RuleChef: Grounding LLM Task Knowledge in Human-Editable Rules
Pith reviewed 2026-07-03 21:28 UTC · model grok-4.3
The pith
RuleChef uses LLMs to create human-editable rules for NLP tasks like classification and NER from task descriptions and examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
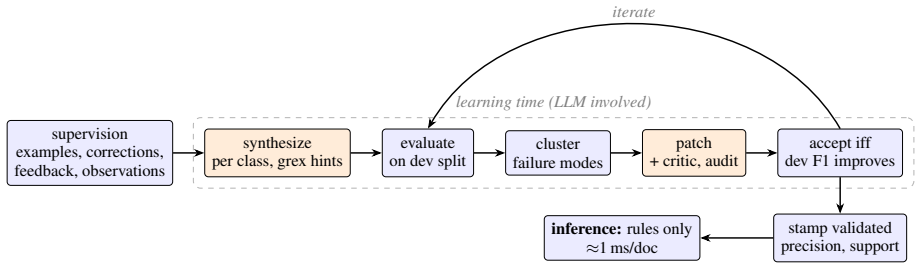
RuleChef generates executable rules for NLP tasks from a task description and labeled examples, then iteratively improves those rules using more examples and human feedback on the rules themselves; LLMs are applied only at learning time to synthesize and patch rules measured against a held-out split, yielding a fast, deterministic, and inspectable rule system that can also be bootstrapped from the input-output behavior of any existing model.
What carries the argument
RuleChef framework: applies LLMs solely during rule synthesis and patching from task descriptions, labeled examples, and human feedback to produce executable rules for downstream use.
If this is right
- Rules become available for text classification, named entity recognition, and relation extraction without keeping LLMs active at runtime.
- The resulting systems run deterministically and allow direct human inspection or editing of the rules.
- Any existing model for a task can supply initial input-output pairs to start the rule generation process.
- Iterative patching uses failures on a held-out split plus human input to refine the rules.
- The final output is released as open-source software.
Where Pith is reading between the lines
- The method could extend to tasks where rule transparency matters more than peak accuracy.
- Human edits might reduce reliance on large labeled datasets by focusing feedback on rule failures.
- Bootstrapping from existing models suggests a way to convert black-box outputs into editable logic.
- Performance on additional tasks beyond classification and NER would test how broadly the synthesis step applies.
Load-bearing premise
LLMs can produce rules from task descriptions and examples that generalize to new data and can be iteratively improved with feedback until they reach useful performance levels.
What would settle it
Run the generated rules on held-out test data for classification or NER; if accuracy stays near random or human feedback produces no measurable gains, the process fails to deliver the claimed rule system.
Figures







read the original abstract
We present RuleChef, a framework that uses large language models (LLMs) to generate executable rules for NLP tasks such as text classification, Named Entity Recognition (NER), or relation extraction. Rules are generated based on a task description and a set of labeled examples, then they are iteratively improved based both on additional examples and on human feedback overexisting rules. RuleChef can also be used to bootstrap rules using the observed input-output pairs from any existing model for a given task. LLMs are used only at learning time, synthesizing rules and iteratively patching them based on failures measured on a held-out split. The result of this process is a fast, deterministic, and inspectable rule system. Preliminary evaluation is performed on both classification and NER tasks. We release RuleChef as open-source software under an Apache 2.0
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents RuleChef, a framework that uses LLMs to generate executable rules for NLP tasks such as text classification, Named Entity Recognition (NER), or relation extraction. Rules are generated from a task description and labeled examples, then iteratively improved using additional examples and human feedback over existing rules. LLMs are used only at learning time to synthesize and patch rules based on failures on a held-out split. The framework also supports bootstrapping rules from observed input-output pairs of existing models. The result is claimed to be a fast, deterministic, and inspectable rule system. Preliminary evaluation on classification and NER tasks is mentioned, and the software is released open-source under Apache 2.0.
