Bespoke-Card: Why Tune When You Can Generate? Synthesizing Workload-Specific Cardinality Estimators
Pith reviewed 2026-06-27 14:21 UTC · model grok-4.3
The pith
An agent system synthesizes workload-specific cardinality estimators as executable code, cutting PostgreSQL runtime on the JOB benchmark by 33%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
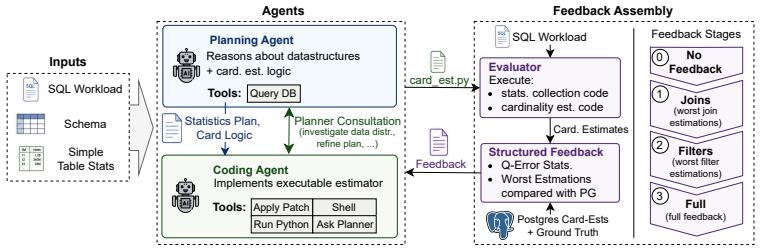
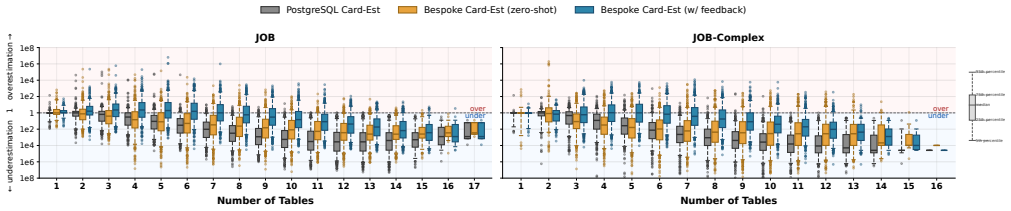
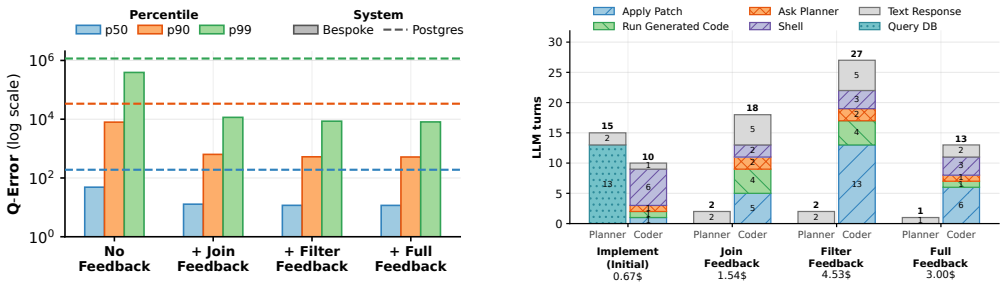
Bespoke-Card synthesizes workload-specific cardinality estimators directly as executable code. A planning agent designs the estimation approach, a coding agent writes the implementation, and a validator scores the code against ground-truth cardinalities and PostgreSQL estimates. Structured feedback from q-error, regression analysis, concrete outlier subplans, and a curriculum covering join-only, filter-only, and full-subplan cases guides selection of the best implementation. When these estimators replace the default inside the optimizer, total PostgreSQL runtime on the JOB benchmark falls by 33% and median q-error over all subplans drops by 41%.
What carries the argument
The multi-agent synthesis harness of planning, coding, and validation agents that iteratively generates, tests, and archives executable cardinality estimation code using q-error and curriculum feedback.
If this is right
- Workload-specific estimators can be created on demand without manual tuning or large training sets.
- Query optimizers gain access to estimates that match the actual schema and query patterns of a given database.
- Synthesis can be repeated cheaply whenever the workload changes, producing fresh estimators each time.
- The approach provides an alternative path for cardinality estimation that sits beside both classical statistics and learned models.
Where Pith is reading between the lines
- The same agent harness could be tested on synthesizing other optimizer components such as cost models or join-order heuristics.
- If the validator remains reliable, the method might reduce dependence on fixed learned architectures that require offline training data collection.
- Applying the synthesis loop to production workloads with slowly drifting query patterns would reveal how often regeneration is needed to maintain gains.
Load-bearing premise
The agents can produce correct, executable estimation code that integrates safely with the optimizer and generalizes beyond the queries used for validation.
What would settle it
Integrating the synthesized code into PostgreSQL and measuring no reduction in total runtime or median q-error on the JOB benchmark would falsify the performance claim.
