Methodology for the Automated Metadata-Based Classification of Incriminating Digital Forensic Artefacts
Pith reviewed 2026-05-25 11:09 UTC · model grok-4.3
The pith
Supervised machine learning on file metadata from past cases recommends which artifacts are likely suspicious in new digital forensic investigations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that by extracting metadata features from file artifacts and applying supervised machine learning trained on the outcomes of earlier investigations, a system can predict which new artifacts are likely to be incriminating, thereby automating prioritization while keeping final decisions with the human analyst.
What carries the argument
A supervised machine learning classifier that uses metadata features from historical case results to score the likelihood an artifact is suspicious.
If this is right
- Forensic examiners could review a much smaller subset of files first while still catching relevant evidence.
- The approach can be added to existing investigation workflows through the described disk image extraction toolkit.
- As more cases are completed, the training data grows and the recommendations can improve over time.
- Investigators gain a way to handle increasing data volumes without a matching rise in manual review hours.
Where Pith is reading between the lines
- Similar metadata-based models might transfer to related high-volume review tasks such as e-discovery in legal cases.
- If metadata alone proves too noisy, future extensions could test adding lightweight content hashes without full file parsing.
- Labs could pool anonymized case outcomes to build shared models while preserving case confidentiality.
Load-bearing premise
Metadata patterns observed in past cases will continue to mark suspicious files in new and different investigations.
What would settle it