Significance. If the process reliably yields generalizable rules, RuleChef could offer a practical method to distill LLM task knowledge into efficient, human-editable rule systems that avoid LLM inference costs at runtime while preserving inspectability and determinism. The open-source release under Apache 2.0 is a clear strength supporting reproducibility.
major comments (2)
- [Abstract] Abstract: the claim that the process produces 'usable rule systems' rests on the assumption that synthesized rules generalize to held-out data and can be iteratively patched to useful performance, yet the abstract provides no metrics, baselines, error bars, or details on measurement and comparison for the preliminary classification and NER evaluations.
- [Framework Description] The iterative patching mechanism (described in the framework overview) is load-bearing for the central claim of producing inspectable rules, but lacks concrete pseudocode, failure-measurement criteria, or examples of how human feedback is incorporated into rule edits.
minor comments (2)
- [Abstract] The final sentence of the abstract is truncated ('under an Apache 2.0').
- [Method] Notation for rule representation and patching operations could be clarified with a small example or table early in the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the abstract and framework description as suggested.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the process produces 'usable rule systems' rests on the assumption that synthesized rules generalize to held-out data and can be iteratively patched to useful performance, yet the abstract provides no metrics, baselines, error bars, or details on measurement and comparison for the preliminary classification and NER evaluations.
Authors: We agree that the abstract should provide more concrete evidence to support the claim of usable rule systems. The current version notes only that preliminary evaluation was performed. In the revised manuscript we will expand the abstract to report key metrics (e.g., accuracy or F1 on held-out splits), the baselines compared against, and a brief description of how generalization and patching success were measured. revision: yes
-
Referee: [Framework Description] The iterative patching mechanism (described in the framework overview) is load-bearing for the central claim of producing inspectable rules, but lacks concrete pseudocode, failure-measurement criteria, or examples of how human feedback is incorporated into rule edits.
Authors: We acknowledge that the iterative patching process is central and that the overview description is high-level. We will add (1) pseudocode for the overall patching loop, (2) explicit criteria used to measure failures on the held-out split, and (3) a short example illustrating how a human comment on an existing rule is translated into an edit. These additions will be placed in the framework section. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents a framework description for synthesizing executable rules via LLMs at learning time only, with no equations, fitted parameters, predictions, or self-citations invoked as load-bearing premises. The central claim (fast/deterministic/inspectable rules) follows directly from the stated process without any reduction to quantities defined by the framework's own outputs. No patterns from the enumerated list apply.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can synthesize useful executable rules from task descriptions and labeled examples that generalize to new data
Reference graph
Works this paper leans on
-
[1]
Qiaochu Chen, Xinyu Wang, Xi Ye, Greg Durrett, and Isil Dillig
ACL. Qiaochu Chen, Xinyu Wang, Xi Ye, Greg Durrett, and Isil Dillig. 2020. Multi-modal synthesis of regular ex- pressions. InProceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), pages 487–502. ACM. Laura Chiticariu, Yunyao Li, and Frederick R. Reiss
2020
-
[2]
Rule-based information extraction is dead! long live rule-based information extraction systems! InProceedings of the 2013 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 827–832. ACL. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language unde...
-
[3]
InFindings of the 61st Annual Meet- ing of the Association for Computational Linguistics (ACL), pages 8003–8017
Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. InFindings of the 61st Annual Meet- ing of the Association for Computational Linguistics (ACL), pages 8003–8017. ACL. Ádám Kovács, Kinga Gémes, Eszter Iklódi, and Gá- bor Recski. 2022. POTATO: exPlainable infOrma- tion exTrAcTiOn framework. InPro...
2022
-
[4]
The text anonymization benchmark (TAB): A dedicated corpus and evaluation framework for text anonymization.Computational Linguistics, 48(4):1053–1101. Alexander Ratner, Stephen H. Bach, Henry Ehrenberg, Jason Fries, Sen Wu, and Christopher Ré. 2017. Snorkel: Rapid training data creation with weak su- pervision.Proceedings of the VLDB Endowment, 11(3):269–...
-
[5]
InThe Twelfth International Conference on Learning Representations (ICLR)
Hypothesis search: Inductive reasoning with language models. InThe Twelfth International Conference on Learning Representations (ICLR). ArXiv:2309.05660. Peter West, Chandra Bhagavatula, Jack Hessel, Jena D. Hwang, Liwei Jiang, Ronan Le Bras, Ximing Lu, Sean Welleck, and Yejin Choi. 2022. Symbolic knowledge distillation: from general language mod- els to ...
