MemoryWAM: Efficient World Action Modeling with Persistent Memory
Pith reviewed 2026-06-26 16:58 UTC · model grok-4.3
The pith
MemoryWAM equips world action models with a hybrid persistent memory of recent frames, event anchors, and gist tokens to handle long-horizon robotic tasks efficiently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
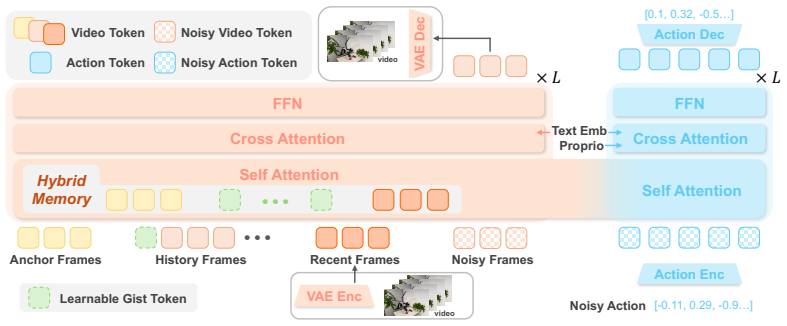
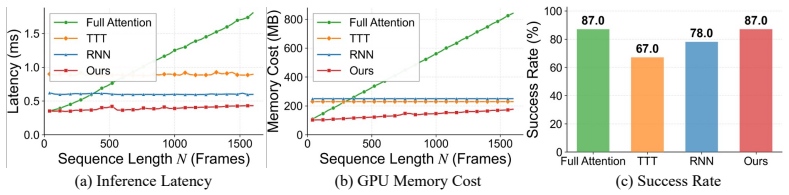
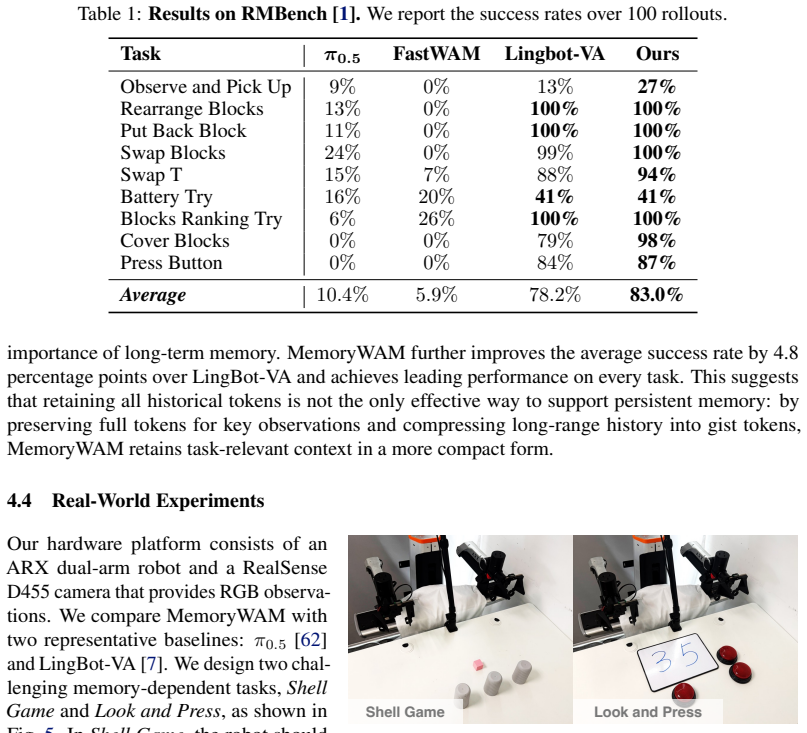
MemoryWAM uses a hybrid memory design that combines recent frames, event-boundary anchor frames, and compact gist tokens that summarize long-range history. A tailored attention mechanism enables retrieval of both detailed short-term context and compressed long-term context, supporting memory-dependent decision-making with reduced inference latency and GPU memory usage. Across long-horizon, memory-dependent manipulation tasks in both simulation and the real world, MemoryWAM outperforms strong vision-language-action and WAM baselines while maintaining favorable computational efficiency.
