SG2Loc: Sequential Visual Localization on 3D Scene Graphs
Pith reviewed 2026-06-27 10:23 UTC · model grok-4.3
The pith
A compact 3D scene graph supports sequential visual localization by matching semantic image patches to projected object meshes in a particle filter.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
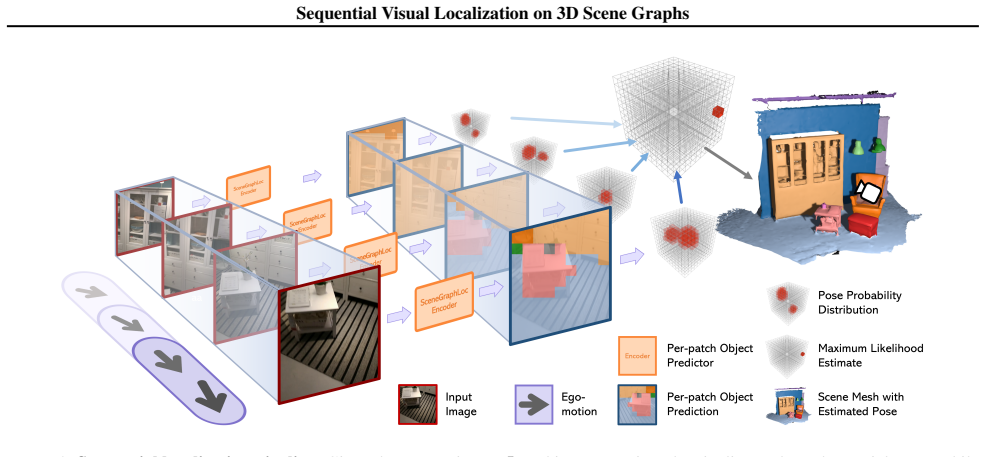
By representing the environment with a compact 3D scene graph of objects and spatial relationships, and performing localization via semantic feature matching in a particle filter that projects coarse meshes to assign object identities to image patches, the method achieves sequential pose estimation with lower storage overhead than traditional database-based approaches.
What carries the argument
The 3D scene graph whose nodes hold coarse object meshes and whose edges record spatial relations; it supplies the compact map that the particle filter projects and matches against per-patch semantic features to weight candidate poses.
If this is right
- Storage for the localization map shrinks to the size of the scene graph rather than collections of images or dense point clouds.
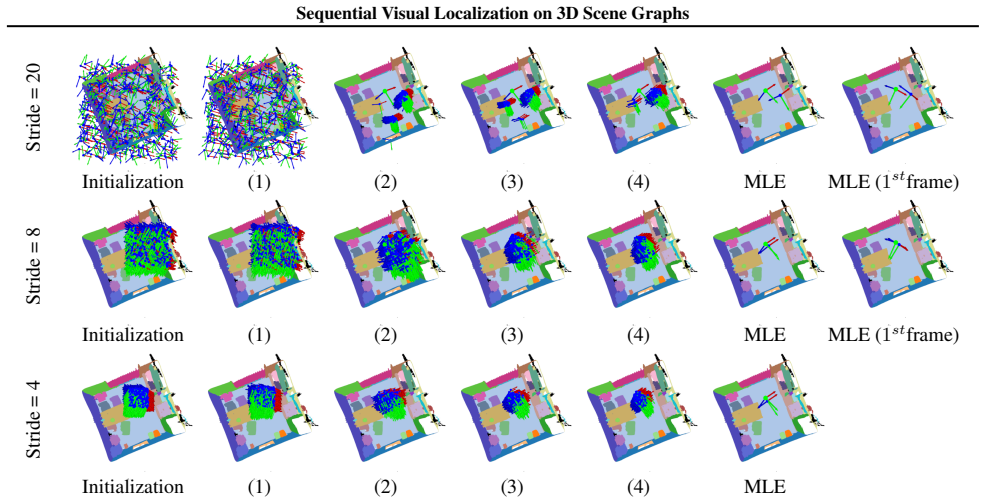
- Pose estimates are refined sequentially as each new image updates particle weights in the filter.
- Object identity assignment via projected mesh visibility enables semantic matching without requiring full geometric detail.
- Reported results claim that accuracy on real indoor datasets stays comparable to heavier methods.