-
[6]
SemRegex: A semantics-based approach for generating regular expressions from natural language specifications. InProceedings of the 2018 Confer- ence on Empirical Methods in Natural Language Processing (EMNLP), pages 1608–1618. ACL. Wenxuan Zhou, Sheng Zhang, Yu Gu, Muhao Chen, and Hoifung Poon. 2024. UniversalNER: Targeted distil- lation from large langua...
-
[7]
Handles all corrections correctly (CRITICAL - these show failure modes)
-
[8]
Works on all examples
-
[9]
Respects user feedback
-
[10]
what else could this match?
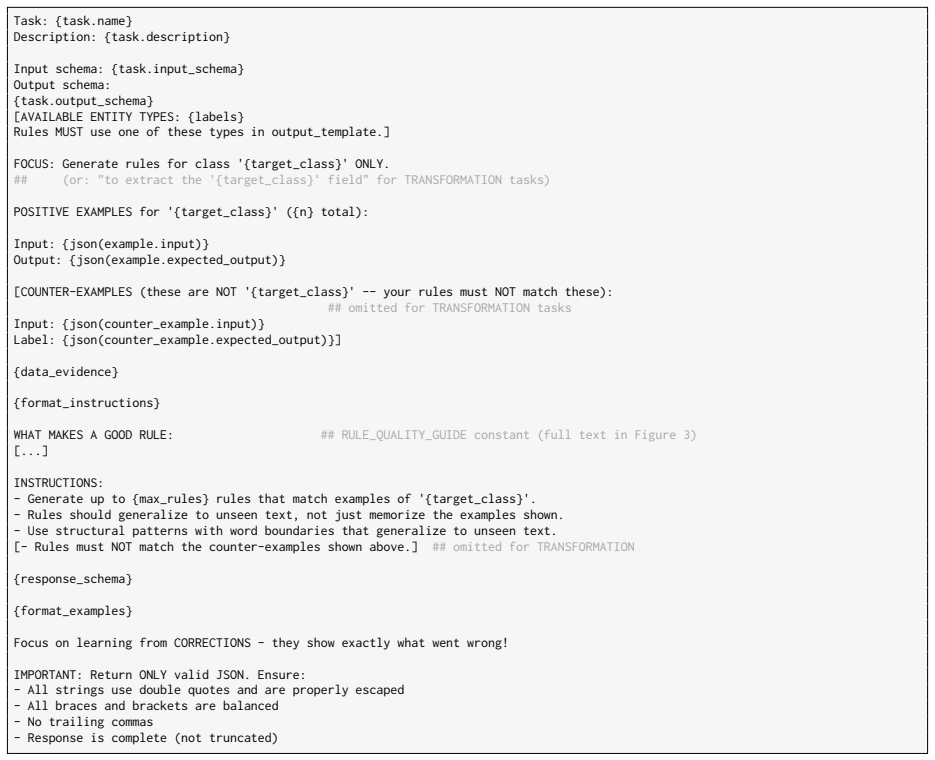
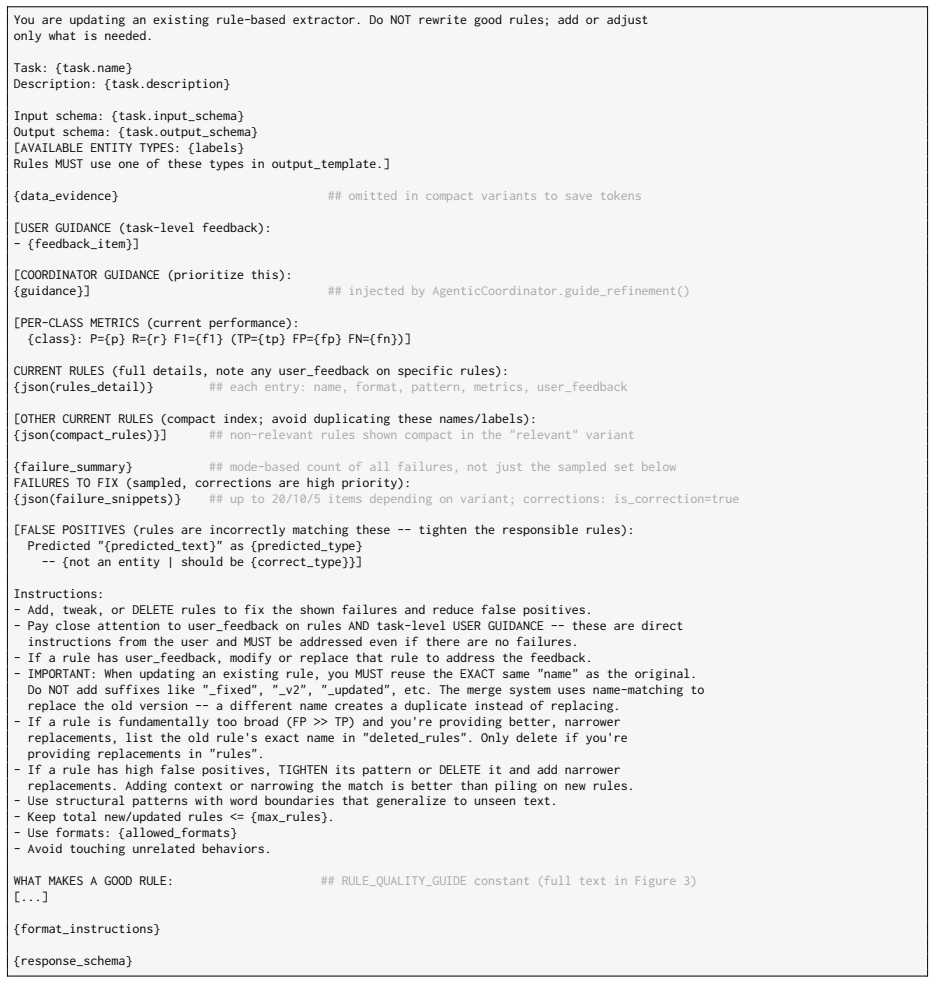
Is general and minimal (avoid redundant rules) WHAT MAKES A GOOD RULE: - PRECISION OVER RECALL: A rule that matches 10 things correctly beats one that matches 100 with 20 wrong. Never sacrifice precision for recall. Missing a match is fixable later; a wrong match poisons results. - GENERALIZE, DON'T MEMORIZE: Rules run on unseen text. Match the *structure...