Figures


read the original abstract
Cardinality estimators are built to support arbitrary schemas and workloads, forcing them to rely on generic statistics even when the schema and workload is known in advance, leaving optimizers prone to large errors and poor plans. We present Bespoke-Card, an agent-driven system that synthesizes workload-specific cardinality estimators as executable code: a planning agent designs the estimators strategies, a coding agent implements them, and a validator scores the estimates against true cardinalities and PostgreSQL estimates, forming a robust and deterministic harness. Going beyond naive prompting, Bespoke-Card uses structured q-error feedback, regression analysis, concrete outlier subplans, a curriculum isolating join-only, filter-only, and full-subplan errors, and archival selection of the best implementation. Injecting its estimates into the optimizer cuts total PostgreSQL runtime on JOB by 33% and reduces median q-error over all JOB subplans by 41%, while synthesizing a strong estimator in under one hour for less than $10. Bespoke-Card is opening a new avenue for cardinality estimation next to classical generic estimators and learned estimator architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Bespoke-Card, an agent-driven system that synthesizes workload-specific cardinality estimators as executable code via a planning agent, coding agent, and validator that scores against ground-truth cardinalities using structured q-error feedback, regression analysis, outlier subplans, and a curriculum over join/filter/full subplans. On the JOB benchmark, the best synthesized estimator reduces total PostgreSQL runtime by 33% and median q-error over all subplans by 41% when injected into the optimizer, at a cost of under one hour and $10.
Significance. If the reported gains reflect genuine generalization, the work would be significant for demonstrating a practical, low-cost alternative to both classical generic estimators and learned models, enabling bespoke estimators tailored to known schemas and workloads.
major comments (1)
- [Evaluation on JOB benchmark] The 41% median q-error reduction and 33% runtime improvement are reported over all JOB subplans, but the validator, structured feedback, outlier analysis, curriculum, and archival selection all operate on these same subplans. No held-out test partition of subplans or queries (excluded from all feedback and selection) is described, so the gains may reflect overfitting to the synthesis set rather than a generalizable workload-specific estimator. This directly undermines the central empirical claim.
minor comments (2)
- [System overview] The abstract and system description would benefit from explicit pseudocode or a diagram of the full agent loop, including how the validator's scores are converted into prompts for the coding agent.
- [Implementation details] Clarify the exact mechanism and safety guarantees for injecting the synthesized estimator into PostgreSQL (e.g., which hooks or extensions are used and how it avoids side effects on other queries).
Simulated Author's Rebuttal
We thank the referee for highlighting a methodological concern in our evaluation. We address the comment directly below and commit to revisions that strengthen the empirical claims.
read point-by-point responses
-
Referee: [Evaluation on JOB benchmark] The 41% median q-error reduction and 33% runtime improvement are reported over all JOB subplans, but the validator, structured feedback, outlier analysis, curriculum, and archival selection all operate on these same subplans. No held-out test partition of subplans or queries (excluded from all feedback and selection) is described, so the gains may reflect overfitting to the synthesis set rather than a generalizable workload-specific estimator. This directly undermines the central empirical claim.
Authors: We agree that the absence of an explicitly held-out partition of subplans or queries (never seen during planning, coding, validation, feedback, or archival selection) leaves open the possibility that the reported q-error reductions partly reflect fitting to the synthesis set rather than a robust workload-specific estimator. The runtime improvement provides some downstream evidence of utility, but it does not fully isolate generalization of the cardinality function itself. We will revise the manuscript to (1) partition the JOB subplans into synthesis and held-out sets, (2) report q-error and runtime results on the held-out portion, and (3) add a discussion of how the curriculum and outlier analysis interact with generalization. These changes will be reflected in the next version. revision: yes
Circularity Check
No significant circularity; results are empirical measurements on external benchmark
full rationale
The paper describes an agent-based synthesis system for workload-specific cardinality estimators and reports concrete runtime and q-error improvements measured on the external JOB benchmark. No equations, fitted parameters, or self-citation chains are presented that reduce any claimed result to the inputs by construction. The central claims rest on direct experimental outcomes rather than any self-definitional, fitted-input, or uniqueness-imported derivation. The absence of an explicit held-out partition is an evaluation-validity concern, not a circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption AI agents can reliably generate correct and effective cardinality estimation code for given workloads
Reference graph
Works this paper leans on
-
[1]
Gibbons, Viswanath Poosala, and Sridhar Ra- maswamy
Swarup Acharya, Phillip B. Gibbons, Viswanath Poosala, and Sridhar Ra- maswamy. 1999. Join Synopses for Approximate Query Answering. InSIGMOD. 275–286
1999
-
[2]
Rico Bergmann, Claudio Hartmann, Dirk Habich, and Wolfgang Lehner. 2025. An Elephant Under the Microscope: Analyzing the Interaction of Optimizer Components in PostgreSQL.SIGMOD3, 1 (2025), 9:1–9:28
2025
-
[3]
Garofalakis, Peter J
Graham Cormode, Minos N. Garofalakis, Peter J. Haas, and Chris Jermaine
-
[4]
Foundations and Trends in Databases4, 1-3 (2012), 1–294
Synopses for Massive Data: Samples, Histograms, Wavelets, Sketches. Foundations and Trends in Databases4, 1-3 (2012), 1–294
2012
-
[5]
Timo Eckmann, Matthias Jasny, Johannes Wehrstein, and Carsten Binnig. 2026. The Future Is Bespoke: Synthesizing One-Size-Fits-One DBMSs with LLM Coding Agents.IEEE Data Engineering Bulletin50, 1 (2026), 88–103
2026
-
[6]
Ullman, and Jennifer Widom
Hector Garcia-Molina, Jeffrey D. Ullman, and Jennifer Widom. 2009.Database Systems - The Complete Book (2. ed.)