What carries the argument
Hybrid memory of recent frames plus event-boundary anchor frames plus compact gist tokens, retrieved via a tailored attention mechanism that separates short-term detail from long-term compression.
If this is right
- The same memory structure can be used on any long-horizon task whose required history fits inside the gist-token budget.
- Inference cost stays roughly constant even as the total number of past observations grows.
- Real-robot deployment becomes practical for tasks that previously forced either short memory or slow full-history models.
- The approach is compatible with existing vision-language-action pipelines by swapping only the memory module.
Where Pith is reading between the lines
- The same hybrid store could be tested on non-robotics sequential problems such as long video understanding where only certain events matter.
- If gist tokens prove too lossy on some tasks, the design suggests a natural next step of making the number of gist tokens task-adaptive rather than fixed.
- Real-world success already reported implies the method tolerates sensor noise better than pure long-context transformers that overfit to exact pixel history.
Load-bearing premise
The chosen mix of recent frames, event-boundary anchors, and gist tokens plus the tailored attention is enough to recover every fact the robot needs for its decisions without losing anything critical.
What would settle it
A long sequence in which success requires recalling a visual detail from before the first anchor frame that the gist tokens also fail to preserve, causing MemoryWAM to choose a wrong action while a full-history model succeeds.
Figures



read the original abstract
Robust robotic manipulation in the real world requires not only an understanding of the current observation, but also memory and dynamics modeling. World action models (WAMs) possess these capabilities by jointly modeling visual foresight and actions conditioned on both current and historical observations, making them a promising paradigm for robotic manipulation. However, existing WAMs face a fundamental trade-off: methods with efficient inference typically condition only on a bounded window of recent observations and therefore struggle in non-Markovian environments, whereas methods that preserve long histories incur time and space costs that grow substantially with sequence length. To address this challenge, we introduce MemoryWAM, a world action model with efficient persistent memory. MemoryWAM uses a hybrid memory design that combines recent frames, event-boundary anchor frames, and compact gist tokens that summarize long-range history. A tailored attention mechanism enables retrieval of both detailed short-term context and compressed long-term context, supporting memory-dependent decision-making with reduced inference latency and GPU memory usage. Across long-horizon, memory-dependent manipulation tasks in both simulation and the real world, MemoryWAM outperforms strong vision-language-action (VLA) and WAM baselines while maintaining favorable computational efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MemoryWAM, a world action model with persistent memory for robotic manipulation. It proposes a hybrid memory architecture combining recent frames, event-boundary anchor frames, and compact gist tokens, paired with a tailored attention mechanism, to jointly model visual foresight and actions while avoiding the efficiency penalties of full history conditioning. The central empirical claim is that this design enables outperformance over strong VLA and WAM baselines on long-horizon, memory-dependent tasks in both simulation and the real world while preserving favorable inference latency and GPU memory usage.
Significance. If the experimental results hold, the work would be significant because it directly targets the core efficiency-memory trade-off in world action models, a recognized limitation when operating in non-Markovian environments. The hybrid memory construction offers a concrete, implementable route to long-range context retrieval without linear growth in cost, which could improve robustness in real-world manipulation. The paper explicitly positions its experiments as a test of whether the proposed components suffice for memory-dependent decisions.
major comments (1)
- [Abstract] Abstract: the central claim of outperformance and efficiency gains is asserted without any quantitative results, baseline descriptions, error bars, dataset details, or experimental protocol. This absence prevents evaluation of the empirical contribution that the hybrid memory design is sufficient for the stated tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of outperformance and efficiency gains is asserted without any quantitative results, baseline descriptions, error bars, dataset details, or experimental protocol. This absence prevents evaluation of the empirical contribution that the hybrid memory design is sufficient for the stated tasks.
