Lung-R1: A Knowledge Graph-Guided LLM for Pulmonary Diagnostic Reasoning
Pith reviewed 2026-06-27 10:07 UTC · model grok-4.3
The pith
A knowledge graph guides LLM training to improve pulmonary diagnosis from patient records.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
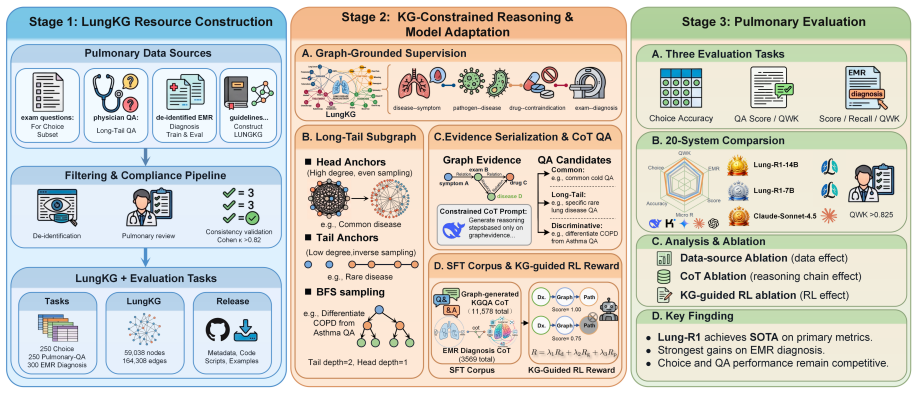
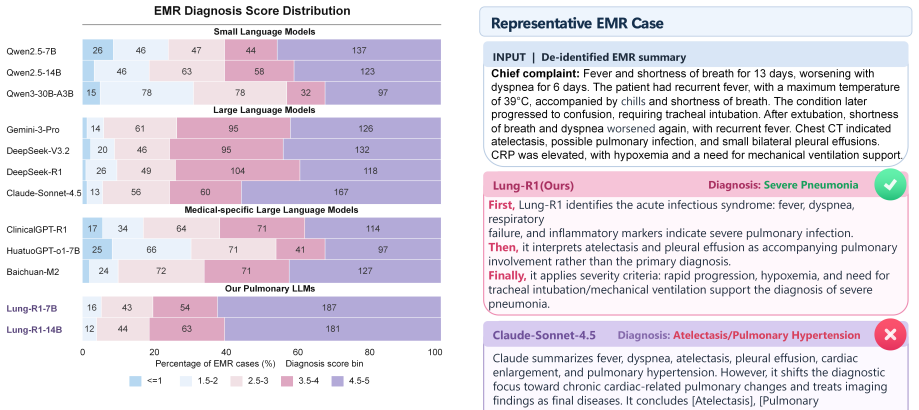
LungKG organizes pulmonary diagnostic knowledge into a graph of entities and relations; Lung-R1-14B trained via KG-constrained reasoning-chain construction and KG-guided reinforcement learning reaches an EMR Diagnosis score of 4.3583 and exceeds the strongest non-Lung-R1 baseline by 0.1476 points across evaluated tasks.
What carries the argument
LungKG, the pulmonary knowledge graph that constrains reasoning chains and guides reinforcement learning during model adaptation for EMR-based diagnosis.
If this is right
- LLMs guided by the graph outperform baselines on EMR Diagnosis by integrating heterogeneous patient evidence.
- KG-constrained training reduces reliance on isolated knowledge recall in favor of relation-aware case reasoning.
- The same LungKG resource can support future adaptation of other models for pulmonary tasks.
- Performance gains hold across Choice, Pulmonary-QA, and EMR Diagnosis benchmarks in a 20-system comparison.
Where Pith is reading between the lines
- Similar knowledge-graph construction and constrained training could be repeated for other medical specialties facing diagnostic overlap.
- Periodic updates to LungKG with new clinical findings would be needed to keep the guided model current.
- The approach may show reduced gains on rare pulmonary conditions if those relations are sparsely represented in the graph.
Load-bearing premise
The constructed LungKG accurately encodes the relations needed for reliable diagnostic reasoning and the training process yields genuine improvements in reasoning rather than task-specific fitting to the evaluation sets.
