LoHoSearch: Benchmarking Long-Horizon Search Agents Beyond the Human Difficulty Ceiling
Pith reviewed 2026-06-27 07:00 UTC · model grok-4.3
The pith
A new benchmark built from a Wikipedia knowledge graph shows top models reach only 34.74 percent accuracy on long-horizon search questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
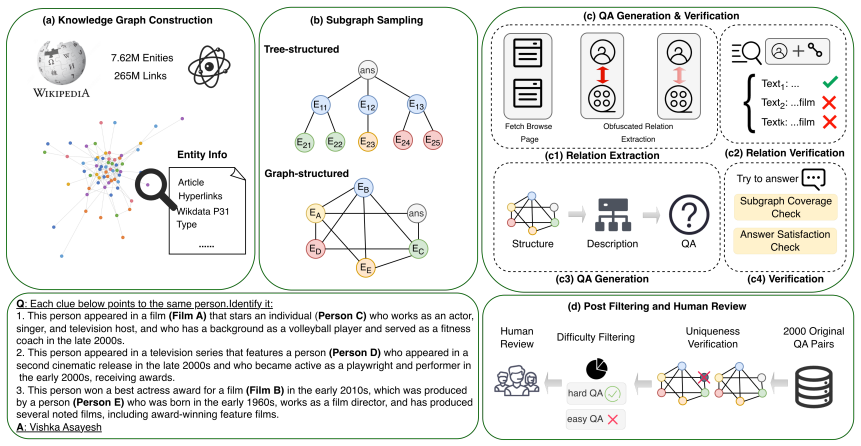
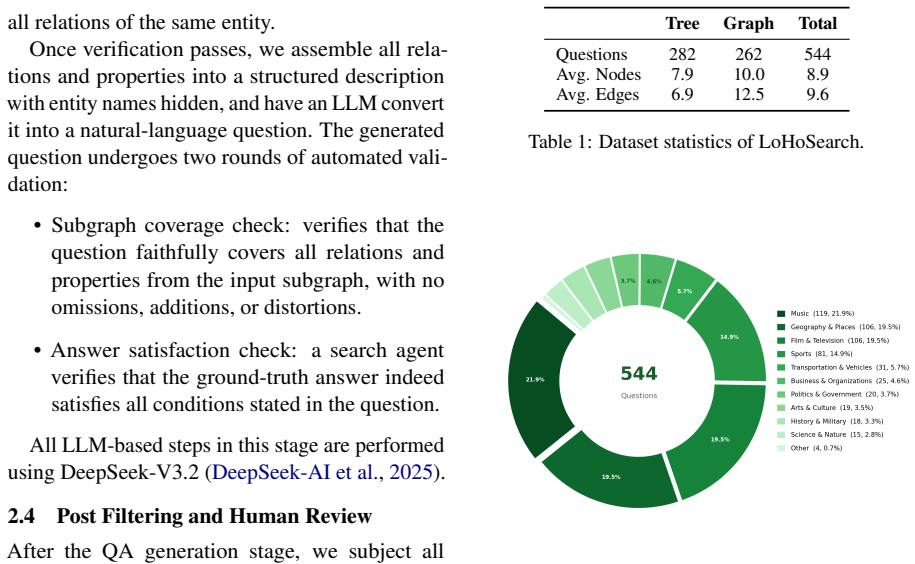
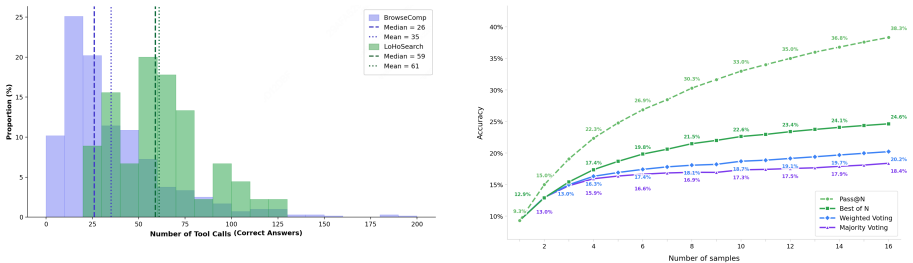
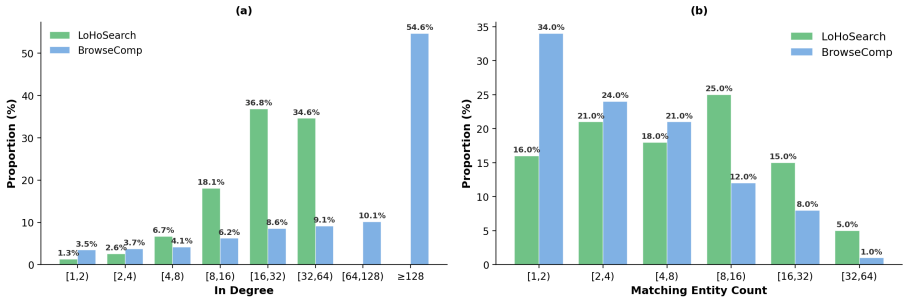
By constructing questions through an automated pipeline on a knowledge graph covering over seven million Wikipedia entities, the authors produce 544 questions whose search spaces and structural complexity exceed what human annotators can reliably create. On this set, the strongest model attains 34.74 percent accuracy and existing context strategies improve performance by at most 6.8 percent, far less than the gains observed on earlier benchmarks.
What carries the argument
The automated pipeline that selects relations with large search spaces from the knowledge graph and assembles them into structurally complex questions with KG-verified unique answers.
If this is right
- Long-horizon search agents must improve substantially beyond current context strategies to handle the larger search spaces and question structures in LoHoSearch.
- Gains from context management observed on earlier benchmarks will not transfer at the same scale to questions built for maximum difficulty.
- Future agent evaluations should incorporate automated construction pipelines to maintain difficulty above human annotation limits.
- Performance ceilings on LoHoSearch provide a clearer signal of remaining gaps in multi-step reasoning over large entity graphs.
Where Pith is reading between the lines
- Human-authored benchmarks systematically underestimate the difficulty of search tasks that require exhaustive exploration of large relation spaces.
- Agents that integrate graph traversal or explicit relation enumeration may show larger relative gains on this benchmark than on prior ones.
- The construction method could be applied to other knowledge bases to generate domain-specific long-horizon tests without additional human authoring effort.
