PRO-CUA: Process-Reward Optimization for Computer Use Agents
Pith reviewed 2026-06-29 11:44 UTC · model grok-4.3
The pith
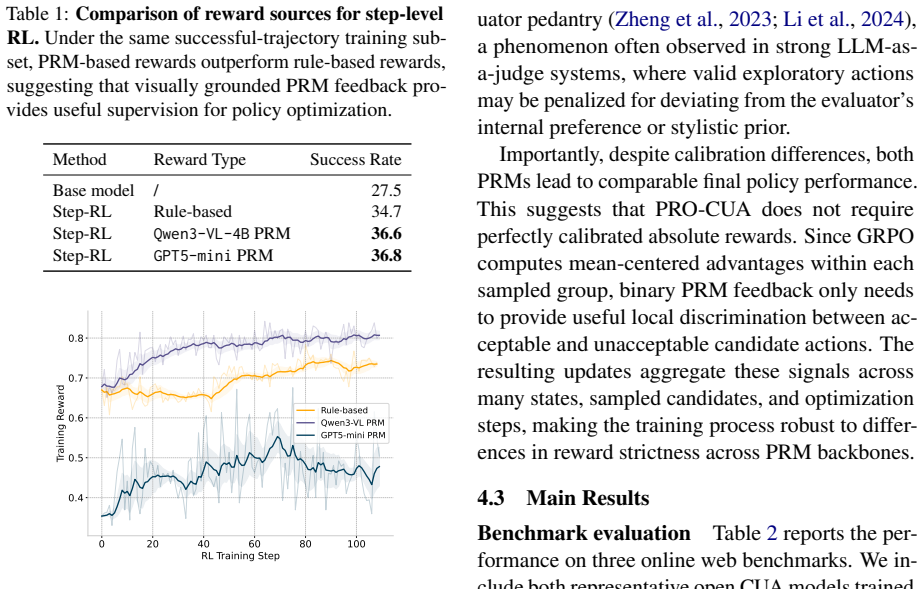
PRO-CUA enables training of computer use agents through step-level reinforcement learning using a process reward model on the agent's own live states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that decoupling on-policy environment interaction from policy optimization, combined with step-level feedback from a process reward model on diverse candidate actions, enables dense and flexible credit assignment while reducing distribution shift by training on the agent's own execution states.
What carries the argument
The process reward model (PRM) that supplies step-level quality signals for ranking actions in GUI states, used with group-relative advantages for optimization.
If this is right
- Training does not depend on golden answers or offline expert trajectories.
- Distribution shift is reduced because optimization uses the agent's own states from live rollouts.
- Credit assignment becomes dense and flexible for long-horizon tasks.
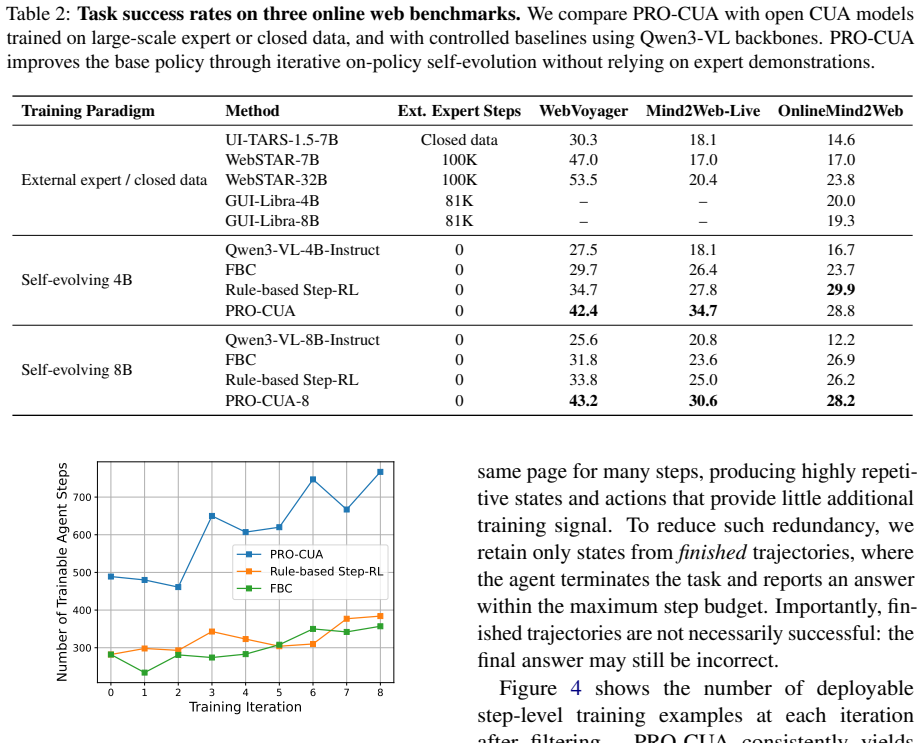
- The approach demonstrates effectiveness on live web benchmarks.
