Stateful Detection of Black-Box Adversarial Attacks
Pith reviewed 2026-05-24 22:46 UTC · model grok-4.3
The pith
Stateful defenses detect black-box adversarial attacks by monitoring sequences of queries to remote services.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
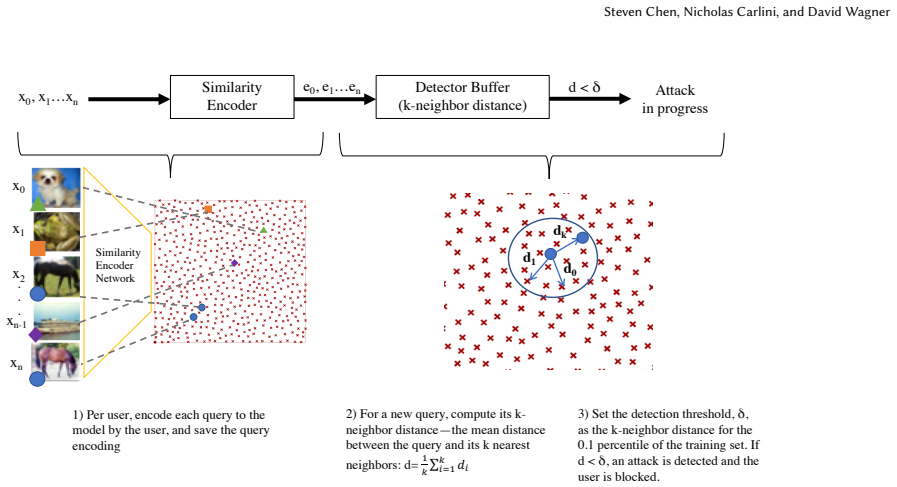
In black-box settings where the classifier is hosted as a remote service, defenders have a much larger space of actions by using stateful defenses that keep a history of past queries to identify sequences for the purpose of generating an adversarial example; the authors develop one such defense and introduce query blinding as a new class of attacks designed to bypass it.
What carries the argument
Stateful query history tracking that identifies sequences of queries aimed at adversarial example generation by distinguishing them from normal usage.
If this is right
- Remote machine learning services can implement detection of attack preparation across multiple queries instead of checking examples in isolation.
- Adversaries must develop new techniques such as query blinding to evade stateful detection.
- The study of adversarial examples moves from stateless classifiers to stateful systems that retain query history.
- Defenders gain additional responses to black-box adversaries beyond per-query analysis.
Where Pith is reading between the lines
- Stateful defenses could be paired with rate limiting or other query controls to limit an attacker's ability to test many variations.
- The same history-tracking idea might apply to detecting other forms of misuse against query-based machine learning APIs.
- Deployment would require deciding how long to retain query histories and how to handle cases where legitimate users submit similar sequences.
Load-bearing premise
Sequences of queries used to generate adversarial examples will exhibit detectable patterns distinguishable from normal usage even after the introduction of query blinding countermeasures.
What would settle it
An experiment in which every sequence of queries crafted to produce an adversarial example is made indistinguishable from sequences of normal user queries.
Figures



read the original abstract
The problem of adversarial examples, evasion attacks on machine learning classifiers, has proven extremely difficult to solve. This is true even when, as is the case in many practical settings, the classifier is hosted as a remote service and so the adversary does not have direct access to the model parameters. This paper argues that in such settings, defenders have a much larger space of actions than have been previously explored. Specifically, we deviate from the implicit assumption made by prior work that a defense must be a stateless function that operates on individual examples, and explore the possibility for stateful defenses. To begin, we develop a defense designed to detect the process of adversarial example generation. By keeping a history of the past queries, a defender can try to identify when a sequence of queries appears to be for the purpose of generating an adversarial example. We then introduce query blinding, a new class of attacks designed to bypass defenses that rely on such a defense approach. We believe that expanding the study of adversarial examples from stateless classifiers to stateful systems is not only more realistic for many black-box settings, but also gives the defender a much-needed advantage in responding to the adversary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that in black-box settings where a classifier is hosted as a remote service, defenders can exploit a larger action space by adopting stateful defenses that maintain a history of past queries to identify sequences indicative of adversarial example generation. It contrasts this approach with prior stateless defenses and introduces query blinding as a new attack class explicitly designed to evade history-based detection. The authors conclude that expanding the study to stateful systems is both more realistic and advantageous for defenders.
