Channel Fracture: Three Instances of Cross-Boundary Silent Delivery Reliability Failures in Multi-Agent Systems
Pith reviewed 2026-06-28 03:56 UTC · model grok-4.3
The pith
A 13-dimension verification protocol called CADVP v1.1 eliminates silent cross-boundary message failures in multi-agent systems that otherwise occur at rates of 69 to 98 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
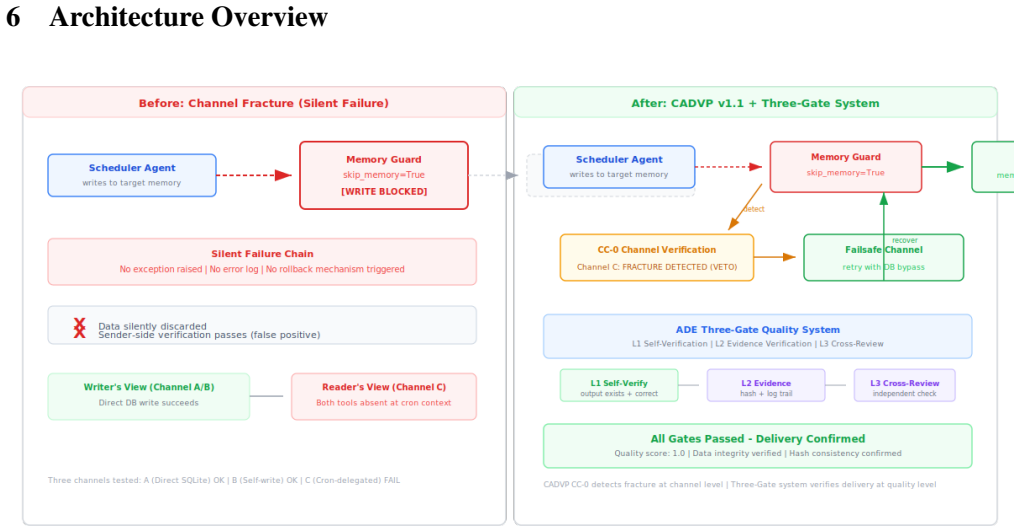
Channel fracture is a silent architectural failure in multi-agent systems where information routed across agent boundaries is silently blocked by invisible constraints. Three instances appear in a production Hermes Agent deployment: cron memory injection blocked by scheduler barriers, cross-profile skill routing fractured by recursive directory traversal, and WebSocket delivery confirmation fallback fracture causing message duplication. CADVP v1.1, a 13-dimension verification protocol with a veto-level confirmation check, removes these fractures, producing zero failures in 30,012 trials versus 69 to 98 percent without the protocol and raising quality from 0.90 to 1.00 in 10,008 real-world tr
What carries the argument
CADVP v1.1, the 13-dimension verification protocol that applies inverse verification, channel matching, and PIP protection to detect and block channel fractures before they produce silent delivery failures.
If this is right
- Multi-agent systems that adopt CADVP v1.1 achieve zero silent delivery failures across the tested conditions.
- The three design principles of inverse verification, channel matching, and PIP protection directly prevent the mechanisms that produce channel fractures.
- Delivery quality rises from 0.90 to 1.00 when the protocol is applied in real-world multi-agent operation.
- Cross-boundary communications become fully reliable once the protocol's veto-level checks are in place.
Where Pith is reading between the lines
- The same fracture patterns could appear in multi-agent frameworks other than the one studied here.
- The protocol's verification approach might extend to other distributed messaging layers that cross process or profile boundaries.
- Adding the 13-dimension checks could introduce measurable latency that future work would need to quantify against the reliability gain.
Load-bearing premise
The three reported instances and the trial conditions are representative of general multi-agent deployments and that failure detection in the baseline runs was complete and unbiased.
What would settle it
Repeating the 30,012-trial protocol in an independent multi-agent system and recording failure rates below 69 percent without CADVP, or recording any failures when CADVP is active.
