Certified Robustness from Approximate Gaussian Mixture Structures in Pretrained Latent Spaces
Pith reviewed 2026-06-29 22:43 UTC · model grok-4.3
The pith
If a pretrained encoder's latent distribution is ε-close in KL divergence to a Gaussian mixture, certified accuracy degrades gracefully via an explicit bound.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
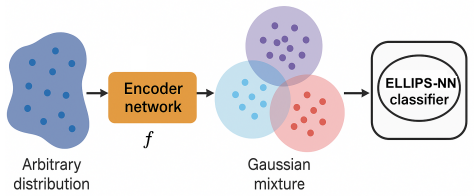
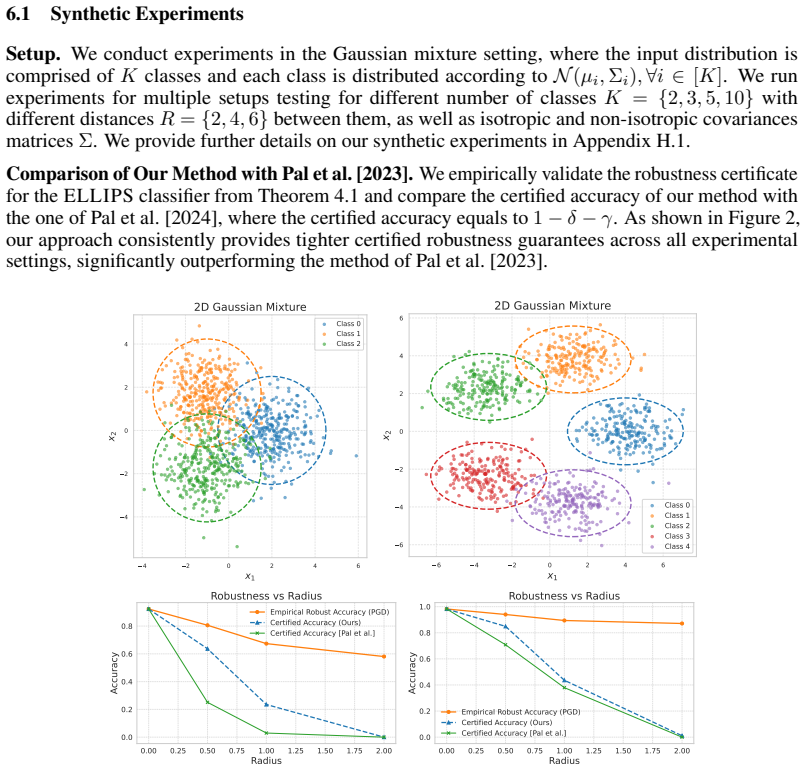
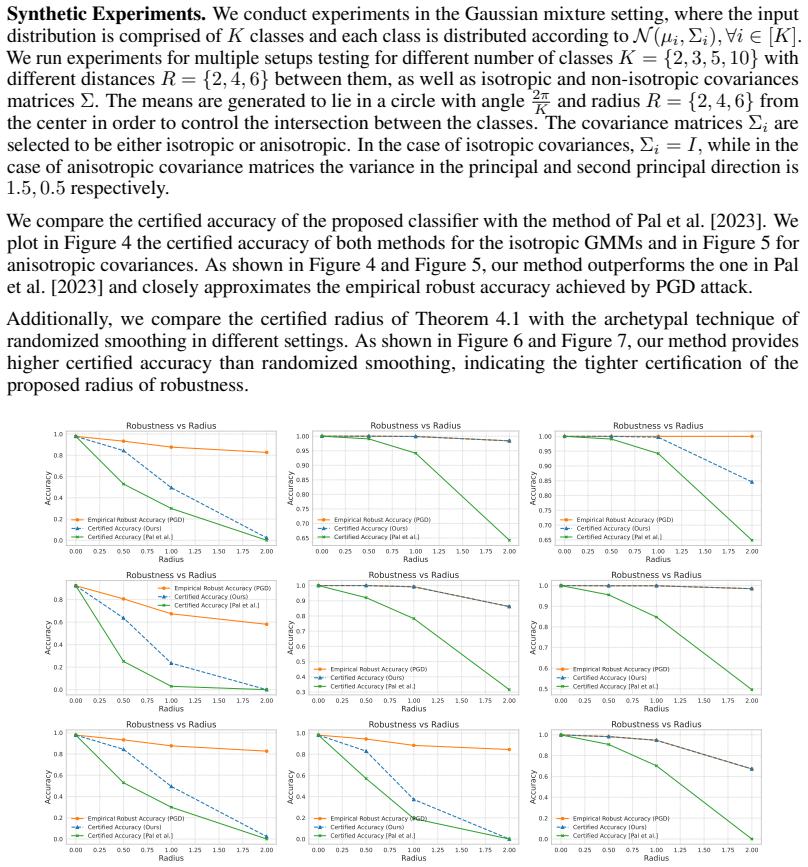
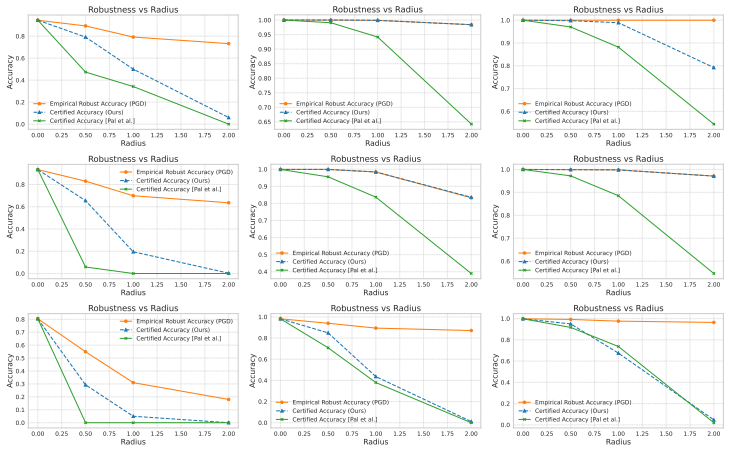
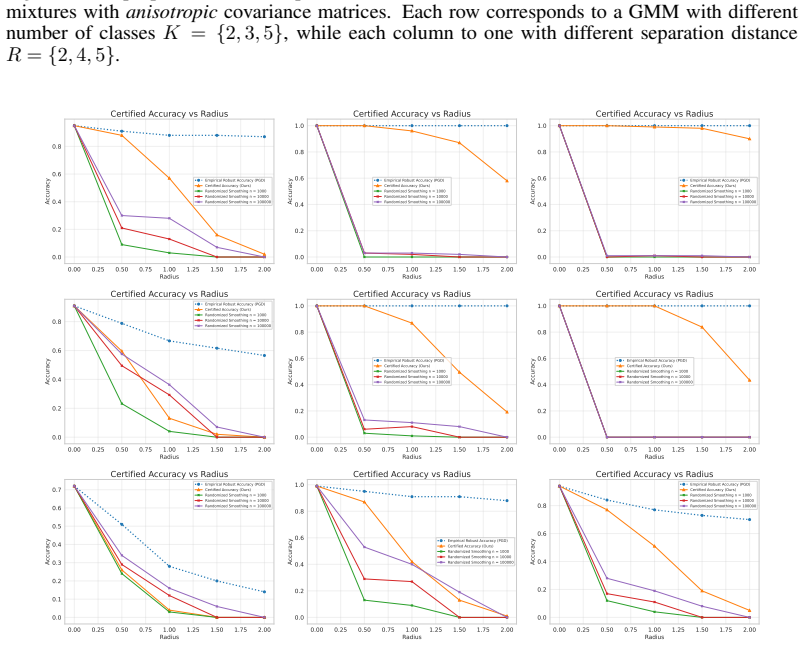
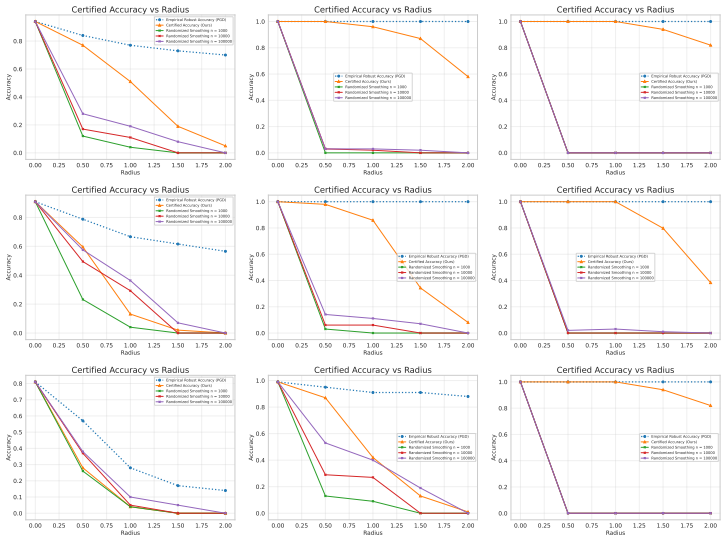
In the exact Gaussian mixture case the authors derive necessary and sufficient conditions for the existence of robust classifiers and give a closed-form certificate together with generalization bounds. Their main result extends this to the approximate setting: when the latent distribution is ε-close in KL to a mixture, the certified accuracy under the true distribution is bounded by the certified accuracy under the mixture plus a term that grows with ε, allowing the direct use of pretrained encoders without exact distributional assumptions.
What carries the argument
The explicit bound relating the robustness certificate under an ε-KL-close latent distribution to the certificate under the corresponding Gaussian mixture.
If this is right
- Any pretrained encoder whose latent space satisfies a small ε bound can be turned into a certifiably robust classifier without retraining or architectural changes.
- The certificate strength can be traded off against the quality of the distributional approximation in a quantifiable way.
- Generalization guarantees derived for the exact mixture case carry over to the approximate case with an additive penalty controlled by ε.
