PhyloFrame: A DataFrame-based Library for Fast, Flexible Phylogenetic Computation
Pith reviewed 2026-06-29 09:25 UTC · model grok-4.3
The pith
A DataFrame with one row per node lets phylogenetic operations on very large trees match or exceed native-code library speeds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
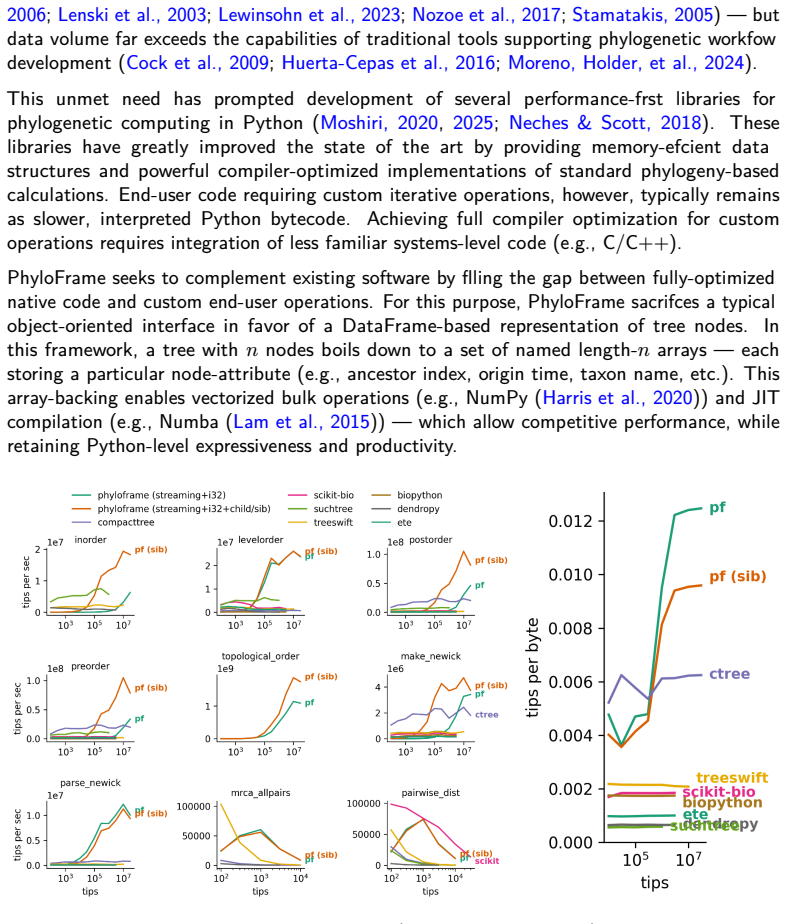
PhyloFrame stores phylogenetic trees as DataFrames in which each row corresponds to a node and columns record ancestor relationships, branch lengths, taxon labels, and user-defined attributes. The array-backed layout permits both library and end-user code to apply Just-In-Time compilation via Numba and vectorized execution via NumPy or Polars to phylogenetic operations. At large tree sizes the resulting performance generally matches or exceeds that of Python libraries backed by native code, with particular strength in topological-order traversals and Newick I/O. The representation further supplies succinct bulk operations, powerful queries and transformations, compatibility with compression-
What carries the argument
DataFrame-based tree representation with one row per node and columns for ancestor, length, label, and attribute data.
If this is right
- Bulk NumPy operations become available on tree data without custom indexing code.
- Polars expressions, Pandas indexing, and SQL-style joins can be used for taxon queries and tree transformations.
- Trees export directly to Parquet and other portable, compressed tabular formats.
- Tree data interoperates with Seaborn, Plotly, Vega-Altair, tidyverse, and Excel without format conversion.
- Library features for input-output, generation, traversals, metrics, manipulation, downsampling, and comparison all inherit the same DataFrame advantages.
Where Pith is reading between the lines
- Analysts could keep phylogenetic trees in the same DataFrame pipeline as sequence alignments or trait tables, eliminating repeated format conversions.
- Custom phylogenetic filters or summary statistics could be written in a few lines of familiar DataFrame syntax rather than specialized tree classes.
- The same storage pattern might be tested on other large tree-like structures such as gene-family trees or cell-lineage trees.
- Machine-learning models that treat tree nodes as ordinary table rows could train directly on phylogenetic features without additional embedding steps.
Load-bearing premise
Storing trees as ordinary DataFrames preserves all required tree-specific functionality while still allowing JIT and vectorized execution to deliver their full speed advantage.
What would settle it
A side-by-side timing test on a tree of 300,000 taxa that shows a topological traversal or Newick round-trip in PhyloFrame taking more than twice as long as the same task in a native-backed library.
