Can Broad Biomedical Knowledge be Contextualized into Scenario-Grounded Propositions?
Pith reviewed 2026-06-29 17:31 UTC · model grok-4.3
The pith
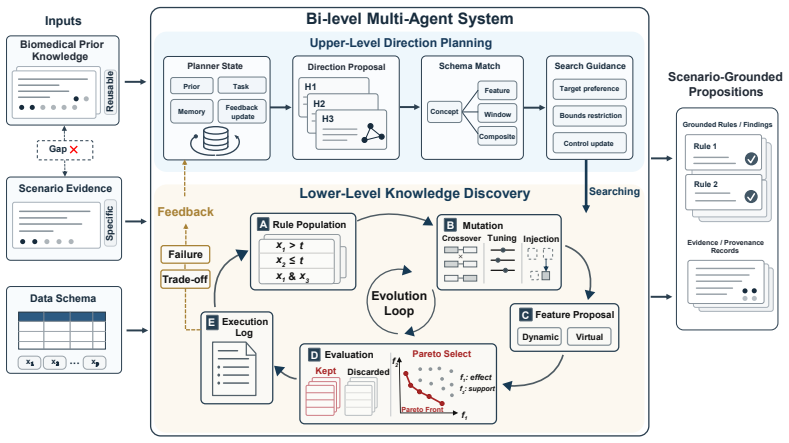
SCENE is a bi-level multi-agent framework that converts broad biomedical knowledge into evidence-supported, scenario-grounded propositions through iterative search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
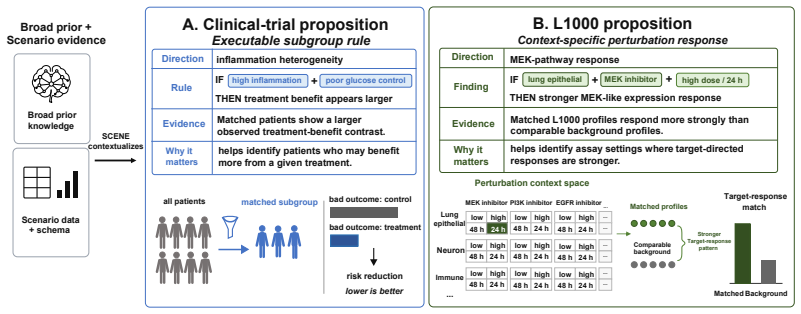
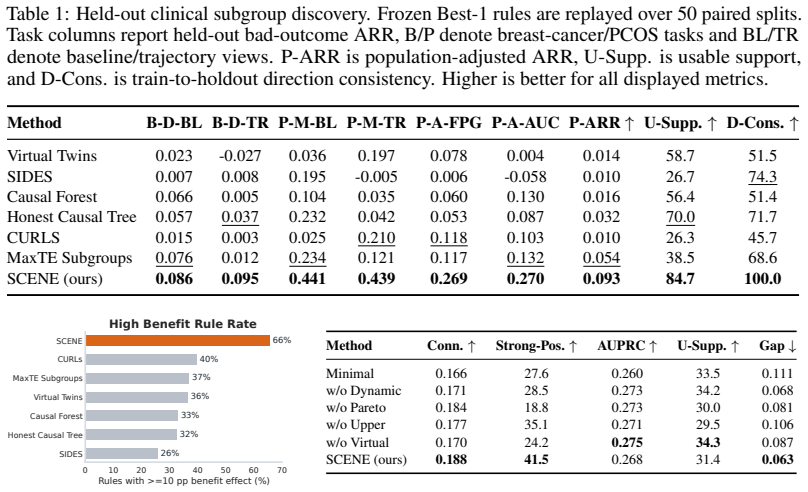
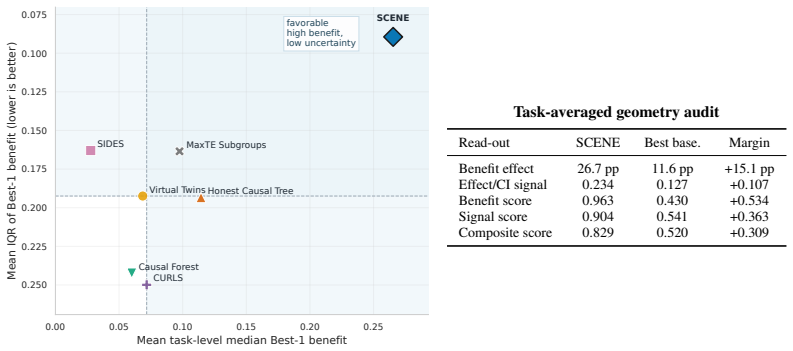
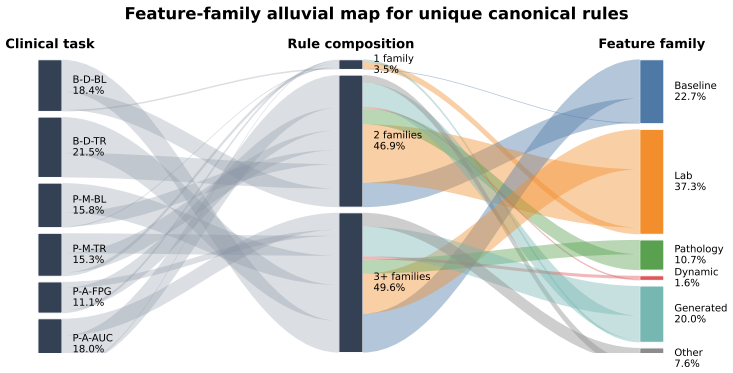
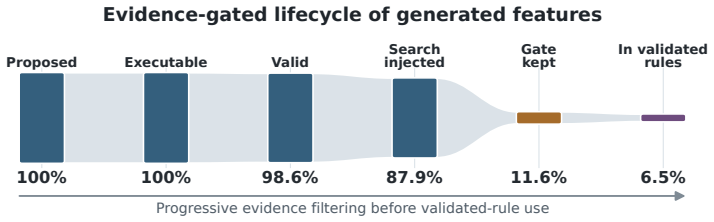
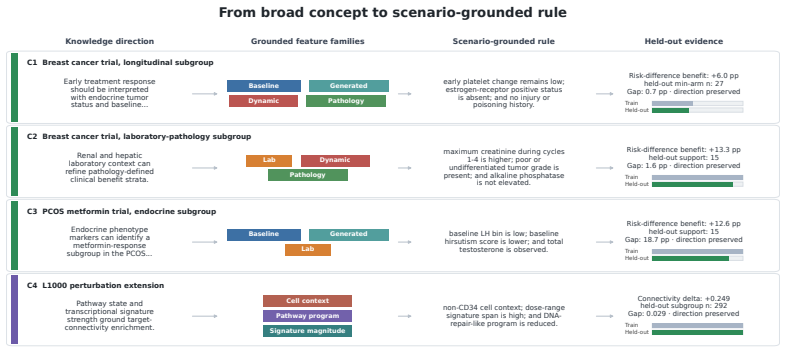
SCENE treats knowledge contextualization as iterative search. The upper level converts broad knowledge into search directions and grounds them in the dataset schema. The lower level executes these directions through multi-objective optimization to identify concrete propositions that balance evidential strength and data support. Feedback between the two levels progressively refines the search. In clinical trials SCENE discovers specific, well-supported subgroups and outperforms baselines; in L1000 studies it identifies perturbational contexts with strong target-response matching and high positive rates.
What carries the argument
SCENE, the bi-level multi-agent framework that performs iterative search with an upper-level search-direction generator and a lower-level multi-objective optimizer connected by feedback.
If this is right
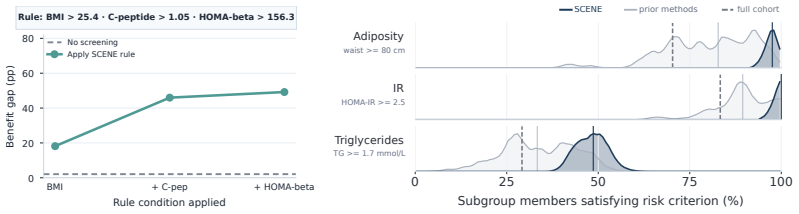
- In clinical-trial scenarios SCENE produces specific, well-supported patient subgroups with heterogeneous treatment benefits.
