Curvature-Guided Mixing for MLLM Adaptation
Pith reviewed 2026-06-26 00:41 UTC · model grok-4.3
The pith
A Hessian approximation of loss landscapes yields a closed-form soft mixing ratio that blends MLLM parameters by relative task curvatures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Curvature-Guided Mixing (CGM) formulates a joint optimization objective and uses a second-order (Hessian) approximation of the loss landscapes to analytically derive an optimal, closed-form soft mixing ratio that blends parameters based on their relative task-specific curvatures; a robust hard-mixing variant (CGM†) performs sparse parameter selection guided by a curvature-aware score, and both variants improve the trade-off between task specialization and general knowledge retention over existing methods on LLaVA-1.5 and Qwen2.5VL across multiple downstream tasks.
What carries the argument
The curvature-guided soft mixing ratio, obtained in closed form from the Hessian approximation of the joint loss objective, which sets blend weights for each parameter according to the relative curvatures of the pre-trained and fine-tuned loss surfaces.
Load-bearing premise
The joint optimization objective admits an analytical closed-form solution under the Hessian approximation without requiring iterative numerical optimization or post-hoc parameter tuning.
What would settle it
An experiment in which models merged using the curvature-derived ratio show no improvement, or a clear degradation, in the combined metric of task accuracy and general capability retention compared with simple averaging or other fixed-ratio heuristics would falsify the central claim.
Figures

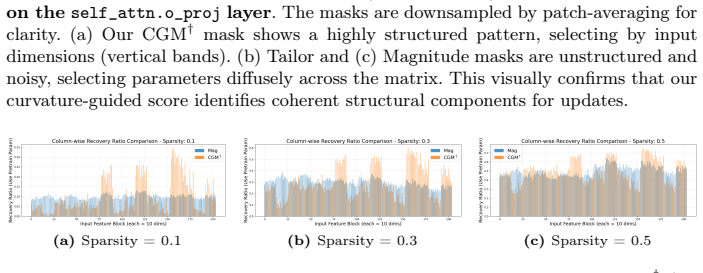
read the original abstract
Fine-tuning Multimodal Large Language Models (MLLMs) on specialized tasks often leads to catastrophic forgetting of their general capabilities. Existing model merging methods to combat this are often heuristic or use sub-optimal objectives. We propose CurvatureGuided Mixing (CGM), a theoretically grounded framework that merges pre-trained and fine-tuned models. CGM formulates a joint optimization objective and uses a second-order (Hessian) approximation of the loss landscapes to analytically derive an optimal, closed-form "soft mixing" ratio. This ratio intelligently blends parameters based on their relative task-specific curvatures. We also introduce CGM$\dagger$, a robust "hard mixing" variant that performs sparse parameter selection guided by a novel, curvature-aware score. Experiments on LLaVA-1.5 and Qwen2.5VL across multiple downstream tasks show that CGM and CGM$\dagger$ consistently improve the trade-off between task specialization and general knowledge retention over existing methods. Code is available at github.com/zzsyjl/CGM-ECCV-2026.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Curvature-Guided Mixing (CGM) to merge pre-trained and fine-tuned MLLMs, mitigating catastrophic forgetting. It formulates a joint optimization objective over the two models and applies a second-order Hessian approximation of the loss landscapes to analytically derive a closed-form 'soft mixing' ratio that blends parameters according to their relative task-specific curvatures. A sparse 'hard mixing' variant (CGM†) is also introduced using a curvature-aware selection score. Experiments on LLaVA-1.5 and Qwen2.5VL across downstream tasks report improved specialization-retention trade-offs relative to prior merging methods.
Significance. If the claimed analytical derivation is correct and produces a genuinely parameter-free closed-form ratio without iterative solvers or post-hoc adjustments, the work would supply a principled, second-order alternative to heuristic merging techniques. Reproducibility is supported by the linked code repository.
major comments (1)
- [Methods / Derivation of CGM] The central claim rests on an analytical derivation of the mixing ratio from the joint objective under Hessian approximation. The manuscript must present the complete derivation (including the joint objective, the precise form of the Hessian approximation, and the algebraic steps to the closed-form ratio) to confirm the absence of cross-parameter terms, iterative numerical optimization, or implicit tuning that would undermine the 'parameter-free' and 'analytically derived' assertions.
minor comments (2)
- [Abstract] The abstract contains a typographical error ('CurvatureGuided' should be 'Curvature-Guided').
