Automatically Differentiable Nonlinear Tensor Networks (ADNTNs) for Exponential Compression of Deep Neural Networks
Pith reviewed 2026-06-29 08:17 UTC · model grok-4.3
The pith
Nonlinear tensor networks generate neural network weights from compact cores, achieving thousands-fold compression per layer while preserving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
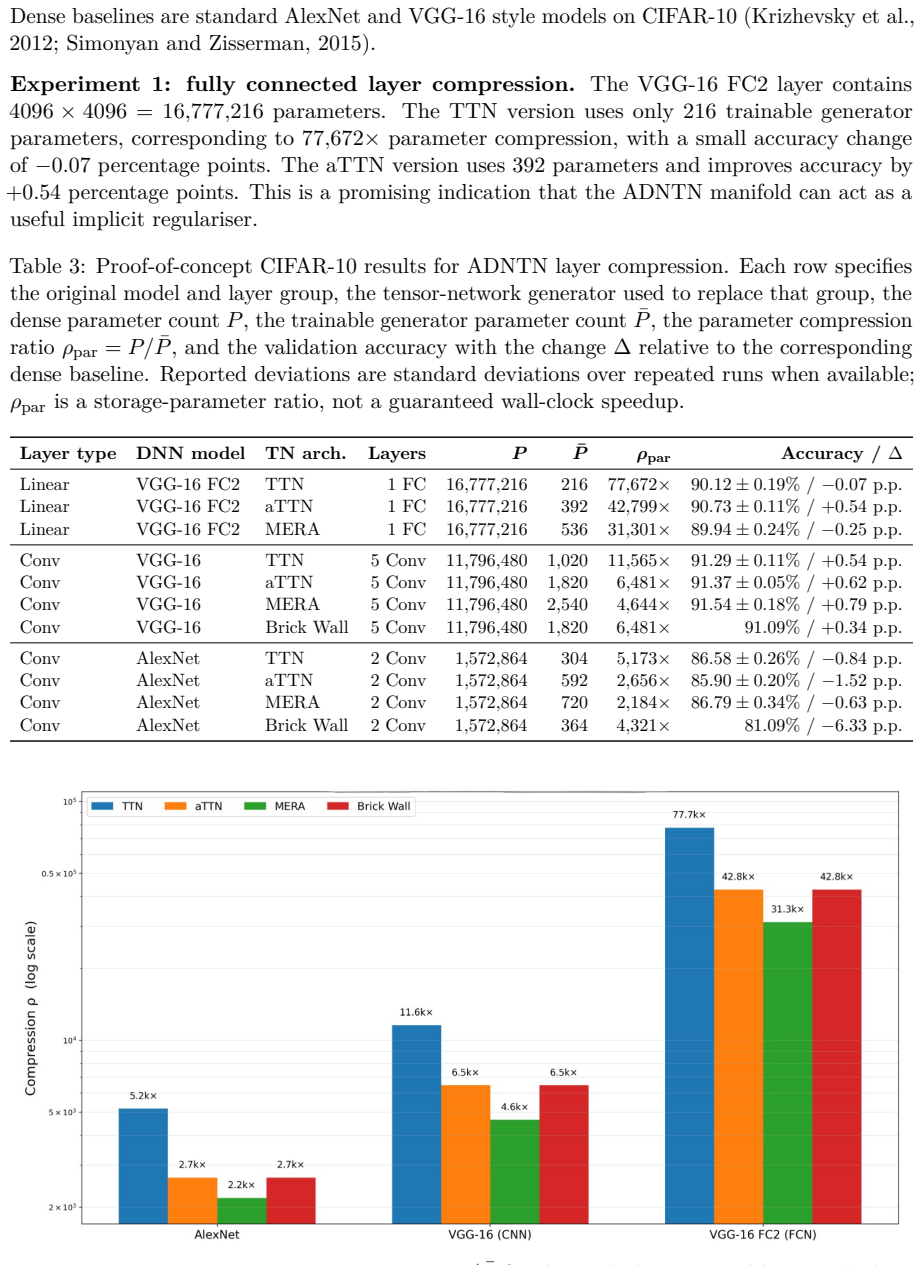
ADNTNs construct large weight tensors through a hierarchy of small core tensors, nonlinear activations, and optional lateral mixing tensors, trained end-to-end by reverse-mode automatic differentiation. Simulations replacing layers in AlexNet and VGG-16 show per-layer compression ratios from roughly 2000× to 77000×, with accuracy often matching the dense baseline and improving it in several VGG-16 cases.
