Toward Signing Activity Projection in Sign Language Interaction
Pith reviewed 2026-06-27 16:49 UTC · model grok-4.3
The pith
Adapting spoken turn-taking models to sign language works for predicting hold-or-shift decisions when hand cues are available but struggles with shift prediction alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Transferring the Voice Activity Projection architecture to dyadic sign language interaction yields promising accuracy on SHIFT/HOLD prediction when hand-derived features are included, while SHIFT prediction remains difficult; these outcomes demonstrate both the partial viability of the transfer and the limits of relying on speech-derived activity categories.
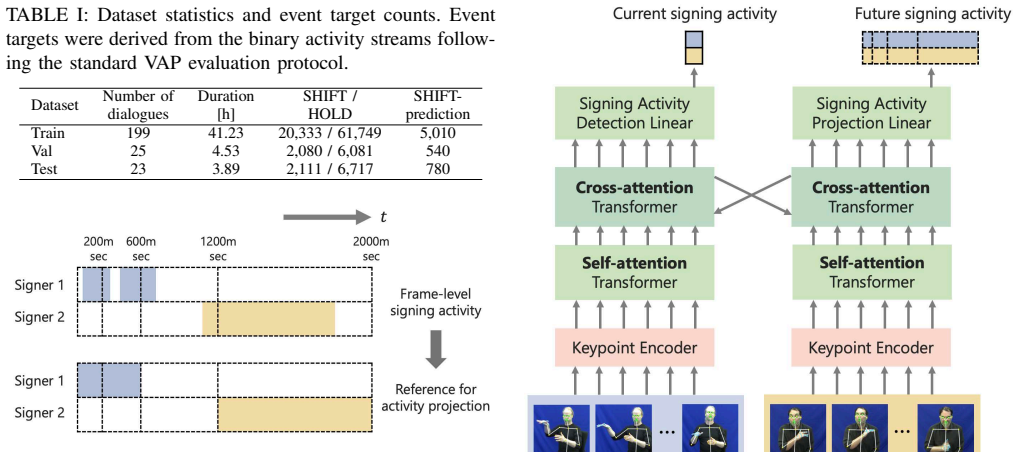
What carries the argument
An adapted Voice Activity Projection model that takes pose-derived hand, eye-region, and mouth-region features as input to forecast future binary signing activity states derived from lexical annotations.
If this is right
- Hand cues supply the strongest signal for deciding whether the current signer will hold or yield the floor.
- Combined hold-or-shift labels are easier to predict than shift labels alone under the current formulation.
- Pose features alone can support initial predictive modeling without requiring full video or depth data.
- Any successful deployment to robots will need event definitions that are native to signing rather than borrowed from speech.
Where Pith is reading between the lines
- Defining signing-specific events such as sustained gaze aversion or body lean could improve prediction beyond the current proxy labels.
- The same architecture might be tested on multi-party signing or on interactions where one participant is a signing robot.
- Collecting new corpora with explicit turn annotations rather than deriving them from lexical tiers would provide a stronger test of the approach.
Load-bearing premise
Binary streams of signing activity extracted from lexical sign annotations serve as a sufficient proxy for the turn-taking events that actually occur in live sign language conversations.
What would settle it
A follow-up experiment that records live sign language dyads, annotates actual turn transitions independently of lexical signs, and shows that the model trained on the proxy streams fails to predict those transitions would falsify the transfer claim.
Figures

read the original abstract
Social robots must interact robustly not only with users assumed by speech-centered systems but also with diverse users whose communication relies on different modalities, e.g., sign language. One important capability gap is predictive turn-taking with signing users. Although Voice Activity Projection (VAP) has been successfully used to model future voice activity in spoken interaction, it remains unclear whether the framework transfers to sign language interaction. This paper presents an initial transfer study of adapting a VAP architecture to dyadic sign language interaction. Using interaction recordings from the Public DGS Corpus, we derive binary signing activity streams from lexical sign annotations and formulate proxy tasks for turn-taking prediction. The model uses pose-derived hand, eye-region, and mouth-region features extracted for each signer. The results show that SHIFT/HOLD prediction is promising, especially with hand cues, while SHIFT-prediction remains difficult. These findings provide initial evidence for both the promise and the current limitations of transferring predictive turn-taking models from spoken interaction to sign language interaction. Predictive modeling of sign language interaction still requires sign-language-specific event definitions that go beyond speech-derived categories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an initial transfer study adapting the Voice Activity Projection (VAP) framework to dyadic sign language interaction. Using recordings from the Public DGS Corpus, binary signing activity streams are derived from lexical sign annotations to formulate proxy tasks for turn-taking prediction (SHIFT/HOLD and SHIFT). The model incorporates pose-derived features from hands, eye regions, and mouth regions. Results indicate SHIFT/HOLD prediction is promising (especially with hand cues) while SHIFT prediction remains difficult, providing initial evidence for both the promise and limitations of transferring predictive turn-taking models from spoken interaction, with a call for sign-language-specific event definitions.