Significance. If the premise that detectable patterns in query sequences survive blinding countermeasures holds, the work could meaningfully expand the design space for practical defenses in remote ML deployments by moving beyond per-query stateless methods.
major comments (1)
- Abstract: the claim that stateful detection yields a defender advantage rests on the unshown premise that query sequences for adversarial example generation remain distinguishable from benign usage even after query blinding; no detection algorithm, similarity metric, threshold, or experimental protocol is described to support this.
Simulated Author's Rebuttal
We thank the referee for their comments on the manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: Abstract: the claim that stateful detection yields a defender advantage rests on the unshown premise that query sequences for adversarial example generation remain distinguishable from benign usage even after query blinding; no detection algorithm, similarity metric, threshold, or experimental protocol is described to support this.
Authors: The abstract is intentionally concise and summarizes the core argument and contributions. The full manuscript (Sections 3–5) defines the stateful detection algorithm, the similarity metric over query histories, the decision threshold, and the experimental protocol (including benign vs. adversarial query sequences). Experiments evaluate distinguishability both before and after query blinding is applied, showing that blinding reduces but does not eliminate detectable patterns, thereby imposing higher query costs on the attacker. We acknowledge that the abstract could more explicitly reference these elements and the nuanced post-blinding results; we will revise it accordingly. revision: yes
Circularity Check
No circularity: purely conceptual proposal without derivations or self-citations
full rationale
The paper advances a conceptual argument that stateful defenses expand defender options in black-box settings and introduces query blinding as a new attack class. No equations, fitted parameters, predictions, or load-bearing self-citations appear in the provided text. The central claim is presented as a belief rather than a derived result from prior inputs, so no reduction to self-definition or fitted inputs exists. This matches the default case of a self-contained conceptual paper with no circularity.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Benchmarking Misuse Mitigation Against Covert Adversaries
Develops the BSD data generation pipeline and two new datasets to evaluate decomposition attacks as effective misuse enablers and stateful defenses as a countermeasure in language model safety.
Reference graph
Works this paper leans on
-
[1]
Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, San- jay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dandelion Mané, Rajat Monga, Sherry Moore, Derek Mur...
work page 2015
-
[2]
On the Robustness of the CVPR 2018 White-Box Adversarial Example Defenses
Anish Athalye and Nicholas Carlini. On the robustness of the CVPR 2018 white- box adversarial example defenses. CoRR, abs/1804.03286, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples
Anish Athalye, Nicholas Carlini, and David Wagner. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In ICML, July 2018
work page 2018
-
[4]
Learning visual similarity for product design with convolutional neural networks
Sean Bell and Kavita Bala. Learning visual similarity for product design with convolutional neural networks. ACM Trans. on Graphics (SIGGRAPH), 34(4), 2015
work page 2015
-
[5]
Evasion Attacks against Machine Learning at Test Time
Battista Biggio, Igino Corona, Davide Maiorca, Blaine Nelson, Nedim Srndic, Pavel Laskov, Giorgio Giacinto, and Fabio Roli. Evasion attacks against machine learning at test time. CoRR, abs/1708.06131, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
