Learning Cross-View Semantic Priors for Single-Reference Unseen Object Pose Estimation
Pith reviewed 2026-06-26 12:36 UTC · model grok-4.3
The pith
Cross-view semantic interaction with two training constraints yields more reliable correspondences for single-reference unseen object 6D pose estimation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
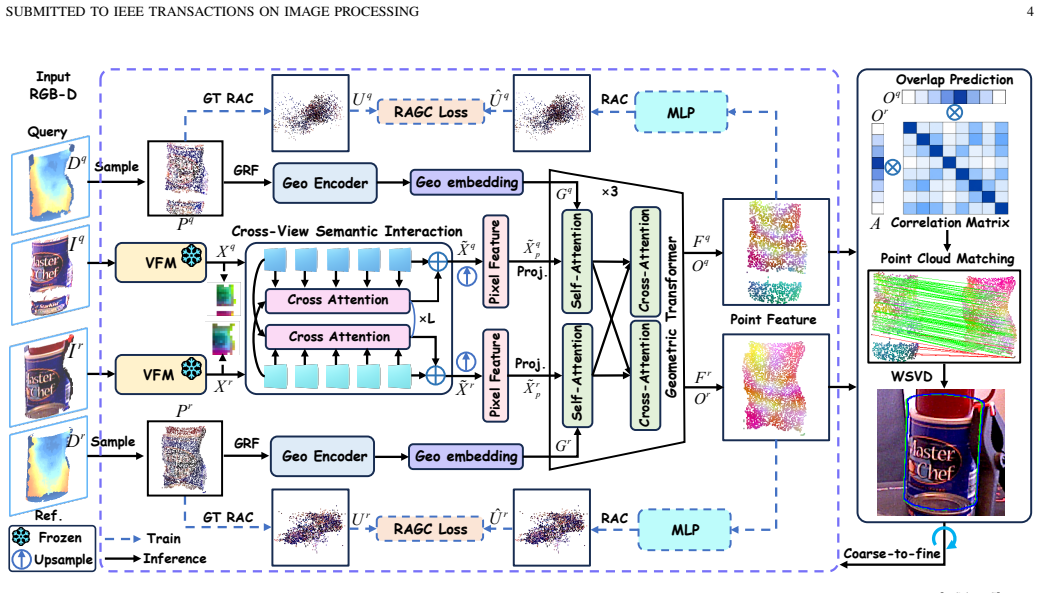
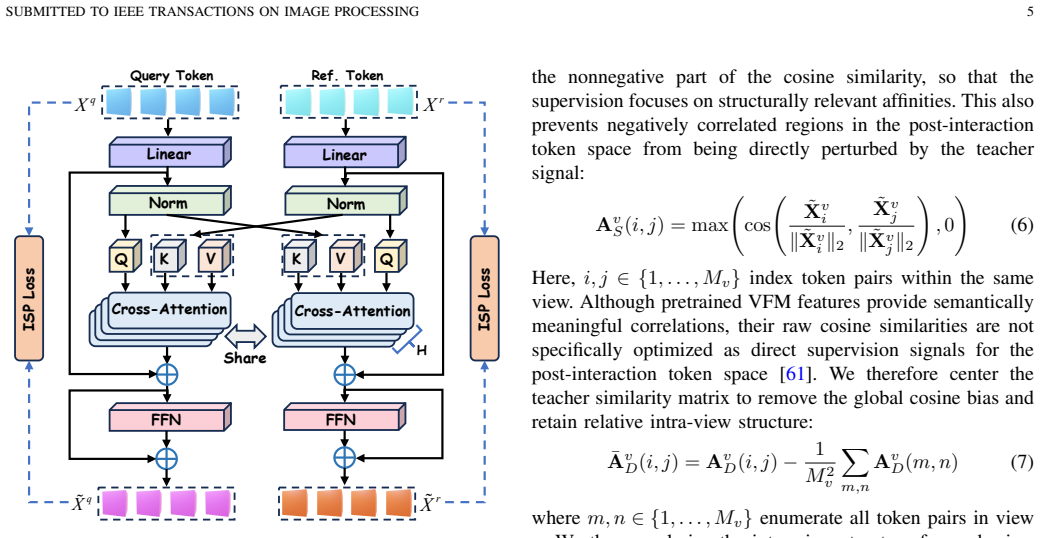
Instead of processing VFM features independently per view, the correspondence pipeline is built around an early cross-view semantic prior formed by dense query-reference token interaction. Direct interaction can disturb original token structure and still requires 3D representation consistency, so the intra-view structure preservation loss keeps intra-view token affinity intact while the reference-anchored geometric consistency loss enforces spatial consistency of decoded point features. The resulting correspondences support weighted SVD pose recovery for arbitrary novel objects from a single reference view.