Significance. If the proxy tasks are shown to validly approximate interactional turn-taking, the work would be significant for extending predictive modeling to sign language users in human-robot interaction, addressing a modality gap in inclusive systems. It usefully identifies differential difficulty between prediction subtasks and demonstrates adaptation of a VAP-style architecture with multi-cue pose features. The explicit acknowledgment of limitations and need for domain-specific definitions is a strength. However, the current presentation supplies only directional claims without metrics, limiting assessment of practical impact.
major comments (2)
- [Abstract] Abstract: the claim that 'the results show that SHIFT/HOLD prediction is promising' supplies no quantitative metrics, baselines, error bars, or architecture/training details, leaving the central claim of 'initial evidence' unsupported by visible evidence and preventing evaluation of effect size or reliability.
- [Abstract] Abstract (proxy task formulation): binary signing activity streams derived from lexical sign annotations are used as proxies for turn-taking events without any reported alignment checks, human validation against interactional phenomena (holds, overlaps, gaze shifts), or comparison to established sign-language coding schemes; this untested mapping is load-bearing for the transfer claim.
minor comments (2)
- The abstract references 'pose-derived hand, eye-region, and mouth-region features' but omits extraction pipeline, feature dimensionality, or how they are fed into the VAP architecture.
- Consider citing prior literature on sign-language turn-taking or VAP extensions to non-speech modalities to better situate the transfer study.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review of our initial transfer study. We address each major comment below and outline revisions to improve the clarity and support for our claims while preserving the exploratory nature of the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'the results show that SHIFT/HOLD prediction is promising' supplies no quantitative metrics, baselines, error bars, or architecture/training details, leaving the central claim of 'initial evidence' unsupported by visible evidence and preventing evaluation of effect size or reliability.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The full manuscript reports F1 scores, comparisons across feature sets (hands, eyes, mouth), and training details for the VAP-style model, but these are not summarized in the abstract. We will revise the abstract to report specific metrics (e.g., F1 for SHIFT/HOLD with hand cues) and briefly note the architecture and evaluation setup to make the central claims self-contained and evaluable. revision: yes
-
Referee: [Abstract] Abstract (proxy task formulation): binary signing activity streams derived from lexical sign annotations are used as proxies for turn-taking events without any reported alignment checks, human validation against interactional phenomena (holds, overlaps, gaze shifts), or comparison to established sign-language coding schemes; this untested mapping is load-bearing for the transfer claim.