-
[11]
Combine into one rule
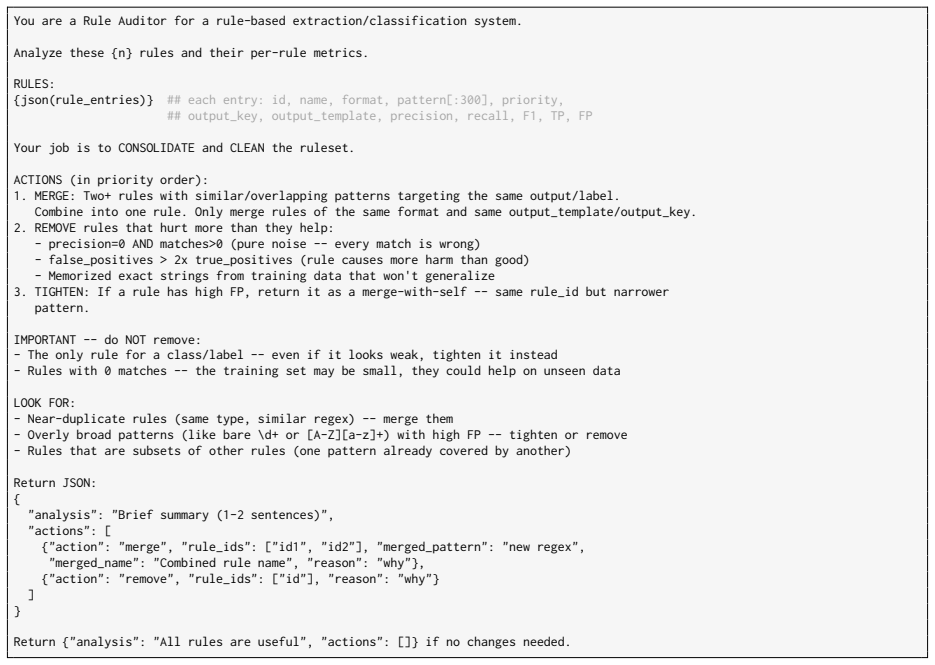
MERGE: Two+ rules with similar/overlapping patterns targeting the same output/label. Combine into one rule. Only merge rules of the same format and same output_template/output_key
-
[12]
REMOVE rules that hurt more than they help: - precision=0 AND matches>0 (pure noise -- every match is wrong) - false_positives > 2x true_positives (rule causes more harm than good) - Memorized exact strings from training data that won't generalize
-
[13]
analysis
TIGHTEN: If a rule has high FP, return it as a merge-with-self -- same rule_id but narrower pattern. IMPORTANT -- do NOT remove: - The only rule for a class/label -- even if it looks weak, tighten it instead - Rules with 0 matches -- the training set may be small, they could help on unseen data LOOK FOR: - Near-duplicate rules (same type, similar regex) -...
