Language-Assisted Super-Resolution from Real-World Low-Resolution Patches
Pith reviewed 2026-07-01 05:47 UTC · model grok-4.3
The pith
Extracting real LR patches from depth variations within single high-quality images and aligning them in language space enables effective unpaired super-resolution on actual low-resolution inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
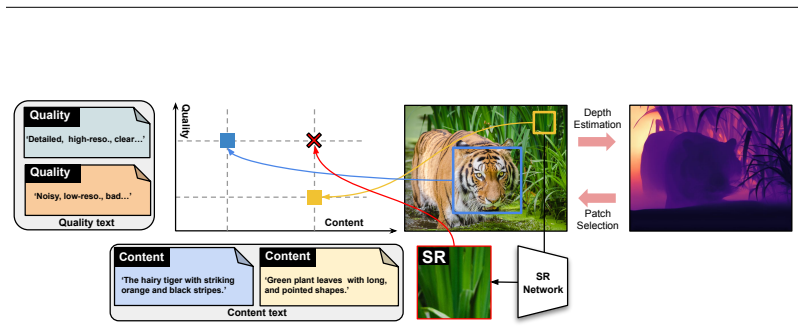
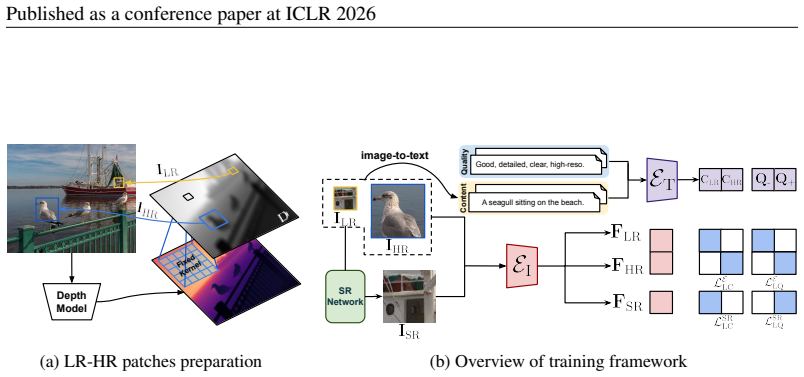
LA-SR projects images into a semantically rich language space and applies linguistic content loss for semantic fidelity plus linguistic quality loss for perceptual realism, allowing the framework to super-resolve real LR patches extracted from depth-varying regions in single high-quality images without any paired training data or synthetic kernels.
What carries the argument
LA-SR framework that uses vision-language models to apply two language-guided losses in a joint content-quality embedding space.
If this is right
- SR training no longer requires paired HR-LR datasets or handcrafted degradation models.
- Models generalize to real captured LR inputs without the domain gap from synthetic data.
- Semantic content stays consistent while perceptual realism improves through language-space alignment.
- Natural depth-induced resolution differences within images become a source of training data.
Where Pith is reading between the lines
- The language-space approach may transfer to other unpaired restoration tasks such as denoising or deblurring where real degradations are hard to simulate.
- Depth-based patch extraction could be combined with multi-view or video data to increase the variety of captured degradations.
- Existing SR networks might be fine-tuned with the same linguistic losses to improve their real-world performance without full retraining.
Load-bearing premise
Patches taken from regions at different depths in one image capture the full complexity of real-world degradations without interference from factors like perspective distortion or illumination changes.