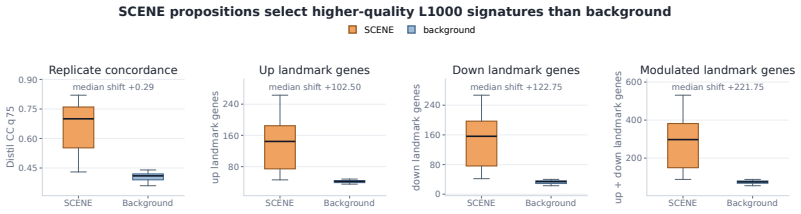
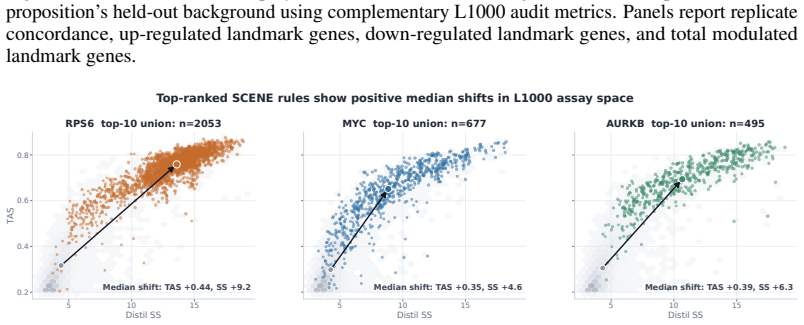
- In LINCS L1000 studies SCENE identifies perturbational contexts that exhibit strong target-response matching and high positive rates.
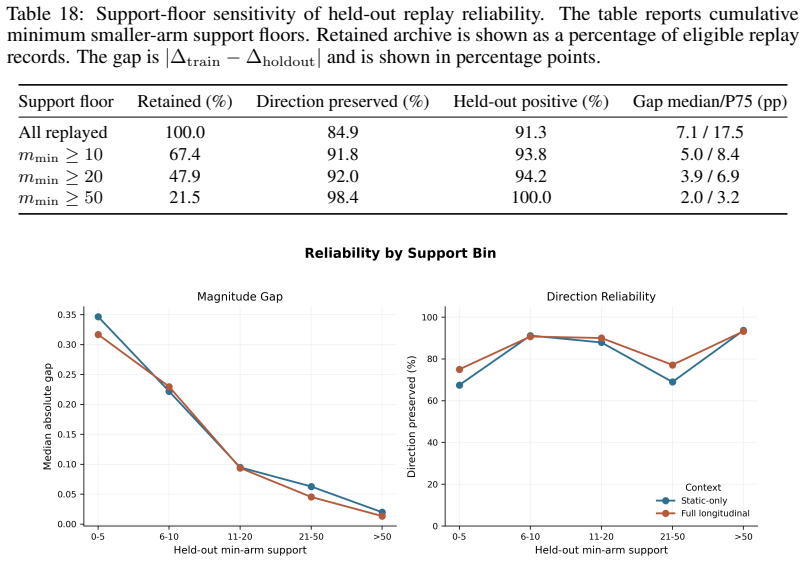
- The framework yields traceable, inspectable hypotheses that domain experts can replay and validate.
- SCENE outperforms existing baselines on both the clinical-trial and L1000 evaluation tasks.
Where Pith is reading between the lines
- The same bi-level search structure could be tested on additional biomedical resources such as electronic health records or single-cell atlases.
- If the feedback loop scales computationally, the method might reduce the manual effort required to generate mechanistic hypotheses from large omics datasets.
- Similar separation of search-direction generation from multi-objective grounding could be examined in non-biomedical domains where general knowledge must be mapped onto specific tabular data.