- [Abstract] The repository link in the abstract points to a 2026 conference; confirm the target venue and update if needed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The primary concern centers on ensuring the analytical derivation of the CGM mixing ratio is fully presented to substantiate the parameter-free and closed-form claims. We agree this is essential and will expand the manuscript accordingly.
read point-by-point responses
-
Referee: [Methods / Derivation of CGM] The central claim rests on an analytical derivation of the mixing ratio from the joint objective under Hessian approximation. The manuscript must present the complete derivation (including the joint objective, the precise form of the Hessian approximation, and the algebraic steps to the closed-form ratio) to confirm the absence of cross-parameter terms, iterative numerical optimization, or implicit tuning that would undermine the 'parameter-free' and 'analytically derived' assertions.
Authors: We agree that a complete, self-contained derivation is required to rigorously support the claims. In the revised manuscript we will add (in Section 3 and/or a dedicated appendix) the full derivation: (1) the joint optimization objective over the pre-trained and fine-tuned parameter sets, (2) the precise second-order Hessian approximation employed (including whether a diagonal or block-diagonal form is used and how curvature is estimated per parameter), and (3) every algebraic step from the approximated objective to the closed-form soft-mixing ratio. This exposition will explicitly show the absence of cross-parameter coupling terms and confirm that the ratio is obtained analytically without iterative solvers or any post-hoc tuning, thereby validating the parameter-free nature of the method. revision: yes
Circularity Check
No circularity: derivation is a standard second-order approximation from stated joint objective.
full rationale
The paper formulates a joint optimization objective over pre-trained and fine-tuned parameters, then applies a Hessian approximation to derive a closed-form mixing ratio. This is a conventional analytic step in optimization literature and does not reduce to a fitted parameter renamed as prediction, self-definition, or load-bearing self-citation. No equations in the provided abstract or description exhibit the reduction patterns (self-definitional, fitted-input-called-prediction, etc.). The result remains independent of the target mixing ratio by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Loss landscapes admit a useful quadratic approximation via the Hessian matrix for the purpose of deriving mixing ratios.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2502.13923 (2025)
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
Pith/arXiv arXiv 2025
-
[2]
Annals of Operations Research134, 19–67 (2005)
de Boer, P.T., Kroese, D.P., Mannor, S., Rubinstein, R.Y.: A tutorial on the cross- entropy method. Annals of Operations Research134, 19–67 (2005)
2005
-
[3]
arXiv preprint arXiv:2411.02564 (2024)
Cao, M., Liu, Y., Liu, Y., Wang, T., Dong, J., Ding, H., Zhang, X., Reid, I., Liang, X.: Continual llava: Continual instruction tuning in large vision-language models. arXiv preprint arXiv:2411.02564 (2024)
arXiv 2024
-
[4]
In: ICML
Cen, J., Wu, C., Liu, X., Yin, S., Pei, Y., Yang, J., Chen, Q., Duan, N., Zhang, J.: Using left and right brains together: Towards vision and language planning. In: ICML. pp. 5982–6001 (2024)
2024
-
[5]
NeurIPS37, 57817–57840 (2024)
Chen, C., Zhu, J., Luo, X., Shen, H.T., Song, J., Gao, L.: Coin: A benchmark of continual instruction tuning for multimodel large language models. NeurIPS37, 57817–57840 (2024)
2024
-
[6]
In: CVPR
Chen, H., Yang, Y., Zhong, N., Ma, K.: Hiding images in diffusion models by editing learned score functions. In: CVPR. pp. 18663–18673 (2025)
2025
-
[7]
In: ICML (2023)
Frantar, E., Alistarh, D.: SparseGPT: Massive language models can be accurately pruned in one-shot. In: ICML (2023)
2023
-
[8]
In: CVPR
Goyal, Y., Khot, T., Summers-Stay, D., Batra, D., Parikh, D.: Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In: CVPR. pp. 6904–6913 (2017)