What would settle it
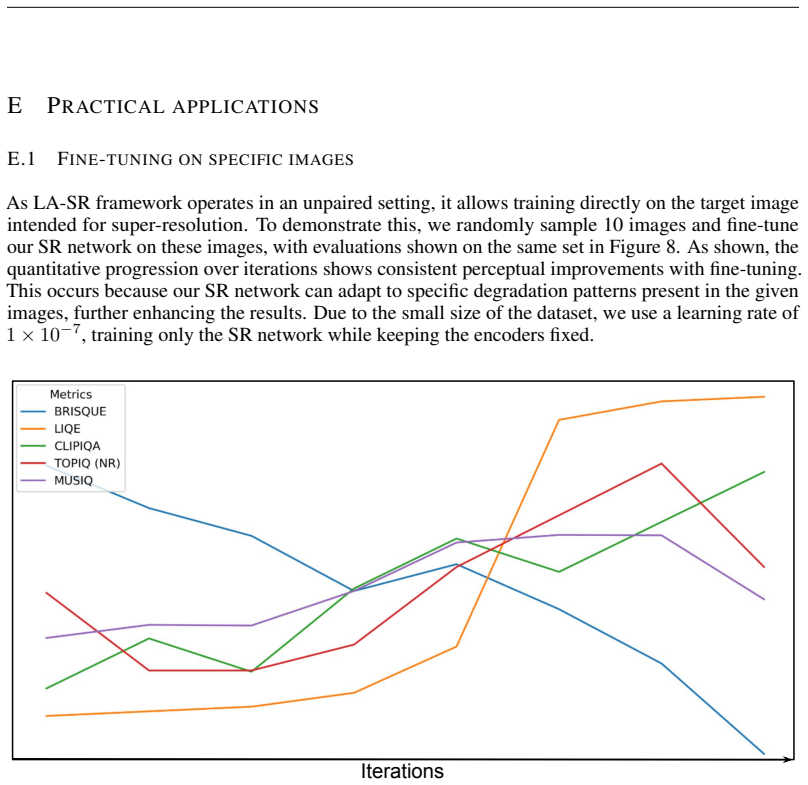
A direct comparison showing that outputs from the method match neither the visual quality nor the degradation statistics of high-resolution ground truth when tested on real LR images captured under conditions absent from the depth-extracted training patches.
Figures






read the original abstract
Single image super-resolution aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs. Training SR models typically requires paired HR-LR data, which is difficult to obtain in reality. As a result, most methods synthesize LR images by artificially degrading HR images with handcrafted kernels or camera ISP adjustments. However, these synthetic degradations fail to capture the complexity of real LR images, leading to poor generalization in practice. To address this, we observe that even within a single high-quality image, regions at different depths exhibit varying resolutions, where distant regions act as LR patches and closer ones as HR patches. This allows the extraction of real, degradation-induced LR patches from real images. Since these LR patches lack paired HR counterparts, we propose LA-SR (Language Assistant for SR), a novel framework for unpaired SR. The key idea of LA-SR is to redefine unpaired SR in the language space, using vision-language models to bridge the LR-HR gap. LA-SR projects images into a semantically rich space representing both content and quality, and applies two language-guided losses: linguistic content loss to preserve semantic fidelity, and linguistic quality loss to enhance perceptual realism. With this alignment, LA-SR effectively super-resolves real LR inputs, producing realistic outputs that overcome the limitations of synthetic-data-trained methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LA-SR, an unpaired single-image super-resolution framework. It extracts real LR patches from distant regions and HR patches from nearby regions within a single high-quality image to obtain authentic degradation pairs, then projects images into a language space via pretrained vision-language models and applies two language-guided losses (linguistic content loss and linguistic quality loss) to align semantics and perceptual quality without requiring paired data or synthetic degradations.