- Empirical results on CIFAR-10 and ImageNet demonstrate that the resulting certificates are competitive while preserving clean accuracy and low overhead.
Where Pith is reading between the lines
- If the KL distance can be estimated reliably from finite samples, the method supplies a practical diagnostic for whether a given pretrained model is suitable for certification.
- Regularizing a pretrained model to reduce its latent KL to the nearest mixture could be used as a training-time knob to tighten the final robustness bound.
- The same continuity argument might apply to other distributional distances or other base distributions if the robustness measure is Lipschitz with respect to those distances.
Load-bearing premise
Pretrained encoders exist whose induced latent distributions are close enough to some Gaussian mixture for the degradation term to remain small.
What would settle it
A pretrained encoder whose latent KL distance to every Gaussian mixture is small, yet whose certified accuracy falls well below the value predicted by the explicit bound, would falsify the degradation claim.
Figures
read the original abstract
Deep learning models are vulnerable to adversarial perturbations, raising important concerns for safety-critical deployment. Empirical defenses can achieve strong robustness in practice, but lack formal guarantees, motivating the need for certifiably robust classifiers. While certified methods provide formal guarantees, they often yield overly conservative bounds due to their inability to exploit structure in complex data distributions. In this work, we propose a framework for designing certifiably robust classifiers that leverages latent structure in data representations. We first analyze the Gaussian