Running the trained model on a fresh case dataset where it consistently assigns low suspicion scores to files that manual review later confirms as central evidence.
Figures
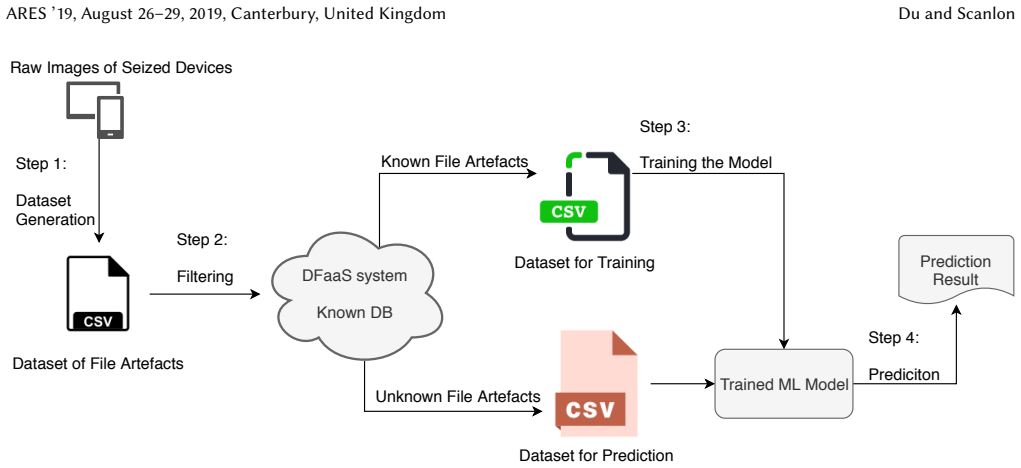

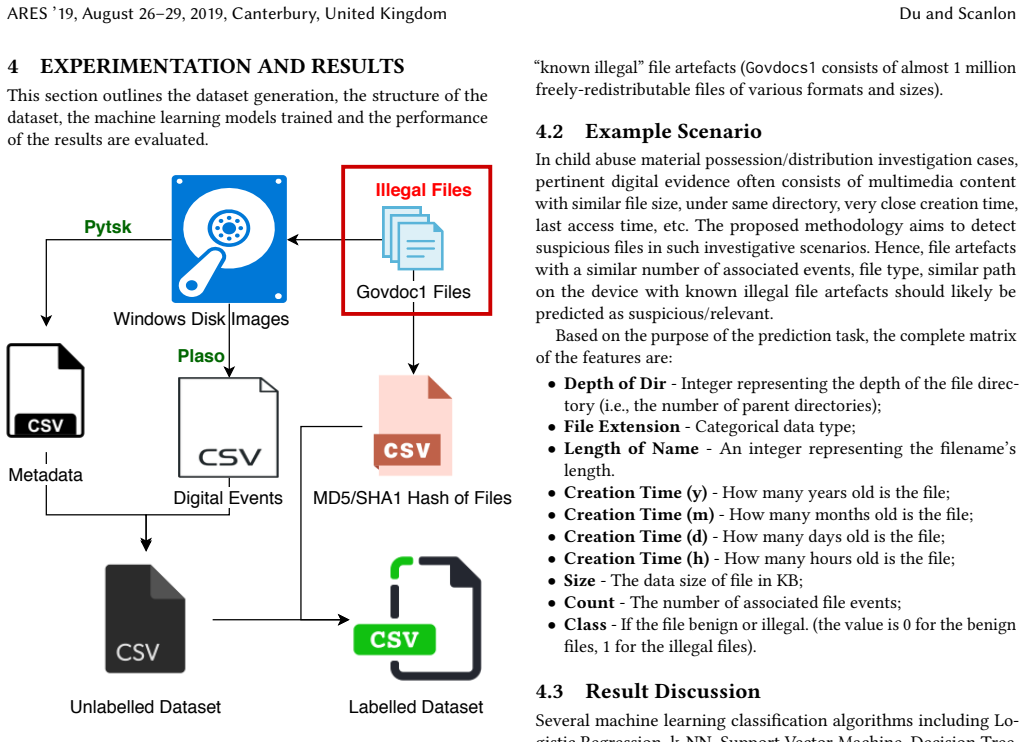
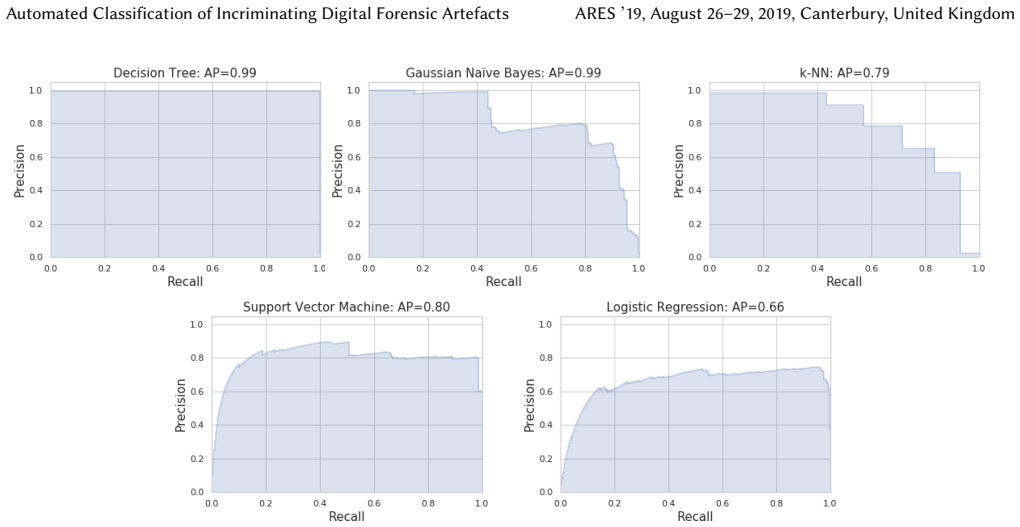
read the original abstract
The ever increasing volume of data in digital forensic investigation is one of the most discussed challenges in the field. Usually, most of the file artefacts on seized devices are not pertinent to the investigation. Manually retrieving suspicious files relevant to the investigation is akin to finding a needle in a haystack. In this paper, a methodology for the automatic prioritisation of suspicious file artefacts (i.e., file artefacts that are pertinent to the investigation) is proposed to reduce the manual analysis effort required. This methodology is designed to work in a human-in-the-loop fashion. In other words, it predicts/recommends that an artefact is likely to be suspicious rather than giving the final analysis result. A supervised machine learning approach is employed, which leverages the recorded results of previously processed cases. The process of features extraction, dataset generation, training and evaluation are presented in this paper. In addition, a toolkit for data extraction from disk images is outlined, which enables this method to be integrated with the conventional investigation process and work in an automated fashion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a supervised machine learning methodology that extracts metadata features from file artefacts in previously processed digital forensic cases, generates datasets from those results, trains models to recommend suspicious artefacts in new investigations, and includes a toolkit for automated data extraction from disk images; the system is intended to operate in a human-in-the-loop fashion to reduce manual review effort.