Authors: We agree that the abstract would benefit from including key quantitative highlights to better support the claims and facilitate evaluation. In the revised version, we will update the abstract to concisely report representative results (e.g., success rates on memory-dependent tasks, baseline comparisons, and efficiency metrics) drawn from the experiments detailed in Sections 4 and 5, while preserving the abstract's length constraints. The main text already contains full experimental protocols, error bars, and dataset descriptions. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces an empirical architecture (hybrid memory with recent frames, event-boundary anchors, gist tokens, and tailored attention) for world action modeling and evaluates it on long-horizon robotic tasks. No equations, derivations, or first-principles claims are present that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The central claim is an empirical performance statement tested via experiments, not a mathematical reduction. Any self-citations are incidental and non-load-bearing for the architecture or results.
Axiom & Free-Parameter Ledger
invented entities (2)
-
event-boundary anchor frames
no independent evidence
-
compact gist tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
T. Chen, Y . Wang, M. Li, Y . Qin, H. Shi, Z. Li, Y . Hu, Y . Zhang, K. Wang, Y . Chen, et al. Rmbench: Memory-dependent robotic manipulation benchmark with insights into policy design. arXiv preprint arXiv:2603.01229, 2026
arXiv 2026
-
[2]
A. Brohan, N. Brown, J. Carbajal, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control.arXiv preprint arXiv:2307.15818, 2023
Pith/arXiv arXiv 2023
-
[3]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[4]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[5]
J. Bjorck, F. Castañeda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[6]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: A diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
Pith/arXiv arXiv 2024
-
[7]
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, Y . Shen, and Y . Xu. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
Pith/arXiv arXiv 2026
-
[8]
H. Luo, W. Zhang, Y . Feng, S. Zheng, H. Xu, C. Xu, Z. Xi, Y . Fu, and Z. Lu. Being-h0.7: A latent world-action model from egocentric videos.arXiv preprint arXiv:2605.00078, 2026
Pith/arXiv arXiv 2026
-
[9]
R. A. Team. Causal video models are data-efficient robot policy learners.Rhoda AI Blog, 2026
2026
-
[10]
H. Bi, H. Tan, S. Xie, Z. Wang, S. Huang, H. Liu, et al. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
Pith/arXiv arXiv 2025
-
[11]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
Pith/arXiv arXiv 2026
-
[12]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, and J. Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning. arXiv preprint arXiv:2601.16163, 2026
Pith/arXiv arXiv 2026
-
[13]
T. Ma, J. Zheng, Z. Wang, C. Jiang, A. Cui, J. Liang, and S. Yang. Dit4dit: Jointly modeling video dynamics and actions for generalizable robot control.arXiv preprint arXiv:2603.10448, 2026
arXiv 2026
-
[14]
T. Yuan, Z. Dong, Y . Liu, and H. Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
Pith/arXiv arXiv 2026
-
[15]
A. Ye, B. Wang, C. Ni, G. Huang, G. Zhao, H. Li, et al. Gigaworld-policy: An efficient action-centered world–action model.arXiv preprint arXiv:2603.17240, 2026
arXiv 2026
-
[16]