What carries the argument
Cross-view semantic interaction (CVSI) that enables dense VFM tokens to exchange semantic context across views, regularized by intra-view structure preservation (IVSP) loss and reference-anchored geometric consistency (RAGC) loss to ensure reliability for rigid 3D correspondence.
If this is right
- Learned point features gain joint semantic and geometric discriminability that helps correspondence in challenging matching scenarios.
- The approach reaches state-of-the-art results on six benchmarks under multiple view-pair settings.
- Inference speed stays comparable to prior VFM-based correspondence pipelines.
- A new view-pair evaluation protocol derived from BOP YCB-V and TUD-L datasets exposes robustness under difficult reference-query conditions.
- Pose recovery proceeds directly from the improved correspondences via weighted SVD.
Where Pith is reading between the lines
- The same early-interaction pattern could be tested on multi-reference or video sequences to see whether the prior scales without additional losses.
- If the constraints generalize, similar token-exchange mechanisms might improve other 3D tasks that currently use frozen VFM features independently per frame.
- The method's reliance on a single reference view suggests it could lower the data-collection cost for deploying pose estimators on new objects in robotics settings.
- A direct test on real-time streaming camera input with varying lighting would reveal whether the learned consistency holds beyond static benchmark pairs.
Load-bearing premise
The two training-time constraints suffice to keep the cross-view semantic prior reliable for rigid 3D correspondence without introducing new mismatches or harming original VFM token discriminability.
What would settle it
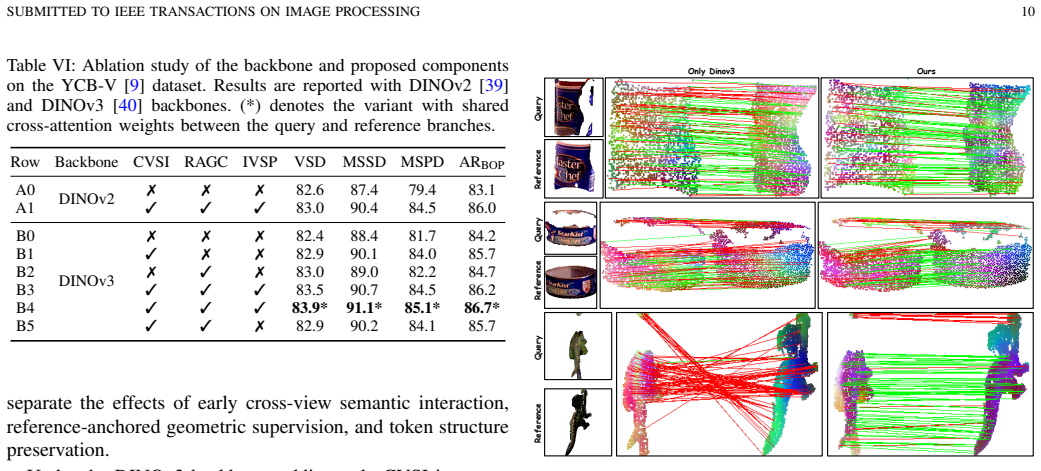
An ablation experiment in which removing either the IVSP or RAGC loss causes accuracy to fall to or below the independent-feature baseline on the same view-pair protocol.
