Hierarchical Image Tokenization for Multi-Scale Image Super Resolution
Pith reviewed 2026-06-30 21:08 UTC · model grok-4.3
The pith
Hierarchical tokenization with scale overlap lets a 300M model do multi-scale super-resolution in one pass without extra data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By replacing standard residual quantization with Hierarchical Image Tokenization that enforces token overlap across scales and adding a Direct Preference Optimization term on low-resolution versus high-resolution pairs, visual auto-regressive training for image super-resolution becomes flexible enough to deliver multi-scale outputs from one forward pass, reach state-of-the-art performance with only 300 million parameters, and require no external annotated data.
What carries the argument
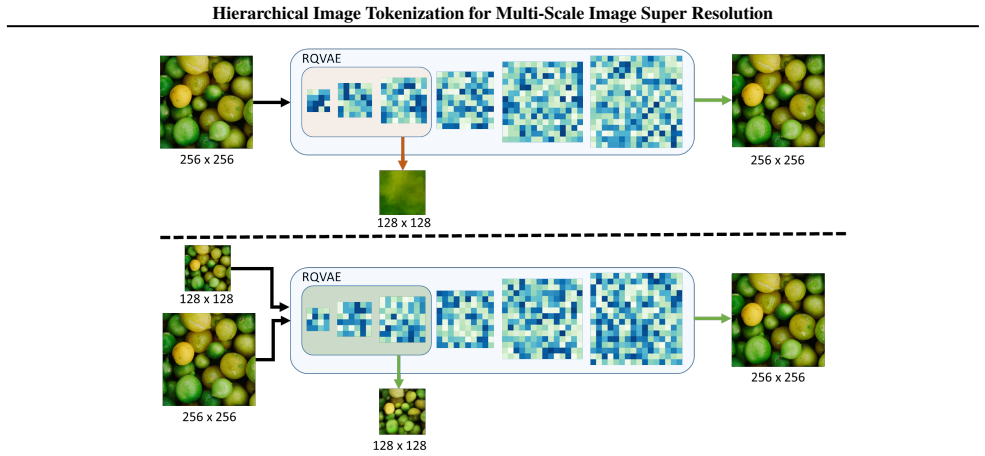
Hierarchical Image Tokenization (HIT): a progressive tokenization procedure that represents an image at multiple scales while enforcing overlap between tokens at successive scales inside residual quantization.
If this is right
- A single trained model produces consistent outputs at every intermediate scale instead of being locked to one fixed output resolution.
- Model size can be reduced from 1 billion to 300 million parameters while still beating prior VAR-based super-resolution methods.
- Training succeeds using only the low-resolution and high-resolution image pairs already present in ordinary super-resolution datasets.
- The same forward pass yields all scales, removing the need for separate models or repeated inference.
Where Pith is reading between the lines
- The overlap constraint may transfer to other residual-quantization generative tasks such as image editing or video prediction where consistent structure across resolutions is useful.
- Because the method avoids external data, it could be retrained quickly on domain-specific paired images such as medical or satellite imagery.
- The single-pass multi-scale property might allow progressive refinement pipelines in which a downstream task inspects an intermediate scale before deciding whether to continue to higher resolution.
Load-bearing premise
Enforcing token overlap across scales will give the transformer enough inductive bias to reach state-of-the-art performance with only 300 million parameters and no external data.
What would settle it
Train an otherwise identical 300M-parameter VAR model on the same low-high pairs but without the HIT overlap constraint and measure whether it still matches the reported state-of-the-art PSNR or perceptual scores on standard multi-scale super-resolution benchmarks.
Figures





read the original abstract
We introduce a multi-scale Image Super Resolution (ISR) method building on recent advances in Visual Auto-Regressive (VAR) modeling. VAR models break image tokenization into additive, gradually increasing scales, using Residual Quantization (RQ), an approach that aligns perfectly with our target ISR task. Previous works taking advantage of this synergy suffer from two main shortcomings. First, due to the limitations in RQ, they only generate images at a predefined fixed scale, failing to map intermediate outputs to the corresponding image scales. They also rely on large backbones or a large corpus of annotated data to achieve better performance. To address both shortcomings, we introduce two novel components to the VAR training for ISR, aiming at increasing its flexibility and reducing its complexity. In particular, we introduce a) a \textbf{Hierarchical Image Tokenization (HIT)} approach that progressively represents images at different scales while enforcing token overlap across scales, and b) a \textbf{Direct Preference Optimization (DPO) regularization term} that, relying solely on the (LR,HR) pair, encourages the transformer to produce the latter over the former. Our proposed HIT acts as a strong inductive bias for the VAR training, resulting in a small model (300M params vs 1B params of VARSR), that achieves state-of-the-art results without external training data, and that delivers multi-scale outputs with a single forward pass.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Hierarchical Image Tokenization (HIT) and a Direct Preference Optimization (DPO) regularization term to adapt Visual Auto-Regressive (VAR) models with Residual Quantization (RQ) for multi-scale image super-resolution (ISR). It claims that enforcing token overlap across scales via HIT provides a strong inductive bias, enabling a 300M-parameter model to achieve state-of-the-art multi-scale ISR results without external training data and to produce outputs at multiple scales in a single forward pass, overcoming limitations of prior VAR-based methods that require larger backbones (e.g., 1B params), annotated data, or fixed-scale generation.
