Universal CT Representations from Anatomy to Disease Phenotype through Agglomerative Pretraining
Pith reviewed 2026-05-22 07:47 UTC · model grok-4.3
The pith
A single CT foundation model trained in three agglomerative stages matches or exceeds task-specific models across five clinical task families.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
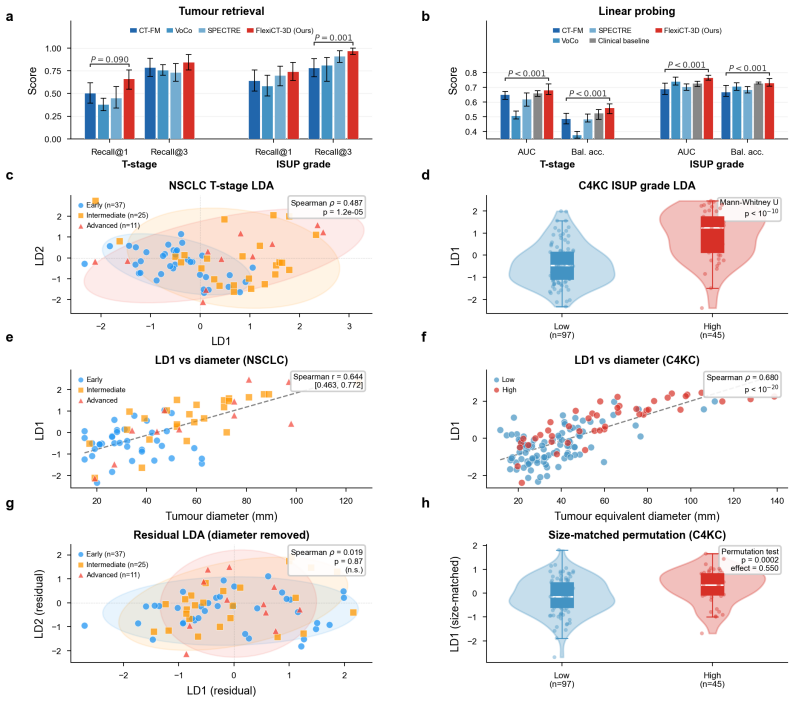
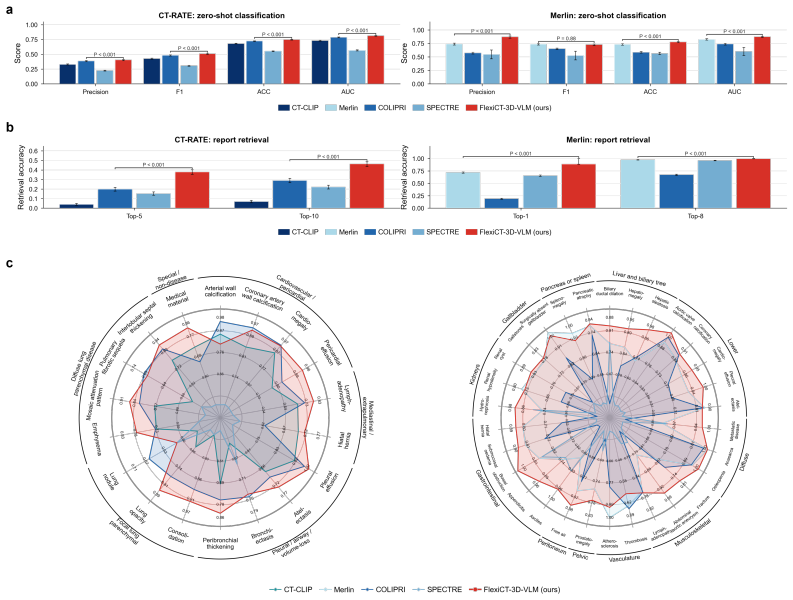
FlexiCT is trained by agglomerative continual pretraining in three stages—two-dimensional axial pretraining, three-dimensional anatomical pretraining, and report-guided semantic alignment—on 266,227 CT volumes from 56 publicly available datasets. The resulting representations match or exceed prior task-specific approaches on benchmarks spanning segmentation, classification, registration, vision-language understanding, and clinical retrieval. The same embeddings further organize scans along gradients linked to tumor stage progression.
What carries the argument
Three-stage agglomerative continual pretraining that progressively builds slice-level, volume-level, and vision-language representations from the same data pool.
If this is right
- One model family supports slice-level, volume-level, and vision-language analysis without retraining from scratch.
- Embeddings capture disease phenotype information such as tumor stage gradients even without explicit supervision for those labels.
- A public checkpoint and code release creates a shared starting point for new CT tasks instead of training each one separately.
- Clinical retrieval and report alignment become feasible using the same representation space built for imaging tasks.
Where Pith is reading between the lines
- The same staged pretraining recipe could be tried on MRI or PET to test whether modality-specific foundations emerge without starting from scratch each time.
- If the tumor-stage organization generalizes, the embeddings might support longitudinal tracking of individual patients across multiple scans.
- Evaluating the model on private multi-center data with scanner and demographic shifts would directly test whether the public-data pretraining is sufficient for broad deployment.
Load-bearing premise
The 56 public datasets are representative of clinical practice and free of leakage so that the learned representations transfer to new patient populations and scanners.
What would settle it
A clear drop in performance relative to task-specific baselines when the model is tested on CT data from a previously unseen hospital network or scanner vendor would show the representations are not yet universal.