mixture setting, deriving necessary and sufficient conditions for the existence of robust classifiers and constructing a classifier with a closed-form robustness certificate and generalization guarantees. Our main contribution is to show that exact structure is not required: we prove that if a pretrained encoder maps inputs to a latent distribution that is $\varepsilon$-close (in KL divergence) to a Gaussian mixture, then certified accuracy degrades gracefully, with an explicit bound relating robustness under the true and approximate distributions. This result enables the direct use of pretrained models without requiring exact distributional assumptions. Empirically, our method achieves state-of-the-art or competitive certified accuracy on CIFAR-10 and ImageNet, while maintaining strong clean performance and low computational overhead. Overall, our work establishes approximate latent structure as a practical and principled route to certifiable robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that certifiably robust classifiers can be designed by exploiting approximate Gaussian mixture structure in the latent space of a pretrained encoder. It first derives necessary and sufficient conditions for robust classifiers under an exact GMM, constructs a closed-form certificate with generalization guarantees, and then proves that if the true latent distribution is ε-close in KL divergence to some GMM, the certified accuracy under the true distribution is bounded by an explicit function of the certified accuracy under the mixture plus a term depending on ε. This enables direct use of pretrained models. Empirically the method reports state-of-the-art or competitive certified accuracy on CIFAR-10 and ImageNet while preserving clean accuracy.