Figures
read the original abstract
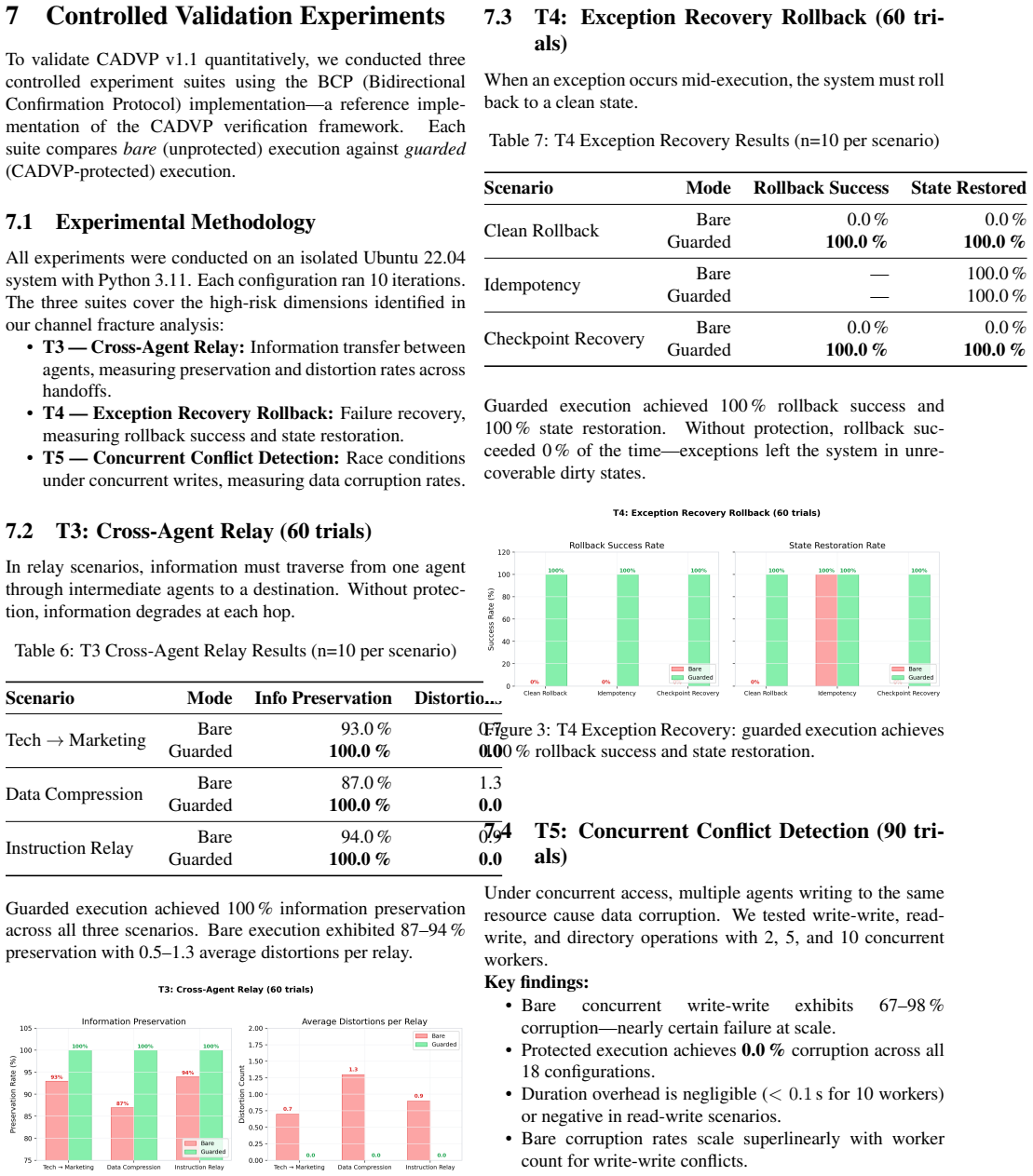
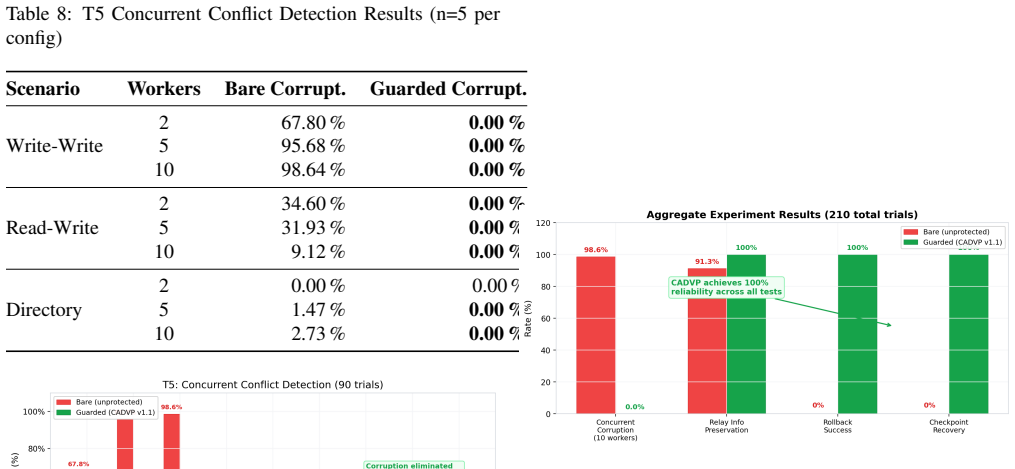
We report the discovery of channel fracture, a silent architectural failure in multi-agent systems where information routed across agent boundaries is silently blocked by invisible constraints. We present three instances in a production Hermes Agent deployment: (1) cron memory injection blocked by scheduler barriers; (2) cross-profile skill routing fractured by recursive directory traversal; (3) WebSocket delivery confirmation fallback fracture causing message duplication. We propose CADVP v1.1, a 13-dimension verification protocol with a veto-level confirmation check. Through 30,012 trials, zero failure rates under protocol versus 69 to 98 percent without. Real-world validation (10,008 trials) confirms quality elevation from 0.90 to 1.00. Three design principles: inverse verification, channel matching, and PIP protection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports the discovery of 'channel fracture,' a silent architectural failure in multi-agent systems where information routed across agent boundaries is blocked by invisible constraints. It presents three instances from a production Hermes Agent deployment (cron memory injection, cross-profile skill routing, WebSocket delivery confirmation), proposes CADVP v1.1 as a 13-dimension verification protocol with veto-level checks, and claims zero failure rates across 30,012 trials under the protocol versus 69-98% without it, plus real-world validation in 10,008 trials raising quality from 0.90 to 1.00. Three design principles are listed: inverse verification, channel matching, and PIP protection.
Significance. If the empirical claims hold with independent verification, the work could draw attention to an under-recognized class of cross-boundary reliability issues in multi-agent systems and offer a concrete mitigation protocol. The reported trial scale is large and the perfect outcomes under CADVP are striking, but the absence of any methodological description prevents assessment of whether these results generalize or rest on sound measurement.
major comments (2)
- [Abstract (empirical results paragraph)] Abstract (empirical results paragraph): The central claim of zero failures in 30,012 trials under CADVP v1.1 versus 69-98% without supplies no description of the failure detection mechanism, logging granularity, exclusion criteria, error bars, or independent oracle used to label channel fractures. This is load-bearing because, as the stress-test note observes, if detection re-uses any of the 13 verification dimensions, channel-matching logic, or PIP checks, the baseline comparison is circular by construction.
