DINO-GFSA: Geo-Localization via Semantic Gated Fusion and Mamba-based Sequential Aggregation
Pith reviewed 2026-06-28 19:05 UTC · model grok-4.3
The pith
DINO-GFSA uses a LoRA-adapted DINOv3 backbone plus a semantic gated fusion module and Mamba aggregation head to reach state-of-the-art accuracy on cross-view UAV geo-localization benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
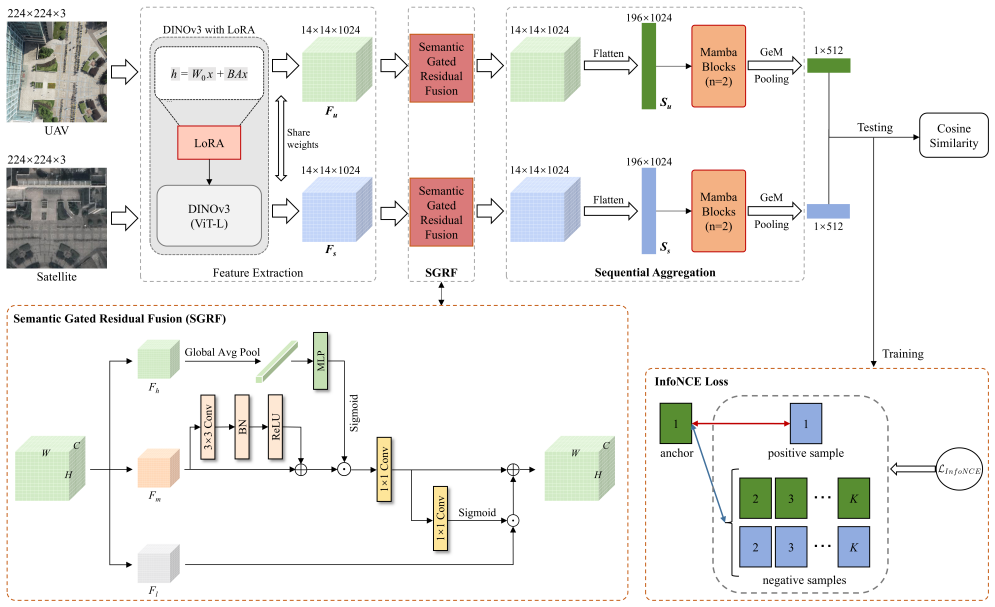
DINO-GFSA demonstrates that a parameter-efficient DINOv3 backbone, when paired with a Semantic Gated Residual Fusion module that calibrates low-level spatial cues using high-level semantics and a Mamba-based Sequential Aggregation Head that captures long-range dependencies linearly, produces state-of-the-art cross-view geo-localization performance on University-1652 and DenseUAV, exceeding the prior best Recall@1 on DenseUAV by 3.48 percent.
What carries the argument
The Semantic Gated Residual Fusion module, which uses high-level semantics to selectively calibrate and integrate low-level spatial cues, together with the Mamba-based Sequential Aggregation Head that models long-range spatial dependencies at linear complexity.
If this is right
- The framework supplies a practical, parameter-efficient pipeline for UAV positioning in GNSS-denied settings.
- The gated fusion step directly addresses the semantic gap between drone and satellite imagery.
- Mamba aggregation replaces heavier attention mechanisms while preserving long-range modeling.
- The same architecture reaches top scores on both University-1652 and the more challenging DenseUAV benchmark.
Where Pith is reading between the lines
- If the gated fusion proves robust, similar selective-calibration blocks could be inserted into other cross-view or multi-resolution vision pipelines.
- Linear-complexity Mamba heads may allow longer image sequences or higher-resolution inputs without the quadratic cost of transformers in geo-localization tasks.
- The reported lift on DenseUAV suggests the method could scale to denser urban or varied terrain scenarios where fine spatial detail matters most.