Where Pith is reading between the lines
- Mobile or embedded devices with limited memory could perform localization without loading large map files.
- Extending the graph with online updates would let the system handle moderate scene changes.
- Pairing the semantic matcher with stronger object detectors might reduce failures in ambiguous regions.
- Evaluating the approach on larger or more dynamic indoor spaces would test whether coarse meshes remain sufficient.
Load-bearing premise
That per-patch semantic features extracted from input images can be predicted and matched to object identities assigned by projecting coarse meshes from the scene graph without major ambiguity or error in real indoor scenes.
What would settle it
Running the method on the real-world indoor datasets and finding that either localization error rises well above traditional baselines or that matching fails on a large fraction of patches would show the storage-reduction claim does not hold under the stated conditions.
Figures



read the original abstract
Visual localization in complex indoor environments remains a critical challenge for robotics and AR applications. Sequential localization, where pose estimates are refined over time, is important for autonomous agents. However, traditional methods often require storing extensive image databases or point clouds, leading to significant overhead. This paper introduces a novel, lightweight approach to sequential visual localization using 3D scene graphs. Our method represents the environment with a compact scene graph, where nodes represent objects (with coarse meshes) and edges encode spatial relationships. For each image in the localization phase, we extract per-patch semantic features, predicting object identities. Localization is performed within a particle filter framework. Each particle, representing a camera pose, projects the coarse object meshes from the scene graph into the image, assigning object identities to patches based on visibility. The similarity of the per-patch features, in the input image, and object features from the scene graph determines the weight of a particle. Subsequent images are incorporated sequentially, refining the pose estimate. By leveraging a compact scene graph and efficient semantic matching, our method significantly reduces storage while maintaining performance on real-world datasets. The code will be available at https://github.com/DmblnNicole/sg2loc.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SG2Loc for sequential visual localization in indoor environments. It replaces large image/point-cloud databases with a compact 3D scene graph whose nodes are objects equipped with coarse meshes and whose edges encode spatial relations. Per-patch semantic features are extracted from query images; a particle filter maintains pose hypotheses; each particle projects the coarse meshes into the current view to assign object identities to patches via visibility; particle weights are then set by the similarity between the observed per-patch features and the corresponding object features stored in the graph. Successive frames refine the estimate. The central claim is that the approach yields substantial storage reduction while preserving localization performance on real-world datasets.
Significance. If the performance parity claim is substantiated, the work would demonstrate a practical route to memory-efficient sequential localization by substituting dense geometric maps with semantically labeled coarse scene graphs. The integration of visibility-based identity assignment inside a particle filter is a coherent combination of standard components, and the stated intention to release code supports reproducibility.
major comments (2)
- [Abstract] Abstract: the assertion that the method 'significantly reduces storage while maintaining performance on real-world datasets' is unsupported by any quantitative metrics, baselines, ablation results, or error statistics. Without these data the central claim cannot be evaluated.
- [Abstract] Abstract (method description): object identities are assigned by projecting coarse meshes and using visibility; the resulting labels directly determine the feature-similarity likelihoods inside the particle filter. No quantitative bound is supplied on projection error, occlusion-induced mis-labeling, or ambiguity rate under typical indoor depth noise and partial views. This step is load-bearing for the storage-reduction claim.
minor comments (1)
- [Abstract] Abstract: the phrase 'predicting object identities' is used before the projection step is described; clarify whether an independent semantic classifier is applied or whether identity is obtained solely from the mesh projection.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript accordingly to strengthen the abstract and provide additional supporting analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the method 'significantly reduces storage while maintaining performance on real-world datasets' is unsupported by any quantitative metrics, baselines, ablation results, or error statistics. Without these data the central claim cannot be evaluated.
Authors: We agree that the abstract should explicitly summarize the quantitative evidence. The full manuscript (Section 4) reports storage reductions of over 90% relative to dense point-cloud or image-retrieval baselines while achieving comparable localization accuracy (within a few centimeters) on ScanNet and Matterport3D sequences. We will revise the abstract to include these key metrics, baselines, and error statistics so the central claim is directly supported. revision: yes
-
Referee: [Abstract] Abstract (method description): object identities are assigned by projecting coarse meshes and using visibility; the resulting labels directly determine the feature-similarity likelihoods inside the particle filter. No quantitative bound is supplied on projection error, occlusion-induced mis-labeling, or ambiguity rate under typical indoor depth noise and partial views. This step is load-bearing for the storage-reduction claim.
