MedGuards: Multi-Agent System for Reliable Medical Error Detection and Correction
Pith reviewed 2026-06-29 05:02 UTC · model grok-4.3
The pith
MedGuards treats medical error detection and correction as a multi-agent in-context learning task with specialized agents and confidence-guided arbitration to improve reliability without retraining LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MedGuards is a framework that treats medical error detection and correction as a multi-agent in-context learning task. Specialized agents separately detect, localize, and correct errors, while a confidence-guided arbitration mechanism resolves disagreements using reasoning traces and confidence scores. This design enhances interpretability, robustness, and adaptability without requiring additional training of the base LLMs, and experiments demonstrate significant improvements across several metrics and models on four multilingual medical datasets.
What carries the argument
The multi-agent in-context learning task with specialized agents for detection, localization, and correction, plus a confidence-guided arbitration mechanism that resolves disagreements using reasoning traces and confidence scores.
If this is right
- Enhances interpretability of the error handling process through reasoning traces.
- Improves robustness and adaptability across different datasets and models without additional training.
- Introduces the Keyword-Prioritized Correction Score (KPCS) as a more comprehensive evaluation metric.
- Supports safer deployment of LLMs in real-world healthcare applications.
Where Pith is reading between the lines
- Similar multi-agent setups could be tested in other high-stakes domains like legal document review.
- The arbitration mechanism might be adapted for general multi-agent LLM tasks beyond medicine.
- Future work could explore combining this with fine-tuning for even better performance.
Load-bearing premise
Existing automated checks and heuristic-based approaches do not generalize well across unseen datasets while the proposed multi-agent in-context learning design will.
What would settle it
Running the framework on one of the four multilingual clinical note datasets and finding no significant improvement in metrics compared to baseline methods would challenge the claim of effectiveness.
Figures

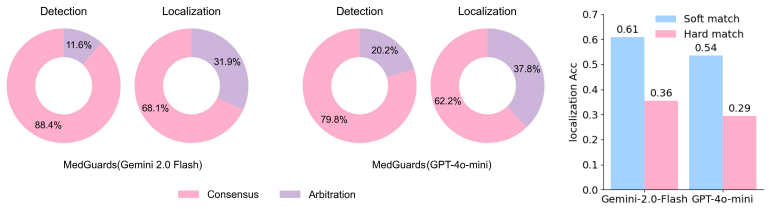



read the original abstract
As Large Language Models (LLMs) are increasingly deployed in healthcare settings, accurate error detection and correction in generated or existing text becomes critical, as even minor mistakes can pose risks to patient safety. Existing methods for error detection and correction, including automated checks and heuristic-based approaches, do not generalize well across unseen datasets. In this paper, we propose MedGuards as a medical safety guardrail, which is a new framework that treats medical error detection and correction as a multi-agent in-context learning task. Specialized agents separately detect, localize, and correct errors, while a confidence-guided arbitration mechanism resolves disagreements using reasoning traces and confidence scores. This design enhances interpretability, robustness, and adaptability, without requiring additional training of the base LLMs. Additionally, we introduce the Keyword-Prioritized Correction Score (KPCS), a new evaluation metric that considers whether critical keywords within the reference text are generated correctly, providing a more comprehensive assessment than conventional metrics. Experiments across four multilingual medical datasets consisting of clinical notes demonstrate significant improvements by the proposed framework across several metrics and models. Our aim is to enable safer deployment of LLMs in real-world healthcare applications. For reproducibility, we make our code publicly available at https://github.com/congboma/MedGuards.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MedGuards, a multi-agent in-context learning framework for medical error detection and correction in LLM outputs. It uses specialized agents for detection, localization, and correction, plus a confidence-guided arbitration mechanism based on reasoning traces and scores. The work introduces the Keyword-Prioritized Correction Score (KPCS) metric and claims significant improvements over baselines across four multilingual clinical-note datasets without requiring additional LLM training.
Significance. If the empirical claims hold with proper cross-dataset controls and statistical support, the multi-agent ICL design and KPCS metric could meaningfully improve interpretability and robustness for LLM safety guardrails in healthcare. The training-free adaptability is a potential strength for real-world deployment.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The central motivation states that existing automated checks and heuristics 'do not generalize well across unseen datasets,' yet the text supplies no protocol details on cross-dataset hold-out (e.g., whether in-context examples are drawn exclusively from three of the four datasets with final metrics reported on the held-out fourth). This separation is load-bearing for attributing gains to the claimed robustness rather than dataset-specific prompting.