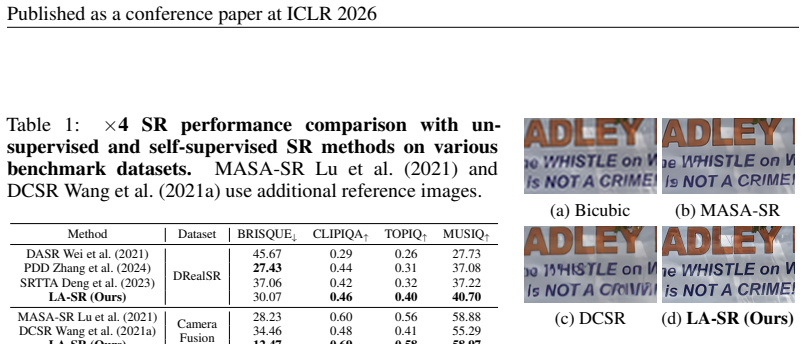
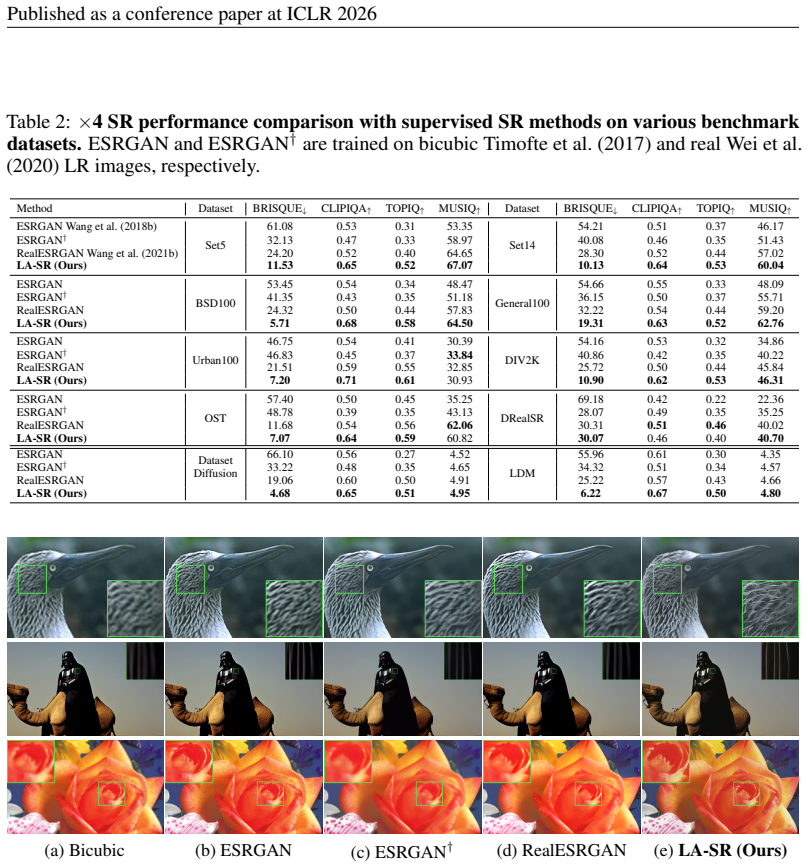
Significance. If experimentally validated, the approach could meaningfully advance real-world SR by sidestepping the domain gap introduced by handcrafted synthetic degradations, offering a scalable route to training on naturally occurring resolution variations.
major comments (2)
- [Abstract] Abstract: the central claim that 'LA-SR effectively super-resolves real LR inputs, producing realistic outputs that overcome the limitations of synthetic-data-trained methods' is unsupported because the manuscript contains no experimental results, ablation studies, quantitative metrics, or comparisons against baselines.
- [Abstract] Abstract: the foundational premise that 'regions at different depths exhibit varying resolutions, where distant regions act as LR patches and closer ones as HR patches' is load-bearing for the unpaired training strategy, yet the text provides no analysis or mitigation for confounding factors (perspective distortion, depth-of-field blur, illumination variation, projective foreshortening) that differentiate these patches from authentic camera LR captures.
minor comments (2)
- The description of how the two language-guided losses are formulated and combined would benefit from explicit equations or pseudocode to clarify their implementation.
- The manuscript should include a limitations section discussing potential failure modes when the depth-based patch assumption does not hold (e.g., scenes without sufficient depth variation).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments correctly identify areas where the current manuscript requires strengthening to support its claims. We respond point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'LA-SR effectively super-resolves real LR inputs, producing realistic outputs that overcome the limitations of synthetic-data-trained methods' is unsupported because the manuscript contains no experimental results, ablation studies, quantitative metrics, or comparisons against baselines.
