Scaling Dense Retrieval with LLM-Annotated Training Data: Structured Mining and Progressive Curriculum for E-Commerce Sponsored Search
Pith reviewed 2026-06-26 06:09 UTC · model grok-4.3
The pith
LLM cascade annotates 240M examples from retrieval disagreements to train a two-tower model that beats click-trained baselines by 5.1% NDCG@10 in sponsored search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
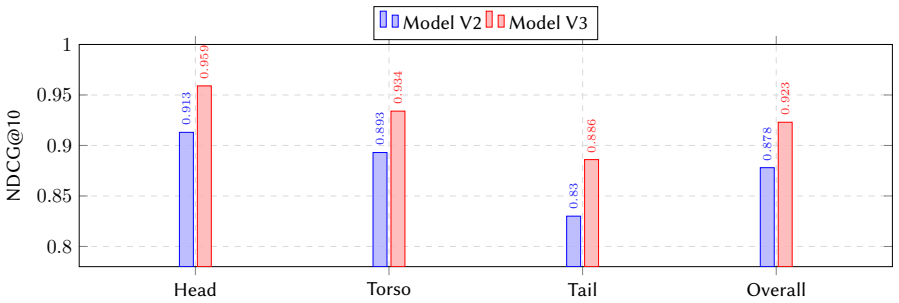
Mining easy and hard positives and negatives from three production retrieval systems, grading them with a three-model LLM cascade, and training a two-tower BERT model with three-stage progressive curriculum on over 240 million examples yields +5.1% NDCG@10 over the click-trained production baseline, drops zero-relevance results from 8.7% to 3.5%, and delivers +2.80% ad spend, +1.4% CTR, +2.8% eCPM, and +2.9% click conversion rate in a two-week online test.
What carries the argument
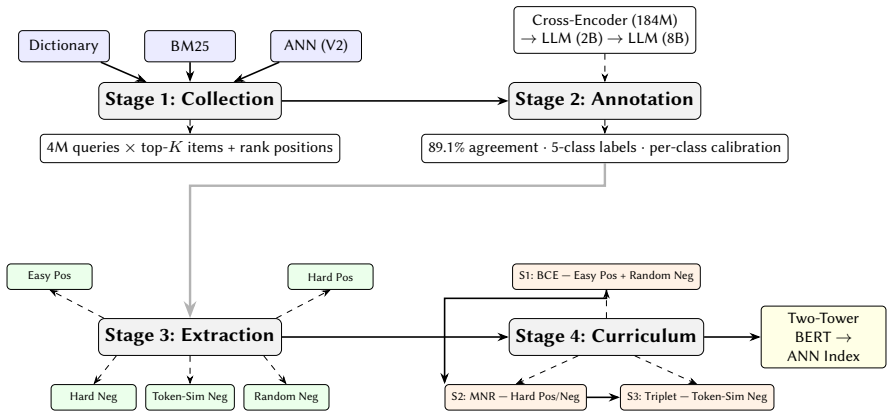
Multi-channel retrieval mining that extracts rank metadata from three systems, combined with graded-relevance annotation by a calibrated three-model LLM cascade and three-stage progressive curriculum training that organizes examples across five difficulty levels.
If this is right
- The largest gains occur on tail queries where click data is sparsest.
- Embarrassing zero-relevance retrievals fall from 8.7% to 3.5%.
- The same pipeline produces measurable lifts in ad spend, CTR, eCPM, and conversion rate during live traffic.
- Progressive curriculum training across five difficulty levels organizes the mined data effectively for the final model.
Where Pith is reading between the lines
- The same disagreement-mining step could supply training data for dense retrieval in domains other than e-commerce sponsored search.
- If the LLM cascade maintains its agreement rate on new query distributions, the approach could reduce dependence on click logs across additional retrieval settings.
- Replacing the three production systems with a different set of heterogeneous retrievers would test how sensitive the structured signal is to the choice of source systems.
Load-bearing premise
The three-model LLM cascade's 89.1% agreement with trained human annotators yields labels of high enough quality to produce the observed retrieval gains.
What would settle it
Train an otherwise identical two-tower model on the same 240M examples but with human labels instead of the LLM cascade and measure whether NDCG@10 and online metrics remain at or above the reported levels.