What carries the argument
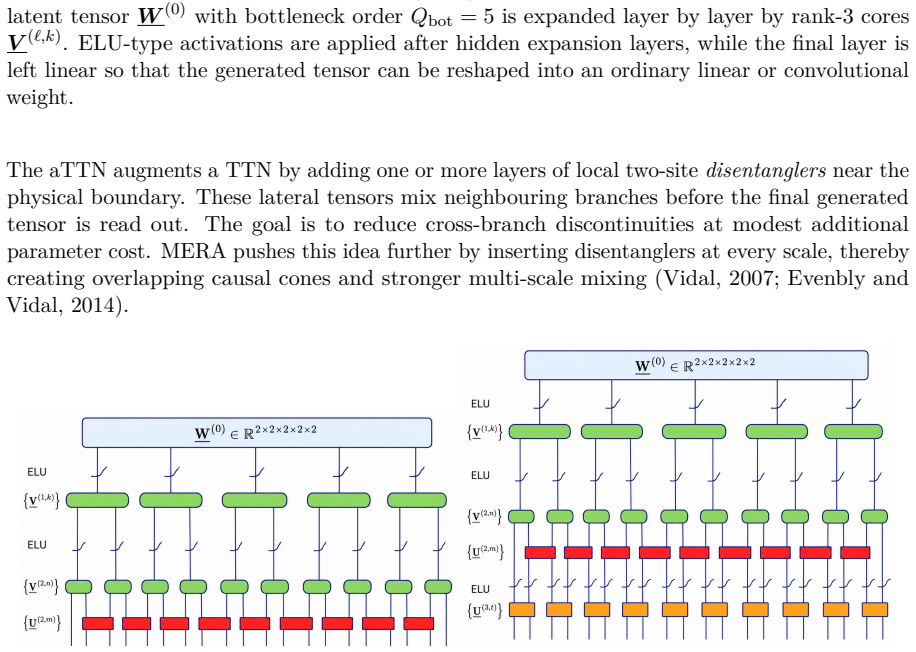
Automatically Differentiable Nonlinear Tensor Networks (ADNTNs) using Tree Tensor Networks (TTNs), augmented TTNs (aTTNs) with boundary disentanglers, and Multi-scale Entanglement Renormalisation Ansatz (MERA) topologies to generate weights from compact cores.
If this is right
- Convolutional layers in standard models can be replaced by these structured generators while supporting batching and task-aware objectives.
- End-to-end training remains possible via reverse-mode automatic differentiation even though the weight tensor is generated from cores.
- Per-layer compression reaches the reported range of 2000× to 77000× on the tested AlexNet and VGG-16 layers.
- Hardware-aware execution schedules can be incorporated without changing the differentiation process.
Where Pith is reading between the lines
- The same hierarchical core approach might extend to attention or linear layers in transformers if suitable contraction orders are found.
- Joint design of contraction schedules and deployment kernels could further reduce memory traffic beyond the reported compression.
- The distinction between differentiating a contraction program and removing its computational cost suggests that specialized tensor hardware would still be needed for large-scale use.
Load-bearing premise
The chosen tensor network topologies combined with nonlinear activations can represent the weight functions required by the target layers without substantial loss of expressivity or trainability.
What would settle it
Replacing a convolutional layer in VGG-16 with an ADNTN of the claimed compression ratio and measuring whether top-1 accuracy falls more than a few percent below the dense baseline after training.