Authors: We agree that the abstract's claim regarding effectiveness is not supported by experimental evidence in the current manuscript, which presents the conceptual framework but lacks results, ablations, or baseline comparisons. We will revise the abstract to describe LA-SR as a proposed framework without asserting validated performance. In addition, we will add a dedicated experiments section with quantitative metrics, ablations, and comparisons in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the foundational premise that 'regions at different depths exhibit varying resolutions, where distant regions act as LR patches and closer ones as HR patches' is load-bearing for the unpaired training strategy, yet the text provides no analysis or mitigation for confounding factors (perspective distortion, depth-of-field blur, illumination variation, projective foreshortening) that differentiate these patches from authentic camera LR captures.
Authors: The referee correctly notes that the depth-based premise requires analysis of confounding factors. The manuscript introduces the observation but does not discuss or mitigate issues such as perspective distortion, depth-of-field blur, illumination variation, or projective foreshortening. We will add a new subsection analyzing these factors, including mitigation approaches like content-aware patch selection and depth normalization, to better support the strategy's validity. revision: yes
Circularity Check
No circularity: derivation relies on external VLMs and empirical observation without self-referential reduction.
full rationale
The paper presents an unpaired SR framework based on extracting LR/HR patches from depth regions in single HQ images and applying language-guided losses via pretrained vision-language models. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central method is defined in terms of external components (VLMs) and an independent observation about image depths, with no reduction of outputs to inputs by construction. This matches the default case of a self-contained method description.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models encode both semantic content and perceptual quality in a shared embedding space usable for loss functions
invented entities (1)
-
LA-SR framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ICCV , year=
Swinir: Image restoration using swin transformer , author=. ICCV , year=
-
[2]
CVPR , pages=
Restormer: Efficient transformer for high-resolution image restoration , author=. CVPR , pages=
-
[3]
CVPR , pages=
Learning texture transformer network for image super-resolution , author=. CVPR , pages=
-
[4]
NeurIPS , year=
Attention is all you need , author=. NeurIPS , year=
-
[5]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
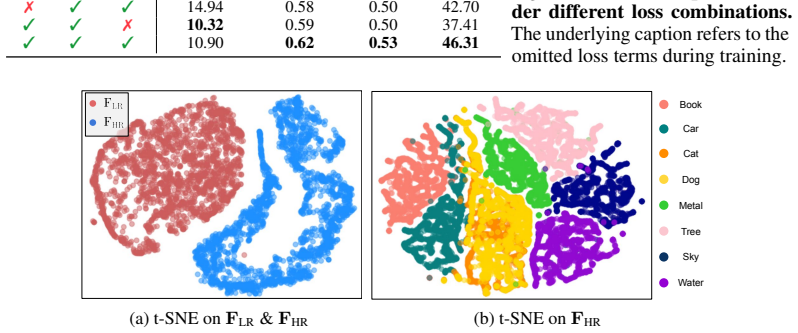
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[6]
CVPR , pages=
Deeply-recursive convolutional network for image super-resolution , author=. CVPR , pages=
-
[7]
CVPR , year=
Photo-realistic single image super-resolution using a generative adversarial network , author=. CVPR , year=
-
[8]
CVPR , year=
Enhanced deep residual networks for single image super-resolution , author=. CVPR , year=
-
[9]
Deep residual learning for image recognition , author=
-
[10]
ECCVW , year=
Esrgan: Enhanced super-resolution generative adversarial networks , author=. ECCVW , year=
-
[11]
NeurIPS , year=
Generative adversarial nets , author=. NeurIPS , year=
-
[12]
ECCV , pages=
Single image super-resolution via a holistic attention network , author=. ECCV , pages=. 2020 , organization=
2020
-
[13]
ECCV , year=
Perceptual losses for real-time style transfer and super-resolution , author=. ECCV , year=
-
[14]
ECCV , year=
Image super-resolution using very deep residual channel attention networks , author=. ECCV , year=
-
[15]
CVPR , year=
Transformer for single image super-resolution , author=. CVPR , year=
-
[16]
arXiv preprint arXiv:2107.09427 , year=
RankSRGAN: Super Resolution Generative Adversarial Networks with Learning to Rank , author=. arXiv preprint arXiv:2107.09427 , year=