2017
-
[9]
In: CVPR
Gurari, D., Li, Q., Stangl, A.J., Guo, A., Lin, C., Grauman, K., Luo, J., Bigham, J.P.: Vizwiz grand challenge: Answering visual questions from blind people. In: CVPR. pp. 3608–3617 (2018)
2018
-
[10]
In: ICML
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Ges- mundo, A., Attariyan, M., Gelly, S.: Parameter-efficient transfer learning for nlp. In: ICML. pp. 2790–2799 (2019)
2019
-
[11]
In: ICLR (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. In: ICLR (2022)
2022
-
[12]
arXiv preprint arXiv:2503.04543 (2025)
Huang, W., Liang, J., Guo, X., Fang, Y., Wan, G., Rong, X., Wen, C., Shi, Z., Li, Q., Zhu, D., Ma, Y., Liang, K., Yang, B., Li, H., Shao, J., Ye, M., Du, B.: Keeping yourself is important in downstream tuning multimodal large language model. arXiv preprint arXiv:2503.04543 (2025)
arXiv 2025
-
[13]
In: ICML (2025)
Huang, W., Liang, J., Shi, Z., Zhu, D., Wan, G., Li, H., Du, B., Tao, D., Ye, M.: Learn from downstream and be yourself in multimodal large language model fine-tuning. In: ICML (2025)
2025
-
[14]
In: CVPR
Hudson, D.A., Manning, C.D.: Gqa: A new dataset for real-world visual reasoning and compositional question answering. In: CVPR. pp. 6700–6709 (2019)
2019
-
[15]
In: NeurIPS (2024)
Jha, S., Gong, D., Yao, L.: CLAP4CLIP: Continual learning with probabilistic finetuning for vision-language models. In: NeurIPS (2024)
2024
-
[16]
Proceedings of the National Academy of Sciences114(13), 3521–3526 (2017)
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A.A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al.: Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences114(13), 3521–3526 (2017)
2017
-
[17]
In: NeurIPS
LeCun, Y., Denker, J.S., Solla, S.A.: Optimal brain damage. In: NeurIPS. vol. 2, pp. 598–605 (1990) 16 J. Yang et al
1990
-
[18]
In: ICML (2023)
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: ICML (2023)
2023
-
[19]
In: EMNLP
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, X., Wen, J.R.: Evaluating object hallu- cination in large vision-language models. In: EMNLP. pp. 292–305 (2023)
2023
-
[20]
In: CVPR
Liang, Y.S., Li, W.J.: Inflora: Interference-free low-rank adaptation for continual learning. In: CVPR. pp. 23638–23647 (2024)
2024
-
[21]
In: CVPR (2024)
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning. In: CVPR (2024)
2024
-
[22]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., et al.: Mmbench: Is your multi-modal model an all-around player? In: ECCV. pp. 216–233 (2024)
2024
-
[23]
In: NeurIPS
Lu, P., Mishra, S., Xia, T., Qiu, L., Chang, K.W., Zhu, S.C., Tafjord, O., Clark, P., Kalyan, A.: Learn to explain: Multimodal reasoning via thought chains for science question answering. In: NeurIPS. vol. 35, pp. 2507–2521 (2022)
2022
-
[24]
In: CVPR (2025)
Luo, G., Yang, X., Dou, W., Wang, Z., Liu, J., Dai, J., Qiao, Y., Zhu, X.: Mono- internvl: Pushing the boundaries of monolithic multimodal large language models with endogenous visual pre-training. In: CVPR (2025)
2025
-
[25]
IEEE/ACM Transactions on Audio, Speech, and Language Processing33, 3776– 3786 (2025)
Luo, Y., Yang, Z., Meng, F., Li, Y., Zhou, J., Zhang, Y.: An empirical study of catastrophic forgetting in large language models during continual fine-tuning. IEEE/ACM Transactions on Audio, Speech, and Language Processing33, 3776– 3786 (2025)
2025
-
[26]
In: CVPR
Marino,K.,Rastegari,M.,Farhadi,A.,Mottaghi,R.:Ok-vqa:Avisualquestionan- swering benchmark requiring external knowledge. In: CVPR. pp. 3195–3204 (2019)
2019
-
[27]
In: ICML
Martens, J., Grosse, R.: Optimizing neural networks with kronecker-factored ap- proximate curvature. In: ICML. pp. 2408–2417 (2015)
2015
-
[28]
In: NeurIPS (2022)
Matena, M., Raffel, C.: Merging models with fisher-weighted averaging. In: NeurIPS (2022)
2022
-
[29]
In: WACV
Mathew, M., Bagal, V., Tito, R., Karatzas, D., Valveny, E., Jawahar, C.: Info- graphicvqa. In: WACV. pp. 1697–1706 (2022)
2022
-
[30]
In: ICML
Panigrahi, A., Saunshi, N., Zhao, H., Arora, S.: Task-specific skill localization in fine-tuned language models. In: ICML. pp. 27011–27033 (2023)