Significance. If validated by experiments, the result would be significant for efficient multi-scale ISR, as it shows how a targeted tokenization scheme can reduce model size by a factor of three while eliminating external data needs and enabling flexible scale outputs. The alignment of RQ's additive scales with ISR is a natural fit, and the single-pass multi-scale capability addresses a practical gap in existing approaches.
major comments (1)
- [Abstract] Abstract: The central claim that HIT's enforced token overlap supplies a sufficiently strong inductive bias for 300M-param SOTA performance (vs. 1B-param VARSR) without external data is load-bearing for the contribution, yet the provided manuscript text contains no quantitative results, ablation studies isolating the overlap mechanism, or implementation details on preserving RQ's additive property. This prevents assessment of whether the inductive bias is adequate as asserted.
Simulated Author's Rebuttal
We thank the referee for their careful reading and the opportunity to clarify the presentation of our results. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that HIT's enforced token overlap supplies a sufficiently strong inductive bias for 300M-param SOTA performance (vs. 1B-param VARSR) without external data is load-bearing for the contribution, yet the provided manuscript text contains no quantitative results, ablation studies isolating the overlap mechanism, or implementation details on preserving RQ's additive property. This prevents assessment of whether the inductive bias is adequate as asserted.
Authors: We agree that the abstract, owing to length constraints, does not itself contain quantitative numbers, ablations, or implementation details. These elements appear in the full manuscript: quantitative comparisons establishing 300M-param SOTA performance versus the 1B-param baseline are reported in the experiments section and associated tables/figures; ablations that isolate the contribution of the enforced token overlap appear in the ablation study; and the method section details how the hierarchical tokenization is constructed so that RQ's additive residual property is preserved. To make the central claim easier to evaluate from the abstract alone, we will revise the abstract to incorporate concise quantitative highlights and explicit references to the supporting ablations and implementation choices. revision: yes
Circularity Check
No circularity: empirical claims rest on new components, not self-referential definitions or fits
full rationale
The paper introduces HIT (enforcing token overlap across scales) and a DPO term as novel additions to VAR training for multi-scale ISR. The central claim—that these yield a 300M model with SOTA results and single-pass multi-scale output—is presented as an empirical outcome, not a quantity derived by construction from fitted parameters or prior self-citations. No equations appear in the abstract that equate a 'prediction' to an input fit, and no uniqueness theorems or ansatzes are smuggled via self-citation. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Residual Quantization aligns perfectly with the ISR task
invented entities (1)
-
Hierarchical Image Tokenization (HIT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
and Timofte, R
Agustsson, E. and Timofte, R. NTIRE 2017 challenge on single image super-resolution: Dataset and study. InIEEE 9 Hierarchical Image Tokenization for Multi-Scale Image Super Resolution Conference on Computer Vision and Pattern Recognition - Workshops,
2017
-
[2]
Ntire 2024 challenge on image super-resolution (x4): Methods and results
Chen, Z., Wu, Z., Zamfir, E., Zhang, K., Zhang, Y ., Timofte, R., Yang, X., Yu, H., Wan, C., Hong, Y ., et al. Ntire 2024 challenge on image super-resolution (x4): Methods and results. InIEEE Conference on Computer Vision and Pattern Recognition, pp. 6108–6132,
2024
-
[3]
Swinir: Image restoration using swin transformer
Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L., and Tim- ofte, R. Swinir: Image restoration using swin transformer. arXiv preprint arXiv:2108.10257,
-
[4]
Liu, D., Zhao, S., Zhuo, L., Lin, W., Xin, Y ., Li, X., Qin, Q., Qiao, Y ., Li, H., and Gao, P. Lumina-mgpt: Illu- minate flexible photorealistic text-to-image generation 10 Hierarchical Image Tokenization for Multi-Scale Image Super Resolution with multimodal generative pretraining.arXiv preprint arXiv:2408.02657,
-
[5]
Ma, X., Zhou, M., Liang, T., Bai, Y ., Zhao, T., Chen, H., and Jin, Y . STAR: Scale-wise text-to-image genera- tion via auto-regressive representations.arXiv preprint arXiv:2406.10797,
-
[6]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Sun, P., Jiang, Y ., Chen, S., Zhang, S., Peng, B., Luo, P., and Yuan, Z. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
V ., Yang, M., and Zhang, L
Timofte, R., Agustsson, E., Gool, L. V ., Yang, M., and Zhang, L. NTIRE 2017 challenge on single image super- resolution: Methods and results. InIEEE Conference on Computer Vision and Pattern Recognition - Workshops,
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.