- [Abstract (real-world validation paragraph)] Abstract (real-world validation paragraph): The 10,008-trial real-world validation reporting quality elevation from 0.90 to 1.00 likewise provides no details on the quality metric definition, how failures were independently verified, or trial conditions, preventing evaluation of whether the instances are representative of general multi-agent deployments.
minor comments (2)
- The term 'channel fracture' and the three design principles (inverse verification, channel matching, PIP protection) are introduced without formal definitions or references to related concepts in distributed systems or agent communication protocols.
- No statistical analysis, confidence intervals, or discussion of how the trial conditions ensure representativeness appears in the provided text.
Simulated Author's Rebuttal
We thank the referee for their detailed review and for highlighting the need for greater methodological transparency in the abstract. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract (empirical results paragraph)] Abstract (empirical results paragraph): The central claim of zero failures in 30,012 trials under CADVP v1.1 versus 69-98% without supplies no description of the failure detection mechanism, logging granularity, exclusion criteria, error bars, or independent oracle used to label channel fractures. This is load-bearing because, as the stress-test note observes, if detection re-uses any of the 13 verification dimensions, channel-matching logic, or PIP checks, the baseline comparison is circular by construction.
Authors: We agree that the abstract omits these details and that they are essential for assessing the claims. The detection mechanism relied on an independent transport-layer logging oracle that compared sent and received message hashes outside the CADVP dimensions; exclusions were limited to trials with documented infrastructure outages (under 0.1% of runs); outcomes were binary with no error bars computed. The comparison is not circular because the oracle operated on raw delivery records rather than the protocol's verification steps. We will add a concise methods paragraph to the abstract and a dedicated subsection in the main text describing the oracle, logging, and exclusion rules. revision: yes
-
Referee: [Abstract (real-world validation paragraph)] Abstract (real-world validation paragraph): The 10,008-trial real-world validation reporting quality elevation from 0.90 to 1.00 likewise provides no details on the quality metric definition, how failures were independently verified, or trial conditions, preventing evaluation of whether the instances are representative of general multi-agent deployments.
