Lynx: Progressive Speculative Quantization for accelerating KV Transfer in Long-Context Inference
Pith reviewed 2026-07-03 06:17 UTC · model grok-4.3
The pith
Splitting KV cache bits into an anchor stream of most significant bits and a residual stream allows speculative decoding to begin before the full cache arrives while preserving BF16 accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
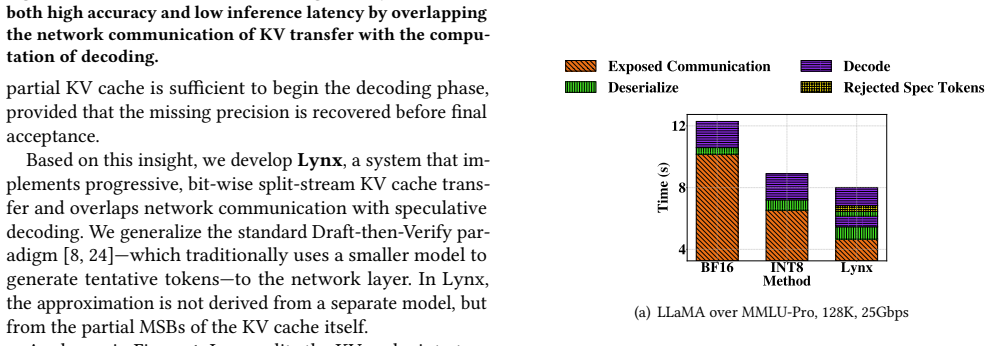
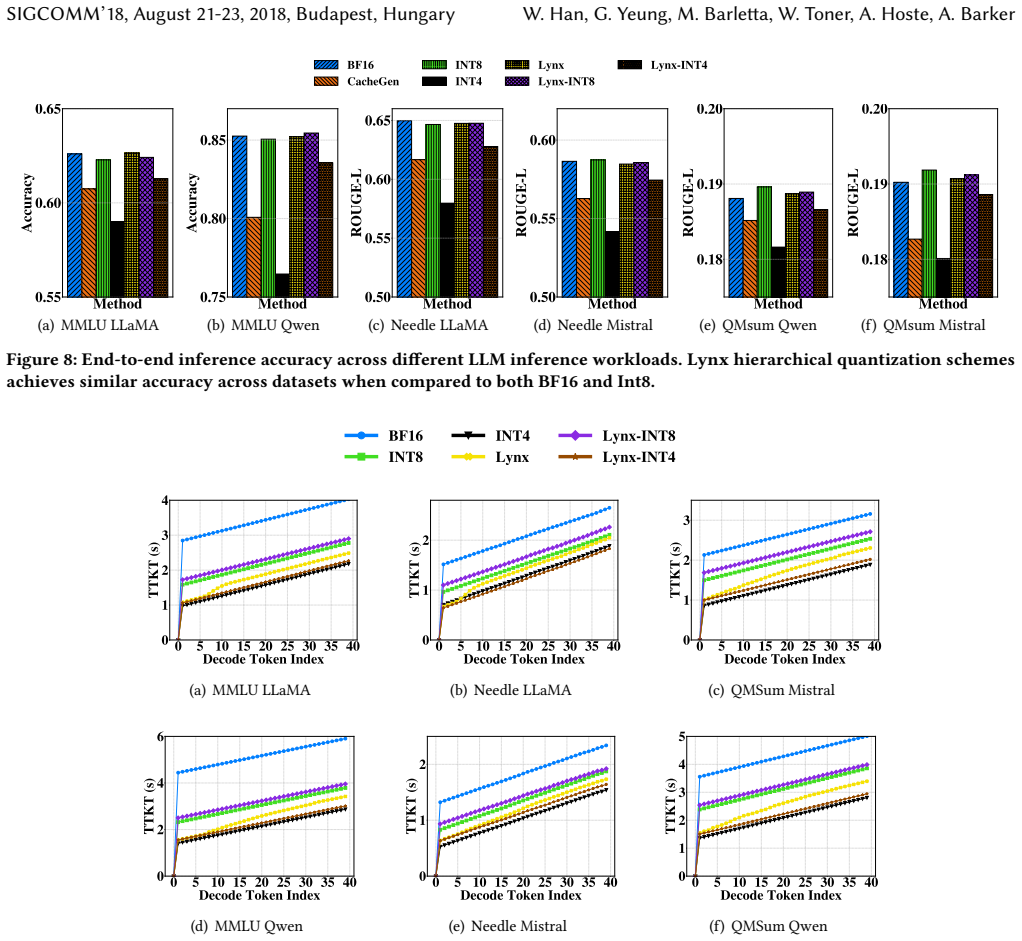
By partitioning the KV cache into a high-priority Anchor stream of most significant bits and a low-priority Residual stream, decoding proceeds speculatively upon Anchor receipt while the Residual transfers concurrently, with verification ensuring the result matches higher-precision decoding; this yields TTFT comparable to aggressive 4-bit quantization yet accuracy matching BF16, with up to 1.43 times better TTFT than standard 8-bit quantization and up to 5.1 percent accuracy gains over prior methods.