Authors: We acknowledge this as a valid limitation of the current proxy formulation. The manuscript already notes the need for sign-language-specific event definitions beyond speech-derived categories. To address the concern, we will expand the discussion to explicitly describe the proxy derivation process, note the absence of alignment validation in this initial study, and outline plans for future human validation against interactional phenomena and established coding schemes. We maintain that the lexical-annotation proxy is a reasonable starting point given available data, but agree additional caveats are warranted. revision: partial
Circularity Check
No circularity: empirical transfer study with independent evaluation
full rationale
The paper performs an empirical adaptation of the VAP framework to sign-language data by deriving binary activity streams from existing lexical annotations, extracting pose features, training a model, and reporting SHIFT/HOLD prediction metrics. No equations, fitted parameters, or self-citations are shown to reduce any reported prediction to the input labels by construction. The central results rest on held-out evaluation of the trained model rather than on definitional equivalence or load-bearing self-reference. The proxy-task assumption is an external validity concern, not a circularity in the derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
V oice Activity Projection: Self-supervised Learning of Turn-taking Events,
E. Ekstedt and G. Skantze, “V oice Activity Projection: Self-supervised Learning of Turn-taking Events,” inProc. Interspeech 2022, 2022, pp. 5190–5194
2022
-
[2]
Real-time and continuous turn-taking prediction using voice ac- tivity projection,
K. Inoue, B. Jiang, E. Ekstedt, T. Kawahara, and G. Skantze, “Real-time and continuous turn-taking prediction using voice activity projection,” inInternational Workshop on Spoken Dialogue Systems Technology (IWSDS), 2024. [Online]. Available: https://arxiv.org/abs/2401.04868
-
[3]
Applying general turn-taking models to conversational human-robot interaction,
G. Skantze and B. Irfan, “Applying general turn-taking models to conversational human-robot interaction,” inProceedings of the 2025 ACM/IEEE International Conference on Human-Robot Interaction, 2025, p. 859–868
2025
-
[4]
Turn taking patterns in deaf conversation,
J. Coates and R. L. Sutton-Spence, “Turn taking patterns in deaf conversation,”Journal of Sociolinguistics, vol. 5, no. 4, pp. 507–529, 2001
2001
-
[5]
Turns and turn-taking in sign lan- guage interaction: A study of turn-final holds,
S. Groeber and E. Pochon-Berger, “Turns and turn-taking in sign lan- guage interaction: A study of turn-final holds,”Journal of Pragmatics, vol. 65, pp. 121–136, 2014
2014
-
[6]
Turn-timing in signed conversations: Coordinating stroke-to-stroke turn boundaries,
C. de V os, F. Torreira, and S. C. Levinson, “Turn-timing in signed conversations: Coordinating stroke-to-stroke turn boundaries,”Fron- tiers in Psychology, vol. 6, p. 268, 2015
2015
-
[7]
R. Konrad, T. Hanke, G. Langer, D. Blanck, J. Bleicken, I. Hofmann, O. Jeziorski, L. K ¨onig, S. K ¨onig, R. Nishio, A. Regen, U. Salden, S. Wagner, S. Worseck, O. B ¨ose, E. Jahn, and M. Schulder, “Meine dgs – annotiert. ¨offentliches korpus der deutschen geb ¨ardensprache, 3. release / my dgs – annotated. public corpus of German Sign Language, 3rd relea...
-
[8]
One signer at a time? a corpus study of turn-taking patterns in signed dialogue,
D. Green and A. Eshghi, “One signer at a time? a corpus study of turn-taking patterns in signed dialogue,” inProceedings of the 27th Workshop on the Semantics and Pragmatics of Dialogue – Poster Abstracts, Maribor, Slovenia, 2023, pp. 146–148
2023
-
[9]
The management of turn transition in signed interaction through the lens of overlaps,
S. Girard-Groeber, “The management of turn transition in signed interaction through the lens of overlaps,”Frontiers in Psychology, vol. 6, p. 741, 2015
2015
-
[10]
Turn-taking mechanism in Japanese Sign Language conversation: An analysis on adjacency pair and signals,
K. Kikuchi, “Turn-taking mechanism in Japanese Sign Language conversation: An analysis on adjacency pair and signals,”Japanese Journal of Sign Language Studies, vol. 17, pp. 29–45, 2008
2008
-
[11]
Predicting conversational turns: Signers’ and non-signers’ sensitivity to language-specific and globally accessible cues,
C. de V os, M. Casillas, T. Uittenbogert, O. Crasborn, and S. C. Levinson, “Predicting conversational turns: Signers’ and non-signers’ sensitivity to language-specific and globally accessible cues,”Lan- guage, vol. 98, no. 1, pp. 35–62, 2022
2022
-
[12]