Figures




read the original abstract
We study Automatically Differentiable Nonlinear Tensor Networks (ADNTNs), a family of structured weight generators whose compact core tensors are trained end-to-end by reverse-mode automatic differentiation (AD). The approach can be viewed as a natural extension of low-rank adaptation and tensor factorisation: instead of using one low-rank matrix update, an ADNTN builds a large weight tensor through a hierarchy of small cores, nonlinear activations, and optional lateral mixing tensors. The paper focuses on three architectures: Tree Tensor Networks (TTNs), augmented TTNs (aTTNs) with boundary disentanglers, and Multi-scale Entanglement Renormalisation Ansatze (MERA). The formulation supports nonlinear activations, task-aware objectives, batching, and hardware-aware execution schedules. At the same time, the paper keeps a clear distinction between \emph{differentiating} a contraction program and making contraction free: AD does not remove the cost of large intermediates, poor contraction orders, or exact contraction of general loopy tensor networks. Extensive simulations on AlexNet and VGG-16 layers show per-layer compression ratios from roughly $2000\times$ to $77000\times$ in the studied settings, with accuracy often matching the dense baseline and, in several VGG-16 cases, improving it. These results are encouraging rather than final: they suggest that ADNTNs are a promising, mathematically structured, and hardware-aware route toward much smaller neural networks, provided that optimisation, contraction schedules, and deployment kernels are designed together.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Automatically Differentiable Nonlinear Tensor Networks (ADNTNs) as structured weight generators that build large tensors from compact core tensors via hierarchies of tensor network cores (TTN, aTTN, MERA), nonlinear activations, and optional lateral mixing, trained end-to-end by reverse-mode AD. It reports per-layer compression ratios of roughly 2000×–77000× on AlexNet and VGG-16 layers, with accuracy often matching the dense baseline and sometimes exceeding it.
Significance. If the results hold, the work offers a mathematically structured and hardware-aware route to exponential DNN compression that extends low-rank adaptation by incorporating tensor-network factorizations and nonlinearity while preserving end-to-end differentiability. The explicit distinction between differentiating a contraction program and eliminating the cost of large intermediates is a useful clarification.
major comments (1)
- [Abstract] Abstract: the central empirical claim of 2000×–77000× compression with maintained or improved accuracy rests on the assumption that TTN/aTTN/MERA topologies plus nonlinear activations are sufficiently universal to represent the target convolutional weight tensors without substantial expressivity loss; no approximation theorem, universality argument, or controlled reconstruction test on random tensors of matching shape is supplied to support this.
minor comments (1)
- [Abstract] Abstract: the description of 'extensive simulations' supplies no information on experimental controls, statistical significance testing, exact layer replacements, or contraction-order implementations, which would improve reproducibility and assessment of the reported ratios and accuracy figures.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The single major comment raises a valid point about the empirical nature of our claims. We respond point-by-point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of 2000×–77000× compression with maintained or improved accuracy rests on the assumption that TTN/aTTN/MERA topologies plus nonlinear activations are sufficiently universal to represent the target convolutional weight tensors without substantial expressivity loss; no approximation theorem, universality argument, or controlled reconstruction test on random tensors of matching shape is supplied to support this.
Authors: We agree that the paper does not supply a universality theorem, approximation bound, or reconstruction experiments on random tensors. Our contribution is empirical rather than theoretical: we demonstrate that the chosen TTN/aTTN/MERA topologies with nonlinear activations and lateral mixing, when trained end-to-end via reverse-mode AD, can represent the specific convolutional weight tensors arising in AlexNet and VGG-16 layers at the reported compression ratios while preserving (or in some VGG-16 cases improving) task accuracy. The abstract already qualifies the results as “encouraging rather than final” and frames them as a “promising … route,” but we will revise the abstract and add a short paragraph in the introduction to explicitly state that no universality claim is made and that expressivity is validated only on the practical weight tensors studied. A controlled test on random tensors would address a different question (whether the ansatz class is dense in the space of all tensors of the given shape) that lies outside the scope of the present work, which focuses on task-aware, hardware-aware compression of real DNN layers. revision: partial
Circularity Check
No circularity; results are empirical outcomes of training and evaluation.
full rationale
The paper introduces ADNTNs as structured weight generators trained end-to-end via automatic differentiation on AlexNet and VGG-16 layers. Reported per-layer compression ratios (2000×–77000×) and accuracy metrics are measured post-training against dense baselines, not derived by construction from fitted parameters, self-definitions, or self-citation chains. No equations or steps in the abstract or described content reduce the central claims to tautological inputs; the derivation chain consists of architectural choices followed by independent simulation results.