What carries the argument
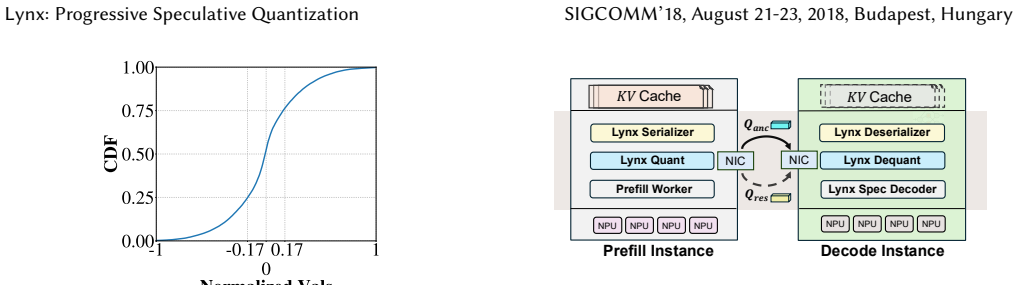
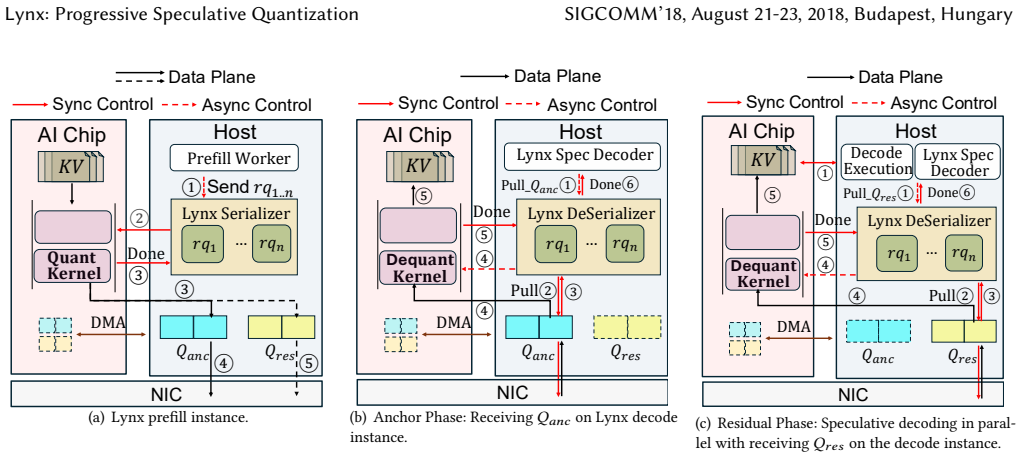
The progressive split-stream KV transfer that separates the cache into Anchor (most significant bits) and Residual (remaining bits) streams to enable concurrent transfer and speculative decoding with later verification.
If this is right
- TTFT becomes comparable to 4-bit KV quantization while accuracy stays at BF16 levels across tested models.
- TTFT improves by up to 1.43 times relative to standard 8-bit KV quantization.
- Accuracy exceeds prior state-of-the-art methods by up to 5.1 percent on the evaluated workloads.
- Decoding can start using only partial KV cache data without waiting for the complete transfer.
- The same split applies to multiple models and serving workloads without retraining.
Where Pith is reading between the lines
- The technique could lower required network bandwidth in disaggregated setups by allowing early use of partial data.