Authors: We acknowledge the need for explicit quantification of this core step. While end-to-end localization results on real datasets already reflect performance under realistic depth noise and partial views, we will add a dedicated analysis (new subsection or appendix) reporting measured labeling accuracy, mis-labeling rates due to projection/occlusion, and sensitivity to depth noise on the evaluation sequences. This will directly bound the reliability of the visibility-based assignment. revision: yes
Circularity Check
No circularity: method description contains no derivations or predictions
full rationale
The paper describes an algorithmic pipeline for sequential localization that combines scene-graph storage, per-patch semantic feature extraction, visibility-based object assignment via mesh projection, and particle-filter weighting by feature similarity. No equations, fitted parameters, predictions, or first-principles derivations appear in the provided text. The approach re-uses standard components (particle filters, semantic matching) without any step that reduces a claimed result to its own inputs by construction, self-citation load-bearing, or renaming. The storage-reduction claim is presented as an empirical outcome of the compact representation rather than a mathematical identity. This is the normal non-circular case for a systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
1913 , publisher=
Zur Ermittlung eines Objektes aus zwei Perspektiven mit innerer Orientierung , author=. 1913 , publisher=
1913
-
[2]
1980 , publisher=
Obstacle avoidance and navigation in the real world by a seeing robot rover , author=. 1980 , publisher=
1980
-
[3]
Communications of the ACM , volume=
Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography , author=. Communications of the ACM , volume=. 1981 , publisher=
1981
-
[4]
International journal of computer vision , volume=
Distinctive image features from scale-invariant keypoints , author=. International journal of computer vision , volume=. 2004 , publisher=
2004
-
[5]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
NetVLAD: CNN architecture for weakly supervised place recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[6]
Proceedings of the IEEE conference on computer vision and pattern recognition workshops , pages=
Superpoint: Self-supervised interest point detection and description , author=. Proceedings of the IEEE conference on computer vision and pattern recognition workshops , pages=
-
[7]
Advances in neural information processing systems , volume=
R2d2: Reliable and repeatable detector and descriptor , author=. Advances in neural information processing systems , volume=
-
[8]
Proceedings of the ieee/cvf conference on computer vision and pattern recognition , pages=
D2-net: A trainable cnn for joint description and detection of local features , author=. Proceedings of the ieee/cvf conference on computer vision and pattern recognition , pages=
-
[9]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Benchmarking 6dof outdoor visual localization in changing conditions , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[10]
Computer vision and image understanding , volume=
MLESAC: A new robust estimator with application to estimating image geometry , author=. Computer vision and image understanding , volume=. 2000 , publisher=
2000
-
[11]
2005 IEEE computer society conference on computer vision and pattern recognition (CVPR'05) , volume=
Matching with PROSAC-progressive sample consensus , author=. 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR'05) , volume=. 2005 , organization=
2005
-
[12]
European conference on computer vision , pages=
LSD-SLAM: Large-scale direct monocular SLAM , author=. European conference on computer vision , pages=. 2014 , organization=
2014
-
[13]
2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
LDSO: Direct sparse odometry with loop closure , author=. 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2018 , organization=
2018
-
[14]
2007 6th IEEE and ACM international symposium on mixed and augmented reality , pages=
Parallel tracking and mapping for small AR workspaces , author=. 2007 6th IEEE and ACM international symposium on mixed and augmented reality , pages=. 2007 , organization=
2007
-
[15]
IEEE transactions on robotics , volume=
ORB-SLAM: A versatile and accurate monocular SLAM system , author=. IEEE transactions on robotics , volume=. 2015 , publisher=
2015
-
[16]
IEEE transactions on robotics , volume=
Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras , author=. IEEE transactions on robotics , volume=. 2017 , publisher=
2017
-
[17]
The International Journal of Robotics Research , volume=
Keyframe-based visual--inertial odometry using nonlinear optimization , author=. The International Journal of Robotics Research , volume=. 2015 , publisher=
2015
-
[18]
IEEE transactions on robotics , volume=
Vins-mono: A robust and versatile monocular visual-inertial state estimator , author=. IEEE transactions on robotics , volume=. 2018 , publisher=
2018
-
[19]
2015 IEEE/RSJ international conference on intelligent robots and systems (IROS) , pages=
Robust visual inertial odometry using a direct EKF-based approach , author=. 2015 IEEE/RSJ international conference on intelligent robots and systems (IROS) , pages=. 2015 , organization=
2015
-
[20]
IEEE Transactions on Automatic Control , volume=
Intrinsic filtering on Lie groups with applications to attitude estimation , author=. IEEE Transactions on Automatic Control , volume=. 2014 , publisher=
2014
-
[21]
2014 IEEE international conference on robotics and automation (ICRA) , pages=
