Factored Causal Representation Learning for Robust Reward Modeling in RLHF
Pith reviewed 2026-05-21 14:13 UTC · model grok-4.3
The pith
Decomposing model embeddings into causal and non-causal factors creates robust reward models for RLHF.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a factored representation learning approach, which extracts causal factors sufficient for reward prediction from contextual embeddings while isolating non-causal factors, combined with an adversarial head and gradient reversal, results in reward models that are robust to spurious features and improve downstream RLHF performance over baselines.
What carries the argument
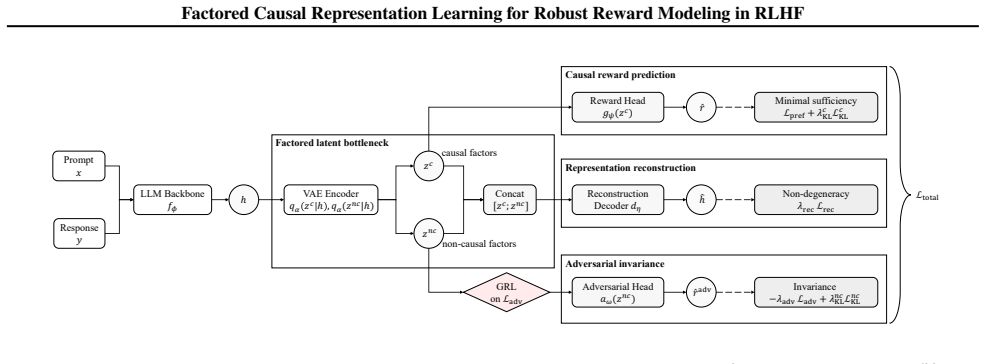
The factored causal representation that decomposes contextual embeddings into causal factors for the reward head and non-causal factors blocked by adversarial gradient reversal.
If this is right
- Reward models will be less prone to exploiting biases such as favoring longer responses or sycophantic content.
- Downstream RLHF will yield policies with better performance on mathematical and dialogue tasks.
- The separation helps validate mitigation of specific hacking behaviors like length and sycophantic bias.
Where Pith is reading between the lines
- This decomposition might allow for better interpretability of what aspects of responses humans actually value.
- Similar factoring could be applied to other preference-based learning methods to reduce shortcut learning.
- Testing on larger models or more diverse feedback sources could reveal if the causal factors are consistent across domains.
Load-bearing premise
That the contextual embedding from the model can be decomposed into causal factors that are sufficient and necessary for accurate reward prediction and non-causal factors that can be isolated without losing predictive power.
What would settle it
Observing that the reward model still performs better when non-causal factors are included or that adversarial training fails to reduce correlation between non-causal factors and rewards would challenge the claim.
Figures






read the original abstract
A reliable reward model is essential for aligning large language models with human preferences through reinforcement learning from human feedback. However, standard reward models are susceptible to spurious features that are not causally related to human labels. This can lead to reward hacking, where high predicted reward does not translate into better behavior. In this work, we address this problem from a causal perspective by proposing a factored representation learning framework that decomposes the model's contextual embedding into (1) causal factors that are sufficient for reward prediction and (2) non-causal factors that capture reward-irrelevant attributes such as length or sycophantic bias. The reward head is then constrained to depend only on the causal component. In addition, we introduce an adversarial head trained to predict reward from the non-causal factors, while applying gradient reversal to discourage them from encoding reward-relevant information. Experiments on both mathematical and dialogue tasks demonstrate that our method learns more robust reward models and consistently improves downstream RLHF performance over state-of-the-art baselines. Analyses on length and sycophantic bias further validate the effectiveness of our method in mitigating reward hacking behaviors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a factored causal representation learning framework for reward modeling in RLHF. It decomposes contextual embeddings into causal factors (used by the reward head) and non-causal factors (capturing attributes like length or sycophancy). An adversarial head predicts reward from non-causal factors with gradient reversal applied to discourage encoding of reward-relevant information. Experiments on mathematical and dialogue tasks report more robust reward models and improved downstream RLHF performance over baselines, supported by analyses mitigating length and sycophantic biases.