Where Pith is reading between the lines
- If the PRM generalizes well, the method could extend to other interactive agent domains like robotics or software testing.
- Reliable step-level rewards might lower the infrastructure costs associated with long-horizon interactions.
- This framework suggests a path to iterative improvement of agents without constant human supervision.
Load-bearing premise
The process reward model must supply reliable, generalizable step-level quality signals that correctly rank actions in live, previously unseen GUI states.
What would settle it
Observing that actions ranked highly by the PRM do not lead to better task completion rates than lower-ranked ones in new environments would falsify the central claim.
Figures


read the original abstract
Computer use agents (CUAs) have shown strong potential for automating complex digital workflows, yet their training remains constrained by costly live environment interaction and limited high-quality supervision. Existing filtered behavior cloning pipelines suffer from imitation bottlenecks, including distribution shift from the expert demonstration and the absence of negative learning signals. Meanwhile, standard trajectory-level reinforcement learning struggles with sparse rewards, ambiguous credit assignment, and high infrastructure costs for long-horizon GUI interaction. In this work, we propose PRO-CUA, a process-reward optimization framework for training CUAs with iterative step-level reinforcement learning. PRO-CUA decouples on-policy environment interaction from policy optimization: the current policy collects states through live rollouts, generates diverse candidate actions for each state, receives step-level feedback from a process reward model (PRM), and is optimized with group-relative advantages. This design enables dense and flexible credit assignment without relying on golden answers or offline expert trajectories, while reducing distribution shift by training on the agent's own execution states. Experiments on live web benchmarks demonstrate the effectiveness of PRO-CUA and the reliability of PRM-guided step-level training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PRO-CUA, a process-reward optimization framework for training computer use agents (CUAs). The method decouples live environment interaction from optimization: the current policy performs rollouts to collect states, generates multiple candidate actions per state, obtains step-level scores from a process reward model (PRM), and is updated via group-relative advantages. The central claims are that this yields dense, flexible credit assignment without golden answers or offline expert trajectories and reduces distribution shift by training exclusively on the agent's own execution states. Experiments on live web benchmarks are reported to confirm effectiveness and PRM reliability.
Significance. If the PRM supplies accurate, generalizable step-level rankings on previously unseen GUI states generated by the current policy, the framework would address key bottlenecks in CUA training—imitation bottlenecks, sparse rewards, and distribution shift—while lowering the cost of high-quality supervision. The on-policy, PRM-guided design with group-relative advantages is a concrete technical contribution that could be adopted more broadly if the generalization assumption holds.
major comments (2)
- [Abstract / Method] Abstract and method description: the claim that PRO-CUA trains 'without relying on golden answers or offline expert trajectories' cannot be evaluated because no information is supplied on the PRM's training data, objective, or validation set. If PRM training itself requires expert step labels or golden trajectories, the stated benefit is not realized and the distribution-shift reduction is only partial.
- [Abstract] Abstract: the assertion that the PRM supplies 'reliable' step-level feedback on live rollouts rests on an untested generalization assumption. No ablation, hold-out evaluation on policy-generated states, or comparison against expert-labeled baselines is described, making it impossible to determine whether credit assignment is actually dense and correct or merely noisy.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the clarity of our claims regarding PRM training and generalization. We address the major comments point-by-point below.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: the claim that PRO-CUA trains 'without relying on golden answers or offline expert trajectories' cannot be evaluated because no information is supplied on the PRM's training data, objective, or validation set. If PRM training itself requires expert step labels or golden trajectories, the stated benefit is not realized and the distribution-shift reduction is only partial.
Authors: The core claim in the abstract refers to the PRO-CUA optimization loop itself: the policy collects its own on-policy states, samples candidate actions, and is updated using only PRM scores via group-relative advantages, without access to golden answers or expert trajectories at optimization time. This is distinct from any offline data used to train the PRM in a separate stage. We agree that the abstract and method section lack sufficient detail on the PRM's training data, objective, and validation, which prevents full evaluation of the claim. We will revise the manuscript to add a dedicated subsection describing the PRM training procedure, data sources, and how the on-policy phase achieves the stated benefits. revision: yes
-
Referee: [Abstract] Abstract: the assertion that the PRM supplies 'reliable' step-level feedback on live rollouts rests on an untested generalization assumption. No ablation, hold-out evaluation on policy-generated states, or comparison against expert-labeled baselines is described, making it impossible to determine whether credit assignment is actually dense and correct or merely noisy.
