Term-Centric Hierarchy Induction from Heterogeneous Corpora
Pith reviewed 2026-06-26 04:37 UTC · model grok-4.3
The pith
A term-centric approach using automatic term extraction induces more coherent hierarchies from heterogeneous corpora than document- or summary-level methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
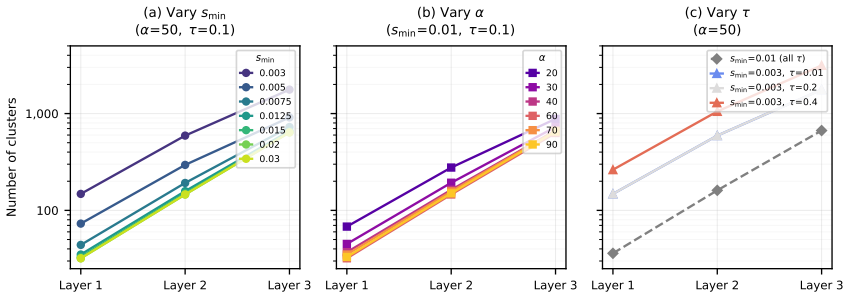
We propose a term-centric framework for inducing hierarchical taxonomies from heterogeneous corpora that scales to massive document collections. Our approach maps documents from diverse sources into a shared representation space using automatic term extraction, enabling robust cross-source alignment. Based on these representations, we construct interpretable hierarchies that integrate domain priors with data-driven clustering. Experiments on a novel English and German multi-source benchmark of over one million documents demonstrate that our method improves cross-source coherence and hierarchy quality over text- and summary-based baselines.
What carries the argument
The term-centric framework that maps documents via automatic term extraction into a shared representation space for cross-source alignment and hierarchy construction.
If this is right
- Hierarchies integrate domain knowledge across sources while preserving source-specific details.
- The approach scales to collections of more than one million documents.
- Hierarchy quality and cross-source coherence exceed results from document-level and summary-based baselines.
- The framework supports practical tasks such as technology landscape mapping in innovation analysis.
Where Pith is reading between the lines
- The same term-extraction alignment step could be tested on additional languages or specialized domains to check how far the shared space generalizes.
- The resulting hierarchies might serve as structured input for downstream models in search or recommendation systems.
- One could examine whether the method retains low-frequency domain terms more reliably than whole-document representations.
Load-bearing premise
Automatic term extraction can map documents from diverse sources into a shared representation space that enables robust cross-source alignment without significant loss of domain-specific information.
What would settle it
If the method produces no measurable improvement in cross-source coherence or hierarchy quality metrics on the English and German multi-source benchmark of over one million documents compared with text- and summary-based baselines, the central claim would be falsified.
Figures

read the original abstract
Organizing knowledge from diverse text sources into interpretable hierarchies is crucial for tasks such as policy analysis, innovation monitoring, and exploratory domain mapping. Existing taxonomy induction methods typically rely on document-level representations that capture entire documents rather than the specific domain concepts relevant for knowledge organization, limiting their ability to generalize across heterogeneous sources. We propose a term-centric framework for inducing hierarchical taxonomies from heterogeneous corpora that scales to massive document collections. Our approach maps documents from diverse sources into a shared representation space using automatic term extraction, enabling robust cross-source alignment. Based on these representations, we construct interpretable hierarchies that integrate domain priors with datadriven clustering. Experiments on a novel English and German multi-source benchmark of over one million documents demonstrate that our method improves cross-source coherence and hierarchy quality over text- and summarybased baselines. A case study on German regional innovation analysis further demonstrates its practical utility for technology landscape mapping.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a term-centric framework for inducing hierarchical taxonomies from heterogeneous corpora. Documents from diverse sources are mapped into a shared representation space via automatic term extraction to enable cross-source alignment. Interpretable hierarchies are then constructed by integrating domain priors with data-driven clustering. Experiments on a novel English and German multi-source benchmark of over one million documents report improvements in cross-source coherence and hierarchy quality over text- and summary-based baselines. A case study on German regional innovation analysis is presented to illustrate practical utility.