Load-bearing premise
The automated pipeline on the knowledge graph can reliably select relations with large search spaces, assemble structurally complex questions, and produce answers that remain valid after human verification.
What would settle it
A model achieving above 70 percent accuracy on the 544 questions using only existing context-management methods, or a human evaluation showing that many questions lack unique answers.
Figures

read the original abstract
Search agent benchmarks exemplified by BrowseComp have rapidly saturated over the past year, with the strongest models surpassing 90% accuracy. Since these benchmarks are predominantly human-authored, annotators lack a global perspective on entity statistics and cannot systematically maximize search space size and structural complexity. This creates a difficulty ceiling that is hard to break. To address this, we introduce LoHoSearch (Long-Horizon Search Agents), a challenging benchmark comprising 544 human-verified questions across 11 domains. LoHoSearch is constructed via an automated pipeline built upon a knowledge graph covering over 7 million Wikipedia entities, which selects relations with large search spaces and assembles them into structurally complex questions with KG-verified unique answers. Our evaluation demonstrates that even the strongest model achieves only 34.74% accuracy, and existing context management strategies (best +6.8%) yield far smaller gains than on prior benchmarks. LoHoSearch provides a more demanding standard for evaluating long-horizon reasoning and context management in search agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LoHoSearch, a benchmark of 544 human-verified questions across 11 domains constructed via an automated pipeline on a knowledge graph covering over 7 million Wikipedia entities. The pipeline selects relations with large search spaces and assembles structurally complex questions with KG-verified unique answers. Evaluation shows the strongest model reaches only 34.74% accuracy, with existing context management strategies yielding at most +6.8% gains, far smaller than on prior benchmarks like BrowseComp.