Some interactional functions of finger pointing in signed language conversations,
L. Ferrara, “Some interactional functions of finger pointing in signed language conversations,”Glossa: a journal of general linguistics, vol. 5, no. 1, pp. 1–26, 2020, article 88
2020
-
[13]
Indexing turn-beginnings in Norwegian Sign Language con- versation,
——, “Indexing turn-beginnings in Norwegian Sign Language con- versation,”Gesture, vol. 21, no. 1, pp. 1–27, 2022
2022
-
[14]
Your turn! using finger pointing and palm-up actions to ask questions in Norwegian Sign Language,
B. Arnold and L. Ferrara, “Your turn! using finger pointing and palm-up actions to ask questions in Norwegian Sign Language,”Sign Language Studies, vol. 24, no. 3, pp. 621–651, 2024
2024
-
[15]
Manual backchannel responses in signers’ conversations in Swedish Sign Language,
J. Mesch, “Manual backchannel responses in signers’ conversations in Swedish Sign Language,”Language & Communication, vol. 50, pp. 22–41, 2016
2016
-
[16]
Finding continuers in Swedish Sign Language,
C. B ¨orstell, “Finding continuers in Swedish Sign Language,”Linguis- tics Vanguard, vol. 10, no. 1, pp. 537–548, 2024
2024
-
[17]
Phonetic differ- ences between affirmative and feedback head nods in German Sign Language (dgs): A pose estimation study,
A. Bauer, A. Kuder, M. Schulder, and J. Schepens, “Phonetic differ- ences between affirmative and feedback head nods in German Sign Language (dgs): A pose estimation study,”PLOS ONE, vol. 19, no. 5, p. e0304040, 2024
2024
-
[18]
Real-time sign language detection using human pose estimation,
A. Moryossef, I. Tsochantaridis, R. Aharoni, S. Ebling, and S. Narayanan, “Real-time sign language detection using human pose estimation,” inComputer Vision – ECCV 2020 Workshops: Glasgow, UK, August 23–28, 2020, Proceedings, Part II, 2020, p. 237–248
2020
-
[19]
Linguistically motivated sign language segmentation,
A. Moryossef, Z. Jiang, M. M ¨uller, S. Ebling, and Y . Goldberg, “Linguistically motivated sign language segmentation,” inFindings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 12 703–12 724. [Online]. Available: https://aclanthology.org/2023.findings-emnlp.846/
2023
-
[20]
Utterance-unit annotation for the JSL dialogue corpus: Toward a multimodal approach to corpus linguistics,
M. Bono, R. Sakaida, T. Okada, and Y . Miyao, “Utterance-unit annotation for the JSL dialogue corpus: Toward a multimodal approach to corpus linguistics,” inProceedings of the LREC2020 9th Workshop on the Representation and Processing of Sign Languages: Sign Language Resources in the Service of the Language Community, Technological Challenges and Applicat...
2020
-
[21]
Evaluating the alignment of utterances in the Swedish Sign Language corpus,
C. B ¨orstell, “Evaluating the alignment of utterances in the Swedish Sign Language corpus,” inProceedings of the LREC- COLING 2024 11th Workshop on the Representation and Processing of Sign Languages: Evaluation of Sign Language Resources. ELRA and ICCL, 2024, pp. 36–45. [Online]. Available: https://aclanthology.org/2024.signlang-1.4/
2024
-
[22]
Multilingual turn-taking prediction using voice activity projection,
K. Inoue, B. Jiang, E. Ekstedt, T. Kawahara, and G. Skantze, “Multilingual turn-taking prediction using voice activity projection,” inProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 2024, pp. 11 873–11 883. [Online]. Available: https://aclanthology.org/2024.lrec-main.1036/
2024
-
[23]
Multimodal voice activity prediction: Turn-taking events detection in expert-novice conversation,
K. Onishi, H. Tanaka, and S. Nakamura, “Multimodal voice activity prediction: Turn-taking events detection in expert-novice conversation,” inProceedings of the 11th International Conference on Human-Agent Interaction, 2023, p. 13–21. [Online]. Available: https://doi.org/10.1145/3623809.3623837
-
[24]
Integrating respiration into voice activity projection for enhancing turn-taking performance,
T. Obi and K. Funakoshi, “Integrating respiration into voice activity projection for enhancing turn-taking performance,” in Proceedings of the 15th International Workshop on Spoken Dialogue Systems Technology, May 2025, pp. 272–276. [Online]. Available: https://aclanthology.org/2025.iwsds-1.28/
2025
-
[25]
A noise-robust turn-taking system for real-world dialogue robots: A field experiment,
K. Inoue, Y . Okafuji, J. Baba, Y . Ohira, K. Hyodo, and T. Kawahara, “A noise-robust turn-taking system for real-world dialogue robots: A field experiment,”2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 874–879, 2025. [Online]. Available: https://arxiv.org/abs/2503.06241
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.