J. Guo, Q. Li, P. Li, Z. Chen, N. Sun, Y . Su, H. Wang, Y . Zhang, X. Li, and H. Liu. Unified 4d world action modeling from video priors with asynchronous denoising.arXiv preprint arXiv:2604.26694, 2026
Pith/arXiv arXiv 2026
-
[17]
M. Team, C. Xiang, F. Bao, H. Liu, H. Tan, H. Bi, J. Li, J. Liu, J. Pang, K. Jing, et al. Motubrain: An advanced world action model for robot control.arXiv preprint arXiv:2604.27792, 2026
Pith/arXiv arXiv 2026
-
[18]
R. C. Atkinson and R. M. Shiffrin. Human memory: A proposed system and its control processes. InThe Psychology of Learning and Motivation, volume 2, pages 89–195. Academic Press, 1968. 10
1968
-
[19]
A. D. Baddeley and G. Hitch. Working memory. InPsychology of Learning and Motivation, volume 8, pages 47–89. Academic Press, 1974
1974
-
[20]
C. J. Brainerd and V . F. Reyna.The Science of False Memory. Oxford University Press, 2005
2005
-
[21]
J. M. Zacks, N. K. Speer, K. M. Swallow, T. S. Braver, and J. R. Reynolds. Event perception: A mind-brain perspective.Psychological Bulletin, 133(2):273–293, 2007
2007
-
[22]
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[23]
Galaxea g0: Open-world dataset and dual-system vision-language-action model
Galaxea Team. Galaxea g0: Open-world dataset and dual-system vision-language-action model. arXiv preprint arXiv:2509.00576, 2025
arXiv 2025
-
[24]
P. Li, Y . Chen, H. Wu, X. Ma, X. Wu, Y . Huang, L. Wang, T. Kong, and T. Tan. BridgeVLA: Input-output alignment for efficient 3d manipulation learning with vision-language models. arXiv preprint arXiv:2506.07961, 2025
arXiv 2025
-
[25]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang, and X. Li. SpatialVLA: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
Pith/arXiv arXiv 2025
-
[26]
J. Wen, Y . Zhu, J. Li, Z. Tang, C. Shen, and F. Feng. Dexvla: Vision-language model with plug-in diffusion expert for general robot control.arXiv preprint arXiv:2502.05855, 2025
Pith/arXiv arXiv 2025
-
[27]
O. X.-E. Collaboration. Open x-embodiment: Robotic learning datasets and rt-x models.arXiv preprint arXiv:2310.08864, 2023
Pith/arXiv arXiv 2023
-
[28]
A. Khazatsky and et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
Pith/arXiv arXiv 2024
-
[29]
Z. Zhang, Z. Li, B. Rahmati, R. H. Yang, Y . Ma, et al. Do world action models generalize better than vlas? a robustness study.arXiv preprint arXiv:2603.22078, 2026
Pith/arXiv arXiv 2026
-
[30]
Y . Du, M. Yang, B. Dai, H. Dai, O. Nachum, J. B. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation. InAdvances in Neural Information Processing Systems, 2023
2023
-
[31]
Y . Feng, H. Tan, X. Mao, G. Liu, S. Huang, C. Xiang, H. Su, and J. Zhu. Vidar: Embodied video diffusion model for generalist bimanual manipulation.arXiv preprint arXiv:2507.12898, 2025
Pith/arXiv arXiv 2025
-
[32]
H. Bharadhwaj, D. Dwibedi, A. Gupta, S. Tulsiani, C. Doersch, T. Xiao, D. Shah, F. Xia, D. Sadigh, and S. Kirmani. Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation.arXiv preprint arXiv:2409.16283, 2024
Pith/arXiv arXiv 2024
-
[33]
S. Zhou, Y . Du, J. Chen, Y . Li, D.-Y . Yeung, and C. Gan. Robodreamer: Learning compositional world models for robot imagination.arXiv preprint arXiv:2404.12377, 2024
Pith/arXiv arXiv 2024
-
[34]
Y . Hu, Y . Guo, P. Wang, X. Chen, Y .-J. Wang, J. Zhang, K. Sreenath, C. Lu, and J. Chen. Video prediction policy: A generalist robot policy with predictive visual representations.arXiv preprint arXiv:2412.14803, 2024
Pith/arXiv arXiv 2024
-
[35]