- [Abstract] Abstract: The claim of 'significant improvements ... across several metrics and models' is asserted without any quantitative results, baseline comparisons, error bars, dataset statistics, or statistical tests. The full manuscript must supply these to substantiate the performance claims.
minor comments (1)
- [Abstract] The public code release at the cited GitHub link supports reproducibility and should be retained.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central motivation states that existing automated checks and heuristics 'do not generalize well across unseen datasets,' yet the text supplies no protocol details on cross-dataset hold-out (e.g., whether in-context examples are drawn exclusively from three of the four datasets with final metrics reported on the held-out fourth). This separation is load-bearing for attributing gains to the claimed robustness rather than dataset-specific prompting.
Authors: We agree that the manuscript does not supply explicit protocol details on cross-dataset hold-out. To support the generalization claims, we will revise §4 to describe the evaluation protocol in full, including how in-context examples were selected across the four datasets and whether a leave-one-dataset-out design was employed. revision: yes
-
Referee: [Abstract] Abstract: The claim of 'significant improvements ... across several metrics and models' is asserted without any quantitative results, baseline comparisons, error bars, dataset statistics, or statistical tests. The full manuscript must supply these to substantiate the performance claims.
Authors: The detailed quantitative results with baselines, error bars, dataset statistics, and statistical tests appear in §4. We will revise the abstract to include representative quantitative highlights and baseline comparisons to better substantiate the performance claims. revision: yes
Circularity Check
No circularity: framework proposal contains no derivations or self-referential reductions
full rationale
The paper proposes MedGuards as a multi-agent ICL system with specialized agents and a new KPCS metric, motivated by a claim that prior heuristic methods fail to generalize. No equations, parameter fittings, or derivation chains appear in the abstract or described structure. Claims rest on experimental results across four datasets rather than any step that reduces by construction to its own inputs, self-citations, or fitted values renamed as predictions. The generalization motivation is an empirical assertion open to external verification and does not constitute a circular step under the defined patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Overview of the mediqa-corr 2024 shared task on medical error detection and correction
Asma Ben Abacha, Wen-wai Yim, Yujuan Fu, Zhaoyi Sun, Fei Xia, and Meliha Yetisgen-Yildiz. Overview of the mediqa-corr 2024 shared task on medical error detection and correction. In Proceedings of the 6th Clinical Natural Language Processing Workshop, pages 596–603, 2024
2024
-
[2]
MEDEC: A benchmark for medical error detection and correction in clinical notes
Asma Ben Abacha, Wen-wai Yim, Yujuan Fu, Zhaoyi Sun, Meliha Yetisgen, Fei Xia, and Thomas Lin. MEDEC: A benchmark for medical error detection and correction in clinical notes. InFindings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, pages 22539–22550, 2025
2025
-
[3]
Zahra Atf, Seyed Amir Ahmad Safavi-Naini, Peter R Lewis, Aref Mahjoubfar, Nariman Naderi, Thomas R Savage, and Ali Soroush. The challenge of uncertainty quantification of large language models in medicine.arXiv preprint arXiv:2504.05278, 2025
-
[4]
AKNL Aththanagoda, KASH Kulathilake, and NA Abdullah. Precision and personalization: How large language models redefining diagnostic accuracy in personalized medicine—a sys- tematic literature review.IEEE Journal of Biomedical and Health Informatics, 2025
2025
-
[5]
Xuanzhong Chen, Ye Jin, Xiaohao Mao, Lun Wang, Shuyang Zhang, and Ting Chen. Rareagents: Advancing rare disease care through llm-empowered multi-disciplinary team.arXiv preprint arXiv:2412.12475, 2024
-
[6]
Mederrbench: A fine-grained multilingual benchmark for medical error detection and correction with clinical expert annotations
Ma Congbo, Zhang Yichun, Al-Jazzazi Yousef, Foisal Ahamed, Sharma Laasya, Sadqi Yousra, Saleh Khaled, Mallat Jihad, and Shamout Farah E. Mederrbench: A fine-grained multilingual benchmark for medical error detection and correction with clinical expert annotations. In Findings of the Association for Computational Linguistics, ACL 2026, San Diego, Californi...