Axiom & Free-Parameter Ledger
free parameters (1)
- core tensor ranks and sizes
axioms (1)
- domain assumption Hierarchical tensor networks with nonlinear activations can faithfully represent the weight tensors needed for the target CNN layers
invented entities (1)
-
ADNTN (Automatically Differentiable Nonlinear Tensor Network)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., Corrado, G.S., Davis, A., Dean, J., Devin, M. et al. (2016) `TensorFlow: Large-scale machine learning on heterogeneous distributed systems', arXiv preprint, arXiv:1603.04467
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
and Siskind, J.M
Baydin, A.G., Pearlmutter, B.A., Radul, A.A. and Siskind, J.M. (2018) `Automatic differentiation in machine learning: a survey', Journal of Machine Learning Research, 18(153), pp. 1--43
2018
-
[3]
and Guttag, J
Blalock, D., Ortiz, J.J.G., Frankle, J. and Guttag, J. (2020) `What is the state of neural network pruning?', Proceedings of Machine Learning and Systems, 2, pp. 129--146
2020
-
[4]
and Townsend, A
Boull\' e , N., Nakatsukasa, Y. and Townsend, A. (2020) `Rational neural networks', Advances in Neural Information Processing Systems, 33, pp. 14243--14253
2020
-
[5]
and Wanderman-Milne, S
Bradbury, J., Frostig, R., Hawkins, P., Johnson, M.J., Leary, C., Maclaurin, D. and Wanderman-Milne, S. (2018) JAX: composable transformations of Python+NumPy programs. Available at: https://github.com/jax-ml/jax
2018
-
[6]
and Hao, W
Chen, C., Yang, Y., Xiang, Y. and Hao, W. (2025) `Automatic differentiation is essential in training neural networks for solving differential equations', Journal of Scientific Computing, 104, Article 54
2025
-
[7]
and Mandic, D.P
Cichocki, A., Lee, N., Oseledets, I.V., Phan, A.-H., Zhao, Q. and Mandic, D.P. (2016) `Tensor networks for dimensionality reduction and large-scale optimisation: Part 1 low-rank tensor decompositions', Foundations and Trends in Machine Learning, 9(4--5), pp. 249--429
2016
-
[8]
and Mandic, D
Cichocki, A., Phan, A.H., Zhao, Q., Lee, N., Oseledets, I., Sugiyama, M. and Mandic, D. (2017) `Tensor networks for dimensionality reduction and large-scale optimisation: Part 2 applications and future perspectives', Foundations and Trends in Machine Learning, 9(6), pp. 431--673
2017
-
[9]
Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs)
Clevert, D.-A., Unterthiner, T. and Hochreiter, S. (2015) `Fast and accurate deep network learning by exponential linear units (ELUs)', arXiv preprint, arXiv:1511.07289
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
and Zettlemoyer, L
Dettmers, T., Pagnoni, A., Holtzman, A. and Zettlemoyer, L. (2023) `QLoRA: Efficient finetuning of quantized LLMs', Advances in Neural Information Processing Systems, 36
2023
-
[11]
(2010) Automatic Differentiation and Neural Networks, lecture notes, University of Massachusetts Amherst
Domke, J. (2010) Automatic Differentiation and Neural Networks, lecture notes, University of Massachusetts Amherst. Available at: https://people.cs.umass.edu/ domke/courses/sml2010/07autodiff_nnets.pdf (Accessed: 19 May 2026)
2010
-
[12]
and Vidal, G
Evenbly, G. and Vidal, G. (2014) `Algorithms for entanglement renormalization', Physical Review B, 89(23), Article 235113
2014
-
[13]
and Alistarh, D
Frantar, E., Ashkboos, S., Hoefler, T. and Alistarh, D. (2023) `GPTQ: Accurate post-training quantization for generative pre-trained transformers', International Conference on Learning Representations
2023
-
[14]
and Winslett, M