Significance. If the causal/non-causal separation holds, the method offers a principled way to reduce reward hacking from spurious correlations, improving reliability of RLHF for LLM alignment. The dual-task experimental validation and bias-specific analyses indicate practical relevance for robust reward modeling.
major comments (2)
- [§3.2] §3.2 (Adversarial component): The gradient reversal mechanism is central to the robustness claim, yet no post-training verification is provided, such as adversarial head accuracy, mutual information estimates between non-causal factors and reward labels, or an ablation removing the reversal term to measure increased reward hacking. This leaves open the possibility of residual reward signal leakage.
- [§4] §4 (Experiments): While improvements over baselines are reported for both math and dialogue tasks, the results lack an explicit ablation isolating the contribution of the factored decomposition versus standard adversarial training, which is load-bearing for attributing gains to the causal factoring approach.
minor comments (2)
- [Abstract] The abstract refers to 'state-of-the-art baselines' without naming them; this should be clarified with specific citations or a table reference.
- [§3] Notation for the causal factor z_c and non-causal factor z_n could be introduced with explicit equations in the method section for clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which highlight important aspects for strengthening the robustness claims in our work. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Adversarial component): The gradient reversal mechanism is central to the robustness claim, yet no post-training verification is provided, such as adversarial head accuracy, mutual information estimates between non-causal factors and reward labels, or an ablation removing the reversal term to measure increased reward hacking. This leaves open the possibility of residual reward signal leakage.
Authors: We agree that explicit post-training verification of the adversarial component would provide stronger evidence for the effectiveness of gradient reversal in preventing reward signal leakage. In the revised manuscript, we will add analyses including the accuracy of the adversarial head when predicting reward labels from the non-causal factors, as well as an ablation that removes the reversal term and measures the resulting increase in reward hacking behaviors. These additions will directly address the concern regarding residual leakage. revision: yes
-
Referee: [§4] §4 (Experiments): While improvements over baselines are reported for both math and dialogue tasks, the results lack an explicit ablation isolating the contribution of the factored decomposition versus standard adversarial training, which is load-bearing for attributing gains to the causal factoring approach.
Authors: We acknowledge that an explicit ablation separating the contribution of the factored causal decomposition from standard adversarial training is necessary to rigorously attribute the observed gains. In the revised experiments section, we will include this comparison, evaluating both the full proposed method and a standard adversarial training baseline (without the causal/non-causal factoring) on the mathematical and dialogue tasks. This will clarify the specific role of the factored representation in improving robustness. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines a factored representation learning method that decomposes contextual embeddings into causal and non-causal factors, constrains the reward head to the causal part, and uses an adversarial head with gradient reversal on the non-causal part. This construction is presented as a novel application of existing causal representation learning and adversarial training techniques rather than a self-referential definition or a fitted parameter renamed as a prediction. No equations or steps in the provided abstract reduce the claimed robustness or RLHF improvement to the inputs by construction, and the experimental claims on mathematical and dialogue tasks are presented as independent validation. The derivation chain remains self-contained against external benchmarks with no load-bearing self-citations or uniqueness theorems invoked from prior author work.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CausalRM decomposes the model’s contextual embedding into two disentangled components: (1) causal factors that are sufficient for reward prediction, and (2) non-causal factors... adversarial head trained via gradient reversal
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We investigate the potential of causal representation learning for mitigating reward hacking in RLHF
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges
The paper introduces the Proxy Compression Hypothesis as a unifying framework explaining reward hacking in RLHF as an emergent result of compressing high-dimensional human objectives into proxy reward signals under op...
