ESNet: An Efficient Symmetric Network for Real-time Semantic Segmentation
Pith reviewed 2026-05-25 17:48 UTC · model grok-4.3
The pith
ESNet's symmetric design of factorized and parallel convolution units enables real-time semantic segmentation with only 1.6 million parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
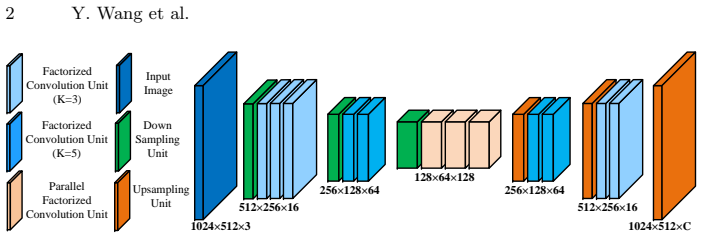
ESNet consists of a series of factorized convolution units and parallel factorized convolution units that together form a symmetric network. This design achieves state-of-the-art results in the speed and accuracy trade-off for real-time semantic segmentation on the Cityscapes dataset, with the model having nearly 1.6 million parameters and running at over 62 FPS on a GTX 1080Ti GPU.
What carries the argument
The factorized convolution unit (FCU) and parallel factorized convolution unit (PFCU), where PFCU uses a transform-split-transform-merge strategy with dilated convolutions.
If this is right
- The low parameter count supports deployment in resource-constrained environments.
- Real-time performance above 60 FPS enables applications in video analysis and autonomous systems.
- The symmetric structure maintains segmentation accuracy without excessive computation.
- Results on Cityscapes suggest the design competes favorably with existing real-time segmentation models.
Where Pith is reading between the lines
- Extending the symmetric factorized approach to other tasks like instance segmentation could yield similar efficiency gains.
- Evaluating the model on diverse hardware platforms would clarify its portability beyond the reported GTX 1080Ti setup.
- The use of dilated convolutions in parallel branches may offer insights for receptive field design in other efficient architectures.
Load-bearing premise
The assumption that performance on Cityscapes validation and test sets with one hardware setup sufficiently demonstrates superiority for real-time semantic segmentation in general.
What would settle it
Demonstrating on another dataset or hardware that an alternative network achieves a superior combination of accuracy and frames per second.
Figures


read the original abstract
The recent years have witnessed great advances for semantic segmentation using deep convolutional neural networks (DCNNs). However, a large number of convolutional layers and feature channels lead to semantic segmentation as a computationally heavy task, which is disadvantage to the scenario with limited resources. In this paper, we design an efficient symmetric network, called (ESNet), to address this problem. The whole network has nearly symmetric architecture, which is mainly composed of a series of factorized convolution unit (FCU) and its parallel counterparts (PFCU). On one hand, the FCU adopts a widely-used 1D factorized convolution in residual layers. On the other hand, the parallel version employs a transform-split-transform-merge strategy in the designment of residual module, where the split branch adopts dilated convolutions with different rate to enlarge receptive field. Our model has nearly 1.6M parameters, and is able to be performed over 62 FPS on a single GTX 1080Ti GPU. The experiments demonstrate that our approach achieves state-of-the-art results in terms of speed and accuracy trade-off for real-time semantic segmentation on CityScapes dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ESNet, a symmetric encoder-decoder network for real-time semantic segmentation. The architecture is built from factorized convolution units (FCU) that apply 1D factorized convolutions within residual blocks and parallel factorized convolution units (PFCU) that follow a transform-split-transform-merge pattern using dilated convolutions at multiple rates to expand receptive fields. The authors state that the resulting model contains approximately 1.6 million parameters and achieves more than 62 FPS on a GTX 1080Ti GPU while attaining state-of-the-art speed-accuracy trade-off on the Cityscapes dataset.
Significance. If the reported Cityscapes results hold, the work supplies a concrete, low-parameter architecture that improves the speed-accuracy frontier for real-time segmentation. The explicit parameter count and single-GPU FPS figure, together with the modular FCU/PFCU design, constitute a reproducible engineering contribution that can be directly compared against other lightweight segmentation models.
minor comments (2)
- [Abstract] Abstract: the claim of 'state-of-the-art results' is not accompanied by any numerical accuracy metric (e.g., mIoU); adding the key quantitative numbers would allow readers to evaluate the trade-off immediately.
- [Abstract] The description of the PFCU 'transform-split-transform-merge' strategy is terse; a short diagram or one-sentence statement of how the split branches are recombined before the residual addition would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of ESNet, the recognition of its engineering contribution, and the recommendation for minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The paper is an empirical architecture proposal describing FCU/PFCU residual modules for semantic segmentation. No equations, fitted parameters, predictions, or derivation chains appear in the provided text. Claims rest on external experimental benchmarks (Cityscapes FPS/accuracy) rather than any self-referential reduction. Self-citations, if present, are not load-bearing for any central result.