-
[14]
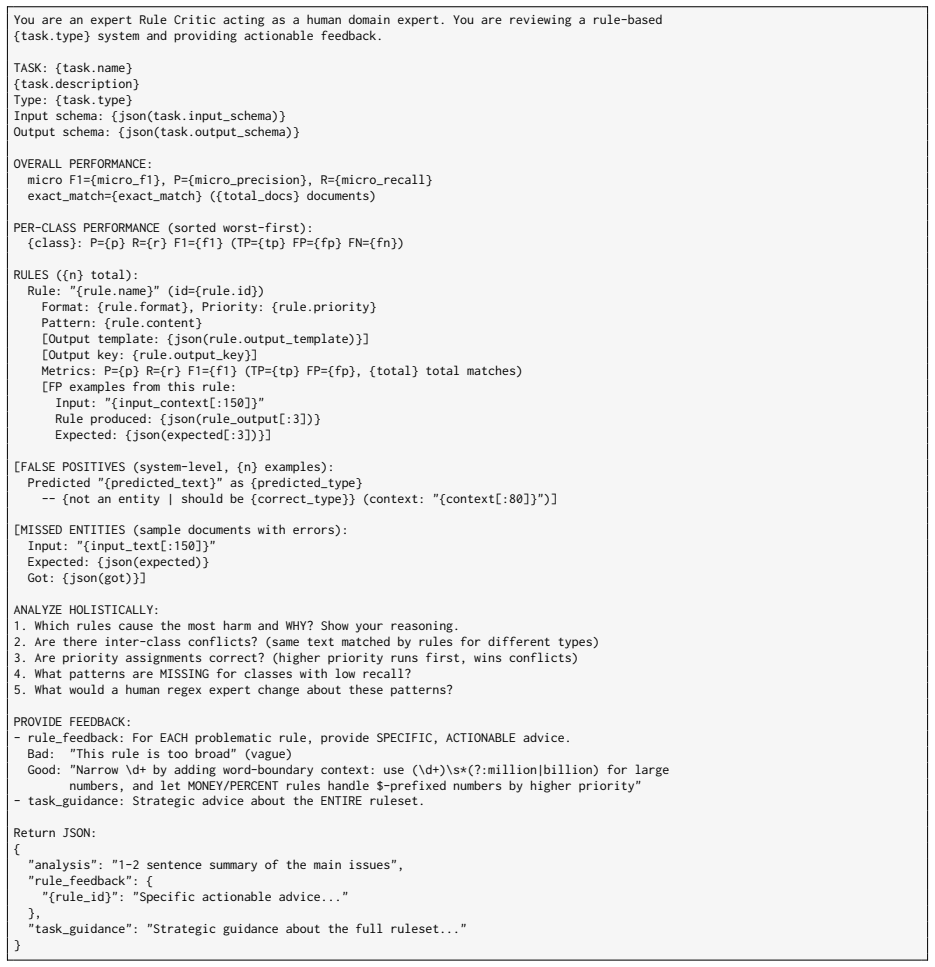
Which rules cause the most harm and WHY? Show your reasoning
-
[15]
Are there inter-class conflicts? (same text matched by rules for different types)
-
[16]
Are priority assignments correct? (higher priority runs first, wins conflicts)
-
[17]
What patterns are MISSING for classes with low recall?