What would settle it
Evaluating Lung-R1 on a fresh collection of EMR cases drawn from an independent hospital system, with ground-truth diagnoses verified by multiple pulmonologists, and finding no performance advantage over non-guided baseline models.
Figures














read the original abstract
Diagnosing pulmonary diseases requires integrating heterogeneous evidence amid phenotypic variability and cross-disease overlap. Although large language models (LLMs) have shown progress on pulmonary knowledge question answering (QA) and information-processing tasks, reliable pulmonary diagnosis requires patient-specific, relation-aware reasoning over electronic medical record (EMR) evidence rather than isolated knowledge recall. We define this gap between pulmonary knowledge and case-level diagnostic reasoning as the Pulmonary Knowledge-to-Diagnosis Gap. To address it, we introduce LungKG, the first structured pulmonary knowledge graph for diagnostic knowledge organization and record-grounded reasoning. LungKG contains 59,038 nodes and 164,308 edges across 15 entity types and 112 relation types, serving as both a reusable pulmonary knowledge resource and the foundation for LungKG-guided model adaptation. Built on LungKG, we propose Lung-R1, a LungKG-guided pulmonary LLM trained through KG-constrained reasoning-chain construction and KG-guided reinforcement learning. In a 20-system evaluation, Lung-R1-14B achieves state-of-the-art performance across Choice, Pulmonary-QA, and EMR Diagnosis, reaching an EMR Diagnosis score of 4.3583 and surpassing the strongest non-Lung-R1 baseline by 0.1476 points. These results demonstrate the value of LungKG-guided training for EMR-based pulmonary diagnosis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LungKG, a structured pulmonary knowledge graph (59,038 nodes, 164,308 edges, 15 entity types, 112 relation types) intended as both a reusable resource and foundation for model adaptation. It proposes Lung-R1, an LLM trained via KG-constrained reasoning-chain construction and KG-guided reinforcement learning, and reports that Lung-R1-14B achieves SOTA results across Choice, Pulmonary-QA, and EMR Diagnosis tasks in a 20-system evaluation, with an EMR Diagnosis score of 4.3583 that exceeds the strongest non-Lung-R1 baseline by 0.1476 points.
Significance. If the result holds, the work would supply a domain-specific KG resource and a training recipe that demonstrably improves case-level diagnostic reasoning over EMR evidence, directly targeting the stated Pulmonary Knowledge-to-Diagnosis Gap. The modest absolute margin on the EMR task makes the contribution sensitive to verification of the KG's clinical fidelity and the training method's generalizability.
major comments (3)
- [Abstract] Abstract: The construction pipeline for LungKG (source corpora, extraction rules, entity/relation validation procedures) is not described. This information is load-bearing for the central claim that the graph encodes the clinically correct, non-redundant relations required for reliable diagnostic reasoning.
- [Abstract] Abstract: No ablation studies or controlled experiments are reported that isolate the effect of KG-constrained reasoning-chain construction and KG-guided RL from other training choices (data mixture, base model, RL hyperparameters). Without these, attribution of the 0.1476-point EMR Diagnosis improvement specifically to the proposed LungKG-guided method cannot be assessed.
- [Abstract] Abstract: The EMR Diagnosis evaluation protocol (scoring rubric and scale, selection of the 20 systems, construction of the test cases, and any overlap checks between evaluation EMRs and LungKG source material) is not specified. This gap prevents verification that the reported numeric improvement reflects genuine reasoning gains rather than evaluation-set fitting or data leakage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below, indicating where revisions will be made to improve clarity and verifiability while preserving the manuscript's core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The construction pipeline for LungKG (source corpora, extraction rules, entity/relation validation procedures) is not described. This information is load-bearing for the central claim that the graph encodes the clinically correct, non-redundant relations required for reliable diagnostic reasoning.