2026
-
[7]
Iryonlp at MEDIQA-CORR 2024: Tackling the medical error detection & correction task on the shoulders of medical agents
Jean-Philippe Corbeil. Iryonlp at MEDIQA-CORR 2024: Tackling the medical error detection & correction task on the shoulders of medical agents. InProceedings of the 6th Clinical Natural Language Processing Workshop, ClinicalNLP@NAACL 2024, Mexico City, Mexico, June 21, 2024, pages 570–580, 2024
2024
-
[8]
Development of a human evaluation framework and correlation with automated metrics for natural language generation of medical diagnoses.medRxiv, 2024
Emma Croxford, Yanjun Gao, Brian Patterson, Daniel To, Samuel Tesch, Dmitriy Dligach, Anoop Mayampurath, Matthew M Churpek, and Majid Afshar. Development of a human evaluation framework and correlation with automated metrics for natural language generation of medical diagnoses.medRxiv, 2024
2024
-
[9]
Medarabiq: Benchmarking large language models on arabic medical tasks
Mouath Abu Daoud, Chaimae Abouzahir, Leen Kharouf, Walid Al-Eisawi, Nizar Habash, and Farah E Shamout. Medarabiq: Benchmarking large language models on arabic medical tasks. arXiv preprint arXiv:2505.03427, 2025
-
[10]
From text to treatment: the crucial role of validation for generative large language models in health care.The Lancet Digital Health, 6(7):e441–e443, 2024
Anne de Hond, Tuur Leeuwenberg, Richard Bartels, Marieke van Buchem, Ilse Kant, Karel GM Moons, and Maarten van Smeden. From text to treatment: the crucial role of validation for generative large language models in health care.The Lancet Digital Health, 6(7):e441–e443, 2024
2024
-
[11]
Deepseek-v3
DeepSeek AI. Deepseek-v3. https://huggingface.co/deepseek-ai/deepseek-vl-7b ,
-
[13]
Doubao-1.5-thinking-pro.https://console.volcengine
Doubao Team, V olcano Engine. Doubao-1.5-thinking-pro.https://console.volcengine. com/ark/region:ark+cn-beijing/model/detail?Id=doubao-1-5-thinking-pro ,
-
[14]
Accessed: 2025-08-01
2025
-
[15]
Alexander R Fabbri, Chien-Sheng Wu, Wenhao Liu, and Caiming Xiong. Qafacteval: Improved qa-based factual consistency evaluation for summarization.arXiv preprint arXiv:2112.08542, 2021
-
[16]
Summarizing patients’ problems from hospital progress notes using pre-trained sequence-to-sequence models
Yanjun Gao, Timothy Miller, Dongfang Xu, Dmitriy Dligach, Matthew M Churpek, and Ma- jid Afshar. Summarizing patients’ problems from hospital progress notes using pre-trained sequence-to-sequence models. InProceedings of COLING. International Conference on Com- putational Linguistics, volume 2022, page 2979, 2022. 10
2022
-
[17]
Gemini 2.0 and 2.5 flash models
Google Research. Gemini 2.0 and 2.5 flash models. https://blog.google/technology/ ai/google-gemini-flash, 2025. Accessed: 2025-08-01
2025
-
[18]
Ascleai: A llm-based clinical note management system for enhancing clinician productivity
Jiyeon Han, Jimin Park, Jinyoung Huh, Uran Oh, Jaeyoung Do, and Daehee Kim. Ascleai: A llm-based clinical note management system for enhancing clinician productivity. InExtended Abstracts of the CHI Conference on Human Factors in Computing Systems, pages 1–7, 2024
2024
-
[19]
Zesheng Hong, Yubiao Yue, Yubin Chen, Lele Cong, Huanjie Lin, Yuanmei Luo, Mini Han Wang, Weidong Wang, Jialong Xu, Xiaoqi Yang, et al. Out-of-distribution detection in medical image analysis: A survey.arXiv preprint arXiv:2404.18279, 2024
-
[20]
What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
2021
-
[21]
Mdagents: An adaptive collaboration of llms for medical decision-making.Advances in Neural Information Processing Systems, 37:79410–79452, 2024
Yubin Kim, Chanwoo Park, Hyewon Jeong, Yik S Chan, Xuhai Xu, Daniel McDuff, Hyeon- hoon Lee, Marzyeh Ghassemi, Cynthia Breazeal, and Hae W Park. Mdagents: An adaptive collaboration of llms for medical decision-making.Advances in Neural Information Processing Systems, 37:79410–79452, 2024
2024
-
[22]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[23]
Camel: Communicative agents for" mind" exploration of large language model society.Advances in Neural Information Processing Systems, 36:51991–52008, 2023
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for" mind" exploration of large language model society.Advances in Neural Information Processing Systems, 36:51991–52008, 2023
2023
-
[24]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. InText Summariza- tion Branches Out, pages 74–81, 2004