Significance. If the graceful-degradation bound holds and the required small KL closeness is realized by standard pretrained encoders, the result would allow certified robustness to be obtained from existing representations without exact distributional assumptions, narrowing the gap between empirical and certified methods. The explicit bound relating the two distributions is a technical strength when the premise is satisfied.
major comments (2)
- [Main theorem and empirical evaluation] The main theorem (the graceful-degradation result relating certified accuracy under the true latent distribution to that under the ε-close GMM) is load-bearing for all downstream claims, yet the manuscript supplies neither a measurement of the realized KL divergence ε for the encoders and datasets used (ResNet/ViT on CIFAR-10/ImageNet) nor a reproducible procedure for selecting or fitting the reference GMM. Without these, the empirical results cannot be shown to follow from the theorem rather than from post-hoc choices.
- [Abstract and §4 (empirical section)] The abstract and introduction assert that the method achieves SOTA certified accuracy on CIFAR-10 and ImageNet, but the absence of reported ε values or sensitivity plots versus ε leaves open whether the certificates remain non-vacuous once the approximation error is accounted for; this directly affects the central claim that approximate structure yields practical certificates.
minor comments (1)
- [GMM analysis section] Notation for the closed-form certificate in the exact GMM case should be cross-referenced explicitly to the generalization bound so readers can verify the parameter-free character claimed in the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive comments emphasizing the need to connect the main theorem to the empirical results. We address the points below and will revise accordingly to improve reproducibility and clarity.
read point-by-point responses
-
Referee: [Main theorem and empirical evaluation] The main theorem (the graceful-degradation result relating certified accuracy under the true latent distribution to that under the ε-close GMM) is load-bearing for all downstream claims, yet the manuscript supplies neither a measurement of the realized KL divergence ε for the encoders and datasets used (ResNet/ViT on CIFAR-10/ImageNet) nor a reproducible procedure for selecting or fitting the reference GMM. Without these, the empirical results cannot be shown to follow from the theorem rather than from post-hoc choices.
Authors: We agree that a reproducible GMM fitting procedure is required for the claims to be verifiable. In revision we will add a dedicated subsection detailing the fitting algorithm, number of mixture components, initialization, and hyperparameter selection for each encoder/dataset pair. Exact computation of the realized KL divergence ε is intractable in these high-dimensional latent spaces without prohibitive density estimation; we will instead add a discussion of this limitation together with any feasible Monte-Carlo proxies or qualitative diagnostics that can be reported. revision: partial
-
Referee: [Abstract and §4 (empirical section)] The abstract and introduction assert that the method achieves SOTA certified accuracy on CIFAR-10 and ImageNet, but the absence of reported ε values or sensitivity plots versus ε leaves open whether the certificates remain non-vacuous once the approximation error is accounted for; this directly affects the central claim that approximate structure yields practical certificates.
Authors: We will revise the abstract, introduction, and empirical section to qualify the SOTA statements with reference to the graceful-degradation bound and to include sensitivity plots of certified accuracy versus ε. These additions will make explicit that the reported certificates are meaningful under the theorem once the approximation quality is taken into account. revision: yes
- Exact numerical measurement of the realized KL divergence ε in high-dimensional latent spaces, which remains computationally intractable.