Load-bearing premise
The performance gains come from the fusion and aggregation modules generalizing rather than from unstated benchmark tuning or data choices.
What would settle it
An independent run on the University-1652 and DenseUAV test sets that fails to match or exceed the reported Recall@1 numbers under the same evaluation protocol.
Figures


read the original abstract
Cross-view geo-localization (CVGL) is critical for Unmanned Aerial Vehicle (UAV) self-positioning and target localization in GNSS-denied environments. However, acquiring robust semantics while preserving finegrained spatial details remains challenging. To address this, we propose DINO-GFSA, a framework leveraging a LoRA (Low-Rank Adaptation) adapted DINOv3 (ViTL) backbone for parameter-efficient, high-capacity representation. Crucially, we introduce a Semantic Gated Residual Fusion module, which utilizes high-level semantics to selectively calibrate and integrate low-level spatial cues, effectively bridging the semantic gap. Furthermore, a Mamba-based Sequential Aggregation Head is designed to capture long-range spatial dependencies with linear complexity. Experiments demonstrate state-of-the-art performance on University-1652 and DenseUAV benchmarks, notably surpassing the previous best on DenseUAV by 3.48% on Recall@1. These results validate DINO-GFSA as a generalized, robust solution for UAV CVGL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DINO-GFSA for cross-view geo-localization (CVGL), employing a LoRA-adapted DINOv3 (ViT-L) backbone, a Semantic Gated Residual Fusion module to calibrate low-level spatial cues with high-level semantics, and a Mamba-based Sequential Aggregation Head to model long-range dependencies at linear complexity. It claims state-of-the-art results on the University-1652 and DenseUAV benchmarks, including a 3.48% Recall@1 gain over the prior best on DenseUAV.
Significance. If the reported gains can be rigorously attributed to the proposed modules via controlled experiments, the work would offer a parameter-efficient approach to bridging semantic-spatial gaps in UAV CVGL while maintaining computational scalability. No machine-checked proofs, reproducible code, or parameter-free derivations are present to credit.
major comments (1)
- [Abstract] Abstract: The central claim of SOTA performance and a specific 3.48% Recall@1 improvement on DenseUAV is presented without any experimental protocol, baseline re-implementations, data splits, augmentation details, hyper-parameters, or ablation results. This absence makes it impossible to determine whether the numerical gains arise from the Semantic Gated Residual Fusion or Mamba head rather than the LoRA-DINOv3 backbone or unstated choices, directly undermining the load-bearing empirical contribution.
Simulated Author's Rebuttal
We thank the referee for the feedback on the abstract. We address the concern point-by-point below, noting that the full manuscript contains the requested experimental details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of SOTA performance and a specific 3.48% Recall@1 improvement on DenseUAV is presented without any experimental protocol, baseline re-implementations, data splits, augmentation details, hyper-parameters, or ablation results. This absence makes it impossible to determine whether the numerical gains arise from the Semantic Gated Residual Fusion or Mamba head rather than the LoRA-DINOv3 backbone or unstated choices, directly undermining the load-bearing empirical contribution.