Significance. If the reported gains hold under scrutiny of the full experimental design, the work could advance scalable taxonomy induction for multi-source and multilingual settings, supporting applications in policy analysis and technology landscape mapping. The scale of the introduced benchmark (>1M documents) represents a positive contribution to evaluation resources in the area.
major comments (1)
- [Abstract (method description)] The central claim that automatic term extraction maps heterogeneous documents into a shared space 'enabling robust cross-source alignment' without significant loss of domain-specific information is load-bearing for both the cross-source coherence improvements and the German innovation case study, yet the manuscript provides no extraction algorithm details, no preservation metrics (e.g., per-source domain-term recall or overlap), and no ablation isolating information loss effects. This directly matches the weakest assumption identified in the stress-test note.
minor comments (1)
- [Abstract] Typo: 'datadriven' should be 'data-driven'.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The point raised about missing details on automatic term extraction is well-taken and directly affects the clarity of the central methodological claim.
read point-by-point responses
-
Referee: [Abstract (method description)] The central claim that automatic term extraction maps heterogeneous documents into a shared space 'enabling robust cross-source alignment' without significant loss of domain-specific information is load-bearing for both the cross-source coherence improvements and the German innovation case study, yet the manuscript provides no extraction algorithm details, no preservation metrics (e.g., per-source domain-term recall or overlap), and no ablation isolating information loss effects. This directly matches the weakest assumption identified in the stress-test note.
Authors: We agree that the current manuscript lacks sufficient detail on the automatic term extraction step, including the specific algorithm, quantitative preservation metrics, and an ablation isolating information loss. In the revised version we will add a dedicated subsection describing the extraction procedure, report per-source domain-term recall and overlap statistics, and include an ablation comparing term-centric versus document-level representations. These additions will directly support the cross-source alignment claim. revision: yes
Circularity Check
No circularity; empirical method validated on external benchmark
full rationale
The paper describes a term-centric framework that maps documents via automatic term extraction into a shared space, then builds hierarchies integrating priors and clustering. No equations, derivations, fitted parameters presented as predictions, or self-citation chains appear in the abstract or description. Claims rest on experimental results against baselines on a novel >1M-document benchmark, which is externally falsifiable and does not reduce to self-definition or renaming. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhu, Kun and Liao, Lizi and Gu, Yuxuan and Huang, Lei and Feng, Xiaocheng and Qin, Bing. Context-Aware Hierarchical Taxonomy Generation for Scientific Papers via LLM -Guided Multi-Aspect Clustering. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.788
-
[2]
GCD - TM : Graph-Driven Community Detection for Topic Modelling in Psychiatry Texts
Krishnan, Anusuya and Ghebrehiwet, Isaias Mehari. GCD - TM : Graph-Driven Community Detection for Topic Modelling in Psychiatry Texts. Proceedings of the 1st Workshop on NLP for Science (NLP4Science). 2024. doi:10.18653/v1/2024.nlp4science-1.6
-
[3]
Topic Modeling Using Community Detection on a Word Association Graph
Chowdhury, Mahfuzur Rahman and Ahmed, Intesur and Sadeque, Farig and Yanhaona, Muhammad. Topic Modeling Using Community Detection on a Word Association Graph. Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing. 2023
2023
-
[4]
2023 , url=
Graph2topic: an opensource topic modeling framework based on sentence embedding and community detection , author=. 2023 , url=
2023
-
[5]
2025 , eprint=
Science Hierarchography: Hierarchical Organization of Science Literature , author=. 2025 , eprint=
2025
-
[6]
AI for Accelerated Materials Design - NeurIPS 2024 , year=
Scientific Knowledge Graph and Ontology Generation using Open Large Language Models , author=. AI for Accelerated Materials Design - NeurIPS 2024 , year=
2024
-
[7]
Knowledge Navigator: LLM -guided Browsing Framework for Exploratory Search in Scientific Literature
Katz, Uri and Levy, Mosh and Goldberg, Yoav. Knowledge Navigator: LLM -guided Browsing Framework for Exploratory Search in Scientific Literature. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.516