Circularity Check
No circularity; derivation is conditional on external assumption and self-contained.
full rationale
The central result is a mathematical bound showing graceful degradation of certified accuracy when the latent distribution is ε-close in KL to a GMM. This is derived from the GMM case and extended via the KL assumption; the bound does not reduce to its inputs by construction, nor does any step rename a fit as a prediction or rely on self-citation chains. The assumption that ε is small for pretrained encoders is stated as external and unverified in the manuscript, but this affects applicability rather than creating definitional circularity in the derivation itself. No load-bearing steps match the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A pretrained encoder exists whose latent distribution is ε-close in KL divergence to some Gaussian mixture
Reference graph
Works this paper leans on
-
[1]
Hassan Ashtiani, Shai Ben-David, Nicholas J. A. Harvey, Christopher Liaw, Abbas Mehrabian, and Yaniv Plan. Near-optimal sample complexity bounds for robust learning of gaussian mixtures via compression schemes. Journal of the ACM, 67 0 (6), 2020
2020
-
[2]
Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples
Anish Athalye, Nicholas Carlini, and David Wagner. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In International Conference on Machine Learning, pages 274--283. PMLR, 2018
2018
-
[3]
On Evaluating Adversarial Robustness
Nicholas Carlini, Anish Athalye, Nicolas Papernot, Wieland Brendel, Jonas Rauber, Dimitris Tsipras, Ian Goodfellow, Aleksander Madry, and Alexey Kurakin. On evaluating adversarial robustness. arXiv preprint arXiv:1902.06705, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[4]
Zico Kolter
Nicholas Carlini, Florian Tram \`e r, Krishnamurthy Dj Dvijotham, Leslie Rice, Mingjie Sun, and J. Zico Kolter. (certified!!) adversarial robustness for free!, 2023
2023
-
[5]
Haeffele, Ren \'e Vidal, and Yi Ma
Tianzhe Chu, Shengbang Tong, Tianjiao Ding, Xili Dai, Benjamin D. Haeffele, Ren \'e Vidal, and Yi Ma. Image clustering via the principle of rate reduction in the age of pretrained models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[6]
Zico Kolter
Jeremy Cohen, Elan Rosenfeld, and J. Zico Kolter. Certified adversarial robustness via randomized smoothing. In International Conference on Machine Learning, 2019
2019
-
[7]
Provable tradeoffs in adversarially robust classification
Edgar Dobriban, Hamed Hassani, David Hong, and Alexander Robey. Provable tradeoffs in adversarially robust classification. IEEE Transactions on Information Theory, 2023
2023
-
[8]
Generalized no free lunch theorem for adversarial robustness
Elvis Dohmatob. Generalized no free lunch theorem for adversarial robustness. In International Conference on Machine Learning, pages 1646--1654. PMLR, 2019
2019
-
[9]
On the effectiveness of interval bound propagation for training verifiably robust models
Sven Gowal, Krishnamurthy Dvijotham, Robert Stanforth, Rudy Bunel, Chongli Qin, Jonathan Uesato, Relja Arandjelovi \'c , Timothy Mann, and Pushmeet Kohli. On the effectiveness of interval bound propagation for training verifiably robust models. In Advances in Neural Information Processing Systems, volume 31, 2018
2018
-
[10]
Horv \'a th, Mark Niklas M \"u ller, Marc Fischer, and Martin Vechev
Mikl \'o s Z. Horv \'a th, Mark Niklas M \"u ller, Marc Fischer, and Martin Vechev. Boosting randomized smoothing with variance reduced classifiers, 2022
2022
-
[11]
Sok: Certified robustness for deep neural networks
Linyi Li, Tao Xie, and Bo Li. Sok: Certified robustness for deep neural networks. In IEEE Symposium on Security and Privacy. IEEE, 2023
2023
-
[12]
Towards Deep Learning Models Resistant to Adversarial Attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
K. V. Mardia. Measures of multivariate skewness and kurtosis with applications. Biometrika, 57 0 (3): 0 519--530, 1970