Significance. If the central claim holds under proper cross-case evaluation, the work would offer a practical, automatable aid for handling the volume of data in digital forensics by prioritizing relevant artefacts based on historical case outcomes.
major comments (1)
- [Dataset generation and evaluation] Dataset generation and evaluation sections: the description of training and evaluation does not specify whether train/test splits are performed across case boundaries. The core claim requires that the learned mapping from metadata features generalizes to entirely new investigations (different devices, users, OS versions); file-level splits within the same cases would instead measure within-case correlation and fail to test the required out-of-investigation transfer.
minor comments (1)
- [Abstract] Abstract: the claim that the approach 'leverages the recorded results of previously processed cases' is central but left without any quantitative indication of dataset scale, feature set, or achieved metrics, which weakens the ability to judge the presented methodology at first reading.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and will revise the manuscript to improve clarity on the evaluation protocol.
read point-by-point responses
-
Referee: [Dataset generation and evaluation] Dataset generation and evaluation sections: the description of training and evaluation does not specify whether train/test splits are performed across case boundaries. The core claim requires that the learned mapping from metadata features generalizes to entirely new investigations (different devices, users, OS versions); file-level splits within the same cases would instead measure within-case correlation and fail to test the required out-of-investigation transfer.
Authors: We agree that the manuscript does not explicitly state whether train/test splits respect case boundaries. The intended use case is generalization to new investigations, so file-level splits within cases would not suffice. In the revised version we will update the Dataset generation and evaluation sections to specify that splits are performed across case boundaries (all artefacts from any given case appear in only one partition). We will also add the number of source cases, the split ratios employed, and a brief justification that this protocol tests out-of-investigation transfer. revision: yes
Circularity Check
No circularity: standard ML pipeline with external case data
full rationale
The paper presents a supervised ML methodology that extracts metadata features from previously processed cases, generates datasets, trains models, and evaluates them to recommend suspicious artefacts. This follows conventional ML practices without any self-definitional reductions, fitted parameters renamed as predictions by construction, or load-bearing self-citations that collapse the central claim. No equations or derivations are given that equate outputs to inputs tautologically; the approach depends on external historical case data and standard training procedures, remaining self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cory Altheide and Harlan Carvey. 2011. Digital forensics with open source tools . Elsevier
work page 2011
-
[2]
Nicole Beebe. 2009. Digital forensic research: The good, the bad and the unad- dressed. In IFIP International Conference on Digital Forensics . Springer, 17–36
work page 2009
-
[3]
Andrew Case, Andrew Cristina, Lodovico Marziale, Golden G Richard, and Vassil Roussev. 2008. FACE: Automated digital evidence discovery and correlation. Digital Investigation 5 (2008), S65–S75
work page 2008
-
[4]
Eoghan Casey. 2011. Digital evidence and computer crime: Forensic science, com- puters, and the internet . Academic Press
work page 2011
-
[5]
Lei Chen, Hassan Takabi, and Nhien-An Le-Khac. 2019. Security, Privacy, and Digital Forensics in the Cloud . John Wiley & Sons
work page 2019
-
[6]
Luís Filipe da Cruz Nassif and Eduardo Raul Hruschka. 2013. Document clustering for forensic analysis: an approach for improving computer inspection. IEEE Transactions on Information Forensics and Security 8, 1 (2013), 46–54
work page 2013
-
[7]
Xiaoyu Du, Nhien-An Le-Khac, and Mark Scanlon. 2017. Evaluation of Digital Forensic Process Models with Respect to Digital Forensics as a Service. In Pro- ceedings of the 16th European Conference on Cyber Warfare and Security (ECCWS 2017). ACPI, Dublin, Ireland, 573–581
work page 2017
-
[8]
Xiaoyu Du, Paul Ledwith, and Mark Scanlon. 2018. Deduplicated Disk Image Evidence Acquisition and Forensically-Sound Reconstruction. In 2018 17th IEEE International Conference on Trust, Security and Privacy in Computing and Commu- nications/12th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE). IEEE, 1674–1679