Significance. If the pipeline reliably produces questions with unique answers that require long-horizon search without shortcuts or ambiguities, the benchmark would be significant for establishing a new standard beyond the saturation of human-authored benchmarks. The automated KG construction over millions of entities is a methodological strength that enables systematic maximization of search space size and structural complexity at scale.
major comments (2)
- [Abstract / §3] Abstract and construction pipeline (presumably §3): the central claim that the 544 questions have KG-verified unique answers and require long-horizon search rests on the automated pipeline selecting large-search-space relations and assembling complex questions, but no quantitative breakdown of pipeline error rates, exclusion criteria, inter-annotator agreement on uniqueness, or search-space size comparisons before/after filtering is referenced.
- [§4 / Table 1] Evaluation (presumably §4 and Table 1): the headline result of 34.74% accuracy and +6.8% from context strategies is only interpretable as evidence of agent limitations if the questions are confirmed to have unique answers post-human verification; without reported agreement numbers or verification details, the difficulty-ceiling claim cannot be fully assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to improve the transparency of our construction and verification processes. We address each major comment below and will revise the manuscript accordingly to include the requested quantitative details.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and construction pipeline (presumably §3): the central claim that the 544 questions have KG-verified unique answers and require long-horizon search rests on the automated pipeline selecting large-search-space relations and assembling complex questions, but no quantitative breakdown of pipeline error rates, exclusion criteria, inter-annotator agreement on uniqueness, or search-space size comparisons before/after filtering is referenced.
Authors: We agree that the current description of the pipeline lacks the requested quantitative breakdowns. The manuscript describes the high-level pipeline and states that questions are human-verified with KG-verified unique answers, but does not report error rates, exclusion criteria, agreement metrics, or search-space statistics. In the revision we will add a dedicated subsection to §3 reporting: (1) estimated pipeline error rates from spot-checks on KG verification, (2) explicit exclusion criteria (e.g., minimum search-space cardinality thresholds), (3) inter-annotator agreement on uniqueness from the two-annotator human verification step, and (4) before/after mean and median search-space sizes for the selected relations. These additions will directly support the central claims. revision: yes
-
Referee: [§4 / Table 1] Evaluation (presumably §4 and Table 1): the headline result of 34.74% accuracy and +6.8% from context strategies is only interpretable as evidence of agent limitations if the questions are confirmed to have unique answers post-human verification; without reported agreement numbers or verification details, the difficulty-ceiling claim cannot be fully assessed.
Authors: We acknowledge that the headline results are difficult to interpret without explicit verification statistics. While the paper states that all 544 questions were human-verified for uniqueness, we did not report agreement numbers or the verification protocol in §4. In the revised version we will expand the evaluation section (and add a short appendix) with the verification details, including the number of questions reviewed by each annotator, the agreement rate on answer uniqueness, and the resolution process for any disagreements. This will strengthen the evidence that the reported accuracies reflect genuine long-horizon search difficulty rather than answer ambiguity. revision: yes
Circularity Check
No circularity; benchmark is externally constructed and evaluated
full rationale
The paper introduces LoHoSearch as an externally constructed benchmark via an automated KG pipeline over Wikipedia entities, followed by human verification, then reports empirical model accuracies (e.g., 34.74%) on the resulting 544 questions. No equations, fitted parameters, or self-citations reduce these accuracy figures or the claimed difficulty gains to quantities defined inside the paper. The central claims rest on the external validity of the pipeline and the measured performance, which are independent of any internal derivation chain. This is the expected non-finding for a benchmark paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The knowledge graph covering over 7 million Wikipedia entities supplies accurate relations that allow selection of large search spaces and verification of unique answers.