Figures
read the original abstract
How can we generate high-quality training data for dense retrieval models at production scale, without relying on click signals or manual annotation? This question is critical for e-commerce sponsored search, where click-based training suffers from position bias and tail-query sparsity, and manual labeling at the scale of hundreds of millions of query-item pairs is economically infeasible. Our work is driven by the following insight: heterogeneous retrieval systems disagree on most items they retrieve, and this disagreement creates a natural source of structured training signal -- easy positives where all systems agree, hard positives that only lexical systems find, and hard negatives that fool exactly one system. As our key novelty, we combine three ideas into an end-to-end pipeline: (a) multi-channel retrieval mining with rank metadata from three production systems, (b) graded-relevance annotation by a calibrated three-model cascade ) that reaches 89.1% agreement with trained human annotators, and (c) three-stage progressive curriculum training that organizes 240M+ training examples across five difficulty levels. We deploy the trained two-tower BERT model on Walmart's sponsored search and evaluate it against 30K queries labeled by trained third-party human annotators. First, we show that the system achieves +5.1% NDCG@10 over the click-trained production baseline, with the largest gain on tail queries . Second, we show that embarrassing retrievals (rating 0) drop from 8.7% to 3.5%. Third, a two-week online A/B test with tens of millions of ad requests per arm confirms +2.80% ad spend, +1.4% CTR, +2.8% eCPM, and +2.9% click conversion rate. Overall, our work provides a practical and scalable blueprint for replacing click-based training with structured LLM-annotated supervision in production retrieval systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that structured mining of disagreements across three production retrieval systems, combined with graded annotation from a calibrated three-model LLM cascade (89.1% human agreement) and three-stage progressive curriculum training on 240M+ examples, enables a two-tower BERT dense retriever to outperform a click-trained production baseline by +5.1% NDCG@10 on a 30K human-annotated query set (largest gains on tail queries, embarrassing retrievals reduced from 8.7% to 3.5%), with corresponding gains (+2.80% ad spend, +1.4% CTR, +2.8% eCPM, +2.9% conversion) confirmed in a two-week production A/B test.
Significance. If the end-to-end empirical results hold, the work supplies a practical, scalable alternative to click-based supervision for production sponsored-search retrieval, directly addressing position bias and tail sparsity while demonstrating measurable offline and online improvements. The structured-mining-plus-curriculum approach and the independent human-labeled test set plus live A/B validation are notable strengths.
major comments (2)
- [Method (mining and annotation pipeline)] The central claim rests on the quality of the LLM-generated labels, yet the manuscript provides insufficient detail on the exact mining rules, cascade calibration procedure, and data exclusion criteria used to reach the reported 89.1% human agreement; without these, it is difficult to assess whether the label-generation process is reproducible or whether the observed gains could be replicated.
- [Offline Evaluation] The offline evaluation reports +5.1% NDCG@10 and the drop in rating-0 retrievals on the 30K human-annotated set, but the manuscript does not report statistical significance tests, confidence intervals, or variance estimates for these metrics; this weakens the strength of the cross-system comparison.
minor comments (2)
- [Abstract] The abstract states the three-stage curriculum organizes examples across five difficulty levels; a one-sentence clarification of how the five levels map to the three stages would improve readability.
- [Training Curriculum] Table or figure presenting the per-difficulty-level breakdown of the 240M training examples would help readers understand the curriculum composition.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, recognition of the practical contributions, and recommendation for minor revision. We address the two major comments below and will incorporate the requested additions into the revised manuscript.
read point-by-point responses
-
Referee: [Method (mining and annotation pipeline)] The central claim rests on the quality of the LLM-generated labels, yet the manuscript provides insufficient detail on the exact mining rules, cascade calibration procedure, and data exclusion criteria used to reach the reported 89.1% human agreement; without these, it is difficult to assess whether the label-generation process is reproducible or whether the observed gains could be replicated.