Figures







read the original abstract
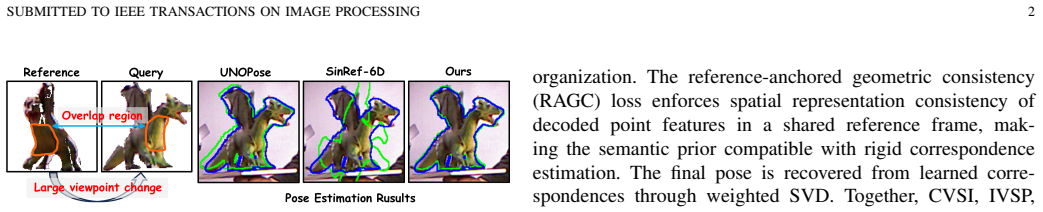
Single-reference unseen object 6D pose estimation reduces object onboarding by estimating poses of arbitrary novel objects from only one reference view. Recent correspondence-based pipelines have achieved robust performance with vision foundation model (VFM) features. However, they typically treat these features as intra-view descriptors, leaving dense visual-semantic cues, including appearance, structure, and context, insufficiently exchanged across views before geometric decoding. Consequently, the decoded point features may lack joint semantic and geometric discriminability, making correspondence estimation still difficult in challenging cases. Instead of processing features independently, we build the correspondence pipeline around an early cross-view semantic prior. Specifically, cross-view semantic interaction (CVSI) enables dense query and reference VFM tokens to exchange semantic context and form a cross-view prior. Nevertheless, direct CVSI may disturb the VFM token structure, while the resulting semantic prior still needs 3D representation consistency for rigid correspondence. To make this CVSI prior reliable for 3D correspondence learning, we introduce two complementary training-time constraints: the intra-view structure preservation (IVSP) loss preserves the original intra-view token affinity structure during interaction, while the reference-anchored geometric consistency (RAGC) loss enforces spatial representation consistency of decoded point features. The final pose is recovered from learned correspondences through weighted SVD. We further construct a challenging view-pair protocol from the BOP Challenge datasets YCB-V and TUD-L to evaluate robustness in difficult matching scenarios. Extensive experiments on six benchmarks under different view-pair settings show that our method achieves state-of-the-art performance while maintaining comparable inference speed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that single-reference unseen object 6D pose estimation can be improved by building the correspondence pipeline around an early cross-view semantic interaction (CVSI) module that lets dense VFM tokens from query and reference views exchange semantic context; two training-time constraints (IVSP loss preserving intra-view token affinity and RAGC loss enforcing reference-anchored spatial consistency of decoded points) are introduced to keep the resulting prior reliable for rigid 3D correspondence; final poses are recovered by weighted SVD; a new challenging view-pair protocol is constructed from YCB-V and TUD-L; and extensive experiments on six benchmarks under varied view-pair settings report state-of-the-art performance at comparable inference speed.
Significance. If the reported results hold, the work would demonstrate a practical way to inject cross-view semantic context into VFM-based correspondence pipelines while mitigating the two risks (disturbance of token structure and lack of 3D consistency) explicitly flagged in the abstract; the construction of a new view-pair protocol from BOP datasets is a concrete contribution that could aid future robustness evaluations.
major comments (2)
- [Method description (paragraph after CVSI definition)] The paragraph beginning 'To make this CVSI prior reliable...' asserts that IVSP and RAGC together suffice to prevent new mismatches and preserve VFM token discriminability, yet the supplied text contains no quantitative ablation isolating their individual effects or failure cases where the constraints are insufficient; because the SOTA claim rests directly on this sufficiency, the absence of such evidence is load-bearing for the central empirical argument.
- [Abstract and Experiments section] The abstract states that 'extensive experiments on six benchmarks ... show that our method achieves state-of-the-art performance' but supplies neither the numerical margins, per-benchmark tables, nor error-analysis breakdowns; without these data the central claim cannot be verified and the soundness assessment remains provisional.
minor comments (2)
- [Abstract] The abstract is unusually long; condensing the motivation and results paragraphs would improve readability while retaining all technical claims.
- [Pose recovery paragraph] Notation for the weighted SVD step is introduced without an explicit equation reference; adding an equation label would clarify how the learned correspondences are converted to pose.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Method description (paragraph after CVSI definition)] The paragraph beginning 'To make this CVSI prior reliable...' asserts that IVSP and RAGC together suffice to prevent new mismatches and preserve VFM token discriminability, yet the supplied text contains no quantitative ablation isolating their individual effects or failure cases where the constraints are insufficient; because the SOTA claim rests directly on this sufficiency, the absence of such evidence is load-bearing for the central empirical argument.
Authors: We agree with the referee that the method description would be improved by including quantitative evidence for the sufficiency of IVSP and RAGC. We will add ablation studies isolating their individual effects and discuss failure cases in the revised manuscript. This will support the central empirical argument more robustly. revision: yes
-
Referee: [Abstract and Experiments section] The abstract states that 'extensive experiments on six benchmarks ... show that our method achieves state-of-the-art performance' but supplies neither the numerical margins, per-benchmark tables, nor error-analysis breakdowns; without these data the central claim cannot be verified and the soundness assessment remains provisional.