Reference graph
Works this paper leans on
-
[1]
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1259
-
[2]
Ho, Xanh and Duong Nguyen, Anh-Khoa and Sugawara, Saku and Aizawa, Akiko. Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps. Proceedings of the 28th International Conference on Computational Linguistics. 2020. doi:10.18653/v1/2020.coling-main.580
-
[3]
Wei, Jason and Sun, Zhiqing and Papay, Spencer and McKinney, Scott and Han, Jeffrey and Fulford, Isa and Chung, Hyung Won and Passos, Alex Tachard and Fedus, William and Glaese, Amelia , journal=. Browse
-
[4]
♫ M u S i Q ue: Multihop Questions via Single-hop Question Composition
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish. M u S i Q ue: Multihop Questions via Single-hop Question Composition. Transactions of the Association for Computational Linguistics. 2022. doi:10.1162/tacl_a_00475
-
[5]
Peilin Zhou and Bruce Leon and Xiang Ying and Can Zhang and Yifan Shao and Qichen Ye and Dading Chong and Zhiling Jin and Chenxuan Xie and Meng Cao and Yuxin Gu and Sixin Hong and Jing Ren and Jian Chen and Chao Liu and Yining Hua , year=. Browse. 2504.19314 , archivePrefix=
-
[6]
Zhengwei Tao and Jialong Wu and Wenbiao Yin and Pu Wu and Junkai Zhang and Baixuan Li and Haiyang SHEN and Kuan Li and Liwen Zhang and Xinyu Wang and Wentao Zhang and Yong Jiang and Pengjun Xie and Fei Huang and Jingren Zhou , booktitle=. Web. 2026 , url=
2026
-
[7]
Kuan Li and Zhongwang Zhang and Huifeng Yin and Liwen Zhang and Litu Ou and Jialong Wu and Wenbiao Yin and Baixuan Li and Zhengwei Tao and Xinyu Wang and Weizhou Shen and Junkai Zhang and Dingchu Zhang and Xixi Wu and Yong Jiang and Ming Yan and Pengjun Xie and Fei Huang and Jingren Zhou , year=. Web. 2507.02592 , archivePrefix=
-
[8]
Kuan Li and Zhongwang Zhang and Huifeng Yin and Rui Ye and Yida Zhao and Liwen Zhang and Litu Ou and Ding-Chu Zhang and Xixi Wu and Xinmiao Yu and Jialong Wu and Xinyu Wang and Zile Qiao and Zhen Zhang and Yong Jiang and Pengjun Xie and Fei Huang and Zhi-Qin John Xu and Shuai Wang and Minhao Cheng and Jingren Zhou , booktitle=. Web. 2026 , url=
2026
-
[9]
Zheng Chu and Xiao Wang and Jack Hong and Huiming Fan and Yuqi Huang and Yue Yang and Guohai Xu and Chenxiao Zhao and Cheng Xiang and Shengchao Hu and Dongdong Kuang and Ming Liu and Bing Qin and Xing Yu , year=. 2602.14234 , archivePrefix=
-
[10]
Proceedings of the Conference on Parsing and Linguistic Theories (CPAL) , year =
Amanlou, Mohammad and. Proceedings of the Conference on Parsing and Linguistic Theories (CPAL) , year =
-
[11]
Zihong Chen and Wanli Jiang and Jinzhe Li and Zhonghang Yuan and Huanjun Kong and Wanli Ouyang and Nanqing Dong , year=. Graph. 2505.20416 , archivePrefix=
-
[12]
Robertson, Alex and Liang, Huizhi and Gani, Mahbub and Kumar, Rohit and Rajamohan, Srijith. KGH alu B ench: A Knowledge Graph-Based Hallucination Benchmark for Evaluating the Breadth and Depth of LLM Knowledge. Findings of the A ssociation for C omputational L inguistics: EACL 2026. 2026. doi:10.18653/v1/2026.findings-eacl.206
-
[13]
The Web as a Knowledge-Base for Answering Complex Questions
Talmor, Alon and Berant, Jonathan. The Web as a Knowledge-Base for Answering Complex Questions. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. doi:10.18653/v1/N18-1059
-
[14]
The Twelfth International Conference on Learning Representations , year=
Gr. The Twelfth International Conference on Learning Representations , year=
-
[15]
Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation
Krishna, Satyapriya and Krishna, Kalpesh and Mohananey, Anhad and Schwarcz, Steven and Stambler, Adam and Upadhyay, Shyam and Faruqui, Manaal. Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Lan...