- Verification overhead might be reduced by tuning the bit split point per attention head based on observed sensitivity.
- The same bit-partition idea could extend to other cache or state transfers in distributed inference systems.
- Measuring how often verification passes on out-of-distribution prompts would test robustness beyond the reported workloads.
Load-bearing premise
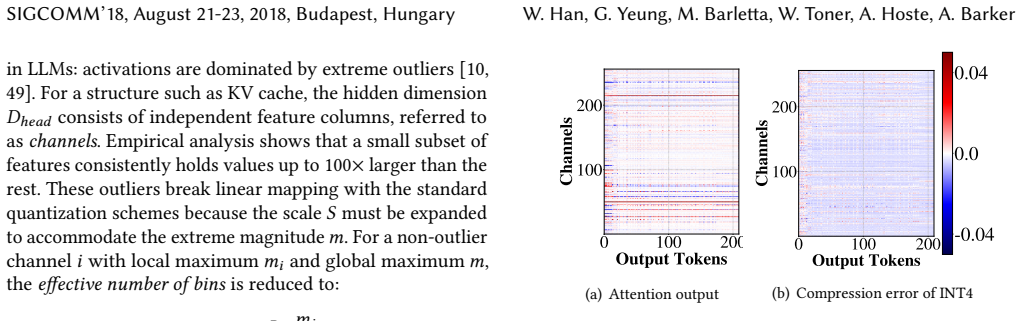
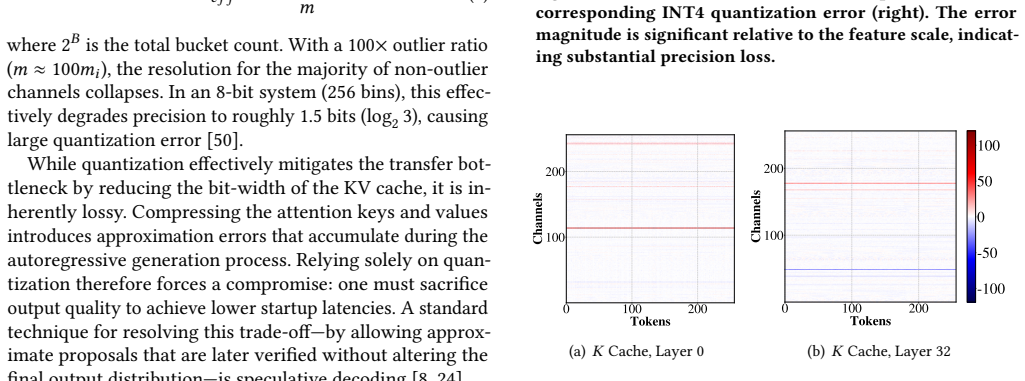
The most significant bits of the KV cache contain enough coarse attention structure to support speculative decoding whose output can be verified as equivalent once the remaining bits arrive.
What would settle it
A set of long-context queries where the verification step rejects a substantial fraction of speculative outputs or where end-to-end accuracy falls below the BF16 baseline on the same model and workload.
Figures



read the original abstract
Long-context inference is increasingly common in large language model (LLM) serving, driven by retrieval-augmented generation and agentic systems. In disaggregated inference, these workloads require transferring large Key-Value (KV) caches across the network, where decoding cannot begin until the transfer completes. Recent KV quantization techniques reduce data volume and alleviate this bottleneck, but existing schemes fail to achieve both low network-exposed latency and high inference accuracy. We challenge the assumption that the KV cache is an indivisible unit that must be fully received before use. We leverage the observation that different bits in the KV cache contribute unequally to attention computation and inference precision: the most significant bits capture the coarse structure of attention and the least significant bits refine precision. This property enables partial use of the KV cache during decoding. We present Lynx, a system that enables progressive, split-stream KV transfer by partitioning the KV cache into a high-priority Anchor stream carrying the most significant bits and a low-priority Residual stream carrying remaining precision. Decoding begins upon receipt of the Anchor stream and proceeds speculatively while the Residual stream is transferred concurrently, followed by verification that ensures equivalence to higher-precision decoding. Across multiple models and serving workloads, Lynx achieves Time-to-First-Token (TTFT) comparable to aggressive 4-bit KV quantization, while matching the accuracy of high-precision (BF16) inference, improving TTFT over standard 8-bit KV quantization by up to $1.43\times$ and improving accuracy over state-of-the-art by up to $5.1\%$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Lynx, a system for accelerating KV cache transfer in disaggregated long-context LLM inference via progressive speculative quantization. The KV cache is split into a high-priority Anchor stream (most significant bits capturing coarse attention structure) and a low-priority Residual stream (remaining bits); speculative decoding begins on the Anchor while the Residual transfers concurrently, followed by a verification step to ensure equivalence to full BF16 precision. The abstract claims TTFT comparable to aggressive 4-bit quantization, accuracy matching BF16, up to 1.43× TTFT improvement over standard 8-bit KV quantization, and up to 5.1% accuracy improvement over state-of-the-art across models and workloads.