2023
-
[31]
co / datasets/unsloth/LaTeX_OCR(2024)
Roboflow: Latex-ocr dataset (unsloth version).https : / / huggingface . co / datasets/unsloth/LaTeX_OCR(2024)
2024
-
[32]
In: CVPR
Singh, A., Natarajan, V., Shah, M., Jiang, Y., Chen, X., Batra, D., Parikh, D., Rohrbach, M.: Towards vqa models that can read. In: CVPR. pp. 8317–8326 (2019)
2019
-
[33]
NeurIPS35, 29440–29453 (2022)
Srinivasan, T., Chang, T.Y., Pinto Alva, L., Chochlakis, G., Rostami, M., Thoma- son, J.: Climb: A continual learning benchmark for vision-and-language tasks. NeurIPS35, 29440–29453 (2022)
2022
-
[34]
In: Workshop on Efficient Systems for Foundation Models @ ICML2023 (2023)
Sun, M., Liu, Z., Bair, A., Kolter, J.Z.: A simple and effective pruning approach for large language models. In: Workshop on Efficient Systems for Foundation Models @ ICML2023 (2023)
2023
-
[35]
In: ICCV
Wang, X., Zhuang, Z., Zhang, Y.: Plan: Proactive low-rank allocation for continual learning. In: ICCV. pp. 2909–2918 (2025)
2025
-
[36]
In: Findings of the Association for Computational Linguistics: EMNLP 2025
Wu, J., Xiong, Y., Li, X., Xia, Y., Wang, R., Wang, Y., Yu, T., Kim, S., Rossi, R.A., Yao, L., Shang, J., McAuley, J.: Mitigating visual knowledge forgetting in MLLM instruction-tuning via modality-decoupled gradient descent. In: Findings of the Association for Computational Linguistics: EMNLP 2025. pp. 2282–2295 (2025)
2025
-
[37]
In: ICLR (2025) Curvature-Guided Mixing for MLLM Adaptation 17
Wu, Y., Piao, H., Huang, L., Wang, R., Li, W., Pfister, H., Meng, D., Ma, K., Wei, Y.: Sd-lora: Scalable decoupled low-rank adaptation for class incremental learning. In: ICLR (2025) Curvature-Guided Mixing for MLLM Adaptation 17
2025
-
[38]
Transactions of the Association for Computational Linguistics2, 67–78 (2014)
Young, P., Lai, A., Hodosh, M., Hockenmaier, J.: From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics2, 67–78 (2014)
2014
-
[39]
NeurIPS37, 49834–49858 (2024)
Yu, J., Xiong, H., Zhang, L., Diao, H., Zhuge, Y., Hong, L., Wang, D., Lu, H., He, Y., Chen, L.: Llms can evolve continually on modality for x-modal reasoning. NeurIPS37, 49834–49858 (2024)
2024
-
[40]
In: CVPR
Yu, J., Zhuge, Y., Zhang, L., Hu, P., Wang, D., Lu, H., He, Y.: Boosting continual learning of vision-language models via mixture-of-experts adapters. In: CVPR. pp. 23219–23230 (2024)
2024
-
[41]
In: ICML (2024)
Yu, L., Yu, B., Yu, H., Huang, F., Li, Y.: Language models are super mario: Absorbing abilities from homologous models as a free lunch. In: ICML (2024)
2024
-
[42]
In: EMNLP
Zeng, F., Zhu, F., Guo, H., Zhang, X.Y., Liu, C.L.: Modalprompt: Towards efficient multimodal continual instruction tuning with dual-modality guided prompt. In: EMNLP. pp. 12126–12141 (2025)
2025
-
[43]
In: ICML
Zenke, F., Poole, B., Ganguli, S.: Continual learning through synaptic intelligence. In: ICML. pp. 3987–3995 (2017)
2017
-
[44]
In: Con- ference on Parsimony and Learning (2023)
Zhai, Y., Tong, S., Li, X., Cai, M., Qu, Q., Lee, Y.J., Ma, Y.: Investigating the catastrophic forgetting in multimodal large language model fine-tuning. In: Con- ference on Parsimony and Learning (2023)
2023
-
[45]
arXiv preprint arXiv:2309.15112 (2023)
Zhang, P., Dong, X., Wang, B., Cao, Y., Xu, C., Ouyang, L., Zhao, Z., Duan, H., Zhang, S., Ding, S., et al.: Internlm-xcomposer: A vision-language large model for advanced text-image comprehension and composition. arXiv preprint arXiv:2309.15112 (2023)
Pith/arXiv arXiv 2023
-
[46]
In: ICML (2024)
Zhu, D., Sun, Z., Li, Z., Shen, T., Yan, K., Ding, S., Kuang, K., Wu, C.: Model tailor: Mitigating catastrophic forgetting in multi-modal large language models. In: ICML (2024)
2024
-
[47]
arXiv preprint arXiv:2504.10479 (2025)
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., Gao, Z., Cui, E., Wang, X., Cao, Y., Liu, Y., Wei, X., Zhang, H., Wang, H., Xu, W., Li, H., Wang, J., Deng, N., Li, S., He, Y., Jiang, T., Luo, J., Wang, Y., He, C., Shi, B., Zhang, X., Shao, W., He, J., Xiong, Y., Qu, W., Sun, P., Jiao, P., Lv, H., Wu, L., Zhang, ...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.