-
[16]
2026 , url=
Ryan Wong and Jiawei Wang and Junjie Zhao and Li Chen and Yan Gao and Long Zhang and Xuan Zhou and Zuo Wang and Kai Xiang and Ge Zhang and Wenhao Huang and Yang Wang and Ke Wang , booktitle=. 2026 , url=
2026
-
[17]
DeepSeek-AI , year =
-
[18]
arXiv preprint arXiv:2210.03629 , year=
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
-
[19]
arXiv preprint arXiv:2509.13313 , year=
Resum: Unlocking long-horizon search intelligence via context summarization , author=. arXiv preprint arXiv:2509.13313 , year=
-
[20]
2026 , eprint=
Kimi K2: Open Agentic Intelligence , author=. 2026 , eprint=
2026
-
[21]
GLM-5-Team and : and Aohan Zeng and Xin Lv and Zhenyu Hou and Zhengxiao Du and Qinkai Zheng and Bin Chen and Da Yin and Chendi Ge and Chenghua Huang and Chengxing Xie and Chenzheng Zhu and Congfeng Yin and Cunxiang Wang and Gengzheng Pan and Hao Zeng and Haoke Zhang and Haoran Wang and Huilong Chen and Jiajie Zhang and Jian Jiao and Jiaqi Guo and Jingsen ...
-
[22]
LongCat-Team and Gui, Anchun and Li, Bei and Tao, Bingyang and Zhou, Bole and Chen, Borun and Zhang, Chao and Gao, Chen and Zhang, Chen and Han, Chengcheng and others , journal=. Long
-
[23]
System Card:
Anthropic , year =. System Card:
-
[24]
Introducing
OpenAI , year =. Introducing
-
[25]
Model Card:
Google DeepMind , year =. Model Card:
-
[26]
Moonshot-AI , year =
-
[27]
Communications of the ACM , pages =
Wikidata: A Free Collaborative Knowledge Base , author =. Communications of the ACM , pages =. 2014 , URL =
2014
-
[28]
DeepSeek-AI and Aixin Liu and Aoxue Mei and Bangcai Lin and Bing Xue and Bingxuan Wang and Bingzheng Xu and Bochao Wu and Bowei Zhang and Chaofan Lin and Chen Dong and Chengda Lu and Chenggang Zhao and Chengqi Deng and Chenhao Xu and Chong Ruan and Damai Dai and Daya Guo and Dejian Yang and Deli Chen and Erhang Li and Fangqi Zhou and Fangyun Lin and Fucon...
-
[29]
Nikita Gupta and Riju Chatterjee and Lukas Haas and Connie Tao and Andrew Wang and Chang Liu and Hidekazu Oiwa and Elena Gribovskaya and Jan Ackermann and John Blitzer and Sasha Goldshtein and Dipanjan Das , year=. Deep. 2601.20975 , archivePrefix=
-
[30]
Ryan Wong and Jiawei Wang and Junjie Zhao and Li Chen and Yan Gao and Long Zhang and Xuan Zhou and Zuo Wang and Kai Xiang and Ge Zhang and Wenhao Huang and Yang Wang and Ke Wang , booktitle=. Wide. 2026 , url=
2026
-
[31]
arXiv preprint arXiv:2411.04368 , year=
Measuring short-form factuality in large language models , author=. arXiv preprint arXiv:2411.04368 , year=
-
[32]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.