Significance. If the empirical results and verification mechanism hold, Lynx addresses a practical bottleneck in network-bound long-context serving (RAG, agents) by enabling partial KV use without accuracy loss. The core observation on unequal bit contributions to attention is a potentially reusable insight for KV management, though its strength is not yet assessable from the provided abstract.
major comments (2)
- [Abstract] Abstract: performance numbers (1.43× TTFT, 5.1% accuracy) and the central claim of accuracy parity with BF16 are stated without any reference to experimental methodology, models, workloads, or data; the core bit-importance observation is plausible but unexamined here, preventing assessment of support for the claims.
- [Description of speculative verification (likely §4 or §5)] The load-bearing assumption that MSB-only (Anchor) attention produces speculative token sequences whose correctness can be verified for exact equivalence after Residual arrival, without net accuracy loss, is not supported by any analysis of rejection rates, distribution shift, or verification overhead; if many tokens are rejected the reported TTFT gains would not materialize.
minor comments (1)
- [Abstract] The abstract refers to 'multiple models and serving workloads' without naming them or providing a table of results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the clarity of our claims and the supporting analysis for the verification mechanism. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: performance numbers (1.43× TTFT, 5.1% accuracy) and the central claim of accuracy parity with BF16 are stated without any reference to experimental methodology, models, workloads, or data; the core bit-importance observation is plausible but unexamined here, preventing assessment of support for the claims.
Authors: The abstract is a concise summary; the specific models (Llama-2-7B/13B, Mistral-7B), workloads (RAG and long-context QA), methodology (bit partitioning, accuracy metrics vs. BF16), and bit-importance analysis appear in Sections 3, 5, and 6. We will revise the abstract to add brief references to the evaluation setup and models. revision: yes
-
Referee: [Description of speculative verification (likely §4 or §5)] The load-bearing assumption that MSB-only (Anchor) attention produces speculative token sequences whose correctness can be verified for exact equivalence after Residual arrival, without net accuracy loss, is not supported by any analysis of rejection rates, distribution shift, or verification overhead; if many tokens are rejected the reported TTFT gains would not materialize.
Authors: Section 4.3 describes the verification step, which recomputes attention with the complete Anchor+Residual KV cache upon arrival to enforce exact equivalence. The manuscript reports empirical rejection rates (typically <5% across workloads) and accounts for verification overhead in the TTFT results; distribution shift is limited because the Anchor preserves coarse attention structure. We will expand Section 4.3 with additional plots and discussion of rejection rates and overhead to strengthen the presentation. revision: partial
Circularity Check
No significant circularity; empirical systems technique with no derivation chain
full rationale
The paper describes an empirical systems contribution for progressive speculative KV cache transfer in disaggregated LLM inference. It relies on an observed empirical property (unequal bit contributions to attention) and reports measured TTFT/accuracy outcomes across models and workloads. No equations, parameter fitting, predictions derived from inputs, or self-citation chains appear in the provided text. The central claims rest on experimental results rather than any self-referential derivation, satisfying the default expectation of no circularity for non-derivational systems work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OCP Microscaling Formats (MX) Specification
2023. OCP Microscaling Formats (MX) Specification. https://www.op encompute.org/documents/ocp-microscaling-formats-mx-v1-0-spe c-final-pdf
2023
-
[2]
Ascend Documentation
2026. Ascend Documentation. https://www.hiascend.com/en/docume nt/
2026
-
[3]
LMCache-Ascend Repo
2026. LMCache-Ascend Repo. https://github.com/LMCache/LMCache -Ascend/commits/main/
2026
-
[4]
vLLM Ascend Repo
2026. vLLM Ascend Repo. https://github.com/vllm-project/vllm-asc end/tree/main/vllm_ascend
