Will Scaling Improve Social Simulation with LLMs?
Pith reviewed 2026-07-03 14:20 UTC · model grok-4.3
The pith
Scaling laws show LLM social simulations improve for most populations but stall on biases and low-resource groups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
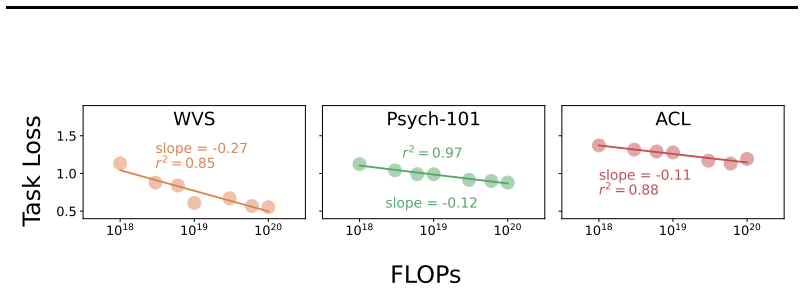
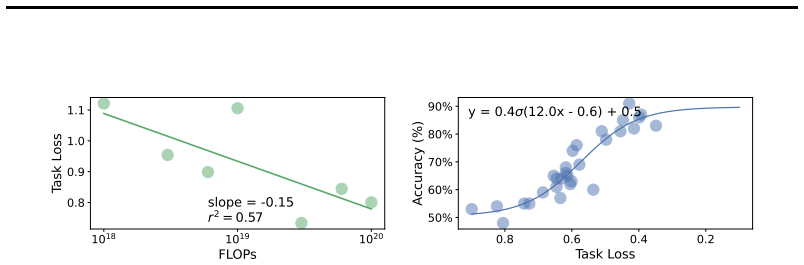
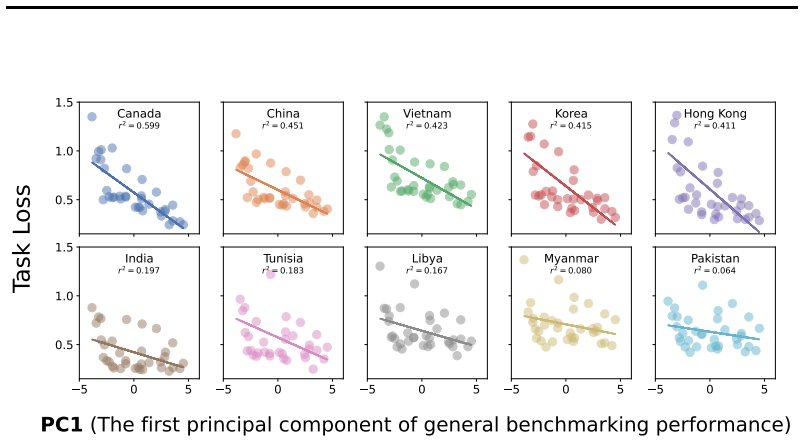
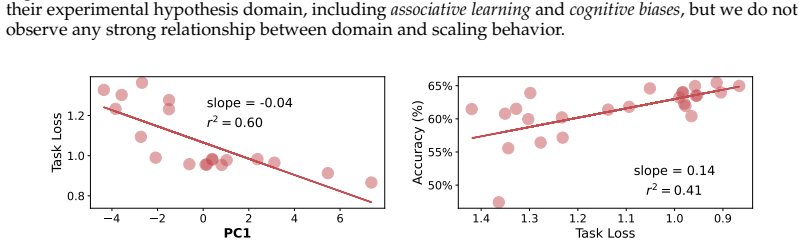
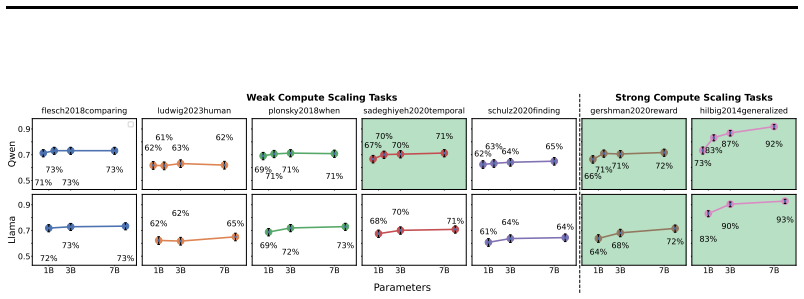
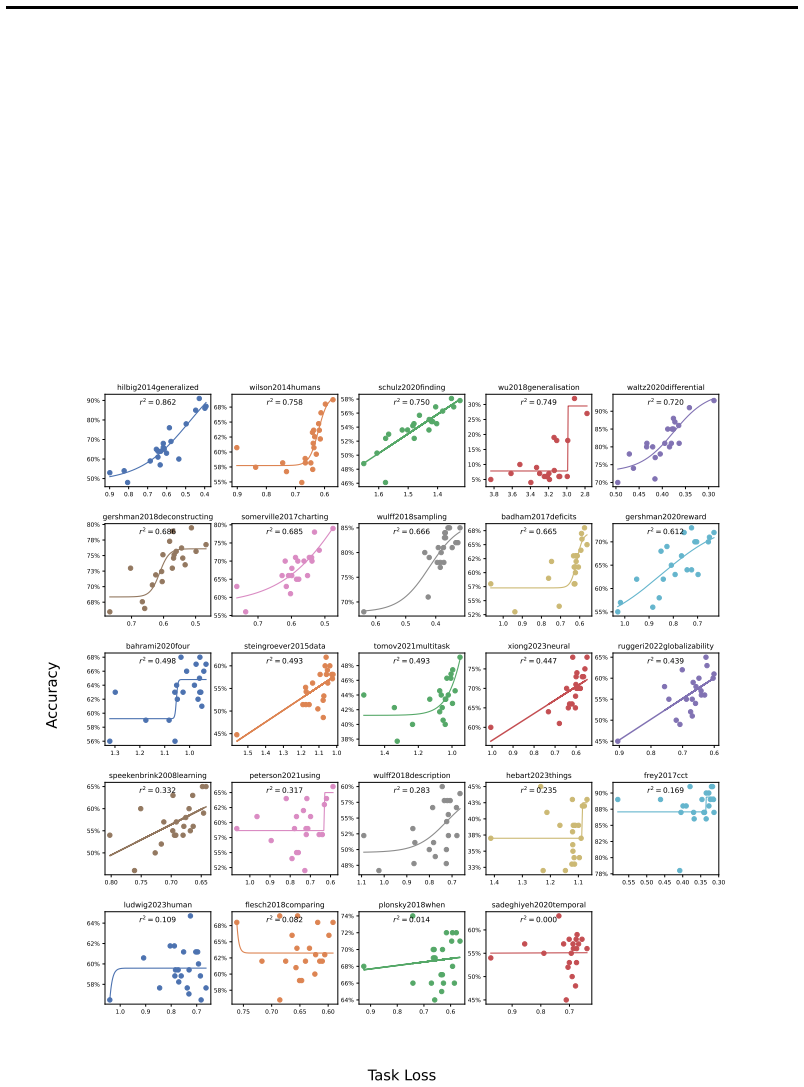
Strong compute scaling appears across the three sub-domains when tasks involve populations well-represented in training data, enabling downstream accuracy to be predicted from pre-training loss; however, scaling does not improve calibration to human cognitive biases or heuristics, and both longitudinal forecasting and underrepresented opinions improve more slowly and correlate less strongly with benchmarks such as MMLU.
What carries the argument
Scaling laws that map pre-training compute budgets (10^18 to 10^20 FLOPs) and model sizes up to 70B parameters to measured fidelity of social simulations against human ground truth in the three sub-domains.
If this is right
- The majority of behavioral and opinion simulation tasks will rapidly improve with scale, especially for populations well-represented in English web corpora.
- Longitudinal forecasting and underrepresented opinions will scale more slowly and show weaker correlation with general knowledge benchmarks.
- Model calibration with human cognitive biases such as risk aversion and with certain learning heuristics will not improve noticeably with scale, even after fine-tuning.
- Improvements from scaling will be less reliable in low-resource domains.
Where Pith is reading between the lines
- As models scale, simulations may increasingly over-represent majority views captured in web text while lagging on minority perspectives.
- General capability gains measured by MMLU may not reliably transfer to modeling of human decision heuristics or biases.
- Targeted data curation or architectural changes may be required to close the gaps that pure scaling leaves open.
- Longer-horizon forecasting tasks may need explicit temporal modeling rather than relying on continued pre-training scale.
Load-bearing premise
The three chosen sub-domains and the specific tasks inside them are representative enough of real-world social simulation needs to support general conclusions about scaling.
What would settle it
Accuracy on behavioral simulation tasks that require matching human risk aversion stays flat or declines when model size increases from 8B to 70B on the same evaluation sets.
