Thermo-VL: Extending Vision-Language Models to Thermal Infrared Perception
Pith reviewed 2026-05-22 07:51 UTC · model grok-4.3
The pith
Thermo-VL adds a thermal encoder and text-guided fusion to a frozen VLM so it can reason with infrared when RGB fails.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A wavelength-aware extension to a frozen vision-language model can incorporate thermal infrared features through prompt-conditioned dual-attention fusion and gated residual injection, preserving the original RGB-language interface while improving performance on low-light and cross-spectrum visual reasoning.
What carries the argument
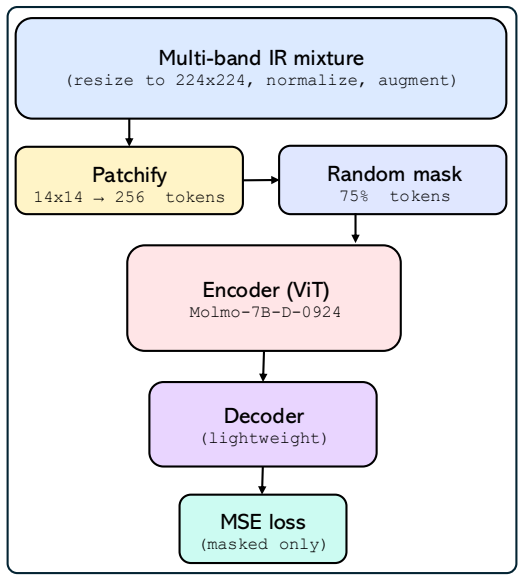
text-guided dual-attention fusion module that conditions thermal tokens on language and RGB context before gated residual injection into the frozen Molmo-7B stream
If this is right
- Prompt-conditioned fusion enables thermal-only reasoning without retraining the entire language model.
- Auxiliary alignment losses reduce over-reliance on RGB cues in mixed-spectrum inputs.
- The new pixel-aligned dataset supports further instruction tuning for multispectral VLMs.
- Gated injection keeps the original RGB-language interface intact while adding infrared capability.
Where Pith is reading between the lines
- The same gated-injection pattern could be applied to add depth or event-camera streams to existing VLMs without full retraining.
- Manual screening of the benchmark reduces label noise that often confounds cross-modal evaluations.
- If the fusion remains effective at larger scales, the method offers a low-cost route to multispectral perception for deployed systems.
Load-bearing premise
The gated residual injection adds thermal evidence without harming the pretrained RGB-language behavior and the auxiliary losses create real cross-modal grounding instead of superficial gains.
What would settle it
Ablating the thermal encoder or fusion module on Thermo-VL-Bench thermal-only questions and measuring whether accuracy falls back to the level of the unmodified frozen Molmo-7B.
Figures










read the original abstract
Vision-language models (VLMs) often fail under low illumination because their visual grounding is learned predominantly from RGB imagery, whereas thermal infrared preserves complementary scene structure when visible cues degrade. We present Thermo-VL, a wavelength-aware VLM that augments a frozen Molmo-7B backbone with a trainable thermal encoder and a text-guided dual-attention fusion module. Given aligned RGB tokens, thermal tokens, and prompt embeddings, the fusion module conditions thermal features on both language and RGB context, then injects a gated residual into the frozen RGB stream so thermal evidence can be incorporated without disrupting Molmo's pretrained RGB-language interface. We train the model with the standard language-modeling objective together with auxiliary alignment and regularization losses that improve cross-modal grounding and reduce over-reliance on RGB. We also introduce a pixel-aligned RGB-thermal instruction-tuning dataset and Thermo-VL-Bench, a manually screened RGB-thermal VQA benchmark for low-light and cross-spectrum reasoning. Experiments show strong gains on challenging thermal-only and RGB+thermal reasoning tasks, highlighting the value of prompt-conditioned multispectral fusion. Our dataset and code are publicly available at: https://thusharakart.github.io/Thermo-VL
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Thermo-VL, which augments a frozen Molmo-7B VLM backbone with a trainable thermal encoder and a text-guided dual-attention fusion module. Thermal features are conditioned on language and RGB context before gated residual injection into the frozen RGB stream. Training combines the standard language-modeling objective with auxiliary alignment and regularization losses. The work also contributes a pixel-aligned RGB-thermal instruction-tuning dataset and the Thermo-VL-Bench benchmark for low-light and cross-spectrum VQA. Experiments report strong gains on thermal-only and RGB+thermal reasoning tasks.