2026
-
[5]
Amey Agrawal, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhar- gav S Gulavani, and Ramachandran Ramjee. 2023. SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills.CoRR (2023)
2023
-
[6]
2025.Claude Code
Anthropic. 2025.Claude Code. https://github.com/anthropics/claude -code Accessed: 2026-02-03
2025
-
[7]
Yelysei Bondarenko, Markus Nagel, and Tijmen Blankevoort. 2023. Quantizable transformers: Removing outliers by helping attention heads do nothing.Advances in Neural Information Processing Systems 36 (2023), 75067–75096
2023
-
[8]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. 2023. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
2025.{IMPRESS}: An {Importance-Informed} {Multi-Tier} Prefix {KV} Storage System for Large Language Model Inference
Weijian Chen, Shuibing He, Haoyang Qu, Ruidong Zhang, Siling Yang, Ping Chen, Yi Zheng, Baoxing Huai, and Gang Chen. 2025.{IMPRESS}: An {Importance-Informed} {Multi-Tier} Prefix {KV} Storage System for Large Language Model Inference. In23rd USENIX Conference on File and Storage Technologies (FAST 25). 187–201
2025
-
[10]
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer
-
[11]
Advances in neural information processing systems35 (2022), 30318– 30332
LLM.int8 (): 8-bit matrix multiplication for transformers at scale. Advances in neural information processing systems35 (2022), 30318– 30332
2022
-
[12]
Roman Dubtsov, Evarist Fomenko, and Babak Hejazi. 2023. New cuBLAS 12.0 Features and Matrix Multiplication Performance on NVIDIA Hopper GPUs. https://developer.nvidia.com/blog/new-cubla s-12-0-features-and-matrix-multiplication-performance-on-nvidi a-hopper-gpus/. NVIDIA Technical Blog
2023
-
[13]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2022. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
2025.Gemini 3 Technical Report
Gemini Team, Google. 2025.Gemini 3 Technical Report. Technical Report. Google DeepMind. https://storage.googleapis.com/deepm ind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf Accessed: 2026-02-03
2025
-
[15]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Song Han, Huizi Mao, and William J. Dally. 2016. Deep Compression: Compressing Deep Neural Network with Pruning, Trained Quantiza- tion and Huffman Coding. In4th International Conference on Learn- ing Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, Yoshua Bengio and Yann LeCun (Eds.). http://arxiv.org/abs/1510.00149
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
Mohammadzadeh, Michael W
Coleman Hooper, Sehoon Kim, H. Mohammadzadeh, Michael W. Ma- honey, Kurt Keutzer, and Amir Gholami. 2024. KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[18]
n.d..Atlas 800I A2 Inference Server
Huawei. n.d..Atlas 800I A2 Inference Server. https://e.huawei.com/cn/ products/computing/ascend/atlas-800i-a2 Accessed: 2026-02-06. 13 SIGCOMM’18, August 21-23, 2018, Budapest, Hungary W. Han, G. Yeung, M. Barletta, W. Toner, A. Hoste, A. Barker
2026
-
[19]
2024.Ascend C Operator Development Guide
Huawei Technologies Co., Ltd. 2024.Ascend C Operator Development Guide. Huawei Ascend. https://www.hiascend.com/document/detail /en/canncommercial/800/opdevg/Ascendcopdevg/atlas_ascendc_10 _0008.html Accessed: 2025-02-05
2024
-
[20]
Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko
-
[21]
In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2704–2713. doi:10.1109/CV PR.2018.00286
work page doi:10.1109/cv 2018
-
[22]
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xu- fang Luo, Surin Ahn, Zhenhua Han, Amir H Abdi, Dongsheng Li, Chin-Yew Lin, et al. 2024. Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention.Advances in Neural Information Processing Systems37 (2024), 52481–52515
2024
-
[23]
Dhiraj D. Kalamkar, Dheevatsa Mudigere, Naveen Mellempudi, Di- pankar Das, Kunal Banerjee, Sasikanth Avancha, Dharma Teja Vooturi, Nataraj Jammalamadaka, Jianyu Huang, Hector Yuen, Jiyan Yang, Jongsoo Park, Alexander Heinecke, Evangelos Georganas, Sudar- shan Srinivasan, Abhisek Kundu, Misha Smelyanskiy, Bharat Kaul, and Pradeep Dubey. 2019. A Study of BF...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[24]
Andrey Kuzmin, Mart van Baalen, Yuwei Ren, Markus Nagel, Jorn Peters, and Tijmen Blankevoort. 2022. FP8 Quantization: The Power of the Exponent. InAdvances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35. Curran Associates, Inc., 14651–14662. https://proceedi ngs.neurips.cc/paper_...