Authors: We agree that providing numerical margins and breakdowns would strengthen the abstract and experiments section. We will revise the abstract to include specific performance numbers and margins, and expand the experiments section with per-benchmark tables and error-analysis breakdowns to allow verification of the SOTA claim. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines CVSI interaction plus two explicit training constraints (IVSP loss preserving intra-view affinity; RAGC loss enforcing reference-anchored geometric consistency) as new modules whose effectiveness is measured on external BOP benchmarks. No equations or steps reduce by construction to fitted inputs, self-citations, or renamed prior results. The central claim rests on the stated constraints being effective, which is an empirical question evaluated outside the derivation itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- weights of IVSP and RAGC losses
axioms (2)
- domain assumption VFM tokens contain dense visual-semantic cues (appearance, structure, context) that benefit from cross-view exchange before geometric decoding
- domain assumption Rigid correspondence requires 3D representation consistency of decoded point features
invented entities (3)
-
Cross-View Semantic Interaction (CVSI)
no independent evidence
-
Intra-View Structure Preservation (IVSP) loss
no independent evidence
-
Reference-Anchored Geometric Consistency (RAGC) loss
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A Review of Robot Learning for Manipulation: Challenges, Representations, and Algorithms
Oliver Kroemer, Scott Niekum, and George Konidaris. “A Review of Robot Learning for Manipulation: Challenges, Representations, and Algorithms”. In:JMLR22.30 (2021), pp. 1–82
2021
-
[2]
Vision-based robotic grasping from object localization, object pose estimation to grasp estimation for parallel grippers: a review
Guoguang Du et al. “Vision-based robotic grasping from object localization, object pose estimation to grasp estimation for parallel grippers: a review”. In:Artificial Intelligence Review54.3 (2021), pp. 1677–1734
2021
-
[3]
Efficient Center V oting for Object Detection and 6D Pose Estimation in 3D Point Cloud
Jianwei Guo et al. “Efficient Center V oting for Object Detection and 6D Pose Estimation in 3D Point Cloud”. In:IEEE Transactions on Image Processing30 (2021), pp. 5072–5084
2021
-
[4]
Domain-Translated 3D Object Pose Estimation
Christos Papaioannidis, Vasileios Mygdalis, and Ioannis Pitas. “Domain-Translated 3D Object Pose Estimation”. In:IEEE Trans- actions on Image Processing29 (2020), pp. 9279–9291
2020
-
[5]
Total3DUnderstanding: Joint layout, object pose and mesh reconstruction for indoor scenes from a single image
Yinyu Nie et al. “Total3DUnderstanding: Joint layout, object pose and mesh reconstruction for indoor scenes from a single image”. In: CVPR. 2020, pp. 55–64
2020
-
[6]
Cooperative holistic scene understanding: Uni- fying 3d object, layout, and camera pose estimation
Siyuan Huang et al. “Cooperative holistic scene understanding: Uni- fying 3d object, layout, and camera pose estimation”. In:NeurIPS. 2018
2018
-
[7]
Pose estimation for augmented reality: a hands-on survey
Eric Marchand, Hideaki Uchiyama, and Fabien Spindler. “Pose estimation for augmented reality: a hands-on survey”. In:IEEE Transactions on Visualization and Computer Graphics22.12 (2015), pp. 2633–2651
2015
-
[8]
Deep multi-state object pose estimation for augmented reality assembly
Yongzhi Su et al. “Deep multi-state object pose estimation for augmented reality assembly”. In:IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct). 2019, pp. 222–227
2019
-
[9]
PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes
Yu Xiang et al. “PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes”. In:RSS. 2018
2018
-
[10]
Zebrapose: Coarse to fine surface encoding for 6dof object pose estimation
Yongzhi Su et al. “Zebrapose: Coarse to fine surface encoding for 6dof object pose estimation”. In:CVPR. 2022, pp. 6738–6748
2022
-
[11]
PVNet: Pixel-Wise V oting Network for 6DoF Object Pose Estimation
Sida Peng et al. “PVNet: Pixel-Wise V oting Network for 6DoF Object Pose Estimation”. In:IEEE Transactions on Pattern Analysis and Machine Intelligence44.6 (2022), pp. 3212–3223
2022
-
[12]
Resolving Symmetry Ambiguity in Correspondence-Based Methods for Instance-Level Object Pose Estimation
Yongliang Lin et al. “Resolving Symmetry Ambiguity in Correspondence-Based Methods for Instance-Level Object Pose Estimation”. In:IEEE Transactions on Image Processing34 (2025), pp. 1700–1711
2025
-
[13]
Gdrnpp: A geometry-guided and fully learning- based object pose estimator
Xingyu Liu et al. “Gdrnpp: A geometry-guided and fully learning- based object pose estimator”. In:IEEE Transactions on Pattern Analysis and Machine Intelligence(2025)
2025
-
[14]
Line-Based 6-DoF Object Pose Estimation and Tracking With an Event Camera
Zibin Liu et al. “Line-Based 6-DoF Object Pose Estimation and Tracking With an Event Camera”. In:IEEE Transactions on Image Processing33 (2024), pp. 4765–4780
2024
-
[15]
Normalized object coordinate space for category-level 6D object pose and size estimation
He Wang et al. “Normalized object coordinate space for category-level 6D object pose and size estimation”. In:CVPR. 2019, pp. 2642–2651. SUBMITTED TO IEEE TRANSACTIONS ON IMAGE PROCESSING 13
2019
-
[16]
6D-ViT: Category-Level 6D Object Pose Estimation via Transformer-Based Instance Representation Learning
Lu Zou et al. “6D-ViT: Category-Level 6D Object Pose Estimation via Transformer-Based Instance Representation Learning”. In:IEEE Transactions on Image Processing31 (2022), pp. 6907–6921
2022
-
[17]
Leveraging SE(3) Equivariance for Self-supervised Category-Level Object Pose Estimation from Point Clouds
Xiaolong Li et al. “Leveraging SE(3) Equivariance for Self-supervised Category-Level Object Pose Estimation from Point Clouds”. In: NeurIPS. 2021
2021
-
[18]
Secondpose: Se (3)-consistent dual-stream feature fusion for category-level pose estimation
Yamei Chen et al. “Secondpose: Se (3)-consistent dual-stream feature fusion for category-level pose estimation”. In:CVPR. 2024, pp. 9959– 9969
2024
-
[19]
ComPose: A Unified Completion-Pose Framework for Robust Category-Level Object Pose Estimation
Huan Ren et al. “ComPose: A Unified Completion-Pose Framework for Robust Category-Level Object Pose Estimation”. In:CVPR. 2026, pp. 14315–14324
2026
-
[20]
Deep learning-based object pose estimation: A comprehensive survey
Jian Liu et al. “Deep learning-based object pose estimation: A comprehensive survey”. In:arXiv preprint arXiv:2405.07801(2024)
arXiv 2024
-
[21]
Challenges for monocular 6-d object pose estimation in robotics
Stefan Thalhammer et al. “Challenges for monocular 6-d object pose estimation in robotics”. In:IEEE Transactions on Robotics40 (2024), pp. 4065–4084
2024
-
[22]
Latentfusion: End-to-end differentiable recon- struction and rendering for unseen object pose estimation
Keunhong Park et al. “Latentfusion: End-to-end differentiable recon- struction and rendering for unseen object pose estimation”. In:CVPR. 2020, pp. 10710–10719
2020
-
[23]
MegaPose: 6D Pose Estimation of Novel Objects via Render & Compare
Yann Labb ´e et al. “MegaPose: 6D Pose Estimation of Novel Objects via Render & Compare”. In:CoRL. PMLR. 2023, pp. 715–725
2023
-
[24]
FoundPose: Unseen Object Pose Estimation with Foundation Features