1970
-
[14]
Adversarial examples might be avoidable: The role of data concentration in adversarial robustness
Ambar Pal, Jeremias Sulam, and Ren \'e Vidal. Adversarial examples might be avoidable: The role of data concentration in adversarial robustness. In Advances in Neural Information Processing Systems, 2023
2023
-
[15]
Certified robustness against sparse adversarial perturbations via data localization
Ambar Pal, Ren \'e Vidal, and Jeremias Sulam. Certified robustness against sparse adversarial perturbations via data localization. Transactions on Machine Learning Research, 2024
2024
-
[16]
Adversarial risk via optimal transport and optimal couplings
Muni Sreenivas Pydi and Varun Jog. Adversarial risk via optimal transport and optimal couplings. In International Conference on Machine Learning, 2020
2020
-
[17]
Provably robust deep learning via adversarially trained smoothed classifiers
Hadi Salman, Jerry Li, Ilya Razenshteyn, Pengchuan Zhang, Huan Zhang, S \'e bastien Bubeck, and Greg Yang. Provably robust deep learning via adversarially trained smoothed classifiers. In Advances in Neural Information Processing Systems, volume 32, 2019
2019
-
[18]
Zico Kolter
Hadi Salman, Mingjie Sun, Greg Yang, Ashish Kapoor, and J. Zico Kolter. Denoised smoothing: A provable defense for pretrained classifiers. In Advances in Neural Information Processing Systems, volume 33, pages 21945--21957, 2020
2020
-
[19]
Robust clip: Unsupervised adversarial fine-tuning of vision embeddings for robust large vision-language models
Christian Schlarmann, Naman Deep Singh, Francesco Croce, and Matthias Hein. Robust clip: Unsupervised adversarial fine-tuning of vision embeddings for robust large vision-language models. In International Conference on Machine Learning, 2024
2024
-
[20]
Ronny Huang, Christoph Studer, Soheil Feizi, and Tom Goldstein
Ali Shafahi, W. Ronny Huang, Christoph Studer, Soheil Feizi, and Tom Goldstein. Are adversarial examples inevitable? In International Conference on Learning Representations, 2018
2018
-
[21]
Davis, Gavin Taylor, and Tom Goldstein
Ali Shafahi, Mahyar Najibi, Mohammad Amin Ghiasi, Zheng Xu, John Dickerson, Christoph Studer, Larry S. Davis, Gavin Taylor, and Tom Goldstein. Adversarial training for free! In Advances in Neural Information Processing Systems, 2019
2019
-
[22]
Intriguing properties of neural networks
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. In International Conference on Learning Representations, 2014
2014
-
[23]
Wainwright
Martin J. Wainwright. High-Dimensional Statistics: A Non-Asymptotic Viewpoint. Cambridge University Press, 2019
2019
-
[24]
Evaluating the robustness of neural networks: An extreme value theory approach, 2018
Tsui-Wei Weng, Huan Zhang, Pin-Yu Chen, Jinfeng Yi, Dong Su, Yupeng Gao, Cho-Jui Hsieh, and Luca Daniel. Evaluating the robustness of neural networks: An extreme value theory approach, 2018
2018
-
[25]
Zico Kolter
Eric Wong and J. Zico Kolter. Provable defenses against adversarial examples via the convex outer adversarial polytope. In International Conference on Machine Learning, pages 5283--5292, 2018
2018
-
[26]
Zico Kolter
Eric Wong, Leslie Rice, and J. Zico Kolter. Fast is better than free: Revisiting adversarial training. In International Conference on Learning Representations, 2020
2020
-
[27]
Densepure: Understanding diffusion models towards adversarial robustness, 2022
Chaowei Xiao, Zhongzhu Chen, Kun Jin, Jiongxiao Wang, Weili Nie, Mingyan Liu, Anima Anandkumar, Bo Li, and Dawn Song. Densepure: Understanding diffusion models towards adversarial robustness, 2022
2022
-
[28]
On the certified robustness for ensemble models and beyond, 2022
Zhuolin Yang, Linyi Li, Xiaojun Xu, Bhavya Kailkhura, Tao Xie, and Bo Li. On the certified robustness for ensemble models and beyond, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.