2004
-
[25]
Fangyu Liu, Ehsan Shareghi, Zaiqiao Meng, Marco Basaldella, and Nigel Collier. Self-alignment pretraining for biomedical entity representations.arXiv preprint arXiv:2010.11784, 2020
-
[26]
A generalist medical language model for disease diagnosis assistance.Nature medicine, 31(3):932–942, 2025
Xiaohong Liu, Hao Liu, Guoxing Yang, Zeyu Jiang, Shuguang Cui, Zhaoze Zhang, Huan Wang, Liyuan Tao, Yongchang Sun, Zhu Song, et al. A generalist medical language model for disease diagnosis assistance.Nature medicine, 31(3):932–942, 2025
2025
-
[27]
On faithfulness and factuality in abstractive summarization.arXiv preprint arXiv:2005.00661, 2020
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. On faithfulness and factuality in abstractive summarization.arXiv preprint arXiv:2005.00661, 2020
-
[28]
A comprehensive overview of large language models.ACM Transactions on Intelligent Systems and Technology, 16(5):1–72, 2025
Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar, Nick Barnes, and Ajmal Mian. A comprehensive overview of large language models.ACM Transactions on Intelligent Systems and Technology, 16(5):1–72, 2025
2025
-
[29]
Why We Need New Evaluation Metrics for NLG
Jekaterina Novikova, Ondˇrej Dušek, Amanda Cercas Curry, and Verena Rieser. Why we need new evaluation metrics for nlg.arXiv preprint arXiv:1707.06875, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Gpt-4o-mini model card
OpenAI. Gpt-4o-mini model card. https://platform.openai.com/docs/models# gpt-4o, 2024. Accessed: 2025-08-01
2024
-
[31]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002
2002
-
[32]
Python Software Foundation.Python Standard Library: difflib — Helpers for computing deltas,
-
[33]
Accessed: 2025-09-23
2025
-
[34]
Em_mixers at mediqa-corr 2024: Knowledge-enhanced few-shot in-context learning for medical error detection and correction
Swati Rajwal, Eugene Agichtein, and Abeed Sarker. Em_mixers at mediqa-corr 2024: Knowledge-enhanced few-shot in-context learning for medical error detection and correction. InProceedings of the 6th Clinical Natural Language Processing Workshop, 2024. 11
2024
-
[35]
Medifact at MEDIQA-CORR 2024: Why AI needs a human touch
Nadia Saeed. Medifact at MEDIQA-CORR 2024: Why AI needs a human touch. InProceedings of the 6th Clinical Natural Language Processing Workshop, ClinicalNLP@NAACL 2024, Mexico City, Mexico, June 21, 2024, pages 346–352, 2024
2024
-
[36]
AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments
Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffrey Jopling, and Michael Moor. Agentclinic: a multimodal agent benchmark to evaluate ai in simulated clinical environments. arXiv preprint arXiv:2405.07960, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Thibault Sellam, Dipanjan Das, and Ankur P. Parikh. BLEURT: learning robust metrics for text generation. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, pages 7881–7892, 2020
2020
-
[38]
Trustworthy and practical ai for healthcare: A guided deferral system with large language models
Joshua Strong, Qianhui Men, and J Alison Noble. Trustworthy and practical ai for healthcare: A guided deferral system with large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 28413–28421, 2025
2025
-
[39]
Large language models in medicine.Nature medicine, 29(8):1930–1940, 2023
Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. Large language models in medicine.Nature medicine, 29(8):1930–1940, 2023
1930
-
[40]
Hse nlp team at mediqa-corr 2024 task: In-prompt ensemble with entities and knowledge graph for medical error correction
Airat Valiev and Elena Tutubalina. Hse nlp team at mediqa-corr 2024 task: In-prompt ensemble with entities and knowledge graph for medical error correction. InProceedings of the 6th Clinical Natural Language Processing Workshop, 2024
2024
-
[41]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[42]
Le, Ed H
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023, 2023
2023
-
[43]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[44]
Physician-and large language model–generated hospital discharge summaries
Christopher YK Williams, Charumathi Raghu Subramanian, Syed Salman Ali, Michael Apoli- nario, Elisabeth Askin, Peter Barish, Monica Cheng, W James Deardorff, Nisha Donthi, Smitha Ganeshan, et al. Physician-and large language model–generated hospital discharge summaries. JAMA Internal Medicine, 2025