Ganesh, P., Chen, Y., Lou, X., Khan, M.A., Yang, Y., Sajjad, H., Nakov, P., Chen, D. and Winslett, M. (2020) `Compression of deep learning models for text: A survey', ACM Transactions on Knowledge Discovery from Data, 15(5), Article 78
2020
-
[15]
and Bengio, Y
Glorot, X. and Bengio, Y. (2010) `Understanding the difficulty of training deep feedforward neural networks', Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, pp. 249--256
2010
-
[16]
and Mandic, D.P
Gu, Y., Zhou, W., Iacovides, G. and Mandic, D.P. (2025) `TensorLLM: Tensorising multi-head attention for enhanced reasoning and compression in LLMs', Proceedings of the International Joint Conference on Neural Networks (IJCNN), pp. 1--8
2025
-
[17]
and Oseledets, I
Gusak, J., Kholiavchenko, M., Ponomarev, E., Markeeva, L., Blagoveschensky, P., Cichocki, A. and Oseledets, I. (2019) `Automated multi-stage compression of neural networks', Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops
2019
-
[18]
(2024) `Introduction to automatic differentiation and neural differentiation', Proceedings of Science and Mathematics, 4(1), pp
Halim, M.A.S. (2024) `Introduction to automatic differentiation and neural differentiation', Proceedings of Science and Mathematics, 4(1), pp. 81--89
2024
-
[19]
and Dally, W.J
Han, S., Mao, H. and Dally, W.J. (2016) `Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding', International Conference on Learning Representations
2016
-
[20]
and Sun, J
He, K., Zhang, X., Ren, S. and Sun, J. (2015) `Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification', IEEE International Conference on Computer Vision, pp. 1026--1034
2015
-
[21]
Gaussian Error Linear Units (GELUs)
Hendrycks, D. and Gimpel, K. (2016) `Gaussian error linear units (GELUs)', arXiv preprint, arXiv:1606.08415
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[22]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O. and Dean, J. (2015) `Distilling the knowledge in a neural network', arXiv preprint, arXiv:1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[23]
(2024) `What is automatic differentiation?', Hugging Face Blog
Holm, A. (2024) `What is automatic differentiation?', Hugging Face Blog. Available at: https://huggingface.co/blog/andmholm/what-is-automatic-differentiation (Accessed: 19 May 2026)
2024
-
[24]
and Chen, W
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L. and Chen, W. (2022) `LoRA: Low-rank adaptation of large language models', International Conference on Learning Representations
2022
-
[25]
Javanmard, Y., Pandit, T. and Mardani, M. (2026) `Compressing transformer language models via Matrix Product Operator decomposition: A case study on PicoGPT', arXiv preprint, arXiv:2603.28534
-
[26]
and Ba, J
Kingma, D.P. and Ba, J. (2015) `Adam: A method for stochastic optimisation', International Conference on Learning Representations
2015
-
[27]
and Bader, B.W
Kolda, T.G. and Bader, B.W. (2009) `Tensor decompositions and applications', SIAM Review, 51(3), pp. 455--500
2009
-
[28]
and Hinton, G.E
Krizhevsky, A., Sutskever, I. and Hinton, G.E. (2012) `ImageNet classification with deep convolutional neural networks', Advances in Neural Information Processing Systems, 25
2012
-
[29]
and Vandewalle, J
De Lathauwer, L., De Moor, B. and Vandewalle, J. (2000) `A multilinear singular value decomposition', SIAM Journal on Matrix Analysis and Applications, 21(4), pp. 1253--1278
2000
-
[30]
and Xiang, T
Liao, H.-J., Liu, J.-G., Wang, L. and Xiang, T. (2019) `Differentiable programming tensor networks', Physical Review X, 9(3), Article 031041
2019
-
[31]