Figures




read the original abstract
Computed tomography (CT) is a central to three-dimensional medical imaging, yet CT-based artificial intelligence remains fragmented across task-specific models for segmentation, classification, registration, and report analysis. Here we present FlexiCT, a family of CT foundation models trained by agglomerative continual pretraining on 266,227 CT volumes from 56 publicly available datasets, forming a large-scale public resource for CT representation learning. FlexiCT uses agglomerative pretraining across three stages: two-dimensional axial pretraining, three-dimensional anatomical pretraining and report-guided semantic alignment. This training strategy supports slice-level, volume-level and vision-language analysis. Across five downstream task families (segmentation, classification, registration, vision-language understanding and clinical retrieval), FlexiCT matches or exceeds prior task-specific approaches on multiple benchmarks. Its embeddings further organize CT scans along gradients associated with various tumor stages, suggesting that CT foundation models can capture imaging features relevant to disease phenotype characterization. Project page and code are available at: https://ricklisz.github.io/flexict.github.io and https://github.com/ricklisz/FlexiCT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FlexiCT, a family of CT foundation models trained via three-stage agglomerative continual pretraining on 266,227 volumes drawn from 56 public datasets. The stages consist of 2D axial pretraining, 3D anatomical pretraining, and report-guided semantic alignment. The resulting embeddings are evaluated across five downstream task families (segmentation, classification, registration, vision-language understanding, and clinical retrieval) and are reported to match or exceed prior task-specific models on multiple benchmarks while also organizing scans along gradients associated with tumor stages.
Significance. If the central claims hold after addressing evaluation details, this would constitute a meaningful contribution to medical imaging by demonstrating that a single set of representations can span anatomy-to-phenotype tasks without task-specific retraining. The scale of the public data collection and the staged pretraining approach are notable strengths, as is the public release of code.
major comments (2)
- [§4 and Evaluation protocols] The manuscript does not provide an explicit description or audit of patient/scan overlap checks between the 56 pretraining collections and the downstream test splits used in the five task families. This is load-bearing for the generalization claim in the abstract and §4, because even modest leakage common in public archives could produce the reported transfer performance without demonstrating the claimed universal anatomy-to-phenotype mapping.
- [Results section] Quantitative results for the downstream benchmarks (including exact metrics, error bars, statistical tests, and full baseline details) are not reported in sufficient detail to support the claim that FlexiCT 'matches or exceeds' prior approaches. This information is required in the results section to allow assessment of effect sizes and to confirm the central performance claim.
minor comments (2)
- [§3] Clarify the precise definition and weighting of the three pretraining stages (e.g., loss functions and data sampling ratios) to improve reproducibility.
- [Figures 4-5] Figure captions should explicitly state the number of samples and any exclusion criteria used for the phenotype organization visualizations.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have addressed each major comment point by point below, with revisions made to strengthen the presentation of our methods and results.
read point-by-point responses
-
Referee: [§4 and Evaluation protocols] The manuscript does not provide an explicit description or audit of patient/scan overlap checks between the 56 pretraining collections and the downstream test splits used in the five task families. This is load-bearing for the generalization claim in the abstract and §4, because even modest leakage common in public archives could produce the reported transfer performance without demonstrating the claimed universal anatomy-to-phenotype mapping.
Authors: We agree that explicit verification of patient and scan overlaps is critical to support the generalization claims. The pretraining corpus was assembled exclusively from public datasets, and downstream evaluations followed the official published splits and protocols for each benchmark. However, the initial submission did not include a dedicated overlap audit. We have now performed this analysis using available metadata (patient identifiers, acquisition dates, and institutional tags where present across the public releases). The audit results, including any minimal overlaps detected and mitigation steps, have been added to §4 along with a new supplementary table. This revision directly bolsters the validity of the reported transfer performance. revision: yes
-
Referee: [Results section] Quantitative results for the downstream benchmarks (including exact metrics, error bars, statistical tests, and full baseline details) are not reported in sufficient detail to support the claim that FlexiCT 'matches or exceeds' prior approaches. This information is required in the results section to allow assessment of effect sizes and to confirm the central performance claim.
Authors: We appreciate the need for greater transparency in the quantitative results. The original manuscript summarized key outcomes in the main text while directing readers to supplementary materials for full tables. To address this concern, we have expanded the Results section with comprehensive tables for all five task families. These now report exact metric values, error bars or confidence intervals, statistical significance tests (e.g., paired comparisons against baselines), and complete baseline details with both originally reported and reproduced scores. Updated figures accompany the tables to facilitate assessment of effect sizes. revision: yes
Circularity Check
No circularity: empirical pretraining evaluated on external benchmarks
full rationale
The paper describes an empirical agglomerative pretraining pipeline on 266,227 CT volumes from 56 public datasets, followed by evaluation across standard downstream task families. No equations, fitted parameters, or derivations are presented that reduce reported performance or embeddings to definitional equivalence with the inputs. The approach relies on external public data and benchmarks rather than self-referential steps, self-citation chains, or ansatzes smuggled via prior work. This is a self-contained experimental result against external validation sets.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 56 public datasets collectively provide unbiased coverage of anatomical and pathological variation sufficient for learning universal representations.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FlexiCT uses agglomerative pretraining across three stages: two-dimensional axial pretraining, three-dimensional anatomical pretraining and report-guided semantic alignment.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We train using a DINOv3 self-supervised framework ... iBOT masked patch prediction loss ... contrastive loss.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.