Y . Tian, S. Yang, J. Zeng, P. Wang, D. Lin, H. Dong, and J. Pang. Predictive inverse dynamics models are scalable learners for robotic manipulation.arXiv preprint arXiv:2412.15109, 2024
Pith/arXiv arXiv 2024
-
[36]
J. Pai, L. Achenbach, V . Montesinos, B. Forrai, O. Mees, and E. Nava. mimic-video: Video- action models for generalizable robot control beyond vlas.arXiv preprint arXiv:2512.15692, 2025. 11
Pith/arXiv arXiv 2025
-
[37]
J. Liang, P. Tokmakov, R. Liu, S. Sudhakar, P. Shah, R. Ambrus, and C. V ondrick. Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
Pith/arXiv arXiv 2025
-
[38]
Y . Su, S. Chen, H. Shi, M. Liu, Z. Zhang, N. Huang, W. Zhong, Z. Zhu, Y . Liu, and X. Liu. World guidance: World modeling in condition space for action generation.arXiv preprint arXiv:2602.22010, 2026
arXiv 2026
-
[39]
C.-L. Cheang, G. Chen, Y . Jing, T. Kong, H. Li, Y . Li, Y . Liu, H. Wu, J. Xu, Y . Yang, H. Zhang, and M. Zhu. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158, 2024
Pith/arXiv arXiv 2024
-
[40]
S. Li, V . Yao, C. Yang, T. Qu, R. Cheng, R. Yu, H. Lu, N. V on, V . Chen, Y . Tang, et al. Wall-wm: Carving world action modeling at the event joints.arXiv preprint arXiv:2606.01955, 2026
Pith/arXiv arXiv 2026
-
[41]
J. L. Elman. Finding structure in time.Cognitive Science, 14(2):179–211, 1990
1990
-
[42]
S. Hochreiter and J. Schmidhuber. Long short-term memory.Neural Computation, 9(8): 1735–1780, 1997. doi:10.1162/neco.1997.9.8.1735
-
[43]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, 2017
2017
-
[44]
Katharopoulos, A
A. Katharopoulos, A. Vyas, N. Pappas, and F. Fleuret. Transformers are RNNs: Fast autore- gressive transformers with linear attention. InProceedings of the International Conference on Machine Learning, 2020
2020
-
[45]
Schlag, K
I. Schlag, K. Irie, and J. Schmidhuber. Linear transformers are secretly fast weight programmers. InProceedings of the International Conference on Machine Learning, 2021
2021
-
[46]
S. Yang, J. Kautz, and A. Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule. InInternational Conference on Learning Representations, volume 2025, pages 29687–29707, 2025
2025
-
[47]
Y . Sun, X. Li, K. Dalal, J. Xu, A. Vikram, G. Zhang, Y . Dubois, X. Chen, X. Wang, S. Koyejo, T. Hashimoto, and C. Guestrin. Learning to (learn at test time): RNNs with expressive hidden states. InProceedings of the International Conference on Machine Learning, 2025
2025
-
[48]
J. Zhang, C. Herrmann, J. Hur, C. Sun, M.-H. Yang, F. Cole, T. Darrell, and D. Sun. LoGeR: Long-context geometric reconstruction with hybrid memory.arXiv preprint arXiv:2603.03269, 2026
Pith/arXiv arXiv 2026
-
[49]
T. Xie, P. Yang, Y . Jin, Y . Cai, W. Yin, W. Ren, Q. Zhang, W. Hua, S. Peng, X. Guo, and X. Zhou. Scal3R: Scalable test-time training for large-scale 3d reconstruction.arXiv preprint arXiv:2604.08542, 2026
Pith/arXiv arXiv 2026
-
[50]
L.-Z. Chen, J. Gao, Y . Chen, K. L. Cheng, Y . Sun, L. Hu, N. Xue, X. Zhu, Y . Shen, Y . Yao, and Y . Xu. Geometric context transformer for streaming 3d reconstruction.arXiv preprint arXiv:2604.14141, 2026
Pith/arXiv arXiv 2026
-
[51]
Zhang, S
L. Zhang, S. Cai, M. Li, G. Wetzstein, and M. Agrawala. Frame context packing and drift prevention in next-frame-prediction video diffusion models.Advances in Neural Information Processing Systems, 38:30546–30566, 2026
2026
-
[52]
J. Yu, J. Bai, Y . Qin, Q. Liu, X. Wang, P. Wan, D. Zhang, and X. Liu. Context as memory: Scene-consistent interactive long video generation with memory retrieval. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–11, 2025. 12