Authors: The full manuscript (Section 3) details the pipeline: sources include PubMed, pulmonary guidelines, and textbooks; extraction combines rule-based patterns with LLM-assisted NER/RE followed by deduplication; validation involves pulmonologist review of sampled triples (inter-rater agreement reported). We will revise the abstract to include a concise high-level description of the pipeline and add an explicit reference to Section 3 plus a summary figure for visibility. revision: yes
-
Referee: [Abstract] Abstract: No ablation studies or controlled experiments are reported that isolate the effect of KG-constrained reasoning-chain construction and KG-guided RL from other training choices (data mixture, base model, RL hyperparameters). Without these, attribution of the 0.1476-point EMR Diagnosis improvement specifically to the proposed LungKG-guided method cannot be assessed.
Authors: The manuscript provides comparative results against 20 systems but lacks explicit ablations isolating the KG components. We will add controlled ablation experiments in the revision (new subsection in Experiments), including variants with/without KG-constrained chain construction and with/without KG-guided RL, while holding other factors fixed. This will directly support attribution of the observed gains. revision: yes
-
Referee: [Abstract] Abstract: The EMR Diagnosis evaluation protocol (scoring rubric and scale, selection of the 20 systems, construction of the test cases, and any overlap checks between evaluation EMRs and LungKG source material) is not specified. This gap prevents verification that the reported numeric improvement reflects genuine reasoning gains rather than evaluation-set fitting or data leakage.
Authors: Section 4.3 of the manuscript specifies the 5-point rubric (1=incorrect diagnosis, 5=correct with complete reasoning), the 20-system selection criteria, the 200 EMR test cases drawn from held-out clinical sources, and explicit overlap/leakage checks against LungKG source material. We will expand the abstract with a brief protocol summary, move the full rubric to the main text, and add a dedicated paragraph on leakage mitigation to make these details immediately accessible. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper presents an empirical system for LLM adaptation using a constructed knowledge graph (LungKG) and reports performance gains on diagnostic tasks. The abstract and available text describe KG construction, constrained reasoning-chain building, and RL training as distinct steps leading to measured outcomes on Choice, Pulmonary-QA, and EMR Diagnosis benchmarks. No equations, self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations are present that would reduce any claimed result to its own inputs by construction. The central claims rest on external evaluation scores rather than internal redefinitions or ansatzes smuggled via prior work. This is the expected non-finding for an applied ML paper whose value is assessed by benchmark deltas rather than a closed mathematical derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pulmonary diagnostic knowledge can be usefully represented as a graph with 15 entity types and 112 relation types.
invented entities (1)
-
LungKG
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2010.16061 , year=
Evaluation: from precision, recall and F-measure to ROC, informedness, markedness and correlation , author=. arXiv preprint arXiv:2010.16061 , year=
arXiv 2010
-
[2]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[3]
, author=
Weighted kappa: Nominal scale agreement provision for scaled disagreement or partial credit. , author=. Psychological bulletin , volume=. 1968 , publisher=
1968
-
[4]
Information processing & management , volume=
A systematic analysis of performance measures for classification tasks , author=. Information processing & management , volume=. 2009 , publisher=
2009
-
[5]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[6]
Scientific data , volume=
Building a knowledge graph to enable precision medicine , author=. Scientific data , volume=. 2023 , publisher=
2023
-
[7]
Proceedings of machine learning research , volume=
Retrieving evidence from EHRs with LLMs: possibilities and challenges , author=. Proceedings of machine learning research , volume=
-
[8]