-
[17]
ICCV , year=
Orthogonal jacobian regularization for unsupervised disentanglement in image generation , author=. ICCV , year=
-
[18]
CVPR , year=
All you need is beyond a good init: Exploring better solution for training extremely deep convolutional neural networks with orthonormality and modulation , author=. CVPR , year=
-
[19]
CVPR , year=
A Conservative Approach for Unbiased Learning on Unknown Biases , author=. CVPR , year=
-
[20]
BMVA , year=
Low-complexity single-image super-resolution based on nonnegative neighbor embedding , author=. BMVA , year=
-
[21]
curves and surfaces , year=
On single image scale-up using sparse-representations , author=. curves and surfaces , year=
-
[22]
ICCV , year=
A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics , author=. ICCV , year=
-
[23]
CVPR , year=
Single image super-resolution from transformed self-exemplars , author=. CVPR , year=
-
[24]
CVPRW , year=
Ntire 2017 challenge on single image super-resolution: Methods and results , author=. CVPRW , year=
2017
-
[25]
TIP , volume=
Image quality assessment: from error visibility to structural similarity , author=. TIP , volume=. 2004 , publisher=
2004
-
[26]
CVPR , year=
Image-to-image translation with conditional adversarial networks , author=. CVPR , year=
-
[27]
TPAMI , year=
Image super-resolution using deep convolutional networks , author=. TPAMI , year=
-
[28]
CVPR , year=
Residual dense network for image super-resolution , author=. CVPR , year=
-
[29]
CVPR , year=
Accurate image super-resolution using very deep convolutional networks , author=. CVPR , year=
-
[30]
AAAI , year=
Scale-wise convolution for image restoration , author=. AAAI , year=
-
[31]
CVPR , pages=
Classsr: A general framework to accelerate super-resolution networks by data characteristic , author=. CVPR , pages=
-
[32]
CVPR , pages=
Image super-resolution with non-local sparse attention , author=. CVPR , pages=
-
[33]
CVPR , year=
SRWarp: Generalized image super-resolution under arbitrary transformation , author=. CVPR , year=
-
[34]
ICCV , year=
Singan: Learning a generative model from a single natural image , author=. ICCV , year=
-
[35]
CVPR , year=
Unsupervised real-world image super resolution via domain-distance aware training , author=. CVPR , year=
-
[36]
manga109
Building a manga dataset “manga109” with annotations for multimedia applications , author=. IEEE MultiMedia , volume=. 2020 , publisher=
2020
-
[37]
ECCV , year=
Deep cyclic generative adversarial residual convolutional networks for real image super-resolution , author=. ECCV , year=
-
[38]
CVPR , year=
Unpaired image-to-image translation using cycle-consistent adversarial networks , author=. CVPR , year=
-
[39]
CVPR , year=
Pulse: Self-supervised photo upsampling via latent space exploration of generative models , author=. CVPR , year=
-
[40]
2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW) , pages=
Frequency separation for real-world super-resolution , author=. 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW) , pages=. 2019 , organization=
2019
-
[41]
TPAMI , year=
Exploiting deep generative prior for versatile image restoration and manipulation , author=. TPAMI , year=
-
[42]
CVPR , year=
Structure-preserving super resolution with gradient guidance , author=. CVPR , year=
-
[43]
ICCV , year=
Designing a practical degradation model for deep blind image super-resolution , author=. ICCV , year=
-
[44]
IJCAI , year=
Deep multimodal hashing with orthogonal regularization , author=. IJCAI , year=
-
[45]
Neural computation , year=
Adaptive mixtures of local experts , author=. Neural computation , year=
-
[46]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. arXiv preprint arXiv:1701.06538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Mixture-of-Experts with Expert Choice Routing , author=. arXiv preprint arXiv:2202.09368 , year=
-
[48]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=
-
[49]
arXiv preprint arXiv:2103.13262 , year=