Figures
read the original abstract
PhyloFrame is a Python library for phylogenetic computation targeting the gap between specialist, compiler-optimized operations and flexible, script-based workflows -- with emphasis on fast, memory-efficient operations for very large tree sizes (e.g., $\geq$ 300,000 taxa). PhyloFrame is built around a DataFrame-based tree representation, where each row corresponds to a node and columns record ancestor relationships, branch lengths, taxon labels, and any user-defined attributes. Crucial for scalability, such array-backed storage allows both library and end-user code alike to seamlessly harness Just-in-Time (JIT) compilation (e.g., Numba) and vectorized execution (e.g., NumPy, Polars). At large tree sizes, performance generally matches or exceeds Python libraries backed by native code -- notably, achieving strong performance in topological-order traversals and Newick I/O. DataFrame-based representation affords several additional conveniences, including: - succinct bulk operations (e.g., NumPy); - powerful queries and transformations (e.g., Polars expressions, Pandas indexing, SQL-style joins and merges); - compatibility with modern tabular data formats that are compression-friendly, type-aware, nullable, and highly portable (e.g., Parquet); and - broad interoperation with table-oriented data science tools (e.g., Seaborn, Plotly, Vega-Altair, tidyverse, Excel). Current library features include tree input/output, synthetic tree generation, taxon-based queries, tree traversals, tree metrics, tree manipulation, tree downsampling, and tree comparison. Most functionality supports both Pandas and Polars DataFrames, and is available through programmatic and CLI-based interfaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. PhyloFrame is a Python library for phylogenetic computation on large trees (≥300k taxa) that stores trees as DataFrames with rows per node and columns for ancestor relationships, branch lengths, and attributes. It claims this representation enables seamless use of Numba JIT, NumPy/Polars vectorization for operations including Newick I/O, topological traversals, tree generation, queries, metrics, manipulation, downsampling, and comparison, while providing compatibility with Pandas/Polars, Parquet, and data-science tools. The central claim is that performance at large scales generally matches or exceeds that of native-code-backed Python phylogenetic libraries.
Significance. If the performance claims hold, the library would provide a useful bridge between specialized phylogenetic algorithms and flexible, scriptable data-science workflows, allowing vectorized and JIT-accelerated operations on very large trees without custom C extensions while retaining interoperability with tabular tools.
major comments (2)
- [Abstract] Abstract: The assertion that 'at large tree sizes, performance generally matches or exceeds Python libraries backed by native code— notably, achieving strong performance in topological-order traversals and Newick I/O' is presented without any benchmarks, timing tables, datasets, error bars, hardware specifications, or direct comparisons to existing libraries. This evidence is load-bearing for the central contribution regarding the viability of the DataFrame representation.
- [Abstract] Abstract and library description: The claim that the row-per-node DataFrame plus ancestor/branch columns 'allows both library and end-user code to seamlessly harness' Numba/NumPy/Polars 'without introducing prohibitive overhead' for graph traversals is not accompanied by any analysis or measurements of indexing/sorting costs versus pointer-based native structures; this is the key assumption underlying the performance equivalence.
Simulated Author's Rebuttal
We thank the referee for the constructive comments emphasizing the need for empirical validation of the performance claims. We address each major point below and will revise the manuscript with additional benchmarks and analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'at large tree sizes, performance generally matches or exceeds Python libraries backed by native code— notably, achieving strong performance in topological-order traversals and Newick I/O' is presented without any benchmarks, timing tables, datasets, error bars, hardware specifications, or direct comparisons to existing libraries. This evidence is load-bearing for the central contribution regarding the viability of the DataFrame representation.
Authors: We agree that the performance claims in the abstract are central and require supporting evidence. The revised manuscript will include a new or expanded benchmarks section with timing tables, datasets (e.g., simulated trees from 10k to >300k taxa), error bars from repeated runs, hardware specifications, and direct comparisons to native-backed libraries such as DendroPy and ETE3. The abstract will be updated to reference these results concisely. revision: yes
-
Referee: [Abstract] Abstract and library description: The claim that the row-per-node DataFrame plus ancestor/branch columns 'allows both library and end-user code to seamlessly harness' Numba/NumPy/Polars 'without introducing prohibitive overhead' for graph traversals is not accompanied by any analysis or measurements of indexing/sorting costs versus pointer-based native structures; this is the key assumption underlying the performance equivalence.
Authors: We accept that quantifying overhead from DataFrame operations (indexing, sorting, column access) versus pointer-based structures is necessary to substantiate the claims. The revision will add a dedicated analysis subsection with microbenchmarks comparing these costs for traversals and other operations, including discussion of scale-dependent effects. Claims will be qualified if overhead proves non-negligible in some cases. revision: yes
Circularity Check
No circularity; purely descriptive library announcement with empirical benchmarks only.
full rationale
The manuscript presents PhyloFrame as a DataFrame-based Python library for phylogenetic operations, emphasizing scalability for large trees via Numba/NumPy/Polars compatibility. No derivations, equations, fitted parameters, or predictions appear; performance statements are direct empirical comparisons rather than outputs derived from inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked. The central claim (performance parity at scale) rests on implementation details and benchmarks, not on any reduction to tautology. This is a standard library paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://doi.org/10.2307/2413326 Faith, D. P. (1992). Conservation evaluation and phylogenetic diversity.Biological Conservation, 61(1), 1–10. https://doi.org/10.1016/0006-3207(92)91201-3 Foster, E. D., & Deardorf, A. (2017). Open science framework (OSF).Journal of the Medical Library Association,105(2), 203. https://doi.org/10.5195/jmla.2017.88 French, R....