Authors: The experiments on live web benchmarks include quantitative results demonstrating PRO-CUA effectiveness and supporting PRM reliability through end-to-end performance gains. However, we acknowledge that the manuscript does not present explicit ablations, hold-out evaluations specifically on policy-generated states, or direct comparisons against expert-labeled baselines for the PRM. We will add these analyses in the revision, including hold-out tests on states sampled from the current policy and any feasible comparisons to expert annotations. revision: yes
Circularity Check
No circularity: derivation treats PRM as external and makes no self-referential reductions
full rationale
The paper claims PRO-CUA achieves dense credit assignment and reduced distribution shift by collecting states via live rollouts from the current policy, generating candidate actions, and optimizing with group-relative advantages from PRM feedback. No equations, fitted parameters, or predictions are shown that reduce these benefits to the inputs by construction. The PRM is presented as an external component supplying step-level signals, with no description of its training that would create a self-definitional loop or fitted-input-called-prediction. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results is smuggled in. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods
Llms-as-judges: a comprehensive survey on llm-based evaluation methods.arXiv preprint arXiv:2412.05579. Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harri- son Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
InInternational Conference on Learning Representations, volume 2024, pages 39578–39601
Let’s verify step by step. InInternational Conference on Learning Representations, volume 2024, pages 39578–39601. Haojia Lin, Xiaoyu Tan, Yulei Qin, Zihan Xu, Yuchen Shi, Zongyi Li, Gang Li, Shaofei Cai, Siqi Cai, Chaoyou Fu, and 1 others. 2025. Cuareward- bench: A benchmark for evaluating reward mod- els on computer-using agent.arXiv preprint arXiv:2510...
-
[3]
InPro- ceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–
A reduction of imitation learning and struc- tured prediction to no-regret online learning. InPro- ceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–
-
[4]
JMLR Workshop and Conference Proceedings. Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and Aviral Kumar. 2025. Rewarding progress: Scaling automated process veri- fiers for llm reasoning. InInternational Conference on Learning Representations, volume 2025, pages 60808–60838. Jun...
-
[5]
Math-shepherd: Verify and reinforce llms step- by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439. Weiyun Wang, Zhangwei Gao, Lianjie Chen, Zhe Chen, Jinguo Zhu, Xiangyu Zhao, Yangzhou Liu, Yue Cao, Shenglong Ye, Xizhou Zhu, and 1 others. 202...
-
[6]
Gui-pra: Process reward agent for gui tasks
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37:52040–52094. Tao Xiong, Xavier Hu, Yurun Chen, Yuhang Liu, Changqiao Wu, Pengzhi Gao, Wei Liu, Jian Luan, and Shengyu Zhang. 2025. Gui-pra: Process reward agent for gui tasks.arXiv preprint arXiv:2509.23263. Yih...
-
[7]
Yaowei Zheng, Richong Zhang, Junhao Zhang, YeYan- han YeYanhan, and Zheyan Luo
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Yaowei Zheng, Richong Zhang, Junhao Zhang, YeYan- han YeYanhan, and Zheyan Luo. 2024. Llamafactory: Unified efficient fine-tuning of 100+ language mod- els. InProceedings of the 62nd Annual Meeting of the Association for Computationa...
2024
-
[8]
The overarching task instruction
-
[9]
The history of actions taken so far
-
[10]
The CURRENT screenshot (the state immediately BEFORE the proposed action), annotated to show the proposed target of the action
-
[11]
mental rollout
The proposed Thought and Action Code. The screenshot is an annotated visualization of the proposed action, not a raw screenshot: - Red marks, arrows, or points indicate where the proposed action is targeting. - Small index labels and overlay text are part of the annotation. - Use these annotations to judge whether the proposed action is correctly grounded...
-
[12]
[Current State Assessment]: What is currently visible on the screen? What is the immediate blocker to completing the task?
-
[13]
[Target Verification]: Does the proposed code correctly and accurately target the intended UI element in the screenshot?
-
[14]
A dropdown menu will appear,
[Mental Rollout]: If this exact code is executed, what will happen? (e.g., "A dropdown menu will appear," "The page will scroll down," "The text ’shoes’ will be typed")
-
[15]
[Task Alignment]: Does this predicted outcome meaningfully and efficiently advance the task? Or is it a redundant/wasteful action given the history?
-
[16]
‘json "is_correct
[Final Verdict]: Conclude whether the step is Correct or Incorrect. </analysis_process> “‘json "is_correct": boolean, "reflection": "A 1-2 sentence summary of why the action was marked correct or incorrect." """ 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.