2025
-
[45]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst Conference on Language Modeling, 2024
2024
-
[46]
Knowlab_aimed at mediqa-corr 2024: Chain-of-though (cot) prompting strategies for medical error detection and correction
Zhaolong Wu, Abul Hasan, Jinge Wu, Yunsoo Kim, Jason Cheung, Teng Zhang, and Honghan Wu. Knowlab_aimed at mediqa-corr 2024: Chain-of-though (cot) prompting strategies for medical error detection and correction. Inproceedings of the 6th clinical natural language processing workshop, pages 353–359, 2024
2024
-
[47]
Unilog: Automatic logging via llm and in-context learning
Junjielong Xu, Ziang Cui, Yuan Zhao, Xu Zhang, Shilin He, Pinjia He, Liqun Li, Yu Kang, Qingwei Lin, Yingnong Dang, et al. Unilog: Automatic logging via llm and in-context learning. InProceedings of the 46th ieee/acm international conference on software engineering, pages 1–12, 2024
2024
-
[48]
Bufang Yang, Siyang Jiang, Lilin Xu, Kaiwei Liu, Hai Li, Guoliang Xing, Hongkai Chen, Xiaofan Jiang, and Zhenyu Yan. Drhouse: An llm-empowered diagnostic reasoning system through harnessing outcomes from sensor data and expert knowledge.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 8(4):1–29, 2024
2024
-
[49]
A large language model for electronic health records.NPJ digital medicine, 5(1):194, 2022
Xi Yang, Aokun Chen, Nima PourNejatian, Hoo Chang Shin, Kaleb E Smith, Christopher Parisien, Colin Compas, Cheryl Martin, Anthony B Costa, Mona G Flores, et al. A large language model for electronic health records.NPJ digital medicine, 5(1):194, 2022. 12
2022
-
[50]
Chatdiet: Empowering personalized nutrition-oriented food recommender chatbots through an llm-augmented framework.Smart Health, 32:100465, 2024
Zhongqi Yang, Elahe Khatibi, Nitish Nagesh, Mahyar Abbasian, Iman Azimi, Ramesh Jain, and Amir M Rahmani. Chatdiet: Empowering personalized nutrition-oriented food recommender chatbots through an llm-augmented framework.Smart Health, 32:100465, 2024
2024
-
[51]
Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
2023
-
[52]
Ziruo Yi, Ting Xiao, and Mark V Albert. A multimodal multi-agent framework for radiology report generation.arXiv preprint arXiv:2505.09787, 2025
-
[53]
Clinicalagent: Clinical trial multi-agent system with large language model-based reasoning
Ling Yue, Sixue Xing, Jintai Chen, and Tianfan Fu. Clinicalagent: Clinical trial multi-agent system with large language model-based reasoning. InProceedings of the 15th ACM Interna- tional Conference on Bioinformatics, Computational Biology and Health Informatics, pages 1–10, 2024
2024
-
[54]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. BERTScore: Evaluating text generation with BERT. InInternational Conference on Learning Representations (ICLR), 2020
2020
-
[55]
Kg4diagnosis: A hierarchical multi-agent llm framework with knowledge graph enhancement for medical diagnosis
Kaiwen Zuo, Yirui Jiang, Fan Mo, and Pietro Lio. Kg4diagnosis: A hierarchical multi-agent llm framework with knowledge graph enhancement for medical diagnosis. InAAAI Bridge Program on AI for Medicine and Healthcare, pages 195–204. PMLR, 2025. A Appendix A.1 Datasets, Baseline Models and Evaluation Metrics We conducted experiments on the publicly availabl...
2025
-
[56]
sepsis” is not treated as a keyword because it represents an existing diagnosis at admission (“Mr. <NAME/> was treated for sepsis, present on admission
Tables 7 and 8 use Gpt-4o-mini as the base model forMedGuards. In Table 7, most other model mixtures lead to slightly lower performance. However, we also observe an interesting case: when Gemini 2.0 Flash is introduced as an additional agent in the localization stage (serving as an agreement agent), the localization and correction performance increase. Th...
1927
-
[57]
CORRECT". If the text has a medical error return one word
Other treatments include: Patient on pres- sure reducing surface,zinc citratemoisture barrier, Assist patient to obtain adequate nu- trition. Ms. <NAME/> is being managed for Stage 3 R and L coccyx pressure ulcers, present on admit (POA). Patient is a <AGE/> YO F recently discharged after a 1 month hos- pitalization for recurrent cirrhosis of trans- plant...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.