Authors: We agree that greater detail on the annotation pipeline is needed for reproducibility. In the revised manuscript we will expand the relevant methods section to specify: (i) the exact multi-system mining rules (items retrieved by all three systems as easy positives, by exactly one lexical system as hard positives, and by exactly one neural system as hard negatives, with rank-position thresholds); (ii) the cascade calibration procedure (three-model ensemble with majority vote, temperature scaling on a 2k human-labeled calibration set, and per-grade precision/recall); and (iii) exclusion criteria (queries with <5 candidates, LLM confidence below 0.7, and items with missing metadata). These additions will occupy approximately one page and directly address replicability concerns. revision: yes
-
Referee: [Offline Evaluation] The offline evaluation reports +5.1% NDCG@10 and the drop in rating-0 retrievals on the 30K human-annotated set, but the manuscript does not report statistical significance tests, confidence intervals, or variance estimates for these metrics; this weakens the strength of the cross-system comparison.
Authors: We concur that statistical reporting strengthens the claims. In the revision we will add bootstrap (10k resamples) 95% confidence intervals and paired significance tests (Wilcoxon signed-rank) for both NDCG@10 and the rating-0 rate on the 30k set. The observed +5.1% NDCG@10 and reduction from 8.7% to 3.5% remain significant (p < 0.001) under these tests; the intervals will be reported alongside the point estimates in Table 2 and the text. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents an empirical pipeline for generating LLM-annotated training data and evaluates the resulting two-tower BERT model directly against an independent 30K human-annotated query set (showing +5.1% NDCG@10) plus a live two-week A/B test on production traffic (showing lifts in ad spend, CTR, eCPM, and conversion). No equations, derivations, or load-bearing claims reduce to fitted parameters by construction, self-citations, or ansatzes imported from prior author work; the 89.1% cascade-human agreement is presented only as supporting context for label quality, not as the source of the reported gains. All central results are measured on external benchmarks outside the training labels themselves.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Heterogeneous retrieval systems disagree on most items they retrieve, creating natural easy positives, hard positives, and hard negatives.
- domain assumption An LLM cascade calibrated to 89.1% human agreement supplies training labels of adequate quality for the reported gains.
Reference graph
Works this paper leans on
-
[1]
The role of relevance in sponsored search
Luca Maria Aiello, Ioannis Arapakis, Ricardo Baeza-Yates, Xiao Bai, Nicola Barbieri, Amin Mantrach, and Fabrizio Silvestri. The role of relevance in sponsored search. InProceedings of the 25th ACM International Conference on Information and Knowledge Management, pages 185–194, 2016
2016
-
[2]
Curriculum learning
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, pages 41–48, 2009
2009
-
[3]
InPars: Data augmentation for information retrieval using large language models
Luiz Bonifacio, Hugo Abonizio, Marzieh Fadaee, and Rodrigo Nogueira. InPars: Data augmentation for information retrieval using large language models. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2316–2320, 2022
2022
-
[4]
Lingjiao Chen, Matei Zaharia, and James Zou. FrugalGPT: How to use large language models while reducing cost and improving performance.arXiv preprint arXiv:2305.05176, 2023
Pith/arXiv arXiv 2023
-
[5]
Deep neural networks for YouTube recommendations
Paul Covington, Jay Adams, and Emre Sargin. Deep neural networks for YouTube recommendations. InProceedings of the 10th ACM Conference on Recommender Systems, 2016
2016
-
[6]
Promptagator: Few-shot dense retrieval from 8 examples
Zhuyun Dai, Arun Tejasvi Chaganty, Vincent Y Zhao, Aida Rashid, Mike Green, and Kelvin Guu. Promptagator: Few-shot dense retrieval from 8 examples. InInternational Conference on Learning Representations, 2023
2023
-
[7]
Shasvat Desai, Md Omar Faruk Rokon, Jhalak Nilesh Acharya, Isha Shah, Hong Yao, Utkarsh Porwal, and Kuang-chih Lee. Unified supervision for walmarts sponsored search retrieval via joint semantic relevance and behavioral engagement modeling.arXiv preprint arXiv:2604.07930, 2026
Pith/arXiv arXiv 2026
-
[8]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding.arXiv preprint arXiv:1810.04805, 2019
Pith/arXiv arXiv 2019
-
[9]
Perspectives on large language models for relevance judgment
Guglielmo Faggioli, Laura Dietz, Charles Clarke, Gianluca Demartini, Matthias Hagen, Claudia Hauff, Noriko Kando, Evangelos Kanoulas, Martin Potthast, Benno Stein, and Henning Wachsmuth. Perspectives on large language models for relevance judgment. InProceedings of the 2023 ACM SIGIR International Conference on the Theory of Information Retrieval, pages 3...