Reference graph
Works this paper leans on
-
[1]
Deep Variational Information Bottleneck
Alemi, A. A., Fischer, I., Dillon, J. V ., and Murphy, K. Deep variational information bottleneck.arXiv preprint arXiv:1612.00410,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Concrete Problems in AI Safety
Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schul- man, J., and Mané, D. Concrete problems in ai safety. arXiv preprint arXiv:1606.06565,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
A General Language Assistant as a Laboratory for Alignment
Askell, A., Bai, Y ., Chen, A., Drain, D., Ganguli, D., Henighan, T., Jones, A., Joseph, N., Mann, B., DasSarma, N., et al. A general language assistant as a laboratory for alignment.arXiv preprint arXiv:2112.00861,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Y ., Jones, A., Ndousse, K., Askell, A., Chen, A., Das- Sarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al. Training a helpful and harmless assistant with rein- forcement learning from human feedback.arXiv preprint arXiv:2204.05862,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Odin: Disentangled reward mitigates hacking in rlhf.arXiv preprint arXiv:2402.07319,
Chen, L., Zhu, C., Soselia, D., Chen, J., Zhou, T., Goldstein, T., Huang, H., Shoeybi, M., and Catanzaro, B. Odin: Disentangled reward mitigates hacking in rlhf.arXiv preprint arXiv:2402.07319,
-
[6]
Chen, Y ., Wang, R., Jiang, H., Shi, S., and Xu, R. Exploring the use of large language models for reference-free text quality evaluation: An empirical study.arXiv preprint arXiv:2304.00723,
- [7]
-
[8]
Reward model ensembles help mitigate overoptimization.arXiv preprint arXiv:2310.02743,
Coste, T., Anwar, U., Kirk, R., and Krueger, D. Reward model ensembles help mitigate overoptimization.arXiv preprint arXiv:2310.02743,
-
[9]
Dubois, Y ., Galambosi, B., Liang, P., and Hashimoto, T. B. Length-controlled alpacaeval: A simple way to debias automatic evaluators.arXiv preprint arXiv:2404.04475,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Helping or herding? reward model ensembles mitigate but do not eliminate reward hacking
Eisenstein, J., Nagpal, C., Agarwal, A., Beirami, A., D’Amour, A., Dvijotham, D., Fisch, A., Heller, K., Pfohl, S., Ramachandran, D., et al. Helping or herding? reward model ensembles mitigate but do not eliminate reward hacking.arXiv preprint arXiv:2312.09244,
-
[11]
Reward shaping to mitigate reward hacking in rlhf.arXiv preprint arXiv:2502.18770,
Fu, J., Zhao, X., Yao, C., Wang, H., Han, Q., and Xiao, Y . Reward shaping to mitigate reward hacking in rlhf.arXiv preprint arXiv:2502.18770,
-
[12]
He-Yueya, J., Poesia, G., Wang, R. E., and Goodman, N. D. Solving math word problems by combining lan- guage models with symbolic solvers.arXiv preprint arXiv:2304.09102,
-
[13]
OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
Hu, J., Wu, X., Zhu, Z., Xianyu, Wang, W., Zhang, D., and Cao, Y . Openrlhf: An easy-to-use, scalable 9 Factored Causal Representation Learning for Robust Reward Modeling in RLHF and high-performance rlhf framework.arXiv preprint arXiv:2405.11143,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Huang, B., Feng, F., Lu, C., Magliacane, S., and Zhang, K. Adarl: What, where, and how to adapt in transfer reinforcement learning.arXiv preprint arXiv:2107.02729,
-
[15]
Mawps: A math word problem reposi- tory
Koncel-Kedziorski, R., Roy, S., Amini, A., Kushman, N., and Hajishirzi, H. Mawps: A math word problem reposi- tory. InProceedings of the 2016 conference of the north american chapter of the association for computational lin- guistics: human language technologies, pp. 1152–1157,
work page 2016
-
[16]
Partial identifiability for domain adaptation.arXiv preprint arXiv:2306.06510,
Kong, L., Xie, S., Yao, W., Zheng, Y ., Chen, G., Stojanov, P., Akinwande, V ., and Zhang, K. Partial identifiability for domain adaptation.arXiv preprint arXiv:2306.06510,
-
[17]
Rrm: Robust reward model training mitigates reward hacking.arXiv preprint arXiv:2409.13156,
Liu, T., Xiong, W., Ren, J., Chen, L., Wu, J., Joshi, R., Gao, Y ., Shen, J., Qin, Z., Yu, T., et al. Rrm: Robust reward model training mitigates reward hacking.arXiv preprint arXiv:2409.13156,
-
[18]
Miao, Y ., Ding, L., Zhang, S., Bao, R., Zhang, L., and Tao, D. Information-theoretic reward modeling for stable rlhf: Detecting and mitigating reward hacking.arXiv preprint arXiv:2510.13694, 2025a. Miao, Y ., Zhang, S., Ding, L., Zhang, Y ., Zhang, L., and Tao, D. The energy loss phenomenon in rlhf: A new perspective on mitigating reward hacking.arXiv pr...