Evin Pınar ¨Ornek et al. “FoundPose: Unseen Object Pose Estimation with Foundation Features”. In:CVPR. 2024
2024
-
[25]
FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects
Bowen Wen et al. “FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects”. In:CVPR. 2024
2024
-
[26]
Sam-6d: Segment anything model meets zero-shot 6d object pose estimation
Jiehong Lin et al. “Sam-6d: Segment anything model meets zero-shot 6d object pose estimation”. In:CVPR. 2024
2024
-
[27]
PoseGaussian: 6D Pose Estimation for Unseen Objects via Sparse-View Object-Level 3D Gaussian Splatting
Wubin Shi, Shaoyan Gai, and Feipeng Da. “PoseGaussian: 6D Pose Estimation for Unseen Objects via Sparse-View Object-Level 3D Gaussian Splatting”. In:CVPR. 2026, pp. 4698–4707
2026
-
[28]
UNOPose: Unseen Object Pose Estimation with an Unposed RGB-D Reference Image
Xingyu Liu et al. “UNOPose: Unseen Object Pose Estimation with an Unposed RGB-D Reference Image”. In:CVPR. June 2025, pp. 22023–22034
2025
-
[29]
COG: Confidence-aware Optimal Geometric Correspondence for Unsupervised Single-reference Novel Object Pose Estimation
Yuchen Che et al. “COG: Confidence-aware Optimal Geometric Correspondence for Unsupervised Single-reference Novel Object Pose Estimation”. In:CVPR. 2026, pp. 11567–11578
2026
-
[30]
Scalable Unseen Objects 6-DoF Absolute Pose Esti- mation with Robotic Integration
Jian Liu et al. “Scalable Unseen Objects 6-DoF Absolute Pose Esti- mation with Robotic Integration”. In:IEEE Transactions on Robotics 42 (2026), pp. 1884–1901
2026
-
[31]
Nope: Novel object pose estimation from a single image
Van Nguyen Nguyen et al. “Nope: Novel object pose estimation from a single image”. In:CVPR. 2024, pp. 17923–17932
2024
-
[32]
Pope: 6-dof promptable pose estimation of any object, in any scene, with one reference
Zhiwen Fan et al. “Pope: 6-dof promptable pose estimation of any object, in any scene, with one reference”. In:CVPR Workshops. 2024
2024
-
[33]
Open-vocabulary object 6D pose estimation
Jaime Corsetti et al. “Open-vocabulary object 6D pose estimation”. In:CVPR. 2024
2024
-
[34]
High-Resolution Open-V ocabulary Object 6D Pose Estimation
Jaime Corsetti et al. “High-Resolution Open-V ocabulary Object 6D Pose Estimation”. In:IEEE Transactions on Pattern Analysis and Machine Intelligence48.2 (2026), pp. 2066–2077
2026
-
[35]
One2Any: One-Reference 6D Pose Estimation for Any Object
Mengya Liu et al. “One2Any: One-Reference 6D Pose Estimation for Any Object”. In:CVPR. 2025, pp. 6457–6467
2025
-
[36]
Any6D: Model-free 6D pose estimation of novel objects
Taeyeop Lee et al. “Any6D: Model-free 6D pose estimation of novel objects”. In:CVPR. 2025, pp. 11633–11643
2025
-
[37]
CoordAR: One-Reference 6D Pose Estimation of Novel Objects via Autoregressive Coordinate Map Generation
Dexin Zuo et al. “CoordAR: One-Reference 6D Pose Estimation of Novel Objects via Autoregressive Coordinate Map Generation”. In: AAAI. V ol. 40. 16. 2026, pp. 14122–14130
2026
-
[38]
ConceptPose: Training-Free Zero-Shot Object Pose Estimation using Concept Vectors
Liming Kuang et al. “ConceptPose: Training-Free Zero-Shot Object Pose Estimation using Concept Vectors”. In:CVPR. 2026, pp. 26582– 26592
2026
-
[39]
Dinov2: Learning robust visual features without supervision
Maxime Oquab et al. “Dinov2: Learning robust visual features without supervision”. In:arXiv preprint arXiv:2304.07193(2023)
Pith/arXiv arXiv 2023
-
[40]
Oriane Sim ´eoni et al. “Dinov3”. In:arXiv preprint arXiv:2508.10104 (2025)
Pith/arXiv arXiv 2025
-
[41]
Geotransformer: Fast and robust point cloud registration with geometric transformer
Zheng Qin et al. “Geotransformer: Fast and robust point cloud registration with geometric transformer”. In:IEEE Transactions on Pattern Analysis and Machine Intelligence(2023)
2023
-
[42]