2023
-
[10]
MOBIUS: Towards the next generation of query-ad matching in Baidu’s sponsored search
Miao Fan, Jiacheng Guo, Shuai Zhu, Shuo Miao, Mingming Sun, and Ping Li. MOBIUS: Towards the next generation of query-ad matching in Baidu’s sponsored search. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 2509–2517, 2019
2019
-
[11]
SPLADE: Sparse lexical and expansion model for first stage ranking
Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. SPLADE: Sparse lexical and expansion model for first stage ranking. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2288–2292, 2021
2021
-
[12]
Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[13]
Sebastian Hofstätter, Sophia Althammer, Michael Schröder, Mete Sertkan, and Allan Hanbury. Improving efficient neural ranking models with cross-architecture knowledge distillation.arXiv preprint arXiv:2010.02666, 2020
arXiv 2010
-
[14]
Embedding-based retrieval in Facebook search
Jui-Ting Huang, Ashish Sharma, Shuying Sun, Li Xia, David Zhang, Philip Pronin, Janani Padman- abhan, Giuseppe Ottaviano, and Linjun Yang. Embedding-based retrieval in Facebook search. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 2553–2561, 2020
2020
-
[15]
Learning deep structured semantic models for web search using clickthrough data
Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. Learning deep structured semantic models for web search using clickthrough data. InACM International Conference on Information and Knowledge Management (CIKM), 2013
2013
-
[16]
Cumulated gain-based evaluation of IR techniques.ACM Transactions on Information Systems, 20(4):422–446, 2002
Kalervo Järvelin and Jaana Kekäläinen. Cumulated gain-based evaluation of IR techniques.ACM Transactions on Information Systems, 20(4):422–446, 2002
2002
-
[17]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, 2020
2020
-
[18]
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281, 2023
Pith/arXiv arXiv 2023
-
[19]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2019
Pith/arXiv arXiv 2019
-
[20]
Semantic retrieval at Walmart
Alessandro Magnani, Feng Liu, Suthee Chaidaroon, Sachin Yadav, Praveen Reddy Suram, Ajit Puthenputhussery, Sijie Chen, Min Xie, Anirudh Kashi, Tony Lee, et al. Semantic retrieval at Walmart. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3495–3503, 2022
2022
-
[21]
Distant supervision for relation extraction without labeled data
Mike Mintz, Steven Bills, Rion Snow, and Daniel Jurafsky. Distant supervision for relation extraction without labeled data. InProceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, pages 1003–1011, 2009
2009
-
[22]
Learning with noisy labels
Nagarajan Natarajan, Inderjit S Dhillon, Pradeep K Ravikumar, and Ambuj Tewari. Learning with noisy labels. InAdvances in Neural Information Processing Systems (NeurIPS), 2013
2013
-
[23]
Semantic product search
Priyanka Nigam, Yiwei Song, Vijai Mohan, Vihan Lakshman, Weitian Ding, Ankit Shingavi, Choon Hui Teo, Hao Gu, and Bing Yin. Semantic product search. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 2876–2885, 2019
2019
-
[24]
RocketQA: An optimized training approach to dense passage retrieval for open-domain question answering
Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu, and Haifeng Wang. RocketQA: An optimized training approach to dense passage retrieval for open-domain question answering. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics, pages 5835–5847, 2021
2021
-
[25]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning (ICML), 2021
2021
-
[26]
Shopping queries dataset: A large-scale ESCI benchmark for improving product search
Chandan K Reddy, Lluís Màrquez, Fran Valero, Nikhil Rao, Hugo Zaragoza, Sambaran Bandyopad- hyay, Arnab Biswas, Anlu Xing, and Karthik Subbian. Shopping queries dataset: A large-scale ESCI benchmark for improving product search. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 4429–4439, 2022
2022
-
[27]
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using siamese BERT- networks.arXiv preprint arXiv:1908.10084, 2019
Pith/arXiv arXiv 1908
-
[28]
Making monolingual sentence embeddings multilingual using knowledge distillation