Authors: The abstract is a concise summary (as is standard) and does not duplicate the full experimental protocol. Section 4 of the manuscript details the experimental setup, including data splits for University-1652 and DenseUAV, augmentation strategies, hyper-parameters, baseline re-implementations with the same LoRA-DINOv3 backbone, and ablation studies that isolate the contributions of the Semantic Gated Residual Fusion module and Mamba-based Sequential Aggregation Head. These controlled experiments attribute the 3.48% Recall@1 gain on DenseUAV to the proposed modules rather than the backbone alone. We can revise the abstract to include a brief clause referencing the experimental section for clarity. revision: partial
Circularity Check
No derivation chain or first-principles claims present; purely empirical architecture proposal
full rationale
The paper introduces architectural components (LoRA-adapted DINOv3 backbone, Semantic Gated Residual Fusion module, Mamba-based Sequential Aggregation Head) and reports empirical SOTA results on University-1652 and DenseUAV benchmarks. No equations, mathematical derivations, predictions from first principles, or parameter-fitting steps that could reduce to inputs by construction appear in the abstract or described content. Performance numbers are presented as experimental outcomes without any claimed derivation that could be self-definitional, fitted-input-called-prediction, or dependent on self-citation chains. The absence of a derivation chain means no circularity of the enumerated kinds can be identified.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Uav-assisted disas- ter management: Applications and open issues,
M. Erdelj and E. Natalizio, “Uav-assisted disas- ter management: Applications and open issues,” in 2016 International Conference on Computing, Net- working and Communications (ICNC), 2016, pp. 1– 5
2016
-
[2]
University- 1652: A multi-view multi-source benchmark for drone-based geo-localization,
Z. Zheng, Y. Wei, and Y. Yang, “University- 1652: A multi-view multi-source benchmark for drone-based geo-localization,” inProceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 1395–1403
2020
-
[3]
Sues-200: A multi-height multi-scene cross-view image benchmark across drone and satel- lite,
R. Zhu, L. Yin, M. Yang, F. Wu, Y. Yang, and W. Hu, “Sues-200: A multi-height multi-scene cross-view image benchmark across drone and satel- lite,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 9, pp. 4825–4839, 2023
2023
-
[4]
Vision-based uav self-positioning in low- altitude urban environments,
M. Dai, E. Zheng, Z. Feng, L. Qi, J. Zhuang, and W. Yang, “Vision-based uav self-positioning in low- altitude urban environments,”IEEE Transactions on Image Processing, vol. 33, pp. 493–508, 2023
2023
-
[5]
Uav-geoloc: A large-vocabulary dataset and geometry-transformed method for uav geo-localization,
R. Wu, J. Deng, M. Mou, X. He, M. Zhang, Y. Liu, and S. Yan, “Uav-geoloc: A large-vocabulary dataset and geometry-transformed method for uav geo-localization,”IEEE Robotics and Automation Letters, 2025
2025
-
[6]
Deep resid- ual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep resid- ual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778
2016
-
[7]
Enhancing cross-view geo-localization with do- main alignment and scene consistency,
P. Xia, Y. Wan, Z. Zheng, Y. Zhang, and J. Deng, “Enhancing cross-view geo-localization with do- main alignment and scene consistency,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 12, pp. 13271–13281, 2024
2024
-
[8]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy et al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[9]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, et al., “Di- nov2: Learning robust visual features without su- pervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Dinov2-based uav visual self-localization in low- altitude urban environments,
J. Yang, D. Qin, H. Tang, S. Tao, H. Bie, and L. Ma, “Dinov2-based uav visual self-localization in low- altitude urban environments,”IEEE Robotics and Automation Letters, 2025
2025
-
[11]
Representation Learning with Contrastive Predictive Coding
A. van den Oord, Y. Li, and O. Vinyals, “Represen- tation learning with contrastive predictive coding,” arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
O. Sim´ eoni, H. V. Vo, M. Seitzer, et al., “Dinov3,” arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Feature pyramid networks for object detection,
T. Y. Lin, P. Doll´ ar, R. Girshick, K. He, B. Hari- haran, and S. Belongie, “Feature pyramid networks for object detection,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recog- nition (CVPR), 2017, pp. 2117–2125