Load-bearing premise
Iterative feedback between the upper-level search-direction generator and the lower-level multi-objective optimizer can progressively refine outputs to achieve a useful balance between evidential strength and data support.
What would settle it
If SCENE is run on an independent clinical-trial dataset and the discovered subgroups fail to show statistically significant heterogeneous treatment benefits upon validation in a separate cohort, the central claim is falsified.
Figures

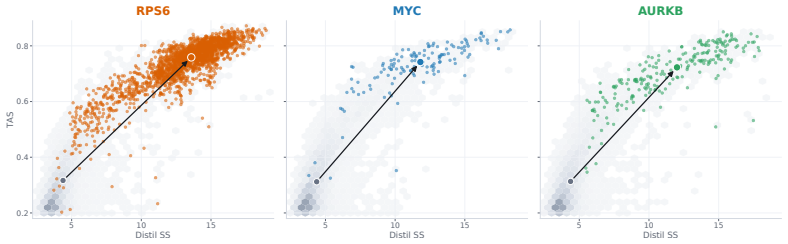
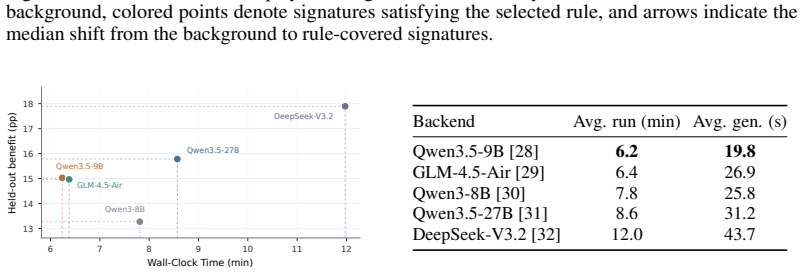
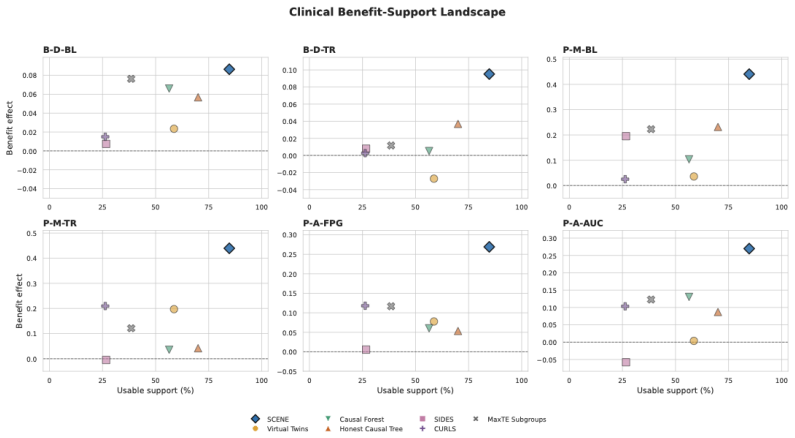
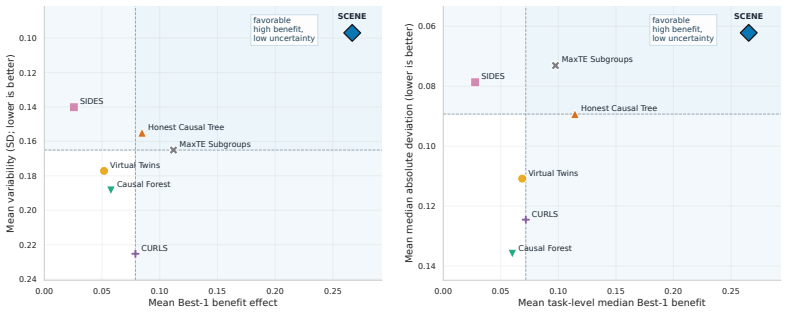


read the original abstract
Biomedical discovery often requires connecting broad biomedical knowledge with specific experimental or clinical data. Background knowledge suggests relevant mechanisms but is usually too general to map directly onto dataset variables, while data-driven patterns can be dataset-specific and hard to interpret mechanistically. We study this missing link as knowledge contextualization: transforming broad biomedical knowledge into evidence-supported, scenario-grounded propositions that domain experts can inspect, replay, and validate. We propose SCENE, a bi-level multi-agent framework that treats knowledge contextualization as iterative search. The upper level converts broad knowledge into search directions and grounds them in the dataset schema. The lower level executes these directions through multi-objective optimization to identify concrete propositions that balance evidential strength and data support. Feedback between the two levels progressively refines the search. We evaluate SCENE in two settings: discovering patient subgroups with heterogeneous treatment benefits in clinical trial scenarios, and identifying context-specific biological responses in LINCS L1000 studies. In clinical trials, SCENE discovers specific, well-supported subgroups and outperforms existing baselines. In L1000 studies, SCENE identifies perturbational contexts with strong target-response matching and high positive rates. These results show that SCENE bridges broad knowledge and scenario-specific evidence, producing traceable, inspectable hypotheses for follow-up validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SCENE, a bi-level multi-agent framework for contextualizing broad biomedical knowledge into scenario-grounded propositions. An upper level generates search directions from general knowledge and grounds them in the dataset schema; a lower level performs multi-objective optimization to produce concrete propositions balancing evidential strength and data support. Iterative feedback between levels refines the search. The framework is evaluated on discovering patient subgroups with heterogeneous treatment effects in clinical trials and identifying context-specific responses in LINCS L1000 data, where it is reported to outperform baselines and yield traceable, inspectable hypotheses.
Significance. If the reported empirical results hold under rigorous evaluation, SCENE would offer a practical mechanism for bridging general biomedical knowledge with dataset-specific evidence, enabling the generation of hypotheses that are both mechanistically grounded and directly testable against data. This could support more transparent and reproducible discovery workflows in areas such as precision medicine and pharmacogenomics.