- [19]
-
[20]
Park, R., Rafailov, R., Ermon, S., and Finn, C. Disentan- gling length from quality in direct preference optimiza- tion.arXiv preprint arXiv:2403.19159,
-
[21]
Are NLP Models really able to Solve Simple Math Word Problems?
Patel, A., Bhattamishra, S., and Goyal, N. Are nlp models really able to solve simple math word problems?arXiv preprint arXiv:2103.07191,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Discovering language model behaviors with model- written evaluations
Perez, E., Ringer, S., Lukosiute, K., Nguyen, K., Chen, E., Heiner, S., Pettit, C., Olsson, C., Kundu, S., Kadavath, S., et al. Discovering language model behaviors with model- written evaluations. InFindings of the Association for Computational Linguistics: ACL 2023, pp. 13387–13434,
work page 2023
-
[23]
Identifiability of Causal Graphs using Functional Models
Peters, J., Mooij, J., Janzing, D., and Schölkopf, B. Identifi- ability of causal graphs using functional models.arXiv preprint arXiv:1202.3757,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Qwen, :, Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Tang, T., Xia, T., Ren, X., Ren, X., Fan, Y ., Su, Y ., Zhang, Y .,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Towards Understanding Sycophancy in Language Models
Sharma, M., Tong, M., Korbak, T., Duvenaud, D., Askell, A., Bowman, S. R., Cheng, N., Durmus, E., Hatfield- Dodds, Z., Johnston, S. R., et al. Towards understand- ing sycophancy in language models.arXiv preprint arXiv:2310.13548,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
A long way to go: Investigating length correlations in rlhf.arXiv preprint arXiv:2310.03716,
Singhal, P., Goyal, T., Xu, J., and Durrett, G. A long way to go: Investigating length correlations in rlhf.arXiv preprint arXiv:2310.03716,
-
[28]
Song, R., Song, Z., Guo, H., and Qiang, W. Causal re- ward adjustment: Mitigating reward hacking in exter- nal reasoning via backdoor correction.arXiv preprint arXiv:2508.04216, 2025a. Song, X., Sun, J., Li, Z., Zheng, Y ., and Zhang, K. Llm interpretability with identifiable temporal-instantaneous representation.arXiv preprint arXiv:2509.23323, 2025b. St...
-
[29]
Veitch, V ., D’Amour, A., Yadlowsky, S., and Eisenstein, J. Counterfactual invariance to spurious correlations: Why and how to pass stress tests.arXiv preprint arXiv:2106.00545,
-
[30]
Wang, C., Zhao, Z., Jiang, Y ., Chen, Z., Zhu, C., Chen, Y ., Liu, J., Zhang, L., Fan, X., Ma, H., et al. Beyond reward hacking: Causal rewards for large language model alignment.arXiv preprint arXiv:2501.09620,
-
[31]
Yang, A., Zhang, B., Hui, B., Gao, B., Yu, B., Li, C., Liu, D., Tu, J., Zhou, J., Lin, J., et al. Qwen2. 5-math techni- cal report: Toward mathematical expert model via self- improvement.arXiv preprint arXiv:2409.12122, 2024a. Yang, Y ., Huang, B., Feng, F., Wang, X., Tu, S., and Xu, L. Towards generalizable reinforcement learning via causality-guided sel...
