AutoDex: An Automated Real-World System for Dexterous Grasping Data Collection
Pith reviewed 2026-06-26 07:50 UTC · model grok-4.3
The pith
AutoDex automates real-world dexterous grasp data collection with 4.8 times higher throughput than teleoperation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
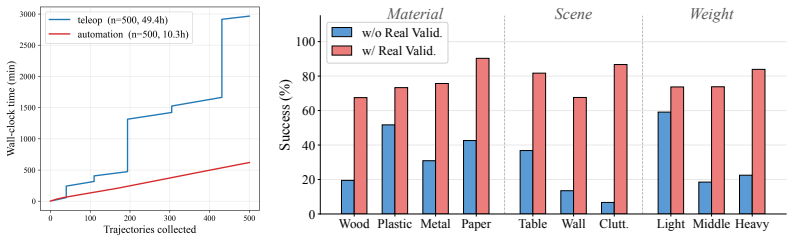
AutoDex is a replaceable-generator system that runs the full perception-execution-labeling-reset loop autonomously: dense multi-view localization under occlusion, collision-monitored motion execution on Allegro and Inspire hands, binary lift-and-hold outcome labeling, and active object resetting to expose new poses. The result is a reusable database of 3,593 synchronized real-world grasp trials. On a matched 500-trial collection, it finishes in 10.3 hours versus 49.4 hours for teleoperation and yields retrieved grasps that succeed at 76 percent versus 34 percent for simulation-only validation.
What carries the argument
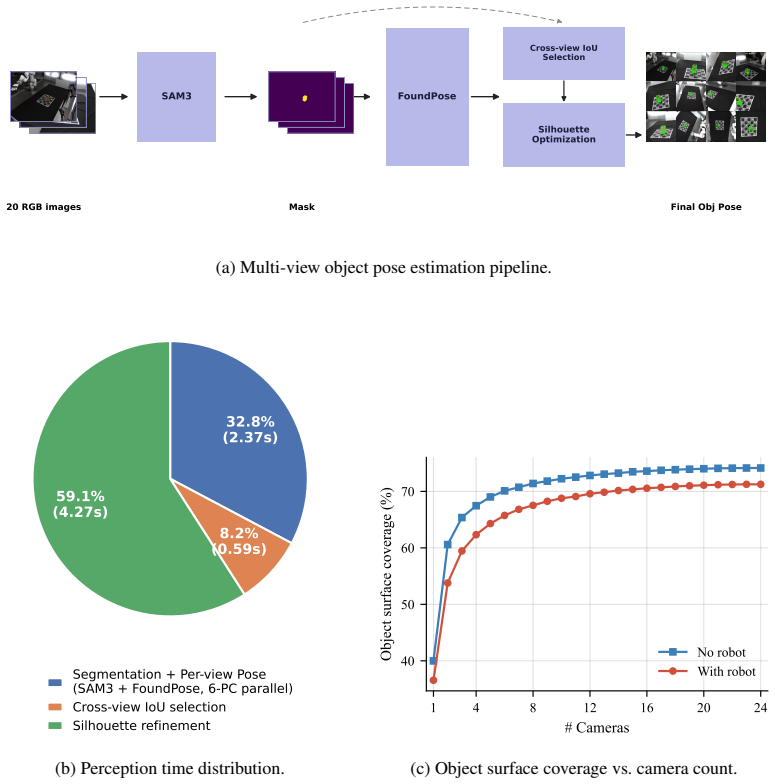
AutoDex automated collection loop: the mechanism that takes a candidate grasp, performs 20-camera pose estimation under occlusion, executes and labels the physical outcome, then actively resets the object to generate additional stable poses without manual intervention.
If this is right
- Real-world grasp data can be collected at scale without operator time or bias.
- A database of physically labeled outcomes supports retrieval that outperforms simulation-only validation.
- The same automated loop can be reused with different grasp generators or robot hands.
- Synchronized multi-view observations and robot-state logs become available as a public resource for downstream training or analysis.