SVO: Fast semi-direct monocular visual odometry , author=. 2014 IEEE international conference on robotics and automation (ICRA) , pages=. 2014 , organization=
2014
-
[22]
2011 International Conference on Computer Vision , pages=
Fast image-based localization using direct 2d-to-3d matching , author=. 2011 International Conference on Computer Vision , pages=. 2011 , organization=
2011
-
[23]
European conference on computer vision , pages=
Worldwide pose estimation using 3d point clouds , author=. European conference on computer vision , pages=. 2012 , organization=
2012
-
[24]
IEEE transactions on pattern analysis and machine intelligence , volume=
Efficient & effective prioritized matching for large-scale image-based localization , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2016 , publisher=
2016
-
[25]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Large-scale location recognition and the geometric burstiness problem , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[26]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Dsac-differentiable ransac for camera localization , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[27]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Learning less is more-6d camera localization via 3d surface regression , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[28]
Proceedings of the IEEE international conference on computer vision , pages=
Posenet: A convolutional network for real-time 6-dof camera relocalization , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[29]
Proceedings of the IEEE international conference on computer vision , pages=
Image-based localization using lstms for structured feature correlation , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[30]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
3d scene graph: A structure for unified semantics, 3d space, and camera , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[31]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Image retrieval using scene graphs , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[32]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Visual translation embedding network for visual relation detection , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[33]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Multi-modal graph neural network for joint reasoning on vision and scene text , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[34]
Visual navigation via reinforcement learning and relational reasoning , author=. 2021 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/IOP/SCI) , pages=. 2021 , organization=
2021
-
[35]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Stochastic attraction-repulsion embedding for large scale image localization , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[36]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Patch-netvlad: Multi-scale fusion of locally-global descriptors for place recognition , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[37]
2019 IEEE international conference on image processing (ICIP) , pages=
Visual localization using sparse semantic 3D map , author=. 2019 IEEE international conference on image processing (ICIP) , pages=. 2019 , organization=
2019
-
[38]
Proceedings of the IEEE International Conference on Computer Vision , pages=
Hyperpoints and fine vocabularies for large-scale location recognition , author=. Proceedings of the IEEE International Conference on Computer Vision , pages=
-
[39]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Orienternet: Visual localization in 2d public maps with neural matching , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[40]
IEEE transactions on pattern analysis and machine intelligence , volume=
Self-supervised visual feature learning with deep neural networks: A survey , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2020 , publisher=
2020
-
[41]
IEEE transactions on pattern analysis and machine intelligence , volume=
Fine-tuning CNN image retrieval with no human annotation , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2018 , publisher=
2018
-
[42]
European Conference on Computer Vision , pages=
Scenegraphloc: Cross-modal coarse visual localization on 3d scene graphs , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[43]
IEEE transactions on robotics , volume=
Orb-slam3: An accurate open-source library for visual, visual--inertial, and multimap slam , author=. IEEE transactions on robotics , volume=. 2021 , publisher=
2021
-
[44]
Advances in neural information processing systems , volume=
KLD-sampling: Adaptive particle filters , author=. Advances in neural information processing systems , volume=
-
[45]
IEEE Robotics and Automation Letters , volume=
Clio: Real-time task-driven open-set 3d scene graphs , author=. IEEE Robotics and Automation Letters , volume=. 2024 , publisher=
2024
-
[46]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Rio: 3d object instance re-localization in changing indoor environments , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[47]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Scannet: Richly-annotated 3d reconstructions of indoor scenes , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[48]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Scenegraphfusion: Incremental 3d scene graph prediction from rgb-d sequences , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[49]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
From coarse to fine: Robust hierarchical localization at large scale , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[50]