BOP: Benchmark for 6D Object Pose Estima- tion
Tomas Hodan et al. “BOP: Benchmark for 6D Object Pose Estima- tion”. In:ECCV. 2018, pp. 19–34
2018
-
[43]
Learning 6D object pose estimation using 3D object coordinates
Eric Brachmann et al. “Learning 6D object pose estimation using 3D object coordinates”. In:ECCV. 2014
2014
-
[44]
Model based training, detection and pose estimation of texture-less 3d objects in heavily cluttered scenes
Stefan Hinterstoisser et al. “Model based training, detection and pose estimation of texture-less 3d objects in heavily cluttered scenes”. In: ACCV. Springer. 2012, pp. 548–562
2012
-
[45]
GigaPose: Fast and Robust Novel Object Pose Estimation via One Correspondence
Van Nguyen Nguyen et al. “GigaPose: Fast and Robust Novel Object Pose Estimation via One Correspondence”. In:CVPR. 2024
2024
-
[46]
Segment anything
Alexander Kirillov et al. “Segment anything”. In:ICCV. 2023, pp. 4015–4026
2023
-
[47]
Onepose: One-shot object pose estimation without cad models
Jiaming Sun et al. “Onepose: One-shot object pose estimation without cad models”. In:CVPR. 2022, pp. 6825–6834
2022
-
[48]
Onepose++: Keypoint-free one-shot object pose estimation without CAD models
Xingyi He et al. “Onepose++: Keypoint-free one-shot object pose estimation without CAD models”. In:NeurIPS. 2022, pp. 35103– 35115
2022
-
[49]
Gen6D: Generalizable Model-Free 6-DoF Object Pose Estimation from RGB Images
Yuan Liu et al. “Gen6D: Generalizable Model-Free 6-DoF Object Pose Estimation from RGB Images”. In:ECCV. 2022
2022
-
[50]
Fs6d: Few-shot 6d pose estimation of novel objects
Yisheng He et al. “Fs6d: Few-shot 6d pose estimation of novel objects”. In:CVPR. 2022, pp. 6814–6824
2022
-
[51]
A Method for Registration of 3- D Shapes
Paul J. Besl and Neil D. McKay. “A Method for Registration of 3- D Shapes”. In:IEEE Transactions on Pattern Analysis and Machine Intelligence14.2 (1992), pp. 239–256
1992
-
[52]
Efficient variants of the ICP algorithm
Szymon Rusinkiewicz and Marc Levoy. “Efficient variants of the ICP algorithm”. In:Proceedings third international conference on 3-D digital imaging and modeling. IEEE. 2001, pp. 145–152
2001
-
[53]
Fast point feature histograms (FPFH) for 3D registration
Radu Bogdan Rusu, Nico Blodow, and Michael Beetz. “Fast point feature histograms (FPFH) for 3D registration”. In:ICRA. IEEE. 2009, pp. 3212–3217
2009
-
[54]
Model globally, match locally: Efficient and robust 3D object recognition
Bertram Drost et al. “Model globally, match locally: Efficient and robust 3D object recognition”. In:CVPR. Ieee. 2010, pp. 998–1005
2010
-
[55]
Predator: Registration of 3d point clouds with low overlap
Shengyu Huang et al. “Predator: Registration of 3d point clouds with low overlap”. In:CVPR. 2021, pp. 4267–4276
2021
-
[56]
LoFTR: Detector-free local feature matching with transformers
Jiaming Sun et al. “LoFTR: Detector-free local feature matching with transformers”. In:CVPR. 2021, pp. 8922–8931
2021
-
[57]
O-MaMa: Learning Object Mask Match- ing between Egocentric and Exocentric Views
Lorenzo Mur-Labadia et al. “O-MaMa: Learning Object Mask Match- ing between Egocentric and Exocentric Views”. In:ICCV. 2025
2025
-
[58]
V 2-SAM: Marrying SAM2 with Multi-Prompt Experts for Cross-View Object Correspondence
Jiancheng Pan et al. “V 2-SAM: Marrying SAM2 with Multi-Prompt Experts for Cross-View Object Correspondence”. In:arXiv preprint arXiv:2511.20886(2025)
Pith/arXiv arXiv 2025
-
[59]
Vggt: Visual geometry grounded transformer
Jianyuan Wang et al. “Vggt: Visual geometry grounded transformer”. In:CVPR. 2025, pp. 5294–5306
2025
-
[60]
PointNet: Deep learning on point sets for 3D classification and segmentation
Charles R Qi et al. “PointNet: Deep learning on point sets for 3D classification and segmentation”. In:CVPR. 2017