Where Pith is reading between the lines
- The approach could be extended to collect data for other contact-rich tasks such as in-hand manipulation or assembly if the reset and labeling steps are adapted.
- Hybrid datasets that mix AutoDex-validated real trials with large simulation sets might further improve policy robustness.
- If the perception pipeline generalizes across object categories, the same hardware setup could support data collection for entirely new object sets with minimal redesign.
Load-bearing premise
The 20-camera perception pipeline can reliably localize objects and estimate poses even when the hand heavily occludes them, and the active reset can repeatedly produce new stable object poses without systematic bias or human help.
What would settle it
Run AutoDex on the same 100 objects for 500 trials and measure whether pose-estimation failures or reset interventions exceed a small fraction of trials, or whether retrieved grasps from the resulting database fail to reach substantially higher real-world success than simulation-only baselines.
Figures







read the original abstract
Learning robust dexterous grasping requires real-world data that records the physical outcomes of grasp attempts. Such data is hard to obtain at scale: teleoperation yields valid physical outcomes but is slow and operator-biased, while simulation-based generation is cheap and scalable but cannot certify contact validity. A natural solution is to generate candidate grasps and verify them on real hardware, but this scales only if the entire collection loop (perception, execution, labeling, and reset) runs without human intervention. We present AutoDex, an automated real-world data-collection system that closes this loop: for each candidate from a replaceable generator, it localizes the object under severe hand-object occlusion with dense 20-camera perception, executes collision-monitored robot motions, labels lift-and-hold success or failure, and actively resets the object between trials to expose additional candidates across stable poses. The result is a reusable database of physically labeled grasp trials that downstream systems can query by retrieval and feasibility filtering. Using AutoDex, we collect 3,593 grasp trials across Allegro and Inspire hands on 100 diverse objects, with synchronized multi-view observations and robot-state logs. For a matched 500-trajectory collection, AutoDex requires 10.3 h versus 49.4 h for teleoperation, yielding a 4.8x throughput improvement, and grasps retrieved from the AutoDex-validated database succeed 76% versus 34% for simulation-only validation. Code and data will be publicly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AutoDex, an automated real-world system for dexterous grasping data collection that integrates 20-camera perception for object localization under occlusion, collision-monitored execution on Allegro and Inspire hands, lift-and-hold labeling, and active object reset. It reports collecting 3,593 grasp trials across 100 objects, with a matched 500-trajectory collection taking 10.3 hours versus 49.4 hours for teleoperation (4.8x throughput) and downstream retrieval success of 76% versus 34% for simulation-only validation. Code and data are to be released publicly.
Significance. If the autonomous operation claims hold, the work provides a concrete, scalable bridge between simulation-generated candidates and physically validated real-world data, with falsifiable metrics on wall-clock time and downstream grasp success that directly address the data bottleneck in dexterous grasping. The public release of the database strengthens reproducibility and enables follow-on retrieval-based methods.
major comments (2)
- [Abstract / perception and reset sections] Abstract and methods description of the perception pipeline: the central 4.8x throughput and 76% success claims rest on reliable object localization and pose estimation under severe hand-object occlusion plus fully autonomous reset, yet no quantitative error rates, failure counts, intervention statistics, or ablation on perception accuracy are supplied; without these, the attribution of the 3,593 trials and time savings to automation cannot be verified.
- [Results / downstream evaluation] Results on downstream evaluation: the 76% vs 34% retrieval success is reported for a matched collection, but the manuscript supplies no details on the size of the query set, the exact retrieval mechanism, or how many AutoDex-labeled trials were used in the comparison, leaving the magnitude of the improvement difficult to interpret or reproduce.
minor comments (1)
- [Abstract] The abstract mentions synchronized multi-view observations and robot-state logs but does not specify the exact data formats or synchronization method; a table or appendix listing the released data schema would improve usability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to improve verifiability and reproducibility.
read point-by-point responses
-
Referee: [Abstract / perception and reset sections] Abstract and methods description of the perception pipeline: the central 4.8x throughput and 76% success claims rest on reliable object localization and pose estimation under severe hand-object occlusion plus fully autonomous reset, yet no quantitative error rates, failure counts, intervention statistics, or ablation on perception accuracy are supplied; without these, the attribution of the 3,593 trials and time savings to automation cannot be verified.