major comments (1)
- [Abstract] Abstract: the claim that SCENE 'outperforms existing baselines' in the clinical-trial and L1000 settings is presented without any description of the baselines, metrics, statistical tests, data splits, or exclusion criteria. Because these details are load-bearing for the central empirical claim, the strength of the reported outperformance cannot be assessed from the manuscript as written.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the abstract regarding our empirical claims. We address the comment below and will revise the manuscript to improve clarity and assessability of the results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that SCENE 'outperforms existing baselines' in the clinical-trial and L1000 settings is presented without any description of the baselines, metrics, statistical tests, data splits, or exclusion criteria. Because these details are load-bearing for the central empirical claim, the strength of the reported outperformance cannot be assessed from the manuscript as written.
Authors: We agree that the abstract is insufficiently detailed on these points. In the revised version we will expand the abstract to include: (1) a concise description of the baselines (random search, knowledge-only, and data-driven ablations); (2) the primary evaluation metrics (subgroup treatment-effect heterogeneity and positive-response rate); (3) mention of the statistical tests (e.g., permutation or bootstrap tests for significance); and (4) a brief note on data splits and exclusion criteria used in both the clinical-trial and LINCS L1000 experiments. These additions will make the outperformance claims directly evaluable from the abstract while remaining within length constraints. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical bi-level multi-agent framework (SCENE) for contextualizing biomedical knowledge into scenario-grounded propositions, with no equations, parameter fits, or formal derivations present in the abstract or described evaluations. Claims of outperformance rest on reported results from subgroup discovery in clinical trials and context identification in L1000 studies, measured against external baselines rather than by construction from the framework's own outputs. No self-citations, uniqueness theorems, or ansatzes are invoked to justify load-bearing steps; the iterative feedback is presented as a practical mechanism whose utility is assessed empirically. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zarin, Tony Tse, Rebecca J
Deborah A. Zarin, Tony Tse, Rebecca J. Williams, Robert M. Califf, and Nicholas C. Ide. The ClinicalTrials.gov results database–update and key issues.The New England Journal of Medicine, 364(9):852–860, 2011
2011
-
[2]
Crawford, David Peck, Joshua W
Justin Lamb, Emily D. Crawford, David Peck, Joshua W. Modell, Irene C. Blat, Matthew J. Wrobel, Jim Lerner, Jean-Philippe Brunet, Aravind Subramanian, Kenneth N. Ross, Michael Reich, Haley Hieronymus, Guo Wei, Scott A. Armstrong, Stephen J. Haggarty, Paul A. Clemons, Ru Wei, Steven A. Carr, Eric S. Lander, and Todd R. Golub. The connectivity map: Using ge...
