inverted-index branch significantly lifts order volume; extending to nearly the entire stage holds conversion while improving CTR. The system is deployed at Kuaishou, serving hundreds of millions of PVs daily.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OneRetrieval, a generative retrieval framework for e-commerce search that uses Keyword-Aligned Encoding (KAE) to tie each identifier position to an interpretable attribute word, organizes attributes into six codebook groups with reserved slots for post-deployment binding of new terms, and applies a four-stage fine-tuning pipeline to jointly achieve competitive recall quality and editability without retraining. On five million real-traffic requests it matches the strongest generative baseline on deep recall while reporting intervention hit rates over an order of magnitude higher than closed-codebook methods; online A/B tests show lifts when replacing the inverted-index branch and maintained conversion with improved CTR when extending to nearly the full stage.
Significance. If the central claim of editability without quality loss holds under direct verification, the work would be significant for industrial retrieval: it offers the first generative method that preserves the real-time term-injection capability of inverted indexes while unifying multi-branch systems under a single optimized model, with demonstrated online business impact at scale.
major comments (2)
- [Abstract / Results] Abstract and experimental evaluation: the claim that binding new words to reserved slots incurs no quality loss (and requires no retraining) is load-bearing for the central contribution yet is supported only by intervention hit-rate numbers; no before/after recall, NDCG, or hit-rate metrics on a fixed item set after binding are reported, leaving the 'without quality loss' half of the editability claim unverified.
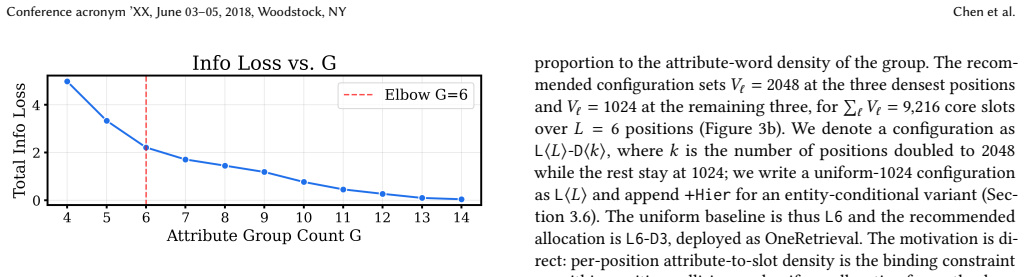
- [Methods] Methods (KAE and codebook construction): the information-theoretic merging of 18 attribute categories into six groups with non-uniform capacity is presented as enabling both quality and editability, but no ablation quantifies the contribution of the merging rule versus uniform allocation or versus the reserved-slot mechanism itself.
minor comments (2)
- [Abstract] The abstract states 'an order of magnitude above closed-codebook encodings' for intervention hit rate but supplies neither the exact numerical values nor the identity of the closed-codebook baseline.
- [Experimental evaluation] No error bars, confidence intervals, or data-exclusion rules are mentioned for the five-million-request offline results or the online lifts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, agreeing that the points identify areas where additional evidence would strengthen the central claims, and we outline revisions to incorporate the suggested verifications.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and experimental evaluation: the claim that binding new words to reserved slots incurs no quality loss (and requires no retraining) is load-bearing for the central contribution yet is supported only by intervention hit-rate numbers; no before/after recall, NDCG, or hit-rate metrics on a fixed item set after binding are reported, leaving the 'without quality loss' half of the editability claim unverified.
Authors: We agree that direct before-and-after metrics on a fixed item set would provide stronger verification of the no-quality-loss claim. The reported intervention hit rates confirm that new terms can be bound and retrieved at high rates, but they do not quantify any potential degradation in overall retrieval quality post-binding. In the revised manuscript we will add an experiment that binds new words to reserved slots, then reports recall, NDCG, and hit-rate on the same fixed item set before and after binding. revision: yes
-
Referee: [Methods] Methods (KAE and codebook construction): the information-theoretic merging of 18 attribute categories into six groups with non-uniform capacity is presented as enabling both quality and editability, but no ablation quantifies the contribution of the merging rule versus uniform allocation or versus the reserved-slot mechanism itself.