-
[8]
2025 , eprint=
Taxonomy Tree Generation from Citation Graph , author=. 2025 , eprint=
2025
-
[9]
Topic Intrusion for Automatic Topic Model Evaluation
Bhatia, Shraey and Lau, Jey Han and Baldwin, Timothy. Topic Intrusion for Automatic Topic Model Evaluation. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1098
-
[10]
Proceedings of the 1996 ACM SIGMOD International Conference on Management of Data , pages =
Zhang, Tian and Ramakrishnan, Raghu and Livny, Miron , title =. Proceedings of the 1996 ACM SIGMOD International Conference on Management of Data , pages =. 1996 , isbn =. doi:10.1145/233269.233324 , abstract =
-
[11]
Ward , journal =
Joe H. Ward , journal =. Hierarchical Grouping to Optimize an Objective Function , urldate =
-
[12]
Sculley, D. , title =. Proceedings of the 19th International Conference on World Wide Web , pages =. 2010 , isbn =. doi:10.1145/1772690.1772862 , abstract =
-
[13]
MacQueen, J. B. Some methods for classification and analysis of multivariate observations. Proceedings of the fifth berkeley symposium on mathematical statistics and probability. 1967
1967
-
[14]
Proceedings of the eighth ACM international conference on Web search and data mining , pages=
Exploring the space of topic coherence measures , author=. Proceedings of the eighth ACM international conference on Web search and data mining , pages=
-
[15]
2010 , publisher=
Software framework for topic modelling with large corpora , author=. 2010 , publisher=
2010
-
[16]
ACM Transactions on Information Systems (TOIS) , volume=
A similarity measure for indefinite rankings , author=. ACM Transactions on Information Systems (TOIS) , volume=. 2010 , publisher=
2010
-
[17]
International conference on applications of Natural Language to information systems , pages=
Word embedding-based topic similarity measures , author=. International conference on applications of Natural Language to information systems , pages=. 2021 , organization=
2021
-
[18]
and Bouldin, Donald W
Davies, David L. and Bouldin, Donald W. , journal=. A Cluster Separation Measure , year=
-
[19]
PeerJ Computer Science , volume=
The Silhouette coefficient and the Davies-Bouldin index are more informative than Dunn index, Calinski-Harabasz index, Shannon entropy, and Gap statistic for unsupervised clustering internal evaluation of two convex clusters , author=. PeerJ Computer Science , volume=. 2025 , publisher=
2025
-
[20]
Proceedings of the forty-eighth annual ACM symposium on Theory of Computing , pages=
A cost function for similarity-based hierarchical clustering , author=. Proceedings of the forty-eighth annual ACM symposium on Theory of Computing , pages=
-
[21]
Crossing Domains without Labels: Distant Supervision for Term Extraction
Senger, Elena and Campbell, Yuri and Goot, Rob Van Der and Plank, Barbara. Crossing Domains without Labels: Distant Supervision for Term Extraction. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track. 2025. doi:10.18653/v1/2025.emnlp-industry.95
-
[22]
Pattern Recognition Letters , volume=
Data clustering: 50 years beyond K-means , author=. Pattern Recognition Letters , volume=. 2010 , doi=
2010
-
[23]
Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD'96) , pages=
A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise , author=. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD'96) , pages=
-
[24]
2017 , doi=
McInnes, Leland and Healy, John and Astels, Steve , journal=. 2017 , doi=
2017
-
[25]
Introduction to Information Retrieval , author=
-
[26]
Statistics and Computing , volume=
A tutorial on spectral clustering , author=. Statistics and Computing , volume=. 2007 , doi=
2007
-
[27]
Shen, Yanzhen and Zhang, Yu and Zhang, Yunyi and Han, Jiawei. A Unified Taxonomy-Guided Instruction Tuning Framework for Entity Set Expansion and Taxonomy Expansion. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.167
-
[28]
Huang, Jiaxin and Xie, Yiqing and Meng, Yu and Zhang, Yunyi and Han, Jiawei , year=. CoRel: Seed-Guided Topical Taxonomy Construction by Concept Learning and Relation Transferring , url=. doi:10.1145/3394486.3403244 , booktitle=
-
[29]
Zhang, Chao and Tao, Fangbo and Chen, Xiusi and Shen, Jiaming and Jiang, Meng and Sadler, Brian and Vanni, Michelle and Han, Jiawei , title =. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages =. 2018 , isbn =. doi:10.1145/3219819.3220064 , abstract =
-
[30]
Panchenko, Alexander and Faralli, Stefano and Ruppert, Eugen and Remus, Steffen and Naets, Hubert and Fairon, C \'e drick and Ponzetto, Simone Paolo and Biemann, Chris. TAXI at S em E val-2016 Task 13: a Taxonomy Induction Method based on Lexico-Syntactic Patterns, Substrings and Focused Crawling. Proceedings of the 10th International Workshop on Semantic...