1929
-
[3]
Corsello, David D
Aravind Subramanian, Rajiv Narayan, Steven M. Corsello, David D. Peck, Ted E. Natoli, Xiaodong Lu, Joshua Gould, John F. Davis, Andrew A. Tubelli, Jacob K. Asiedu, David L. Lahr, Jodi E. Hirschman, Zihan Liu, Melanie Donahue, Bina Julian, Mariya Khan, David Wadden, Ian C. Smith, Daniel Lam, Arthur Liberzon, Courtney Toder, Mukta Bagul, Marek Orzechowski, ...
2017
-
[4]
FEDMEKI: A benchmark for scaling medical foundation models via federated knowledge injection
Jiaqi Wang, Xiaochen Wang, Lingjuan Lyu, Jinghui Chen, and Fenglong Ma. FEDMEKI: A benchmark for scaling medical foundation models via federated knowledge injection. In Proceedings of the Conference on Neural Information Processing Systems, 2024. Datasets and Benchmarks Track
2024
-
[5]
HypKG: Hypergraph-based knowledge graph contextualization for precision healthcare
Yuzhang Xie, Xu Han, Ran Xu, Xiao Hu, Jiaying Lu, and Carl Yang. HypKG: Hypergraph-based knowledge graph contextualization for precision healthcare. InProceedings of the International Semantic Web Conference, 2025
2025
-
[6]
Foster, Jeremy M
Jared C. Foster, Jeremy M. G. Taylor, and Stephen J. Ruberg. Subgroup identification from randomized clinical trial data.Statistics in Medicine, 30(24):2867–2880, 2011
2011
-
[7]
Ilya Lipkovich, Alex Dmitrienko, Jonathan Denne, and Gregory Enas. Subgroup identification based on differential effect search—a recursive partitioning method for establishing response to treatment in patient subpopulations.Statistics in Medicine, 30(21):2601–2621, 2011
2011
-
[8]
Recursive partitioning for heterogeneous causal effects
Susan Athey and Guido Imbens. Recursive partitioning for heterogeneous causal effects. Proceedings of the National Academy of Sciences, 113(27):7353–7360, 2016
2016
-
[9]
Generalized random forests.The Annals of Statistics, 47(2):1148–1178, 2019
Susan Athey, Julie Tibshirani, and Stefan Wager. Generalized random forests.The Annals of Statistics, 47(2):1148–1178, 2019
2019
-
[10]
CURLS: Causal rule learning for subgroups with significant treatment effect
Jiehui Zhou, Linxiao Yang, Xingyu Liu, Xinyue Gu, Liang Sun, and Wei Chen. CURLS: Causal rule learning for subgroups with significant treatment effect. InProceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 4619–4630, 2024
2024
-
[11]
Learning subgroups with maximum treatment effects without causal heuristics
Lincen Yang, Zhong Li, Matthijs van Leeuwen, and Saber Salehkaleybar. Learning subgroups with maximum treatment effects without causal heuristics. InProceedings of the AAAI Confer- ence on Artificial Intelligence, volume 40, pages 27565–27573, 2026
2026
-
[12]
Building a knowledge graph to enable precision medicine.Scientific Data, 10(1):67, 2023
Payal Chandak, Kexin Huang, and Marinka Zitnik. Building a knowledge graph to enable precision medicine.Scientific Data, 10(1):67, 2023
2023
-
[13]
The PROV data model and abstract syntax notation
Luc Moreau, Paolo Missier, Khalid Belhajjame, Reza B’Far, James Cheney, Sam Coppens, Stephen Cresswell, Yolanda Gil, Paul Groth, Graham Klyne, Timothy Lebo, James McCusker, Simon Miles, Jim Myers, Satya Sahoo, and Curt Tilmes. The PROV data model and abstract syntax notation. W3C recommendation, World Wide Web Consortium (W3C), 2013. 10
2013
-
[14]
Modern approaches for evaluating treatment effect heterogeneity from clinical trials and observational data.Statistics in Medicine, 43(22):4388–4436, 2024
Ilya Lipkovich, David Svensson, Bohdana Ratitch, and Alex Dmitrienko. Modern approaches for evaluating treatment effect heterogeneity from clinical trials and observational data.Statistics in Medicine, 43(22):4388–4436, 2024
2024
-
[15]
MetaGPT: Meta programming for a multi- agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. MetaGPT: Meta programming for a multi- agent collaborative framework. InProceedings of the International Conference on Learning Representati...