Significance. If the central claims hold, the approach offers a practical route to multispectral VLMs that preserves a strong pretrained RGB-language interface while adding thermal perception, which is relevant for low-illumination applications. The public release of the dataset and code supports reproducibility and follow-on work in cross-modal grounding.
major comments (2)
- [§3] §3 (Architecture, gated residual injection paragraph): The claim that gated residual injection incorporates thermal evidence without disrupting the pretrained Molmo-7B RGB-language interface is load-bearing for the 'extending rather than trading off' assertion, yet no quantitative results are reported on held-out RGB-only VQA or captioning benchmarks before versus after training the thermal encoder and fusion module.
- [§4] §4 (Experiments): The reported gains on Thermo-VL-Bench and thermal-only tasks are presented without ablations that isolate the contribution of the text-guided dual-attention fusion versus the gated residual or the auxiliary losses, making it difficult to verify that improvements stem from the proposed prompt-conditioned multispectral mechanism rather than dataset-specific effects.
minor comments (2)
- [Abstract] Abstract: The phrase 'strong gains' would be more informative if accompanied by at least one concrete metric (e.g., accuracy delta over baseline) even in summary form.
- [§3] Notation in the fusion module description is occasionally ambiguous regarding whether 'text-guided' attention is applied before or after RGB-thermal token concatenation; a clarifying equation or diagram label would help.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment point by point below, indicating where revisions have been made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Architecture, gated residual injection paragraph): The claim that gated residual injection incorporates thermal evidence without disrupting the pretrained Molmo-7B RGB-language interface is load-bearing for the 'extending rather than trading off' assertion, yet no quantitative results are reported on held-out RGB-only VQA or captioning benchmarks before versus after training the thermal encoder and fusion module.
Authors: We agree that quantitative verification of preserved RGB performance is important to support the central claim. Because the Molmo-7B backbone remains frozen and the gated residual is designed to be zero when thermal evidence is not relevant, we expect minimal interference; however, we acknowledge the absence of explicit before/after numbers on held-out RGB benchmarks. In the revised manuscript we have added these evaluations (new Table in §3 and Appendix), showing that RGB-only VQA and captioning accuracy remains within 1-2% of the original frozen model, with the small variance attributable to the auxiliary regularization terms. This directly substantiates the 'extending rather than trading off' assertion. revision: yes
-
Referee: [§4] §4 (Experiments): The reported gains on Thermo-VL-Bench and thermal-only tasks are presented without ablations that isolate the contribution of the text-guided dual-attention fusion versus the gated residual or the auxiliary losses, making it difficult to verify that improvements stem from the proposed prompt-conditioned multispectral mechanism rather than dataset-specific effects.
Authors: We concur that component-wise ablations would strengthen the experimental claims. The current results rely on the full model versus strong baselines, but do not fully disentangle the dual-attention fusion, gated residual, and auxiliary losses. We have therefore added a dedicated ablation subsection in the revised §4, including variants that disable each module in turn while keeping training data and schedule identical. The new results show that removing the text-guided dual-attention fusion accounts for the largest drop on cross-spectrum VQA, while the gated residual primarily stabilizes training and the auxiliary losses reduce RGB over-reliance; these controls indicate that gains are attributable to the proposed mechanisms rather than dataset artifacts alone. revision: yes
Circularity Check
No significant circularity; standard training pipeline with empirical results on new benchmark.
full rationale
The paper presents an architectural extension to a frozen VLM backbone using a trainable thermal encoder, text-guided fusion, and gated residual injection, trained via standard language-modeling loss plus auxiliary alignment/regularization terms on a newly introduced RGB-thermal instruction dataset. Performance improvements on Thermo-VL-Bench and thermal-only tasks are reported as direct empirical outcomes of this training process rather than any closed-form derivation or prediction that reduces to the inputs by construction. No equations are shown that define a target quantity in terms of itself, no fitted parameters are relabeled as predictions, and no load-bearing claims rely on self-citations or imported uniqueness theorems. The derivation chain is therefore self-contained against external benchmarks and the introduced evaluation set.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Masked Autoencoders Are Scalable Vision Learners , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[10]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Multispectral Pedestrian Detection: Benchmark Dataset and Baseline , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[11]
FREE Teledyne FLIR Thermal Dataset for Algorithm Training (FLIR-ADAS) , howpublished =
-
[12]