Authors: We acknowledge that an ablation isolating the merging rule would be valuable for quantifying its contribution relative to uniform allocation or the reserved-slot design. The information-theoretic grouping was motivated by balancing capacity according to attribute entropy and frequency, yet without explicit comparisons the benefit remains unmeasured. We will add an ablation study in the revision that compares the proposed merging against uniform capacity allocation and against variants that omit reserved slots, reporting effects on both retrieval quality and editability metrics. revision: yes
Circularity Check
No significant circularity; claims rest on architectural description without self-referential reductions
full rationale
The manuscript text (abstract and summary) presents OneRetrieval as an architectural framework relying on Keyword-Aligned Encoding, reserved codebook slots, and a four-stage fine-tuning pipeline. No equations, derivations, or parameter-fitting steps are exhibited that reduce by construction to their own inputs. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatzes or renamings of prior results are smuggled in. The editability claim is asserted as a direct consequence of the described design choices rather than derived from fitted quantities or prior author work. This is the normal case of a self-contained systems paper whose central assertions remain open to external verification.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alfred V Aho and Margaret J Corasick. 1975. Efficient string matching: an aid to bibliographic search.Commun. ACM18, 6 (1975), 333–340
1975
-
[2]
Michele Bevilacqua, Giuseppe Ottaviano, Patrick Lewis, Scott Yih, Sebastian Riedel, and Fabio Petroni. 2022. Autoregressive search engines: Generating substrings as document identifiers.Advances in Neural Information Processing Systems35 (2022), 31668–31683
2022
- [3]
-
[4]
Ben Chen, Siyuan Wang, Yufei Ma, Zihan Liang, Xuxin Zhang, Yue Lv, Ying Yang, Huangyu Dai, Lingtao Mao, Tong Zhao, et al. 2026. OneSearch-V2: The Latent Reasoning Enhanced Self-distillation Generative Search Framework.arXiv preprint arXiv:2603.24422(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
1999.Elements of information theory
Thomas M Cover. 1999.Elements of information theory. John Wiley & Sons
1999
-
[6]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. Onerec: Unifying retrieve and rank with generative OneRetrieval: Unifying Multi-Branch E-commerce Retrieval with an Editable Generative Model Conference acronym ’XX, June 03–05, 2018, Woodstock, NY recommender and iterative preference alignment.arXiv p...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021. Simcse: Simple contrastive learning of sentence embeddings. InProceedings of the 2021 conference on empirical methods in natural language processing. 6894–6910
2021
-
[8]
Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun. 2013. Optimized product quantization.IEEE transactions on pattern analysis and machine intelligence36, 4 (2013), 744–755
2013
-
[9]
Xian Guo, Ben Chen, Siyuan Wang, Ying Yang, Mingyue Cheng, Chenyi Lei, Yuqing Ding, and Han Li. 2026. Onesug: The unified end-to-end generative framework for e-commerce query suggestion. InProceedings of the AAAI Confer- ence on Artificial Intelligence, Vol. 40. 14774–14782
2026
-
[10]
Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2010. Product quantization for nearest neighbor search.IEEE transactions on pattern analysis and machine intelligence33, 1 (2010), 117–128
2010
-
[11]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs.IEEE transactions on big data7, 3 (2019), 535–547
2019
-
[12]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[13]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open- domain question answering. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP). 6769–6781
2020
-
[14]
Omar Khattab and Matei Zaharia. 2020. Colbert: Efficient and effective passage search via contextualized late interaction over bert. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 39–48
2020
-
[15]
Sunkyung Lee, Minjin Choi, and Jongwuk Lee. 2023. GLEN: Generative retrieval via lexical index learning. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 7693–7704
2023
-
[16]
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. InProceedings of the 58th annual meeting of the association for computational linguistics. 7871–7880
2020
- [17]
-
[18]
Yongqi Li, Nan Yang, Liang Wang, Furu Wei, and Wenjie Li. 2024. Learning to rank in generative retrieval. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 8716–8723
2024
- [19]
-
[20]
Rodrigo Nogueira and Jimmy Lin. 2019. From doc2query to docTTTTTquery. Online preprint(2019)
2019
-
[21]
Ming Pang, Chunyuan Yuan, Xiaoyu He, Zheng Fang, Donghao Xie, Fanyi Qu, Xue Jiang, Changping Peng, Zhangang Lin, Zheng Luo, et al. 2025. Generative retrieval and alignment model: A new paradigm for e-commerce retrieval. In Companion Proceedings of the ACM on Web Conference 2025. 413–421
2025
-
[22]
Qi Pi, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, Xiaoqiang Zhu, and Kun Gai. 2020. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. InProceedings of the 29th ACM International Conference on Information & Knowledge Management. 2685–2692
2020
-
[23]
Junyan Qiu, Ze Wang, Fan Zhang, Zuowu Zheng, Jile Zhu, Jiangke Fan, Teng Zhang, Haitao Wang, and Xingxing Wang. 2025. UniROM: Unifying Online Advertising Ranking as One Model. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 2440–2449
2025
-
[24]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al
-
[25]
Recommender systems with generative retrieval.Advances in Neural Information Processing Systems36 (2023), 10299–10315
2023
-
[26]
2009.The probabilistic relevance frame- work: BM25 and beyond
Stephen Robertson and Hugo Zaragoza. 2009.The probabilistic relevance frame- work: BM25 and beyond. Vol. 4. Now Publishers Inc
2009
-
[27]
Badrul Sarwar, George Karypis, Joseph Konstan, and John Riedl. 2001. Item-based collaborative filtering recommendation algorithms. InProceedings of the 10th international conference on World Wide Web. 285–295
2001
-
[28]
Yi Tay, Vinh Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, et al. 2022. Transformer memory as a differentiable search index.Advances in neural information processing systems35 (2022), 21831–21843
2022
-
[29]
Huimin Xu, Wenting Wang, Xinnian Mao, Xinyu Jiang, and Man Lan. 2019. Scaling up open tagging from tens to thousands: Comprehension empowered attribute value extraction from product title. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 5214–5223
2019
-
[30]
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. 2024. Adapting large language models by integrating collaborative semantics for recommendation. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 1435–1448
2024
-
[31]
Guineng Zheng, Subhabrata Mukherjee, Xin Luna Dong, and Feifei Li. 2018. Opentag: Open attribute value extraction from product profiles. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1049–1058
2018
- [32]
- [33]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.