European Conference on Computer Vision , pages=
Meshloc: Mesh-based visual localization , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[51]
European Conference on Computer Vision , pages=
Geocalib: Learning single-image calibration with geometric optimization , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[52]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Superglue: Learning feature matching with graph neural networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[53]
IEEE Robotics and Automation Letters , volume=
Anyloc: Towards universal visual place recognition , author=. IEEE Robotics and Automation Letters , volume=. 2023 , publisher=
2023
-
[54]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Correlation verification for image retrieval , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[55]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Roma: Robust dense feature matching , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[56]
Viktor Larsson and contributors , URL =
-
[57]
ACM Transactions on Graphics (ToG) , volume=
Bundlefusion: Real-time globally consistent 3d reconstruction using on-the-fly surface reintegration , author=. ACM Transactions on Graphics (ToG) , volume=. 2017 , publisher=
2017
-
[58]
Advances in neural information processing systems , volume=
Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras , author=. Advances in neural information processing systems , volume=
-
[59]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Glace: Global local accelerated coordinate encoding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[60]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Accelerated coordinate encoding: Learning to relocalize in minutes using rgb and poses , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[61]
arXiv preprint arXiv:2104.06697 , year=
Revisiting hierarchical approach for persistent long-term video prediction , author=. arXiv preprint arXiv:2104.06697 , year=
-
[62]
The International Journal of Robotics Research , volume=
Large-scale, real-time visual--inertial localization revisited , author=. The International Journal of Robotics Research , volume=. 2020 , publisher=
2020
-
[63]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Kfnet: Learning temporal camera relocalization using kalman filtering , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[64]
IEEE Robotics and Automation Letters , volume=
maplab: An open framework for research in visual-inertial mapping and localization , author=. IEEE Robotics and Automation Letters , volume=. 2018 , publisher=
2018
-
[65]
arXiv preprint arXiv:2209.09050 , year=
Loc-nerf: Monte carlo localization using neural radiance fields , author=. arXiv preprint arXiv:2209.09050 , year=
-
[66]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Mast3r-slam: Real-time dense slam with 3d reconstruction priors , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[67]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Megaloc: One retrieval to place them all , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[68]
Advances in Neural Information Processing Systems , volume=
Vggt-slam: Dense rgb slam optimized on the sl (4) manifold , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
arXiv preprint arXiv:2508.18242 , year=
GSVisLoc: Generalizable Visual Localization for Gaussian Splatting Scene Representations , author=. arXiv preprint arXiv:2508.18242 , year=
-
[70]
IEEE Transactions on Cognitive and Developmental Systems , year=
Nurf: Nudging the particle filter in radiance fields for robot visual localization , author=. IEEE Transactions on Cognitive and Developmental Systems , year=
-
[71]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
F3Loc: Fusion and filtering for floorplan localization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[72]
IEEE Robotics and Automation Letters , volume=
Vision-only robot navigation in a neural radiance world , author=. IEEE Robotics and Automation Letters , volume=. 2022 , publisher=
2022
-
[73]
International Conference on Learning Representations , volume=
GS-CPR: Efficient camera pose refinement via 3d gaussian splatting , author=. International Conference on Learning Representations , volume=
-
[74]
Roma v2: Harder better faster denser feature matching.arXiv preprint arXiv:2511.15706, 2025
RoMa v2: Harder Better Faster Denser Feature Matching , author=. arXiv preprint arXiv:2511.15706 , year=
-
[75]
2020 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Openvins: A research platform for visual-inertial estimation , author=. 2020 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2020 , organization=
2020
-
[76]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Learning with average precision: Training image retrieval with a listwise loss , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[77]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Gqa: A new dataset for real-world visual reasoning and compositional question answering , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[78]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Learning 3d semantic scene graphs from 3d indoor reconstructions , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[79]
European Conference on Computer Vision , pages=
Scalable 6-DOF localization on mobile devices , author=. European Conference on Computer Vision , pages=. 2014 , organization=
2014
-
[80]
IEEE transactions on pattern analysis and machine intelligence , volume=
Direct sparse odometry , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2017 , publisher=
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.