work page 2018
-
[9]
Peter Flach. 2012. Machine learning: the art and science of algorithms that make sense of data. Cambridge University Press
work page 2012
-
[10]
Simson L Garfinkel. 2010. Digital forensics research: The next 10 years. Digital Investigation 7 (2010), S64–S73
work page 2010
-
[11]
Antonio Grillo, Alessandro Lentini, Gianluigi Me, and Matteo Ottoni. 2009. Fast user classifying to establish forensic analysis priorities. In IT Security Incident Management and IT Forensics, 2009. IMF’09. Fifth International Conference on. IEEE, 69–77
work page 2009
-
[12]
Kristinn Guðjónsson. 2010. Mastering the super timeline with log2timeline.SANS Institute (2010)
work page 2010
-
[13]
Christopher Hargreaves and Jonathan Patterson. 2012. An automated timeline reconstruction approach for digital forensic investigations. Digital Investigation 9 (2012), S69–S79
work page 2012
-
[14]
Ben Hitchcock, Nhien-An Le-Khac, and Mark Scanlon. 2016. Tiered forensic methodology model for Digital Field Triage by non-digital evidence specialists. Digital Investigation 16 (2016), S75–S85
work page 2016
-
[15]
Ronald In de Braekt, Nhien-An Le-Khac, Jason Farina, Mark Scanlon, and Mohand- Tahar Kechadi. 2016. Increasing Digital Investigator Availability through Efficient Workflow Management and Automation. (04 2016), 68–73
work page 2016
-
[16]
Bartosz Inglot, Lu Liu, and Nick Antonopoulos. 2012. A framework for enhanced timeline analysis in digital forensics. In 2012 IEEE International Conference on Green Computing and Communications . IEEE, 253–256
work page 2012
-
[17]
Michael Donovan Kohn, Mariki M Eloff, and Jan HP Eloff. 2013. Integrated digital forensic process model. Computers & Security 38 (2013), 103–115
work page 2013
-
[18]
Quan Le, Oisín Boydell, Brian Mac Namee, and Mark Scanlon. 2018. Deep learning at the shallow end: Malware classification for non-domain experts. Digital Investigation 26 (2018), S118–S126
work page 2018
-
[19]
David Lillis, Brett Becker, Tadhg O’Sullivan, and Mark Scanlon. 2016. Current Challenges and Future Research Areas for Digital Forensic Investigation. In The 11th ADFSL Conference on Digital Forensics, Security and Law (CDFSL 2016) . ADFSL, Daytona Beach, FL, USA, 9–20
work page 2016
-
[20]
Fabio Marturana and Simone Tacconi. 2013. A Machine Learning-based Triage methodology for automated categorization of digital media. Digital Investigation 10, 2 (2013), 193–204
work page 2013
-
[21]
Sebastian Neuner, Martin Mulazzani, Sebastian Schrittwieser, and Edgar Weippl
-
[22]
In 2015 10th International Con- ference on A vailability, Reliability and Security
Gradually improving the forensic process. In 2015 10th International Con- ference on A vailability, Reliability and Security. IEEE, 404–410
work page 2015
-
[23]
Sriram Raghavan and SV Raghavan. 2013. Determining the origin of downloaded files using metadata associations. Journal of Communications 8, 12 (2013), 902– 910
work page 2013
-
[24]
Marcus K Rogers, James Goldman, Rick Mislan, Timothy Wedge, and Steve Debrota. 2006. Computer forensics field triage process model. Journal of Digital Forensics, Security and Law 1, 2 (2006), 2
work page 2006
-
[25]
Neil C. Rowe and Simson L. Garfinkel. 2012. Finding Anomalous and Suspicious Files from Directory Metadata on a Large Corpus. In Digital Forensics and Cyber Crime, Pavel Gladyshev and Marcus K. Rogers (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 115–130
work page 2012
-
[26]
Mark Scanlon. 2016. Battling the Digital Forensic Backlog through Data Dedu- plication. In Proceedings of the 6th IEEE International Conference on Innovative Computing Technologies (INTECH 2016) . IEEE, Dublin, Ireland
work page 2016
-
[27]
RB Van Baar, HMA Van Beek, and EJ van Eijk. 2014. Digital Forensics as a Service: A game changer. Digital Investigation 11 (2014), S54–S62
work page 2014
-
[28]
HMA Van Beek, EJ van Eijk, RB van Baar, Mattijs Ugen, JNC Bodde, and AJ Siemelink. 2015. Digital forensics as a service: Game on. Digital Investigation 15 (2015), 20–38
work page 2015
-
[29]
Kathryn Watkins, Mike McWhorte, Jeff Long, and Bill Hill. 2009. Teleporter: An analytically and forensically sound duplicate transfer system.Digital Investigation 6 (2009), S43–S47
work page 2009
-
[30]
Shams Zawoad and Ragib Hasan. 2015. Digital forensics in the age of big data: Challenges, approaches, and opportunities. In 2015 IEEE 17th International Con- ference on High Performance Computing and Communications, 2015 IEEE 7th International Symposium on Cyberspace Safety and Security, and 2015 IEEE 12th International Conference on Embedded Software and...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.