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Yao, W., Sun, Y ., Ho, A., Sun, C., and Zhang, K. Learning temporally causal latent processes from general temporal data.arXiv preprint arXiv:2110.05428,
-
[33]
Zhou, Y ., Xu, P., Liu, X., An, B., Ai, W., and Huang, F. Explore spurious correlations at the concept level in language models for text classification.arXiv preprint arXiv:2311.08648,
-
[34]
11 Factored Causal Representation Learning for Robust Reward Modeling in RLHF Zhou, Y ., Liu, H., Chen, Z., Tian, Y ., and Chen, B. Gsm- infinite: How do your llms behave over infinitely increas- ing context length and reasoning complexity?arXiv preprint arXiv:2502.05252,
-
[35]
12 Factored Causal Representation Learning for Robust Reward Modeling in RLHF A. Derivation of the Minimal Sufficiency Objective In this section, we derive a variational lower bound for Eq. (11), following Alemi et al. (2016) and Miao et al. (2024). Recall that our minimal sufficiency objective for the causal latentz c is maxI(z c;r)−λ c KL I(h;z c),(16) ...
work page 2016
-
[36]
Results and analysis.Tables 9 and 10 summarize the ablation results
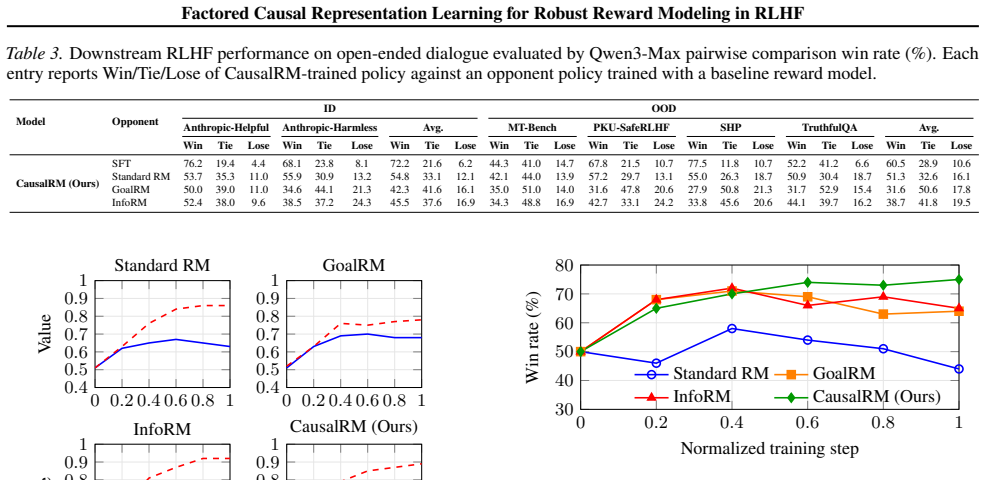
All other training details follow the main experiments to ensure a controlled comparison. Results and analysis.Tables 9 and 10 summarize the ablation results. Overall, we observe that the full CausalRM consistently performs best, and different components contribute in complementary ways. Factorization and the structural restriction are important.Compared ...
work page 2012
-
[37]
= 6 (1) = 6\\)\n\nThe least possible result is \\(-10\\).The final answer is (\\boxed{-10}).```python\nimport itertools\n\n# Define the numbers\nnumbers = [4, 5, 6]\n\n# Initialize the minimum value to a large number\nmin_value = float('inf')\n\n# Iterate through all permutations of the numbers\nfor A, B, C in itertools.permutations(numbers):\n # Calculat...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.