Authors: We acknowledge that the manuscript does not supply quantitative error rates, failure counts, intervention statistics, or perception ablations. The throughput comparison is presented as a matched autonomous collection, but without these metrics the attribution to full automation cannot be independently verified from the text. We will add the requested statistics and an ablation on perception accuracy in the revised methods and results sections. revision: yes
-
Referee: [Results / downstream evaluation] Results on downstream evaluation: the 76% vs 34% retrieval success is reported for a matched collection, but the manuscript supplies no details on the size of the query set, the exact retrieval mechanism, or how many AutoDex-labeled trials were used in the comparison, leaving the magnitude of the improvement difficult to interpret or reproduce.
Authors: We agree that the manuscript omits key details required to interpret and reproduce the 76% versus 34% comparison. We will expand the downstream evaluation section to specify the query set size, the retrieval mechanism, and the exact number of AutoDex-labeled trials used. revision: yes
Circularity Check
No circularity: empirical system evaluation with direct measurements
full rationale
The paper presents an automated hardware/software system for grasp data collection and reports wall-clock times (10.3 h vs 49.4 h) and success rates (76% vs 34%) from physical trials. These are direct empirical observations of the deployed system rather than outputs of any fitted model, mathematical derivation, or self-referential prediction. No equations, parameters, or uniqueness theorems appear in the provided text; the central claims rest on measured throughput and retrieval performance, which are externally falsifiable by replication and do not reduce to their own inputs by construction. Self-citations, if present, are not load-bearing for the reported results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Dense 20-camera multi-view system can localize objects under severe hand-object occlusion
- domain assumption Lift-and-hold test accurately labels grasp success or failure
Reference graph
Works this paper leans on
-
[1]
Y . Liu, Y . Yang, Y . Wang, X. Wu, J. Wang, Y . Yao, S. Schwertfeger, S. Yang, W. Wang, J. Yu, et al. Realdex: Towards human-like grasping for robotic dexterous hand.arXiv preprint arXiv:2402.13853, 2024
arXiv 2024
-
[2]
C. Wang, H. Shi, W. Wang, R. Zhang, L. Fei-Fei, and C. K. Liu. Dexcap: Scalable and portable mocap data collection system for dexterous manipulation.arXiv preprint arXiv:2403.07788, 2024
arXiv 2024
-
[3]
Z. Chen, K. Van Wyk, Y .-W. Chao, W. Yang, A. Mousavian, A. Gupta, and D. Fox. Dextransfer: Real world multi-fingered dexterous grasping with minimal human demonstrations.arXiv preprint arXiv:2209.14284, 2022
arXiv 2022
-
[4]
Zhang, H
J. Zhang, H. Liu, D. Li, X. Yu, H. Geng, Y . Ding, J. Chen, and H. Wang. DexGraspNet 2.0: Learning generative dexterous grasping in large-scale synthetic cluttered scenes. InConference on Robot Learning (CoRL), 2024
2024
-
[5]
Bicchi and V
A. Bicchi and V . Kumar. Robotic grasping and contact: A review. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), volume 1, pages 348– 353, 2000
2000
-
[6]
Y . Qin, W. Yang, B. Huang, K. Van Wyk, H. Su, X. Wang, Y .-W. Chao, and D. Fox. Anyteleop: A general vision-based dexterous robot arm-hand teleoperation system. InRobotics: Science and Systems, 2023
2023
-
[7]