Teledyne FLIR ADAS Dataset README , howpublished =
-
[13]
OTCBVS Benchmark: Dataset 01 (OSU Thermal Pedestrian Database) , howpublished =
-
[14]
James W. Davis and Mark A. Keck , title =. Proceedings of the IEEE Workshop on Applications of Computer Vision (WACV) , year =
-
[15]
OTCBVS Benchmark: Dataset 03 (OSU Color and Thermal Database) , howpublished =
-
[16]
Davis and Vinay Sharma , title =
James W. Davis and Vinay Sharma , title =. Computer Vision and Image Understanding , volume =. 2007 , note =
work page 2007
-
[17]
M. Brown and S. S\"usstrunk , title =. Computer Vision and Pattern Recognition (CVPR11) , pages =. 2011 , OPTeditor =
work page 2011
-
[18]
Near-infrared spectrum overview , howpublished =
-
[19]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Pixel-aligned RGB-NIR Stereo Imaging and Dataset for Robot Vision , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[20]
arXiv preprint arXiv:2503.19654 , year=
RGB-Th-Bench: A Dense benchmark for Visual-Thermal Understanding of Vision Language Models , author=. arXiv preprint arXiv:2503.19654 , year=
-
[21]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[22]
International Journal of Computer Vision , volume=
Visual instruction tuning towards general-purpose multimodal large language model: A survey , author=. International Journal of Computer Vision , volume=. 2025 , publisher=
work page 2025
-
[23]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
- [24]
-
[25]
Color-NIR Study and Deblurring , author =. 2018 , howpublished =
work page 2018
-
[26]
2017 IEEE International Conference on Image Processing (ICIP) , pages=
Correlation-based deblurring leveraging multispectral chromatic aberration in color and near-infrared joint acquisition , author=. 2017 IEEE International Conference on Image Processing (ICIP) , pages=. 2017 , organization=
work page 2017
-
[27]
arXiv preprint arXiv:2401.10731 , year=
Removal and selection: Improving rgb-infrared object detection via coarse-to-fine fusion , author=. arXiv preprint arXiv:2401.10731 , year=
-
[28]
arXiv preprint arXiv:2504.02801 , year=
F-ViTA: Foundation Model Guided Visible to Thermal Translation , author=. arXiv preprint arXiv:2504.02801 , year=
-
[29]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Lightweight thermal super-resolution and object detection for robust perception in adverse weather conditions , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[30]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
LLVIP: A Visible-infrared Paired Dataset for Low-light Vision , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[31]
Teledyne FLIR , title =
- [32]
-
[33]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Infrared-LLaVA: Enhancing Understanding of Infrared Images in Multi-Modal Large Language Models , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=. 2024 , address=
work page 2024
-
[34]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , pages=
Enhanced Thermal-RGB Fusion for Robust Object Detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , pages=
-
[35]
IEEE Robotics and Automation Letters , volume=
RTFNet: RGB-Thermal Fusion Network for Semantic Segmentation of Urban Scenes , author=. IEEE Robotics and Automation Letters , volume=. 2019 , publisher=
work page 2019
-
[36]
Journal of Imaging Science and Technology , volume=
Illumination-guided with Crossmodal Transformer Fusion for RGB-T Object Detection , author=. Journal of Imaging Science and Technology , volume=. 2023 , doi=
work page 2023
-
[37]
AT-Detr: A Multispectral Detector with Adaptive Feature Alignment and Fusion , author=. 2025 , note=
work page 2025
-
[38]
Multimodal fusion transformer network for multispectral pedestrian detection , author=. Scientific Reports , volume=. 2025 , publisher=
work page 2025
-
[39]
Multimodal fusion transformer network for multispectral pedestrian detection in low-light condition , author=. Scientific Reports , volume=. 2025 , publisher=
work page 2025
-
[40]
arXiv preprint arXiv:2411.03576 , year=
Hybrid Attention for Robust RGB-T Pedestrian Detection in Adverse Conditions , author=. arXiv preprint arXiv:2411.03576 , year=
-
[41]
IEEE Robotics and Automation Letters , year=
Hybrid Attention for Robust RGB-T Pedestrian Detection in Real-World Conditions , author=. IEEE Robotics and Automation Letters , year=
-
[42]
arXiv preprint arXiv:2509.24878 , year =
Xiao, Jiuhong and Nayak, Roshan and Zhang, Ning and Tortei, Daniel and Loianno, Giuseppe , title =. arXiv preprint arXiv:2509.24878 , year =. doi:10.48550/arXiv.2509.24878 , url =
-
[43]
Berg, Andreas and Olofsson, Mikael and Johanson, Fredrik , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , year =
-
[44]
SN Computer Science , volume =
Li, Yuchuan and Ko, Yoon and Lee, Wonsook , title =. SN Computer Science , volume =. 2023 , doi =
work page 2023
-
[45]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[46]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , author=. arXiv preprint arXiv:2308.12966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae , month=. LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
-
[48]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Masked autoencoders are scalable vision learners , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[49]
Layer normalization , author=. arXiv preprint arXiv:1607.06450 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
An Introduction to Convolutional Neural Networks
An introduction to convolutional neural networks , author=. arXiv preprint arXiv:1511.08458 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.