Figures
read the original abstract
Large Language Model (LLM) social simulations are a promising research method, but they are not yet faithful enough to be adopted widely. In this work, we investigate whether the current scaling paradigm in language modeling is likely to close these gaps, or whether simulation fidelity is orthogonal to general capabilities and therefore deserving of more research attention. We use scaling laws to study the relationship between LLMs' compute scale, general capability benchmarks, and the fidelity of social simulation in three representative sub-domains: opinion modeling, behavioral simulation, and longitudinal forecasting. Surprisingly, we discover strong compute scaling in all three settings, using a suite of 85 transformer LLMs with the Qwen3 architecture pre-trained on the DCLM web text corpus under fixed-compute budgets from $10^{18}$ to $10^{20}$ FLOPs. Then we evaluate 35 larger and more capable open-weight models up to 70B parameters, allowing us to predict downstream accuracy from loss. This reveals that the majority of behavioral and opinion simulation tasks will rapidly improve with scale, particularly when they involve populations that are well-represented in English web corpora. Longitudinal forecasting and underrepresented opinions scale more slowly, especially when they are less correlated with general knowledge and reasoning benchmarks like MMLU. In behavior simulation, scaling fails to improve model calibration with human cognitive biases like risk aversion, as well as human heuristics like learning correlated rewards from related tasks. On these tasks, even fine-tuned models fail to noticeably scale up performance from 0.5B to 8B parameters. Taken together, we conclude that scale will improve social simulations in most settings, but outliers exist, and improvements will be less reliable in low-resource domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether LLM scaling improves fidelity in social simulations across three sub-domains (opinion modeling, behavioral simulation, longitudinal forecasting). Using 85 Qwen3 transformers pretrained on the DCLM corpus under fixed compute budgets ($10^{18}$ to $10^{20}$ FLOPs) plus 35 larger open-weight models up to 70B, it reports strong compute scaling for most tasks (especially well-represented populations correlated with English web text and MMLU), slower scaling for longitudinal forecasting and underrepresented opinions, and failure to improve calibration on cognitive biases or heuristics even after fine-tuning.
Significance. If the results hold, the work supplies controlled empirical evidence that general scaling laws extend to many social-simulation tasks while identifying concrete outliers (bias calibration, low-resource domains). The explicit compute-budget pretraining of 85 models and downstream loss-to-accuracy prediction constitute a reproducible strength that can guide future simulation research.
major comments (3)
- [Discussion / Conclusion] The central claim that scaling improves fidelity 'in most settings' rests on the representativeness of the three chosen sub-domains and their concrete tasks; the manuscript provides no quantitative sampling argument or coverage analysis showing these tasks capture the broader distribution of social-simulation needs (e.g., multi-agent coordination, cultural transmission, non-English contexts).
- [§3 / Results] §3 (Experimental Setup) and the results sections omit full task definitions, exact metrics, statistical procedures, and error analysis; without these the reported 'rapid improvement' and 'strong compute scaling' cannot be independently verified.
- [Behavioral Simulation Results] The claim that scaling fails for bias-calibration and heuristic tasks is supported only up to 8B parameters (fine-tuned); it is unclear whether the same pattern persists in the 35 larger models evaluated up to 70B or whether the loss-to-accuracy regression was applied to these outlier tasks.
minor comments (2)
- [§3] Notation for the loss-to-accuracy mapping and the precise definition of 'fidelity' should be stated explicitly in the methods.
- [Figures] Figure captions and axis labels for the scaling plots should include the exact number of models and compute range for each curve.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the recognition of the paper's controlled experimental design. We address each major comment below with specific plans for revision where appropriate.
read point-by-point responses
-
Referee: [Discussion / Conclusion] The central claim that scaling improves fidelity 'in most settings' rests on the representativeness of the three chosen sub-domains and their concrete tasks; the manuscript provides no quantitative sampling argument or coverage analysis showing these tasks capture the broader distribution of social-simulation needs (e.g., multi-agent coordination, cultural transmission, non-English contexts).
Authors: We selected the three sub-domains because they represent the most common categories in existing LLM social simulation literature (opinion polling, individual decision tasks, and multi-step forecasting). We agree that the manuscript lacks a quantitative coverage analysis or sampling argument. In revision we will add a dedicated paragraph in the Discussion section that explicitly lists the scope limitations, including the absence of multi-agent coordination and non-English settings, and note that the 'most settings' claim is conditioned on the evaluated task distribution rather than a formal statistical sample of all possible social simulation needs. revision: partial
-
Referee: [§3 / Results] §3 (Experimental Setup) and the results sections omit full task definitions, exact metrics, statistical procedures, and error analysis; without these the reported 'rapid improvement' and 'strong compute scaling' cannot be independently verified.