American journal of respiratory and critical care medicine , volume=
Idiopathic pulmonary fibrosis (an update) and progressive pulmonary fibrosis in adults: an official ATS/ERS/JRS/ALAT clinical practice guideline , author=. American journal of respiratory and critical care medicine , volume=. 2022 , publisher=
2022
-
[9]
Journal of Big Data , volume=
Healthcare knowledge graph construction: A systematic review of the state-of-the-art, open issues, and opportunities , author=. Journal of Big Data , volume=. 2023 , publisher=
2023
-
[10]
Scientific Reports , year=
Fine-tuned large language models with structured prompts enable efficient construction of lung cancer knowledge graphs , author=. Scientific Reports , year=
-
[11]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Automated knowledge graph construction using large language models and sentence complexity modelling , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[12]
arXiv preprint arXiv:2408.07971 , year=
Predicting lung cancer patient prognosis with large language models , author=. arXiv preprint arXiv:2408.07971 , year=
-
[13]
arXiv preprint arXiv:2512.01210 , year=
Knowledge Graph Augmented Large Language Models for Disease Prediction , author=. arXiv preprint arXiv:2512.01210 , year=
-
[14]
medRxiv , pages=
Large language models and medical knowledge grounding for diagnosis prediction , author=. medRxiv , pages=. 2023 , publisher=
2023
-
[15]
AAAI Bridge Program on AI for Medicine and Healthcare , pages=
Kg4diagnosis: A hierarchical multi-agent llm framework with knowledge graph enhancement for medical diagnosis , author=. AAAI Bridge Program on AI for Medicine and Healthcare , pages=. 2025 , organization=
2025
-
[16]
Bioinformatics , volume=
Biomedical knowledge graph-optimized prompt generation for large language models , author=. Bioinformatics , volume=. 2024 , publisher=
2024
-
[17]
2026 , month = apr, type =
2026
-
[18]
2026 , month = feb, type =
2026
-
[19]
European Respiratory Journal , volume=
Update of the international multidisciplinary classification of the interstitial pneumonias: an ERS/ATS statement , author=. European Respiratory Journal , volume=. 2025 , publisher=
2025
-
[20]
Radiology , volume=
Meta-Analysis of interobserver agreement in assessment of interstitial lung disease using high-resolution CT , author=. Radiology , volume=. 2024 , publisher=
2024
-
[21]
European Respiratory Journal , volume=
Treatable traits: a comprehensive precision medicine approach in interstitial lung disease , author=. European Respiratory Journal , volume=. 2023 , publisher=
2023
-
[22]
2020 , doi =
Lee, Jinhyuk and Yoon, Wonjin and Kim, Sungdong and Kim, Donghyeon and Kim, Sunkyu and So, Chan Ho and Kang, Jaewoo , journal =. 2020 , doi =
2020
-
[23]
2017 , publisher=
Clinical reasoning in image guided radiotherapy: a multimethod study , author=. 2017 , publisher=
2017
-
[24]
Publicly Available Clinical BERT Embeddings
Alsentzer, Emily and Murphy, John and Boag, William and Weng, Wei-Hung and Jindi, Di and Naumann, Tristan and McDermott, Matthew. Publicly Available Clinical BERT Embeddings. Proceedings of the 2nd Clinical Natural Language Processing Workshop. 2019. doi:10.18653/v1/W19-1909
-
[25]
Nature , volume=
Large language models encode clinical knowledge , author=. Nature , volume=. 2023 , publisher=
2023
-
[26]
2023 , doi =
Wu, Chaoyi and Lin, Weixiong and Zhang, Xiaoman and Zhang, Ya and Wang, Yanfeng and Xie, Weidi , journal =. 2023 , doi =
2023
-
[27]
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models
Chen, Zeming and Hern. arXiv preprint arXiv:2311.16079 , year =. doi:10.48550/arXiv.2311.16079 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2311.16079
-
[28]
Applied Sciences , volume =
What Disease Does This Patient Have? A Large-Scale Open Domain Question Answering Dataset from Medical Exams , author =. Applied Sciences , volume =. 2021 , doi =
2021
-
[29]
URLhttps://doi.org/10.18653/v1/D19-1259
Jin, Qiao and Dhingra, Bhuwan and Liu, Zhengping and Cohen, William and Lu, Xinghua. P ub M ed QA : A Dataset for Biomedical Research Question Answering. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. 2019. doi:10.18653/v1/D19-1259
-
[30]
Measuring Massive Multitask Language Understanding