Liao, H.-J. and Liu, Z.-Y. (2021) `Differentiable programming of isometric tensor networks', arXiv preprint, arXiv:2110.03898
-
[32]
and Hutter, F
Loshchilov, I. and Hutter, F. (2019) `Decoupled weight decay regularization', International Conference on Learning Representations
2019
-
[33]
and Vetrov, D.P
Novikov, A., Podoprikhin, D., Osokin, A. and Vetrov, D.P. (2015) `Tensorising neural networks', Advances in Neural Information Processing Systems, 28, pp. 442--450
2015
-
[34]
(2014) `A practical introduction to tensor networks: matrix product states and projected entangled pair states', Annals of Physics, 349, pp
Or\' u s, R. (2014) `A practical introduction to tensor networks: matrix product states and projected entangled pair states', Annals of Physics, 349, pp. 117--158
2014
-
[35]
(2011) `Tensor-train decomposition', SIAM Journal on Scientific Computing, 33(5), pp
Oseledets, I.V. (2011) `Tensor-train decomposition', SIAM Journal on Scientific Computing, 33(5), pp. 2295--2317
2011
-
[36]
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L. et al. (2019) `PyTorch: An imperative style, high-performance deep learning library', Advances in Neural Information Processing Systems, 32
2019
-
[37]
and Cichocki, A
Phan, A.H., Sobolev, K., Sozykin, K., Ermilov, D., Gusak, J., Tichavsk\' y , P. and Cichocki, A. (2020) `Stable low-rank tensor decomposition for compression of convolutional neural networks', European Conference on Computer Vision, Springer, pp. 522--539
2020
-
[38]
and Ran, S.-J
Qing, Y., Li, K., Zhou, P.-F. and Ran, S.-J. (2025) `Compressing neural networks using tensor networks with exponentially fewer variational parameters', Intelligent Computing, 4, Article 0123
2025
-
[39]
Searching for Activation Functions
Ramachandran, P., Zoph, B. and Le, Q.V. (2017) `Searching for activation functions', arXiv preprint, arXiv:1710.05941
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
and Lewenstein, M
Ran, S.-J., Tirrito, E., Peng, C., Chen, X., Tagliacozzo, L., Su, G. and Lewenstein, M. (2020) Tensor Network Contractions: Methods and Applications to Quantum Many-Body Systems, Springer, Cham
2020
-
[41]
and Vidal, G
Shi, Y.-Y., Duan, L.-M. and Vidal, G. (2006) `Classical simulation of quantum many-body systems with a tree tensor network', Physical Review A, 74(2), Article 022320
2006
-
[42]
and Zisserman, A
Simonyan, K. and Zisserman, A. (2015) `Very deep convolutional networks for large-scale image recognition', International Conference on Learning Representations
2015
-
[43]
and Wetzstein, G
Sitzmann, V., Martel, J.N.P., Bergman, A.W., Lindell, D.B. and Wetzstein, G. (2020) `Implicit neural representations with periodic activation functions', Advances in Neural Information Processing Systems, 33, pp. 7462--7473
2020
-
[44]
and Schwab, D.J
Stoudenmire, E.M. and Schwab, D.J. (2016) `Supervised learning with tensor networks', Advances in Neural Information Processing Systems, 29
2016
-
[45]
(2007) `Entanglement renormalization', Physical Review Letters, 99(22), Article 220405
Vidal, G. (2007) `Entanglement renormalization', Physical Review Letters, 99(22), Article 220405
2007
-
[46]
Tensor networks meet neural networks: A survey and future perspectives
Wang, M., Pan, Y., Xu, Z., Li, G., Yang, X., Mandic, D. and Cichocki, A. (2023) `Tensor networks meet neural networks: A survey and future perspectives', arXiv preprint, arXiv:2302.09019
-
[47]
Zhao, Q., Zhou, G., Xie, S., Zhang, L. and Cichocki, A. (2016) `Tensor ring decomposition', arXiv preprint, arXiv:1606.05535
work page internal anchor Pith review Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.