R. Wang, J. Zhang, J. Chen, Y . Xu, P. Li, T. Liu, and H. Wang. Dexgraspnet: A large- scale robotic dexterous grasp dataset for general objects based on simulation.arXiv preprint arXiv:2210.02697, 2022
arXiv 2022
-
[8]
J. Chen, Y . Ke, and H. Wang. Bodex: Scalable and efficient robotic dexterous grasp synthesis using bilevel optimization.arXiv preprint arXiv:2412.16490, 2024
arXiv 2024
- [9]
- [10]
-
[11]
Y . Park, J. S. Bhatia, L. Ankile, and P. Agrawal. Dart: Dexterous augmented reality teleoper- ation platform for large-scale robot data collection in simulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 13883–13889. IEEE, 2025
2025
-
[12]
T. Liu, Z. Liu, Z. Jiao, Y . Zhu, and S.-C. Zhu. Synthesizing diverse and physically stable grasps with arbitrary hand structures using differentiable force closure estimator.IEEE Robotics and Automation Letters, 7(1):470–477, Jan. 2022. ISSN 2377-3774. doi:10.1109/lra.2021. 3129138. URLhttp://dx.doi.org/10.1109/LRA.2021.3129138
-
[13]
Zhang, S
H. Zhang, S. Christen, Z. Fan, O. Hilliges, and J. Song. GraspXL: Generating grasping motions for diverse objects at scale. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[14]
S. Chen, J. Bohg, and C. K. Liu. Springgrasp: Synthesizing compliant, dexterous grasps under shape uncertainty.arXiv preprint arXiv:2404.13532, 2024
arXiv 2024
-
[15]
A. H. Li, P. Culbertson, J. W. Burdick, and A. D. Ames. Frogger: Fast robust grasp generation via the min-weight metric. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 6809–6816. IEEE, 2023
2023
-
[16]
J. Lundell, F. Verdoja, and V . Kyrki. Ddgc: Generative deep dexterous grasping in clutter. arXiv preprint arXiv:2103.04783, 2021
arXiv 2021
-
[17]
Y . Xu, W. Wan, J. Zhang, H. Liu, Z. Shan, H. Shen, R. Wang, H. Geng, Y . Weng, J. Chen, et al. Unidexgrasp: Universal robotic dexterous grasping via learning diverse proposal generation and goal-conditioned policy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4737–4746, 2023
2023
-
[18]
W. Wan, H. Geng, Y . Liu, Z. Shan, Y . Yang, L. Yi, and H. Wang. Unidexgrasp++: Improving dexterous grasping policy learning via geometry-aware curriculum and iterative generalist- specialist learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3891–3902, 2023
2023
-
[19]
J. Ye, K. Wang, C. Yuan, R. Yang, Y . Li, J. Zhu, Y . Qin, X. Zou, and X. Wang. Dex1b: Learning with 1b demonstrations for dexterous manipulation. InRobotics: Science and Systems (RSS), 2025
2025
-
[20]
Z. Q. Chen, K. Van Wyk, Y .-W. Chao, W. Yang, A. Mousavian, A. Gupta, and D. Fox. Learning robust real-world dexterous grasping policies via implicit shape augmentation.arXiv preprint arXiv:2210.13638, 2022
arXiv 2022
-
[21]
Christen, M
S. Christen, M. Kocabas, E. Aksan, J. Hwangbo, J. Song, and O. Hilliges. D-grasp: Phys- ically plausible dynamic grasp synthesis for hand-object interactions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20577–20586, 2022
2022
-
[22]
Tobin, R
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017
2017
-
[23]
OpenAI, I. Akkaya, M. Andrychowicz, M. Chociej, M. Litwin, B. McGrew, A. Petron, A. Paino, M. Plappert, G. Powell, et al. Solving rubik’s cube with a robot hand.arXiv preprint arXiv:1910.07113, 2019
Pith/arXiv arXiv 1910
-
[24]
Levine, P
S. Levine, P. Pastor, A. Krizhevsky, J. Ibarz, and D. Quillen. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection.The International Journal of Robotics Research (IJRR), 37(4-5):421–436, 2018
2018
-