Measuring Massive Multitask Language Understanding , author =. International Conference on Learning Representations , year =. doi:10.48550/arXiv.2009.03300 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2009.03300 2009
-
[31]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Cmb: A comprehensive medical benchmark in chinese , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[32]
2022 , publisher =
Pal, Ankit and Umapathi, Logesh Kumar and Sankarasubbu, Malaikannan , booktitle =. 2022 , publisher =
2022
-
[33]
Johnson, Alistair E. W. and Bulgarelli, Lucas and Shen, Lu and Gayles, Alvin and Shammout, Ayad and Horng, Steven and Pollard, Tom J. and Hao, Sicheng and Moody, Benjamin and Gow, Brian and Lehman, Li-Wei H. and Celi, Leo A. and Mark, Roger G. , journal =. 2023 , doi =
2023
-
[34]
2023 , url =
Bae, Seongsu and Kyung, Daeun and Ryu, Jaehee and Cho, Eunbyeol and Lee, Gyubok and Kweon, Sunjun and Oh, Jungwoo and Ji, Lei and Chang, Eric I-Chao and Kim, Tackeun and Choi, Edward , booktitle =. 2023 , url =
2023
-
[35]
Physiological Measurement , volume =
An Open Access Database for the Evaluation of Respiratory Sound Classification Algorithms , author =. Physiological Measurement , volume =. 2019 , doi =
2019
-
[36]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems , volume =. 2020 , url =
2020
-
[37]
Advances in Neural Information Processing Systems , volume =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[38]
, booktitle =
Zelikman, Eric and Wu, Yuhuai and Mu, Jesse and Goodman, Noah D. , booktitle =. 2022 , url =
2022
-
[39]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year =
Self-Instruct: Aligning Language Models with Self-Generated Instructions , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year =
-
[40]
From Local to Global: A Graph
Edge, Darren and Trinh, Ha and Cheng, Newman and Bradley, Joshua and Chao, Alex and Mody, Apurva and Truitt, Steven and Metropolitansky, Dasha and Ness, Robert Osazuwa and Larson, Jonathan , journal =. From Local to Global: A Graph. 2024 , doi =
2024
-
[41]
The Lancet Infectious Diseases , volume=
Global, regional, and national incidence and mortality burden of non-COVID-19 lower respiratory infections and aetiologies, 1990--2021: a systematic analysis from the Global Burden of Disease Study 2021 , author=. The Lancet Infectious Diseases , volume=. 2024 , publisher=
1990
-
[42]
Nature Medicine , volume =
Evaluation and Mitigation of the Limitations of Large Language Models in Clinical Decision-Making , author =. Nature Medicine , volume =. 2024 , doi =
2024
-
[43]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Arora, Rahul K. and Wei, Jason and Hicks, Rebecca Soskin and Bowman, Preston and Qui. 2025 , eprint =. doi:10.48550/arXiv.2505.08775 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.08775 2025
-
[44]
Nature Medicine , pages=
Holistic evaluation of large language models for medical tasks with MedHELM , author=. Nature Medicine , pages=. 2026 , publisher=
2026
-
[45]
Nature , volume =
Towards Accurate Differential Diagnosis with Large Language Models , author =. Nature , volume =. 2025 , doi =
2025
-
[46]
2025 , eprint =. doi:10.48550/arXiv.2412.15115 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2025
-
[47]
Yang, An and others , year =. doi:10.48550/arXiv.2505.09388 , url =. 2505.09388 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388
-
[48]
2025 , url =
Introducing. 2025 , url =
2025
-
[49]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
2025 , eprint =. doi:10.48550/arXiv.2501.12948 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[50]
doi:10.48550/arXiv.2504.09421 , url =
Lan, Wuyang and others , year =. doi:10.48550/arXiv.2504.09421 , url =. 2504.09421 , archivePrefix =
-
[51]
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
Chen, Junying and others , year =. doi:10.48550/arXiv.2412.18925 , url =. 2412.18925 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.18925
-
[52]
Sellergren, Andrew and Kazemzadeh, Sahar and Jaroensri, Tiam and Kiraly, Atilla and Traverse, Madeleine and Kohlberger, Timo and Xu, Shawn and Jamil, Fayaz and Hughes, Cian and Lau, Charles and others , year =. 2507.05201 , archivePrefix =
-
[53]
Baichuan-M2: Scaling Medical Capability with Large Verifier System
2025 , eprint =. doi:10.48550/arXiv.2509.02208 , url =
-
[54]
arXiv preprint arXiv:2508.10925 , year=
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.