2024
-
[16]
White, Doug Burger, and Chi Wang
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversations. InProceedings of the Conference on Language Modeling, 2024
2024
-
[17]
AFlow: Automating agentic workflow generation
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, and Chenglin Wu. AFlow: Automating agentic workflow generation. InProceedings of the International Conference on Learning Representations, 2025
2025
-
[18]
Meyarivan
Kalyanmoy Deb, Amrit Pratap, Sameer Agarwal, and T. Meyarivan. A fast and elitist mul- tiobjective genetic algorithm: NSGA-II.IEEE Transactions on Evolutionary Computation, 6(2):182–197, 2002
2002
-
[19]
Project Data Sphere: Data access
Project Data Sphere. Project Data Sphere: Data access. https://data.projectdatasphe re.org/projectdatasphere/html/access. Accessed 2026-05-05
2026
-
[20]
Green, Katherine E
Angela K. Green, Katherine E. Reeder-Hayes, Robert W. Corty, Ethan Basch, Matthew I. Milowsky, Stacie B. Dusetzina, Antonia V . Bennett, and William A. Wood. The project data sphere initiative: Accelerating cancer research by sharing data.The Oncologist, 20(5):464–e20, 2015
2015
-
[21]
Qidan Wen, Min Hu, Maohua Lai, Juan Li, Zhenxing Hu, Kewei Quan, Jia Liu, Hua Liu, Yanbing Meng, Suling Wang, Xiaohui Wen, Chuyi Yu, Shuna Li, Shiya Huang, Yanhua Zheng, Han Lin, Xingyan Liang, Lingjing Lu, Zhefen Mai, Chunren Zhang, Taixiang Wu, Ernest H. Y . Ng, Elisabet Stener-Victorin, and Hongxia Ma. Data: Effect of acupuncture and metformin on insul...
2021
-
[22]
Qidan Wen, Min Hu, Maohua Lai, Juan Li, Zhenxing Hu, Kewei Quan, Jia Liu, Hua Liu, Yanbing Meng, Suling Wang, Xiaohui Wen, Chuyi Yu, Shuna Li, Shiya Huang, Yanhua Zheng, Han Lin, Xingyan Liang, Lingjing Lu, Zhefen Mai, Chunren Zhang, Taixiang Wu, Ernest H. Y . Ng, Elisabet Stener-Victorin, and Hongxia Ma. Effect of acupuncture and metformin on insulin sen...
2022
-
[23]
Keenan, Sherry L
Alexandra B. Keenan, Sherry L. Jenkins, Kathleen M. Jagodnik, Simon Koplev, Edward He, Denis Torre, Zichen Wang, Anders B. Dohlman, Moshe C. Silverstein, Alexander Lachmann, Maxim V . Kuleshov, Avi Ma’ayan, Vasileios Stathias, Raymond Terryn, Daniel Cooper, Michele Forlin, Amar Koleti, Dusica Vidovic, Caty Chung, Stephan C. Schürer, et al. The library of ...
2018
-
[24]
Cooper, John P
Amar Koleti, Raymond Terryn, Vasileios Stathias, Caty Chung, Daniel J. Cooper, John P. Turner, Dusica Vidovic, Michele Forlin, Tanya T. Kelley, Alessandro D’Urso, et al. Data portal for the library of integrated network-based cellular signatures (LINCS) program: Integrated access to diverse large-scale cellular perturbation response data.Nucleic Acids Res...