2022
-
[25]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[26]
InProceedings of the 29th symposium on operating systems principles
Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles. 611–626
-
[27]
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning. PMLR, 19274–19286
2023
-
[28]
Xiaoyao Liang. 2020. Chapter 3 - Hardware architecture. InAscend AI Processor Architecture and Programming, Xiaoyao Liang (Ed.). Elsevier, 75–100. doi:10.1016/B978-0-12-823488-4.00003-5
-
[29]
Chin-Yew Lin and Franz Josef Och. 2004. Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics. InProceedings of the 42nd annual meeting of the association for computational linguistics (ACL-04). 605–612
2004
-
[30]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Guangxuan Xiao, and Song Han. 2025. AWQ: Activation-aware Weight Quantization for On- Device LLM Compression and Acceleration.GetMobile: Mobile Comp. and Comm.28, 4 (Jan. 2025), 12–17. doi:10.1145/3714983.3714987
-
[31]
Yujun Lin, Haotian Tang, Shang Yang, Zhekai Zhang, Guangxuan Xiao, Chuang Gan, and Song Han. 2025. Qserve: W4a8kv4 quantization and system co-design for efficient llm serving.Proceedings of Machine Learning and Systems7 (2025)
2025
-
[32]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al
-
[33]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. 2025. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
2025.COMET: Towards Practical W4A4KV4 LLMs Serving
Lian Liu, Long Cheng, Haimeng Ren, Zhaohui Xu, Yudong Pan, Mengdi Wang, Xiaowei Li, Yinhe Han, and Ying Wang. 2025.COMET: Towards Practical W4A4KV4 LLMs Serving. Association for Computing Machin- ery, New York, NY, USA, 131–146. https://doi.org/10.1145/3676641.37 16252
-
[36]
Yuhan Liu, Yihua Cheng, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaot- ing Feng, Yuyang Huang, Samuel Shen, Rui Zhang, Kuntai Du, et al
- [37]
-
[38]
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Anantha- narayanan, et al. 2024. Cachegen: Kv cache compression and streaming for fast large language model serving. InProceedings of the ACM SIG- COMM 2024 Conference. 38–56
2024
-
[39]
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. 2023. Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time.Advances in Neural Information Processing Systems36 (2023), 52342–52364
2023
-
[40]
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. 2024. KIVI: a tuning- free asymmetric 2bit quantization for KV cache. InProceedings of the 41st International Conference on Machine Learning. 32332–32344
2024
-
[41]
Mistral AI. 2025. Mistral Small 3. https://mistral.ai/news/mistral-sma ll-3/
2025
-
[42]
NVIDIA. 2025. NVIDIA Dynamo: A Low-Latency Distributed Inference Framework for Scaling Reasoning AI Models. https://developer.nvidia .com/blog/introducing-nvidia-dynamo-a-low-latency-distributed-i nference-framework-for-scaling-reasoning-ai-models/. Accessed: 2025-06-15
2025
-
[43]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 118–132
2024
-
[44]
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. 2024. YaRN: Efficient Context Window Extension of Large Language Models. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=wHBfxhZu1u
2024
-
[45]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. Mooncake: Trading more storage for less computation—a {KVCache-centric} architecture for serving {LLM} chatbot. In23rd USENIX Conference on File and Storage Technologies (FAST 25). 155–170
2025
-
[46]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He
-
[47]
InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 3505–3506
-
[48]
Luka Ribar, Ivan Chelombiev, Luke Hudlass-Galley, Charlie Blake, Carlo Luschi, and Douglas Orr. 2024. SparQ Attention: Bandwidth- Efficient LLM Inference. InInternational Conference on Machine Learn- ing. PMLR, 42558–42583
2024
-
[49]
Ohad Rubin, Jonathan Herzig, and Jonathan Berant. 2022. Learning To Retrieve Prompts for In-Context Learning. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2655–2666. doi:10.18653/v1/2022.naacl -main.191
-
[50]
Shay Vargaftik, Ran Ben-Basat, Amit Portnoy, Gal Mendelson, Yaniv Ben-Itzhak, and Michael Mitzenmacher. 2021. Drive: One-bit dis- tributed mean estimation.Advances in Neural Information Processing 14 Lynx: Progressive Speculative Quantization SIGCOMM’18, August 21-23, 2018, Budapest, Hungary Systems34 (2021), 362–377
2021
-
[51]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. At- tention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[52]
Weiyun Wang, Shuibo Zhang, Yiming Ren, Yuchen Duan, Tiantong Li, Shuo Liu, Mengkang Hu, Zhe Chen, Kaipeng Zhang, Lewei Lu, Xizhou Zhu, Ping Luo, Yu Qiao, Jifeng Dai, Wenqi Shao, and Wenhai Wang. 2024. Needle In A Multimodal Haystack. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, a...