2009
-
[7]
Benjamin Hilprecht, Andreas Schmidt, Moritz Kulessa, Alejandro Molina, Kris- tian Kersting, and Carsten Binnig. 2020. DeepDB: Learn from Data, not from Queries!VLDB13, 7 (2020), 992–1005
2020
-
[8]
Andreas Kipf, Thomas Kipf, Bernhard Radke, Viktor Leis, Peter Boncz, and Alfons Kemper. 2019. Learned Cardinalities: Estimating Correlated Joins with Deep Learning. InCIDR
2019
-
[9]
Oleksii Kliukin. 2014. PgTune – Tuning PostgreSQL Config by Your Hardware
2014
-
[10]
Viktor Leis, Andrey Gubichev, Atanas Mirchev, Peter Boncz, Alfons Kemper, and Thomas Neumann. 2015. How Good Are Query Optimizers, Really?VLDB9, 3 (2015), 204–215
2015
-
[11]
Viktor Leis, Bernhard Radke, Andrey Gubichev, Alfons Kemper, and Thomas Neumann. 2017. Cardinality Estimation Done Right: Index-Based Join Sampling. InCIDR
2017
-
[12]
Yao Lu, Srikanth Kandula, Arnd Christian König, and Surajit Chaudhuri. 2021. Pre-training Summarization Models of Structured Datasets for Cardinality Esti- mation.VLDB15, 3 (2021), 414–426
2021
-
[13]
Ioannidis
Viswanath Poosala and Yannis E. Ioannidis. 1997. Selectivity Estimation Without the Attribute Value Independence Assumption. InVLDB. 486–495
1997
-
[14]
Ioannidis, Peter J
Viswanath Poosala, Yannis E. Ioannidis, Peter J. Haas, and Eugene J. Shekita
-
[15]
In SIGMOD
Improved Histograms for Selectivity Estimation of Range Predicates. In SIGMOD. 294–305
-
[16]
Selinger, Morton M
Patricia G. Selinger, Morton M. Astrahan, Donald D. Chamberlin, Raymond A. Lorie, and Thomas G. Price. 1979. Access Path Selection in a Relational Database Management System. InSIGMOD. 23–34
1979
-
[17]
One Size Fits All
Michael Stonebraker and Ugur Çetintemel. 2005. "One Size Fits All": An Idea Whose Time Has Come and Gone (Abstract). InICDE. 2–11
2005
-
[18]
Alexander van Renen, Dominik Horn, Pascal Pfeil, Kapil Vaidya, Wenjian Dong, Murali Narayanaswamy, Zhengchun Liu, Gaurav Saxena, Andreas Kipf, and Tim Kraska. 2024. Why TPC Is Not Enough: An Analysis of the Amazon Redshift Fleet.VLDB17, 11 (2024), 3694–3706
2024
-
[19]
Johannes Wehrstein, Carsten Binnig, Fatma Özcan, Shobha Vasudevan, Yu Gan, and Yawen Wang. 2025. Towards Foundation Database Models. InCIDR
2025
-
[20]
Johannes Wehrstein, Timo Eckmann, Roman Heinrich, and Carsten Binnig
-
[21]
JOB-Complex: A Challenging Benchmark for Traditional & Learned Query Optimization.VLDB(2025)
2025
-
[22]
Johannes Wehrstein, Timo Eckmann, Matthias Jasny, and Carsten Binnig. 2026. Bespoke OLAP: Synthesizing Workload-Specific One-size-fits-one Database En- gines.arXiv preprint arXiv:2603.02001(2026)
arXiv 2026
-
[23]
Peizhi Wu and Gao Cong. 2021. A Unified Deep Model of Learning from both Data and Queries for Cardinality Estimation. InSIGMOD. 2009–2022
2021
-
[24]
Zongheng Yang, Amog Kamsetty, Sifei Luan, Eric Liang, Yan Duan, Xi Chen, and Ion Stoica. 2020. NeuroCard: One Cardinality Estimator for All Tables.VLDB14, 1 (2020), 61–73
2020
-
[25]
Tianjing Zeng, Junwei Lan, Jiahong Ma, Wenqing Wei, Rong Zhu, Pengfei Li, Bolin Ding, Defu Lian, Zhewei Wei, and Jingren Zhou. 2024. PRICE: A Pretrained Model for Cross-Database Cardinality Estimation.VLDB18, 3 (2024), 637–650. 10
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.