-
[18]
This rule is too broad
What would a human regex expert change about these patterns? PROVIDE FEEDBACK: - rule_feedback: For EACH problematic rule, provide SPECIFIC, ACTIONABLE advice. Bad: "This rule is too broad" (vague) Good: "Narrow \d+ by adding word-boundary context: use (\d+)\s*(?:million|billion) for large numbers, and let MONEY/PERCENT rules handle $-prefixed numbers by ...
-
[19]
TRIGGER if we have corrections (users fixing mistakes)
-
[20]
TRIGGER if we have a significant batch of new examples (5+)
-
[21]
should_learn
WAIT if data looks sparse or redundant. STRATEGIES: -'balanced': Standard mix (default) -'corrections_first': If we have corrections -'diversity': If we have many similar examples -'uncertain': If examples look ambiguous Return JSON: { "should_learn": boolean, "strategy": "balanced"|"corrections_first"| "diversity"|"uncertain", "max_iterations": integer (...
-
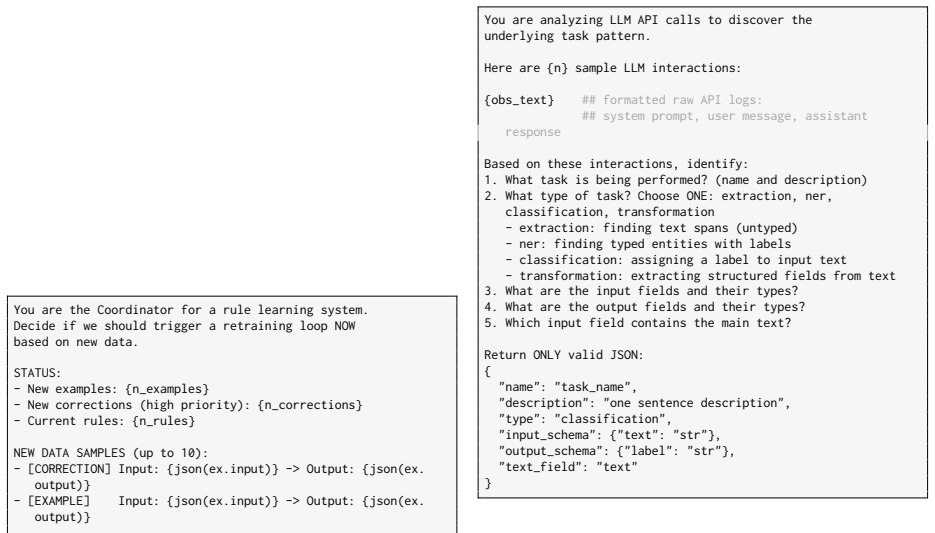
[22]
What task is being performed? (name and description)
-
[23]
What type of task? Choose ONE: extraction, ner, classification, transformation - extraction: finding text spans (untyped) - ner: finding typed entities with labels - classification: assigning a label to input text - transformation: extracting structured fields from text
-
[24]
What are the input fields and their types?
-
[25]
What are the output fields and their types?
-
[26]
name": "task_name
Which input field contains the main text? Return ONLY valid JSON: { "name": "task_name", "description": "one sentence description", "type": "classification", "input_schema": {"text": "str"}, "output_schema": {"label": "str"}, "text_field": "text" } Figure 10: Task discovery prompt. Issued once in obser- vation mode when no task schema is provided upfront....
-
[27]
Is it relevant to the task above? (relevant: true/false)
-
[28]
relevant
If relevant, extract the input (matching input_schema keys) and output (matching output_schema keys). Return ONLY a JSON array with exactly {n} objects: [ {"relevant": true, "input": {...}, "output": {...}}, {"relevant": false, "input": null, "output": null}, ... ] Figure 11: Observation mapping prompt. Issued once per batch of up to ten raw API call logs...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.