Nils Reimers and Iryna Gurevych. Making monolingual sentence embeddings multilingual using knowledge distillation. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020
2020
-
[29]
The probabilistic relevance framework: BM25 and beyond
Stephen Robertson and Hugo Zaragoza. The probabilistic relevance framework: BM25 and beyond. Foundations and Trends in Information Retrieval, 3(4):333–389, 2009
2009
-
[30]
Contrastive learning with hard negative samples
Joshua Robinson, Ching-Yao Chuang, Suvrit Sra, and Stefanie Jegelka. Contrastive learning with hard negative samples. InInternational Conference on Learning Representations, 2021
2021
-
[31]
Enhancement of e-commerce sponsored search relevancy with LLM
Md Omar Faruk Rokon, Andrei Simion, Weizhi Du, Musen Wen, Hong Yao, and Kuang-chih Lee. Enhancement of e-commerce sponsored search relevancy with LLM. InProceedings of the SIGIR Workshop on eCommerce (eCom’24), 2024
2024
-
[32]
Deep learning is robust to massive label noise.arXiv preprint arXiv:1705.10694, 2017
David Rolnick, Andreas Veit, Serge Belongie, and Nir Shavit. Deep learning is robust to massive label noise.arXiv preprint arXiv:1705.10694, 2017
Pith/arXiv arXiv 2017
-
[33]
User intent, behaviour, and perceived satisfaction in product search
Ning Su, Jiyin He, Yiqun Liu, Min Zhang, and Shaoping Ma. User intent, behaviour, and perceived satisfaction in product search. InProceedings of the Eleventh ACM International Conference on Web Search and Data Mining, pages 547–555, 2018
2018
-
[34]
BEIR: A heterogeneous benchmark for zero-shot evaluation of information retrieval models
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. BEIR: A heterogeneous benchmark for zero-shot evaluation of information retrieval models. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2021
2021
-
[35]
Large language models can accurately predict searcher preferences
Paul Thomas, Seth Spielman, Nick Craswell, and Bhaskar Mitra. Large language models can accurately predict searcher preferences. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1930–1940, 2024
1930
-
[36]
Text embeddings by weakly-supervised contrastive pre-training.arXiv preprint arXiv:2212.03533, 2022
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training.arXiv preprint arXiv:2212.03533, 2022
Pith/arXiv arXiv 2022
-
[37]
Click- conversion multi-task model with position bias mitigation for sponsored search in ecommerce
Yuanxing Wang, Yaqing Xue, Buyun Liu, Musen Wen, Wenjia Zhao, and Song Guo. Click- conversion multi-task model with position bias mitigation for sponsored search in ecommerce. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2023
2023
-
[38]
Zhaodong Wang, Weizhi Du, Md Omar Faruk Rokon, Prabir Adhikary, Yaqing Xue, Jian Xu, Jingyi Zhou, Kuang-chih Lee, and Musen Wen. Semantic ads retrieval at Walmart ecommerce with language models progressively trained on multiple knowledge domains.arXiv preprint arXiv:2502.09089, 2025
arXiv 2025
-
[39]
C-Pack: Packed resources for general Chinese embeddings.arXiv preprint arXiv:2309.07597, 2023
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-Pack: Packed resources for general Chinese embeddings.arXiv preprint arXiv:2309.07597, 2023
Pith/arXiv arXiv 2023
-
[40]
Approximate nearest neighbor negative contrastive learning for dense text retrieval
Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul Bennett, Junaid Ahmed, and Arnold Overwijk. Approximate nearest neighbor negative contrastive learning for dense text retrieval. InInternational Conference on Learning Representations, 2021
2021
-
[41]
Optimizing dense retrieval model training with hard negatives
Jingtao Zhan, Jiaxin Mao, Yiqun Liu, Jiafeng Guo, Min Zhang, and Shaoping Ma. Optimizing dense retrieval model training with hard negatives. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1503–1512, 2021
2021
-
[42]
Judging LLM-as-a-Judge with MT-Bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P Xing, Hao Zhang, Joseph E Gonzalez, and Ion Stoica. Judging LLM-as-a-Judge with MT-Bench and chatbot arena. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.