2017
-
[61]
Unsupervised semantic segmentation by dis- tilling feature correspondences
Mark Hamilton et al. “Unsupervised semantic segmentation by dis- tilling feature correspondences”. In:arXiv preprint arXiv:2203.08414 (2022)
arXiv 2022
-
[62]
Representa- tion learning with contrastive predictive coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. “Representa- tion learning with contrastive predictive coding”. In:arXiv preprint arXiv:1807.03748(2018)
Pith/arXiv arXiv 2018
-
[63]
PyTorch: An Imperative Style, High-performance Deep Learning Library
Adam Paszke et al. “PyTorch: An Imperative Style, High-performance Deep Learning Library”. In:NeurIPS. 2019, pp. 8026–8037
2019
-
[64]
An image is worth 16x16 words: Trans- formers for image recognition at scale
Alexey Dosovitskiy et al. “An image is worth 16x16 words: Trans- formers for image recognition at scale”. In:ICLR. 2021
2021
-
[65]
BOP Challenge 2023 on Detection, Segmentation and Pose Estimation of Seen and Unseen Rigid Objects
Tomas Hodan et al. “BOP Challenge 2023 on Detection, Segmentation and Pose Estimation of Seen and Unseen Rigid Objects”. In:CVPR Workshops. 2024
2023
-
[66]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. “Adam: A Method for Stochastic Optimization”. In:ICLR. Ed. by Yoshua Bengio and Yann LeCun. 2015
2015
-
[67]
SGDR: Stochastic Gradient Descent with Warm Restarts
Frank Hutter Ilya Loshchilov. “SGDR: Stochastic Gradient Descent with Warm Restarts”. In:ICLR. 2017
2017
-
[68]
On evaluation of 6D object pose estimation
Tom ´aˇs Hoda ˇn, Ji ˇr´ı Matas, and ˇStˇep´an Obdr ˇz´alek. “On evaluation of 6D object pose estimation”. In:ECCV. Springer. 2016, pp. 606–619
2016
-
[69]
3D Registration with Maximal Cliques
Xiyu Zhang et al. “3D Registration with Maximal Cliques”. In:CVPR. 2023, pp. 17745–17754
2023
-
[70]
Fully convolu- tional geometric features
Christopher Choy, Jaesik Park, and Vladlen Koltun. “Fully convolu- tional geometric features”. In:ICCV. 2019, pp. 8958–8966
2019
-
[71]
UTOPIC: Uncertainty-aware Overlap Prediction Network for Partial Point Cloud Registration
Zhilei Chen et al. “UTOPIC: Uncertainty-aware Overlap Prediction Network for Partial Point Cloud Registration”. In:Computer Graphics Forum41 (2022), pp. 87–98
2022
-
[72]
Learning general and distinctive 3D local deep descriptors for point cloud registration
Fabio Poiesi and Davide Boscaini. “Learning general and distinctive 3D local deep descriptors for point cloud registration”. In:IEEE Transactions on Pattern Analysis and Machine Intelligence45.3 (2022), pp. 3979–3985
2022
-
[73]
FreeZe: Training-free Zero-shot 6D Pose Es- timation with Geometric and Vision Foundation Models
Andrea Caraffa et al. “FreeZe: Training-free Zero-shot 6D Pose Es- timation with Geometric and Vision Foundation Models”. In:ECCV. 2024
2024
-
[74]
Posediffu- sion: Solving pose estimation via diffusion-aided bundle adjustment
Jianyuan Wang, Christian Rupprecht, and David Novotny. “Posediffu- sion: Solving pose estimation via diffusion-aided bundle adjustment”. In:ICCV. 2023, pp. 9773–9783
2023
-
[75]
Relpose++: Recovering 6d poses from sparse-view observations
Amy Lin et al. “Relpose++: Recovering 6d poses from sparse-view observations”. In:3DV. 2024
2024
-
[76]
Object recognition from local scale-invariant fea- tures
David G Lowe. “Object recognition from local scale-invariant fea- tures”. In:ICCV. V ol. 2. IEEE. 1999, pp. 1150–1157
1999
-
[77]
Objectmatch: Ro- bust registration using canonical object correspondences
Can G ¨umeli, Angela Dai, and Matthias Nießner. “Objectmatch: Ro- bust registration using canonical object correspondences”. In:CVPR. 2023, pp. 13082–13091
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.