[25]
Kalashnikov, A
D. Kalashnikov, A. Irpan, P. Pastor, J. Ibarz, A. Herzog, E. Jang, D. Quillen, E. Holly, M. Kalakrishnan, V . Vanhoucke, and S. Levine. QT-Opt: Scalable deep reinforcement learning for vision-based robotic manipulation. InConference on Robot Learning (CoRL), 2018. 10
2018
-
[26]
Kalashnikov, J
D. Kalashnikov, J. Varley, Y . Chebotar, B. Swanson, R. Jonschkowski, C. Finn, S. Levine, and K. Hausman. Scaling up multi-task robotic reinforcement learning. InConference on Robot Learning (CoRL), 2021
2021
-
[27]
M. Ahn, D. Dwibedi, C. Finn, M. Arenas, K. Armstrong, V . Baruch, S. Belkhale, A. Bro- han, N. Brown, K. Choromanski, et al. AutoRT: Embodied foundation models for large scale orchestration of robotic agents.arXiv preprint arXiv:2401.12963, 2024
arXiv 2024
-
[28]
H. Zhu, J. Yu, A. Gupta, D. Shah, K. Hartikainen, A. Singh, V . Kumar, and S. Levine. The in- gredients of real-world robotic reinforcement learning. InInternational Conference on Learn- ing Representations (ICLR), 2020
2020
-
[29]
Sharma, A
A. Sharma, A. M. Ahmed, R. Ahmad, and C. Finn. Self-improving robots: End-to-end au- tonomous visuomotor reinforcement learning. InConference on Robot Learning (CoRL), 2023
2023
-
[30]
H. Liu, S. Nasiriany, L. Zhang, Z. Bao, and Y . Zhu. Robot learning on the job: Human-in- the-loop autonomy and learning during deployment. InRobotics: Science and Systems (RSS), 2023
2023
-
[31]
Mirchandani, S
S. Mirchandani, S. Belkhale, J. Hejna, E. Choi, M. S. Islam, and D. Sadigh. So you think you can scale up autonomous robot data collection? InConference on Robot Learning (CoRL), 2024
2024
-
[32]
J. Yu, L. Fu, H. Huang, K. El-Refai, R. A. Ambrus, R. Cheng, M. Z. Irshad, and K. Goldberg. Real2Render2Real: Scaling robot data without dynamics simulation or robot hardware.arXiv preprint arXiv:2505.09601, 2025
arXiv 2025
-
[33]
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, et al. Sam 3: Segment anything with concepts.arXiv:2511.16719, 2025
Pith/arXiv arXiv 2025
-
[34]
B. Wen, W. Yang, J. Kautz, and S. Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[35]
H. Lin, S. Chen, J. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang. Depth anything 3: Recovering the visual space from any views.arXiv:2511.10647, 2025
Pith/arXiv arXiv 2025
-
[36]
Hinterstoisser, V
S. Hinterstoisser, V . Lepetit, S. Ilic, S. Holzer, G. Bradski, K. Konolige, and N. Navab. Model based training, detection and pose estimation of texture-less 3d objects in heavily cluttered scenes. InAsian conference on computer vision, 2012
2012
-
[37]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–
2012
- [38]
-
[39]
E. P. ¨Ornek, Y . Labb´e, B. Tekin, L. Ma, C. Keskin, C. Forster, and T. Hoda ˇn. Foundpose: Unseen object pose estimation with foundation features.European Conference on Computer Vision (ECCV), 2024
2024
-
[40]
V . N. Nguyen, C. Forster, B. Tekin, S. Shkodrani, V . Lepetit, C. Keskin, and T. Hodaˇn. Gotrack: Generic 6dof object pose refinement and tracking.Computer Vision and Pattern Recognition Workshops (CVPRW), 2025
2025
-
[41]
Sundaralingam, S
B. Sundaralingam, S. K. S. Hari, A. Fishman, C. Garrett, K. Van Wyk, V . Blukis, A. Millane, H. Oleynikova, A. Handa, F. Ramos, et al. Curobo: Parallelized collision-free robot motion generation. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 8112–8119. IEEE, 2023. 11 Supplementary Material A Candidate Generation and Executi...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.