2017
-
[14]
Fine- tuning cnn image retrieval with no human annota- tion,
F. Radenovi´ c, G. Tolias, and O. Chum, “Fine- tuning cnn image retrieval with no human annota- tion,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 7, pp. 1655–1668, 2018
2018
-
[15]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y. Shen, P. Wallis, et al., “Lora: Low-rank adaptation of large language models,”International Conference on Learning Representations (ICLR), vol. 1, no. 2, pp. 3, 2022
2022
-
[16]
Mamba: Linear-time sequence modeling with selective state spaces,
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” inFirst Con- ference on Language Modeling, 2024
2024
-
[17]
Swin transformer: Hierarchical vision transformer using shifted win- dows,
Z. Liu, Y. Lin, Y. Cao, et al., “Swin transformer: Hierarchical vision transformer using shifted win- dows,” inProceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV), 2021, pp. 10012–10022
2021
-
[18]
Shaa: Spatial hybrid attention net- work with adaptive cross-entropy loss function for uav-view geo-localization,
N. Chen, D. Zhang, K. Jiang, Y. Meng, W. Zhang, and Z. Wang, “Shaa: Spatial hybrid attention net- work with adaptive cross-entropy loss function for uav-view geo-localization,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[19]
R2ploc: A region-to-point uav visual geo-localization frame- work leveraging hierarchical semantic representa- tion,
Bin Tang, Ruitao Lu, Xiaogang Yang, Yansheng Li, Yunsong Li, and Dingwen Zhang, “R2ploc: A region-to-point uav visual geo-localization frame- work leveraging hierarchical semantic representa- tion,”IEEE Transactions on Geoscience and Re- mote Sensing, 2025
2025
-
[20]
Squeeze-and- excitation networks,
J. Hu, L. Shen, and G. Sun, “Squeeze-and- excitation networks,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recog- nition (CVPR), 2018, pp. 7132–7141
2018
-
[21]
Language modeling with gated convolutional net- works,
Y. N. Dauphin, A. Fan, M. Auli, and D. Grangier, “Language modeling with gated convolutional net- works,” inProceedings of the International Confer- ence on Machine Learning (ICML). PMLR, 2017, pp. 933–941
2017
-
[22]
Each part matters: Lo- cal patterns facilitate cross-view geo-localization,
T. Wang, Z. Zheng, et al., “Each part matters: Lo- cal patterns facilitate cross-view geo-localization,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 2, pp. 867–879, 2021. 7
2021
-
[23]
Sam- ple4geo: Hard negative sampling for cross-view geo- localisation,
F. Deuser, K. Habel, and N. Oswald, “Sam- ple4geo: Hard negative sampling for cross-view geo- localisation,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 16801–16810
2023
-
[24]
Mccg: A convnext-based multiple-classifier method for cross-view geo localization,
T. Shen, Y. Wei, L. Kang, S. Wan, and Y.-H. Yang, “Mccg: A convnext-based multiple-classifier method for cross-view geo localization,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 3, pp. 1456–1468, 2024
2024
-
[25]
Sdpl: Shifting-dense parti- tion learning for uav-view geo-localization,
Q. Chen et al., “Sdpl: Shifting-dense parti- tion learning for uav-view geo-localization,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 11, pp. 11810–11824, 2024
2024
-
[26]
Ccr: A counterfactual causal reasoning based method for cross-view geo- localization,
H. Du, J. He, and Y. Zhao, “Ccr: A counterfactual causal reasoning based method for cross-view geo- localization,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 11, pp. 11630–11643, 2024
2024
-
[27]
Multi- level embedding and alignment network with con- sistency and invariance learning for cross-view geo- localization,
Z. Chen, Z. X. Yang, and H. J. Rong, “Multi- level embedding and alignment network with con- sistency and invariance learning for cross-view geo- localization,”IEEE Transactions on Geoscience and Remote Sensing, 2025
2025
-
[28]
A faster and more effective cross-view matching method of uav and satellite images for uav geolo- calization,
J. Zhuang, M. Dai, X. Chen, and E. Zheng, “A faster and more effective cross-view matching method of uav and satellite images for uav geolo- calization,”Remote Sensing, vol. 13, no. 19, pp. 3979, 2021
2021
-
[29]
A transformer-based feature segmentation and region alignment method for uav-view geo-localization,
M. Dai, J. Hu, J. Zhuang, and E. Zheng, “A transformer-based feature segmentation and region alignment method for uav-view geo-localization,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 7, pp. 4376–4389, 2022. 8
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.