Decision-based adversarial attacks: Reliable attacks against black-box machine learning models
Wieland Brendel, Jonas Rauber, and Matthias Bethge. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models. In ICLR, 2018
work page 2018
-
[7]
Guess- ing smart: Biased sampling for efficient black-box adversarial attacks
Thomas Brunner, Frederik Diehl, Michael Truong-Le, and Alois Knoll. Guess- ing smart: Biased sampling for efficient black-box adversarial attacks. CoRR, abs/1812.09803, 2018
-
[8]
On Evaluating Adversarial Robustness
Nicholas Carlini, Anish Athalye, Nicolas Papernot, Wieland Brendel, Jonas Rauber, Dimitris Tsipras, Ian Goodfellow, and Aleksander Madry. On evalu- ating adversarial robustness. arXiv preprint arXiv:1902.06705, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[9]
Adversarial examples are not easily detected: Bypassing ten detection methods
Nicholas Carlini and David Wagner. Adversarial examples are not easily detected: Bypassing ten detection methods. In ACM Workshop on Artificial Intelligence and Security, pages 3–14, 2017
work page 2017
-
[10]
Nicholas Carlini and David A. Wagner. Towards evaluating the robustness of neural networks. CoRR, abs/1608.04644, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Blind signatures for untraceable payments
David Chaum. Blind signatures for untraceable payments. In CRYPTO. Springer, 1983
work page 1983
-
[12]
François Chollet et al. Keras. https://keras.io, 2015. Stateful Detection of Black-Box Adversarial Attacks
work page 2015
-
[13]
Transforming enterprises with computer vision ai
Clarifai. Transforming enterprises with computer vision ai. https://clarifai.com/
-
[14]
Evaluating and understand- ing the robustness of adversarial logit pairing
Logan Engstrom, Andrew Ilyas, and Anish Athalye. Evaluating and understand- ing the robustness of adversarial logit pairing. In NIPS 2018 Machine Learning and Computer Security Workshop, November 2018
work page 2018
-
[15]
Detecting Adversarial Samples from Artifacts
Reuben Feinman, Ryan R. Curtin, Saurabh Shintre, and Andrew B. Gardner. Detecting adversarial samples from artifacts. CoRR, abs/1703.00410, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Adversarial Examples Are a Natural Consequence of Test Error in Noise
Nic Ford, Justin Gilmer, Nicolas Carlini, and Dogus Cubuk. Adversarial examples are a natural consequence of test error in noise. arXiv:1901.10513, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[17]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In NIPS. Curran Associates, Inc., 2014
work page 2014
-
[18]
Explaining and har- nessing adversarial examples
Ian Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and har- nessing adversarial examples. In ICLR, 2015
work page 2015
- [19]
-
[20]
On the (Statistical) Detection of Adversarial Examples
Kathrin Grosse, Praveen Manoharan, Nicolas Papernot, Michael Backes, and Patrick D. McDaniel. On the (statistical) detection of adversarial examples. CoRR, abs/1702.06280, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. CoRR, abs/1512.03385, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[22]
Black-box adver- sarial attacks with limited queries and information
Andrew Ilyas, Logan Engstrom, Anish Athalye, and Jessy Lin. Black-box adver- sarial attacks with limited queries and information. In ICML, July 2018
work page 2018
-
[23]
Michael I. Jordan Jianbo Chen. Boundary attack++: Query-efficient decision- based adversarial attack. https://arxiv.org/abs/1904.02144, 2019
-
[24]
Mika Juuti, Sebastian Szyller, Alexey Dmitrenko, Samuel Marchal, and N. Asokan. PRADA: protecting against DNN model stealing attacks. CoRR, abs/1805.02628, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
E-LPIPS: Robust Perceptual Image Similarity via Random Transformation Ensembles
Markus Kettunen, Erik Härkönen, and Jaakko Lehtinen. E-LPIPS: Ro- bust perceptual image similarity via random transformation ensembles, 2019. arxiv:1906.03973