-
[31]
Improving Hypernymy Detection with an Integrated Path-based and Distributional Method
Shwartz, Vered and Goldberg, Yoav and Dagan, Ido. Improving Hypernymy Detection with an Integrated Path-based and Distributional Method. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016. doi:10.18653/v1/P16-1226
-
[32]
Automatic Acquisition of Hyponyms from Large Text Corpora
Hearst, Marti A. Automatic Acquisition of Hyponyms from Large Text Corpora. COLING 1992 Volume 2: The 14th I nternational C onference on C omputational L inguistics. 1992
1992
-
[33]
Wang, Chi and Danilevsky, Marina and Desai, Nihit and Zhang, Yinan and Nguyen, Phuong and Taula, Thrivikrama and Han, Jiawei , title =. Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages =. 2013 , isbn =. doi:10.1145/2487575.2487631 , abstract =
-
[34]
Liu, Xueqing and Song, Yangqiu and Liu, Shixia and Wang, Haixun , title =. Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages =. 2012 , isbn =. doi:10.1145/2339530.2339754 , abstract =
-
[35]
Proceedings of the 24th International Conference on Machine Learning , pages =
Mimno, David and Li, Wei and McCallum, Andrew , title =. Proceedings of the 24th International Conference on Machine Learning , pages =. 2007 , isbn =. doi:10.1145/1273496.1273576 , abstract =
-
[36]
ArXiv , year=
BERTopic: Neural topic modeling with a class-based TF-IDF procedure , author=. ArXiv , year=
-
[37]
Proceedings of the ACM Web Conference 2022 , pages =
Lee, Dongha and Shen, Jiaming and Kang, Seongku and Yoon, Susik and Han, Jiawei and Yu, Hwanjo , title =. Proceedings of the ACM Web Conference 2022 , pages =. 2022 , isbn =. doi:10.1145/3485447.3512002 , abstract =
-
[38]
Polchar, Jan , title =. 2024 , address =. doi:10.1787/84820cd8-en , url =
-
[39]
2022 , month =
Hakiman, Kamran and Stull-Lane, Chloe , title =. 2022 , month =
2022
-
[40]
DeepPatent: patent classification with convolutional neural networks and word embedding , pages =
Li, Shaobo and Hu, Jie and Cui, Yuxin and Hu, Jianjun , year =. DeepPatent: patent classification with convolutional neural networks and word embedding , pages =. Scientometrics , doi =
-
[41]
2022 , eprint=
OpenAlex: A fully-open index of scholarly works, authors, venues, institutions, and concepts , author=. 2022 , eprint=
2022
-
[42]
doi:10.2906/112117098108/12 , url =
2015 , publisher =. doi:10.2906/112117098108/12 , url =
-
[43]
doi:10.2906/112117098108/20 , url =
2022 , publisher =. doi:10.2906/112117098108/20 , url =
-
[44]
All Science Journal Classification (ASJC) Codes , howpublished =
-
[45]
2025 , eprint=
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. 2025 , eprint=
2025
-
[46]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[47]
Zhu, Xingwei and Ming, Zhao-Yan and Zhu, Xiaoyan and Chua, Tat-Seng , title =. Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2013 , isbn =. doi:10.1145/2484028.2484032 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.