-
[53]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chan- dra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. 2024. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.arXiv preprint arXiv:2406.01574 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain- of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Informa- tion Processing Systems(New Orleans, LA, USA)(NIPS ’22). Curran Associates Inc., Red Hook,...
2022
-
[55]
Xiuying Wei, Yunchen Zhang, Xiangguo Zhang, Ruihao Gong, Shang- hang Zhang, Qi Zhang, Fengwei Yu, and Xianglong Liu. 2022. Outlier suppression: Pushing the limit of low-bit transformer language models. Advances in Neural Information Processing Systems35 (2022), 17402– 17414
2022
-
[56]
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. 2023. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational conference on machine learning. PMLR, 38087–38099
2023
-
[57]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
-
[58]
Qwen3 Technical Report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
John Yang, Carlos E Jimenez, Alex L Zhang, Kilian Lieret, Joyce Yang, Xindi Wu, Ori Press, Niklas Muennighoff, Gabriel Synnaeve, Karthik R Narasimhan, et al . 2024. SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?CoRR(2024)
2024
- [60]
-
[61]
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. 2025. CacheBlend: Fast large language model serving for RAG with cached knowledge fu- sion. InProceedings of the Twentieth European Conference on Computer Systems. 94–109
2025
-
[62]
Shengnan Yue, Mowei Wang, Yu Yan, Weiqiang Cheng, Zihan Jiang, and Zhenhui Zhang. 2025. RTT-or Bandwidth-Bound? Demystifying the KV Cache Transfer in Large Language Model Serving. InProceed- ings of the 2nd Workshop on Networks for AI Computing. 5–7
2025
-
[63]
Zeyu Zhang, Haiying Shen, Shay Vargaftik, Ran Ben Basat, Michael Mitzenmacher, and Minlan Yu. 2025. Hack: Homomorphic acceleration via compression of the key-value cache for disaggregated llm inference. InProceedings of the ACM SIGCOMM 2025 Conference. 1245–1247
2025
-
[64]
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, and Baris Kasikci. 2024. Atom: Low-bit quantization for efficient and accurate llm serving.Proceedings of Machine Learning and Systems6 (2024), 196–209
2024
-
[65]
Ming Zhong, Da Yin, Tao Yu, Ahmad Zaidi, Mutethia Mutuma, Rahul Jha, Ahmed Hassan Awadallah, Asli Celikyilmaz, Yang Liu, Xipeng Qiu, and Dragomir Radev. 2021. QMSum: A New Benchmark for Query-based Multi-domain Meeting Summarization. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human ...
-
[66]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. {DistServe}: Disaggregat- ing prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 193–210
2024
-
[67]
Ruidong Zhu, Ziheng Jiang, Chao Jin, Peng Wu, Cesar A Stuardo, Dongyang Wang, Xinlei Zhang, Huaping Zhou, Haoran Wei, Yang Cheng, et al. 2025. Megascale-infer: Efficient mixture-of-experts model serving with disaggregated expert parallelism. InProceedings of the ACM SIGCOMM 2025 Conference. 592–608
2025
- [68]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.