Fastmoe: A fast mixture-of-expert training system , author=. arXiv preprint arXiv:2103.13262 , year=
-
[50]
CVPR , year=
Recovering realistic texture in image super-resolution by deep spatial feature transform , author=. CVPR , year=
-
[51]
CVPR , year=
Generalized Real-World Super-Resolution through Adversarial Robustness , author=. CVPR , year=
-
[52]
CVPR , year=
Details or Artifacts: A Locally Discriminative Learning Approach to Realistic Image Super-Resolution , author=. CVPR , year=
-
[53]
CVPR , year=
Deep unfolding network for image super-resolution , author=. CVPR , year=
-
[54]
Deep Linear Discriminant Analysis
Deep linear discriminant analysis , author=. arXiv preprint arXiv:1511.04707 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
SiPS , year=
Fisher discriminant analysis with kernels , author=. SiPS , year=
-
[56]
NeurIPS , year =
PyTorch: An Imperative Style, High-Performance Deep Learning Library , author =. NeurIPS , year =
-
[57]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
The relativistic discriminator: a key element missing from standard GAN
The relativistic discriminator: a key element missing from standard GAN , author=. arXiv preprint arXiv:1807.00734 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
CVPR , year=
Material recognition in the wild with the materials in context database , author=. CVPR , year=
-
[60]
NeurIPS , year=
Mesh-tensorflow: Deep learning for supercomputers , author=. NeurIPS , year=
-
[61]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Gshard: Scaling giant models with conditional computation and automatic sharding , author=. arXiv preprint arXiv:2006.16668 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[62]
CVPR , year=
Ntire 2017 challenge on single image super-resolution: Dataset and study , author=. CVPR , year=
2017
-
[63]
Multimedia Tools and Applications , volume=
Sketch-based manga retrieval using manga109 dataset , author=. Multimedia Tools and Applications , volume=. 2017 , publisher=
2017
-
[64]
ECCV , year=
Accelerating the super-resolution convolutional neural network , author=. ECCV , year=
-
[65]
Categorical Reparameterization with Gumbel-Softmax
Categorical reparameterization with gumbel-softmax , author=. arXiv preprint arXiv:1611.01144 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
NeurIPS , year=
Gans trained by a two time-scale update rule converge to a local nash equilibrium , author=. NeurIPS , year=
-
[67]
CVPR , year=
The unreasonable effectiveness of deep features as a perceptual metric , author=. CVPR , year=
-
[68]
TPAMI , year=
Image quality assessment: Unifying structure and texture similarity , author=. TPAMI , year=
-
[69]
TIP , year=
No-reference image quality assessment in the spatial domain , author=. TIP , year=
-
[70]
CVPR , year=
Learning Continuous Image Representation with Local Implicit Image Function , author=. CVPR , year=
-
[71]
NeurIPS , year=
Implicit neural representations with periodic activation functions , author=. NeurIPS , year=
-
[72]
CVPR , pages=
A Text Attention Network for Spatial Deformation Robust Scene Text Image Super-resolution , author=. CVPR , pages=
-
[73]
CVPR , pages=
LAR-SR: A Local Autoregressive Model for Image Super-Resolution , author=. CVPR , pages=
-
[74]
arXiv preprint arXiv:2207.09228 , year=
Image Super-Resolution with Deep Dictionary , author=. arXiv preprint arXiv:2207.09228 , year=
-
[75]
arXiv preprint arXiv:2208.11247 , year=
SwinFIR: Revisiting the SwinIR with Fast Fourier Convolution and Improved Training for Image Super-Resolution , author=. arXiv preprint arXiv:2208.11247 , year=
-
[76]
ICCV , pages=
Mask r-cnn , author=. ICCV , pages=
-
[77]
ECCV , year=
Microsoft coco: Common objects in context , author=. ECCV , year=
-
[78]
, author=
Visualizing data using t-SNE. , author=. JMLR , year=
-
[79]
CVPR , year=
The perception-distortion tradeoff , author=. CVPR , year=
-
[80]
ICCV , year=
Real-esrgan: Training real-world blind super-resolution with pure synthetic data , author=. ICCV , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.