2018
-
[25]
The relationship between precision-recall and ROC curves
Jesse Davis and Mark Goadrich. The relationship between precision-recall and ROC curves. In Proceedings of the International Conference on Machine Learning, pages 233–240, 2006. 11
2006
-
[26]
The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets.PLOS ONE, 10(3):e0118432, 2015
Takaya Saito and Marc Rehmsmeier. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets.PLOS ONE, 10(3):e0118432, 2015
2015
-
[27]
A systematic analysis of performance measures for classification tasks.Information Processing & Management, 45(4):427–437, 2009
Marina Sokolova and Guy Lapalme. A systematic analysis of performance measures for classification tasks.Information Processing & Management, 45(4):427–437, 2009
2009
-
[28]
Qwen/Qwen3.5-9B model card
Qwen Team. Qwen/Qwen3.5-9B model card. https://huggingface.co/Qwen/Qwen3.5-9 B, 2026. Accessed 2026-05-07
2026
-
[29]
GLM-4.5-Air model card
Z.AI. GLM-4.5-Air model card. https://huggingface.co/zai-org/GLM-4.5-Air ,
-
[30]
Qwen3: Think deeper, act faster
Qwen Team. Qwen3: Think deeper, act faster. https://qwenlm.github.io/blog/qwen3/,
-
[31]
Qwen/Qwen3.5-27B model card
Qwen Team. Qwen/Qwen3.5-27B model card. https://huggingface.co/Qwen/Qwen3. 5-27B, 2026. Accessed 2026-05-07
2026
-
[32]
DeepSeek-V3.2 release
DeepSeek-AI. DeepSeek-V3.2 release. https://api-docs.deepseek.com/news/news25 1201, 2025. Accessed 2026-05-07
2025
-
[33]
ClinicalTrials.gov record for NCT00174655
ClinicalTrials.gov. ClinicalTrials.gov record for NCT00174655. https://clinicaltria ls.gov/study/NCT00174655, 2011. ClinicalTrials.gov identifier NCT00174655; accessed 2026-04-28
2011
-
[34]
ClinicalTrials.gov record for NCT02491333
ClinicalTrials.gov. ClinicalTrials.gov record for NCT02491333. https://clinicaltria ls.gov/study/NCT02491333, 2022. ClinicalTrials.gov identifier NCT02491333; accessed 2026-04-28
2022
-
[35]
Rothwell
Peter M. Rothwell. Subgroup analysis in randomised controlled trials: Importance, indications, and interpretation.The Lancet, 365(9454):176–186, 2005
2005
-
[36]
Kent, Jessica K
David M. Kent, Jessica K. Paulus, David van Klaveren, Ralph D’Agostino, Steven Goodman, Rodney Hayward, John P. A. Ioannidis, Bray Patrick-Lake, Sally Morton, Michael Pencina, Gowri Raman, Joseph S. Ross, Harry P. Selker, Ravi Varadhan, Andrew Vickers, John B. Wong, and Ewout W. Steyerberg. The predictive approaches to treatment effect heterogeneity (PATH...
2020
-
[37]
Mesirov, and Pablo Tamayo
Arthur Liberzon, Chet Birger, Helga Thorvaldsdóttir, Mahmoud Ghandi, Jill P. Mesirov, and Pablo Tamayo. The molecular signatures database hallmark gene set collection.Cell Systems, 1(6):417–425, 2015
2015
-
[38]
Qwen3.5: Towards native multimodal agents
Qwen Team. Qwen3.5: Towards native multimodal agents. https://qwen.ai/blog?id=qw en3.5, 2026. Accessed 2026-05-03
2026
-
[39]
An introduction to ROC analysis.Pattern Recognition Letters, 27(8):861–874, 2006
Tom Fawcett. An introduction to ROC analysis.Pattern Recognition Letters, 27(8):861–874, 2006
2006
-
[40]
scenario_context
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
1901
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.