-
[2]
https://doi.org/10.21105/joss.04866 Moreno, M. A., Holder, M. T., & Sukumaran, J. (2024). DendroPy 5: A mature python library for phylogenetic computing.Journal of Open Source Software,9(101), 6943. https://doi.org/10.21105/joss.06943 Moreno, M. A., Ranjan, A., Dolson, E., & Zaman, L. (2025). Testing the inference accuracy of accelerator-friendly approxim...
-
[3]
https://doi.org/10.21105/joss.01026 VanderPlas, J., Granger, B., Heer, J., Moritz, D., Wongsuphasawat, K., Satyanarayan, A., Lees, E., Timofeev, I., Welsh, B., & Sievert, S. (2018). Altair: Interactive statistical visualizations for python.Journal of Open Source Software,3(32), 1057. https://doi.org/ 10.21105/joss.01057 Vink, R., Gooier, S. de, Beedie, A....
-
[4]
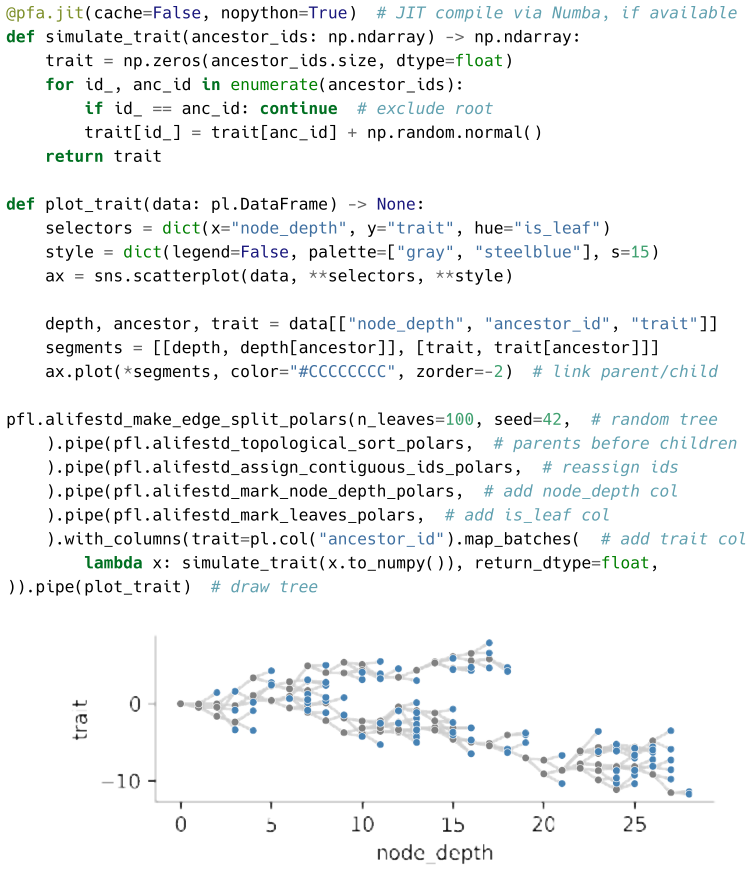
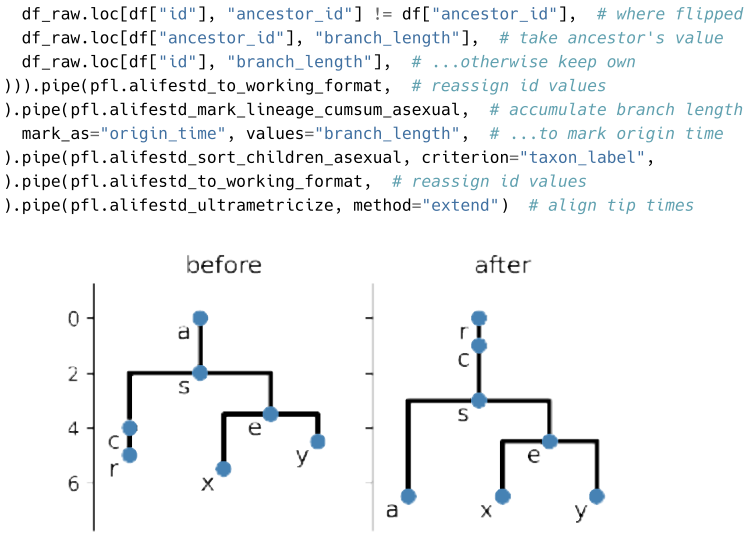
Appendix B: Tree Manipulation Pipeline Demo Example code shows sequential tree transforms applied using a pipeline pattern
and ALife data standard tooling ( Lalejini et al., 2019 ). Appendix B: Tree Manipulation Pipeline Demo Example code shows sequential tree transforms applied using a pipeline pattern. Such complex tree manipulations, including custom operations, can often be performed succinctly without loops or recursion. Moreno et al. (2026). PhyloFrame: A DataFrame-base...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.