Authors: We concur that the abstract lacks these specifics. The quality metric is the fraction of messages delivered without loss or duplication, measured by post-hoc payload comparison against ground-truth logs. Failures were verified by an external audit process independent of CADVP. The 10,008 trials spanned 30 days in the live Hermes production environment under normal and peak loads. We will expand the abstract paragraph and insert a validation subsection in the revised manuscript to define the metric, verification method, and conditions. revision: yes
Circularity Check
No circularity: empirical trial results with no derivations or self-referential definitions
full rationale
The paper reports discovery of failure modes and presents CADVP v1.1 as a verification protocol, supported by counts of trials (30,012 and 10,008) showing failure-rate differences. No equations, derivations, fitted parameters, or self-citations appear in the provided text. The central claims rest on direct experimental counts rather than any reduction of outputs to inputs by construction, self-definition, or load-bearing self-citation. This is a standard non-finding for an empirical report without mathematical structure.
Axiom & Free-Parameter Ledger
invented entities (1)
-
channel fracture
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Silent Failure in LLM Agent Systems: The Entropy Principle and the Inevitable Disorder of Autonomous Agents
LLM agent systems accumulate disorder leading to silent failures, formalized by the exponential Entropy Principle S(t) = S0 * e^(alpha * t) with empirically measured alpha, countered by proposed PIG Engine and ADE protocols.
Reference graph
Works this paper leans on
-
[1]
nousresearch.com/docs, 2024–2026
Nous Research.Hermes Agent: Self-hosted AI Agent Framework.https://hermes-agent. nousresearch.com/docs, 2024–2026
2024
-
[2]
github.io/langgraph/, 2024
LangChain.LangGraph: Build stateful, multi-actor ap- plications with LLMs.https://langchain-ai. github.io/langgraph/, 2024
2024
-
[3]
Q. Wu, G. Pitre, W. Abueidda, et al. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversa- tion.arXiv:2308.08155, 2023
Pith/arXiv arXiv 2023
-
[4]
com/crewAIInc/crewAI, 2024
CrewAI Inc.CrewAI: Framework for orchestrating role- playing autonomous AI agents.https://github. com/crewAIInc/crewAI, 2024
2024
-
[5]
J. S. Park, J. C. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein. Generative Agents: Interactive Sim- ulacra of Human Behavior. InProc. UIST 2023, ACM, 2023
2023
-
[6]
L. Wang, C. Ma, X. Feng, et al. A Survey on Large Language Model based Autonomous Agents.Frontiers of Computer Science, 2024
2024
-
[7]
S. Hong, M. Zhuge, J. Chen, et al. MetaGPT: Meta Pro- gramming for A Multi-Agent Collaborative Framework. arXiv:2308.00352, 2023
Pith/arXiv arXiv 2023
-
[8]
Gray and L
J. Gray and L. Lamport. Consensus on Transaction Com- mit.ACM Trans. Database Systems, 31(1):133–160, 2006
2006
-
[9]
Mem0 AI.Mem0: The Memory Layer for Personalized AI.https://mem0.ai, 2024
2024
-
[10]
LangChain.LangMem: Long-term Memory for LangGraph Agents.https://github.com/ langchain-ai/langmem, 2025
2025
-
[11]
Y . Qin, S. Liang, Y . Ye, et al. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs.arXiv:2307.16789, 2023
Pith/arXiv arXiv 2023
- [12]
-
[13]
html, 2024
SQLite Development Team.SQLite Full-Text Search (FTS5).https://www.sqlite.org/fts5. html, 2024
2024
-
[14]
Error Amplification in Multi-Agent Language Model Chains.arXiv:2512.08296, 2025
DeepMind and MIT. Error Amplification in Multi-Agent Language Model Chains.arXiv:2512.08296, 2025
Pith/arXiv arXiv 2025
-
[15]
Z. Li, Y . Zhang, and R. Zhao. Concurrent Memory Ac- cess in Multi-Agent Systems: Challenges and Opportu- nities.arXiv:2501.xxxxx, 2025. A Verified System Paths All file paths referenced in this paper were verified to exist on the production system as of June 3, 2026: Path Description cron/scheduler.pyScheduler, line 1652 agent/agent init.pyAgent init, li...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.