2025
-
[53]
Dalal, D
K. Dalal, D. Koceja, J. Xu, Y . Zhao, S. Han, K. C. Cheung, J. Kautz, Y . Choi, Y . Sun, and X. Wang. One-minute video generation with test-time training. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17702–17711, 2025
2025
-
[54]
T. Zhang, S. Bi, Y . Hong, K. Zhang, F. Luan, S. Yang, K. Sunkavalli, W. T. Freeman, and H. Tan. Test-time training done right.arXiv preprint arXiv:2505.23884, 2025
Pith/arXiv arXiv 2025
- [55]
-
[56]
H. Shi, B. Xie, Y . Liu, L. Sun, F. Liu, T. Wang, E. Zhou, H. Fan, X. Zhang, and G. Huang. Mem- oryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation. arXiv preprint arXiv:2508.19236, 2025
Pith/arXiv arXiv 2025
-
[57]
H. Li, F. Shen, D. Chen, L. Yang, X. Wang, J. Shi, Z. Bing, Z. Liu, and A. Knoll. Remem-vla: Empowering vision-language-action model with memory via dual-level recurrent queries.arXiv preprint arXiv:2603.12942, 2026
arXiv 2026
-
[58]
A. Sridhar, J. Pan, S. Sharma, and C. Finn. Memer: Scaling up memory for robot control via experience retrieval.arXiv preprint arXiv:2510.20328, 2025
arXiv 2025
-
[59]
H. Li, S. Yang, Y . Chen, Y . Tian, X. Yang, X. Chen, H. Wang, T. Wang, F. Zhao, D. Lin, et al. Cronusvla: Transferring latent motion across time for multi-frame prediction in manipulation. arXiv e-prints, pages arXiv–2506, 2025
2025
-
[60]
Y . Gao, J. Liu, S. Li, and S. Song. Gated memory policy.arXiv preprint arXiv:2604.18933, 2026
Pith/arXiv arXiv 2026
-
[61]
H. Lei, W. Song, H. Zhang, J. Pei, J. Chen, H. Yan, H. Zhao, P. Ding, Z. Zhang, L. Huang, et al. Robomemarena: A comprehensive and challenging robotic memory benchmark.arXiv preprint arXiv:2605.10921, 2026
Pith/arXiv arXiv 2026
-
[62]
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al. π0.5: A vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[63]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, J. Zeng, J. Wang, J. Zhang, J. Zhou, J. Wang, J. Chen, K. Zhu, K. Zhao, K. Yan, L. Huang, M. Feng, N. Zhang, P. Li, P. Wu, R. Chu, R. Feng, S. Zhang, S. Sun, T. Fang, T. Wang, T. Gui, T. Weng, T. Shen, W. Lin, W. Wang, W. Wang, W. Zhou, W. Wang, W. Shen, W. Yu, X. Shi, X....
Pith/arXiv arXiv 2025
-
[64]
W. Liang, L. Yu, L. Luo, S. Iyer, N. Dong, C. Zhou, G. Ghosh, M. Lewis, W.-t. Yih, L. Zettle- moyer, et al. Mixture-of-transformers: A sparse and scalable architecture for multi-modal foundation models.arXiv preprint arXiv:2411.04996, 2024
Pith/arXiv arXiv 2024
-
[65]
Huang, Z
X. Huang, Z. Li, G. He, M. Zhou, and E. Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion. InAdvances in Neural Information Processing Systems, 2025
2025
-
[66]
L. X. Shi, B. Ichter, M. Equi, L. Ke, K. Pertsch, Q. Vuong, J. Tanner, A. Walling, H. Wang, N. Fusai, et al. Hi robot: Open-ended instruction following with hierarchical vision-language- action models.arXiv preprint arXiv:2502.19417, 2025
Pith/arXiv arXiv 2025
-
[67]
A. Figure. Helix: A vision-language-action model for generalist humanoid control.Figure AI News, 2024
2024
-
[68]
C. Deng, D. Zhu, K. Li, C. Gou, F. Li, Z. Wang, S. Zhong, W. Yu, X. Nie, Z. Song, G. Shi, and H. Fan. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025. 13 A Appendix A.1 Implementation Details Training setup.Training is conducted in bfloat16 mixed precision with FSDP, activation checkpoint- ing on every DiT block...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.