Axiom & Free-Parameter Ledger
free parameters (2)
- dilation rates in PFCU
- channel widths and block counts
axioms (2)
- domain assumption Factorized 1D convolutions preserve sufficient representational power for segmentation
- domain assumption Transform-split-transform-merge with parallel dilated branches improves accuracy without harming speed
Reference graph
Works this paper leans on
- [1]
- [2]
- [3]
-
[4]
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. IEEE TPAMI 39 (2017) 640–651
work page 2017
-
[5]
IEEE TPAMI 40 (2018) 834–848 ESNet for Real-time Semantic Segmentation 11
Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE TPAMI 40 (2018) 834–848 ESNet for Real-time Semantic Segmentation 11
work page 2018
- [6]
- [7]
-
[8]
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
Badrinarayanan, V., Alex, K., Roberto, C.: Segnet: A deep convolutional encoder- decoder architecture for image segmentation. arXiv preprint arXiv:1511.00561 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
- [9]
- [10]
- [11]
- [12]
-
[13]
IEEE TPAMI 40 (2018) 1352–1366
Lin, G.S., Shen, C.H., Van, D.H., Reid, I.: Exploring context with deep structured models for semantic segmentation. IEEE TPAMI 40 (2018) 1352–1366
work page 2018
-
[14]
Cong, D., Zhou, Q., Chen, J., Wu, X., Zhang, S., Ou, W., Lu, H.: Can: Contextual aggregating network for semantic segmentation. In: ICASSP. (2019) accepted
work page 2019
-
[15]
CGNet: A Light-weight Context Guided Network for Semantic Segmentation
Wu, T.Y., Tang, S., Zhang, R., Zhang, Y.D.: Cgnet: A light-weight context guided network for semantic segmentation. In: arXiv preprint arXiv:1811.08201v1. (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[16]
Treml, M., Arjona-Medina, J., Mayr, A., Heusel, M., Widrich, M., Bodenhofer, U., Nessler, B., Hochreiter, S.: Speeding up semantic segmentation for autonomous driving. In: NIPS Workshop. (2016) 1–7
work page 2016
-
[17]
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
Paszke, A., Chaurasia, A., Kim, S., Culurciello, E.: Enet: A deep neural network architecture for real-time semantic segmentation. In: arXiv preprint arXiv:1606.02147. (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[18]
ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation
Mehta, S., Rastegari, M., Caspi, A., Shapiro, L., Hajishirzi, H.: Espnet: Effi- cient spatial pyramid of dilated convolutions for semantic segmentation. In: arXiv preprint arXiv:1803.06815v3. (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Romera, E., Alvarez, J.M., Bergasa, L.M., Arroyo, R.: Erfnet: Efficient residual factorized convnet for real-time semantic segmentation. IEEE TITS 19 (2018) 263–272
work page 2018
- [20]
-
[21]
IEEE TPAMI 35 (2013) 1915–1929
Farabet, C., Couprie, C., Najman, L., LeCun, Y.: Learning hierarchical features for scene labeling. IEEE TPAMI 35 (2013) 1915–1929
work page 2013
- [22]
-
[23]
Rethinking Atrous Convolution for Semantic Image Segmentation
Liang-Chieh, C., George, P., F., S., H., A.: Rethinking atrous convolution for semantic image segmentation. In: arXiv:1706.05587. (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Multi-Scale Context Aggregation by Dilated Convolutions
Yu, F., Koltun, V.: Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
Ronneberger, O., Philipp, F., Thomas, B.: U-net: Convolutional networks for biomedical image segmentation. In: MICCAI. (2015) 225–233 12 Y. Wang et al
work page 2015
- [26]
- [27]
-
[28]
Everingham, M., Eslami, S.A., Van Gool, L., Williams, C.K., Winn, J., Zisserman, A.: The pascal visual object classes challenge: A retrospective. IJCV 111 (2015) 98–136
work page 2015
-
[29]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., W.Wang, Weyand, T., An- dreetto, M., Adam, H.: Mobilenets: efficient convolutional neural networks for mobile vision applications. In: arXiv preprint arXiv:1704.04861. (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [30]
- [31]
- [32]
- [33]
-
[34]
BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation
Changqian, Y., Jingbo, W., Chao, P., Changxin, G., Gang, Y., Nong, S.: Bisenet: Bilateral segmentation network for real-time semantic segmentation. In: arXiv preprint arXiv:1808.00897. (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[35]
ICNet for Real-Time Semantic Segmentation on High-Resolution Images
Zhao, H.S., Qi, X.J., Shen, X.Y., Shi, J.P., Jia, J.Y.: Icnet for real-time semantic segmentation on high-resolution images. In: arXiv preprint arXiv:1704.08545v2. (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [36]
-
[37]
Zhang, X., Cheny, Z., Wu, Q.M.J., Cai, L., Lu, D., Li, X.: Fast semantic segmen- tation for scene perception. IEEE TII (2019) accepted
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.