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[26]
RED-Attack: Resource Efficient Decision based Attack for Machine Learning
Faiq Khalid, Hassan Ali, Muhammad Abdullah Hanif, Semeen Rehman, Rehan Ahmed, and Muhammad Shafique. RED-attack: Resource efficient decision based attack for machine learning. CoRR, abs/1901.10258, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[27]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015
work page 2015
- [28]
-
[29]
A geometry-inspired decision-based attack
Yujia Liu, Seyed-Mohsen Moosavi-Dezfooli, and Pascal Frossard. A geometry- inspired decision-based attack. CoRR, abs/1903.10826, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[30]
Towards Deep Learning Models Resistant to Adversarial Attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
On detecting adversarial perturbations
Jan Hendrik Metzen, Tim Genewein, Volker Fischer, and Bastian Bischoff. On detecting adversarial perturbations. In ICLR, 2017
work page 2017
-
[32]
Practical Black-Box Attacks against Machine Learning
Nicolas Papernot, Patrick D. McDaniel, Ian J. Goodfellow, Somesh Jha, Z. Berkay Celik, and Ananthram Swami. Practical black-box attacks against deep learning systems using adversarial examples. CoRR, abs/1602.02697, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[33]
YOLO9000: better, faster, stronger
Joseph Redmon and Ali Farhadi. YOLO9000: better, faster, stronger. In CVPR, 2017
work page 2017
-
[34]
Sitatapatra: Blocking the transfer of adversarial samples.CoRR, abs/1901.08121, 2019
Ilia Shumailov, Xitong Gao, Yiren Zhao, Robert Mullins, Ross Anderson, and Cheng-Zhong Xu. Sitatapatra: Blocking the transfer of adversarial samples.CoRR, abs/1901.08121, 2019
-
[35]
David Silver, Aja Huang, Christopher J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Pan- neershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Masteri...
work page 2016
-
[36]
Intriguing properties of neural networks
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. In ICLR, 2014
work page 2014
-
[37]
Ensemble adversarial training: Attacks and defenses
Florian Tramèr, Alexey Kurakin, Nicolas Papernot, Ian Goodfellow, Dan Boneh, and Patrick McDaniel. Ensemble adversarial training: Attacks and defenses. In ICLR, 2018
work page 2018
-
[38]
Florian Tramèr, Fan Zhang, Ari Juels, Michael K. Reiter, and Thomas Ristenpart. Stealing machine learning models via prediction apis. In USENIX Security, 2016
work page 2016
-
[39]
Adversarial Risk and the Dangers of Evaluating Against Weak Attacks
Jonathan Uesato, Brendan O’Donoghue, Aäron van den Oord, and Pushmeet Kohli. Adversarial risk and the dangers of evaluating against weak attacks.CoRR, abs/1802.05666, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS 2017, 2017
work page 2017
-
[41]
Mimicry attacks on host-based intrusion detection systems
David Wagner and Paolo Soto. Mimicry attacks on host-based intrusion detection systems. In CCS. ACM, 2002
work page 2002
-
[42]
Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks
Weilin Xu, David Evans, and Yanjun Qi. Feature squeezing: Detecting adversarial examples in deep neural networks. CoRR, abs/1704.01155, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. CoRR, abs/1605.07146, 2016. A CNN ARCHITECTURE Layer Filters Size Details Conv 32 3 × 3 ReLU Conv 32 3 × 3 ReLU Max Pool 2 × 2 stride = 2 Dropout p = 0.25 Conv 64 3 × 3 ReLU Conv 64 3 × 3 ReLU Max Pool 2 × 2 stride = 2 Dropout p = 0.25 Dense 512 ReLU Dropout p = 0.5 Dense 256 Table 6: Architect...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[44]
withϵ= 0.05. The network was trained for 100 epochs, where the adversarial examples for each epoch were generated from a ran- domly selected model from the ensemble and the defended model, and one adversarial example was generated per image in the CIFAR- 10 training set. D A DIFFICULT SOFT-LABEL CASE Our paper focuses on the “hard-label” threat model wher...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.