Authors: All task definitions, exact metrics (including accuracy, calibration error, and correlation coefficients), statistical procedures (bootstrap confidence intervals and regression details), and error analysis appear in the appendix. We acknowledge that the main text does not sufficiently cross-reference these details. In the revised manuscript we will expand §3 with concise definitions and metric formulas for the primary tasks and add explicit pointers to the appendix for full specifications and statistical methods. revision: yes
-
Referee: [Behavioral Simulation Results] The claim that scaling fails for bias-calibration and heuristic tasks is supported only up to 8B parameters (fine-tuned); it is unclear whether the same pattern persists in the 35 larger models evaluated up to 70B or whether the loss-to-accuracy regression was applied to these outlier tasks.
Authors: The bias-calibration and heuristic tasks were evaluated exclusively on the 85 controlled Qwen3 models (0.5B–8B) with fine-tuning; the 35 larger open-weight models were used only for the loss-to-accuracy regressions on the main opinion and behavioral tasks. We will revise the Behavioral Simulation Results section to state this scope explicitly and note that the loss-to-accuracy analysis was not applied to the bias-calibration outliers because those tasks were not run on the larger models. We will also add a sentence indicating that extrapolation from the observed flat scaling up to 8B suggests limited improvement at larger scales, while acknowledging the absence of direct measurements beyond 8B. revision: partial
Circularity Check
No circularity; claims rest on direct empirical measurements against human data
full rationale
The paper derives its conclusions from explicit evaluations of 85 Qwen3 models and 35 larger open-weight models on opinion modeling, behavioral simulation, and longitudinal forecasting tasks, measuring fidelity directly against human data and observing compute scaling trends. No equation or claim reduces a prediction to a fitted parameter by construction, no self-citation bears the load of the central result, and no ansatz or uniqueness theorem is imported to force the outcome. The scaling relationships and outlier identification are data-driven observations, not self-referential definitions or renamings of known results.
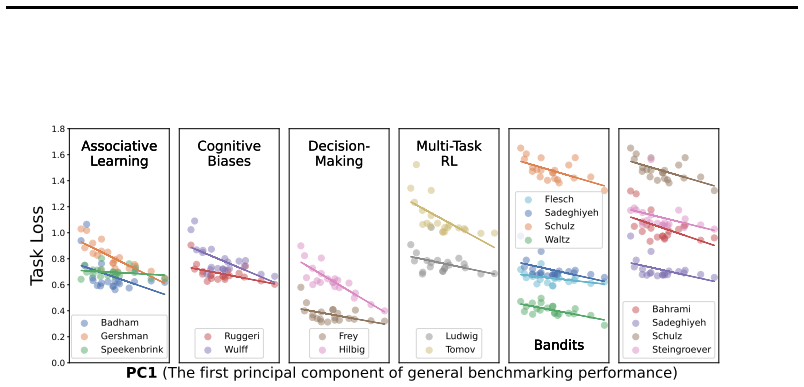
Axiom & Free-Parameter Ledger
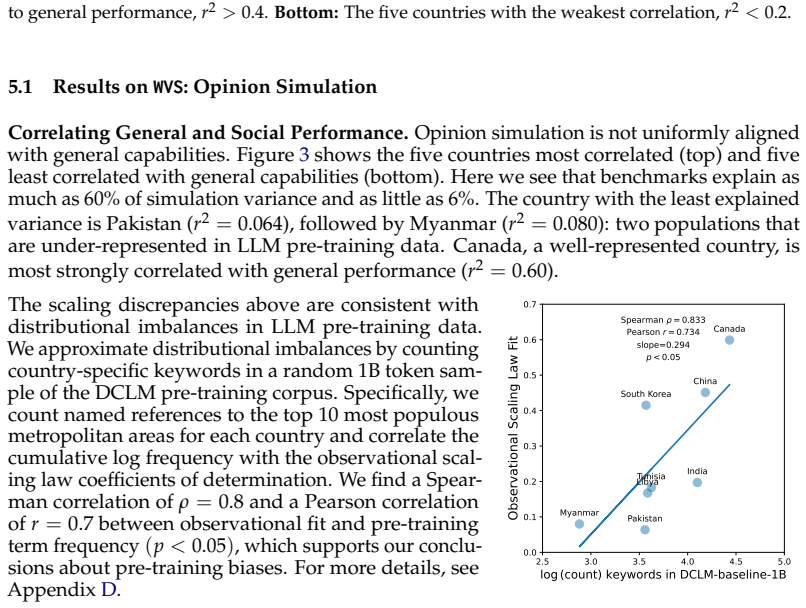
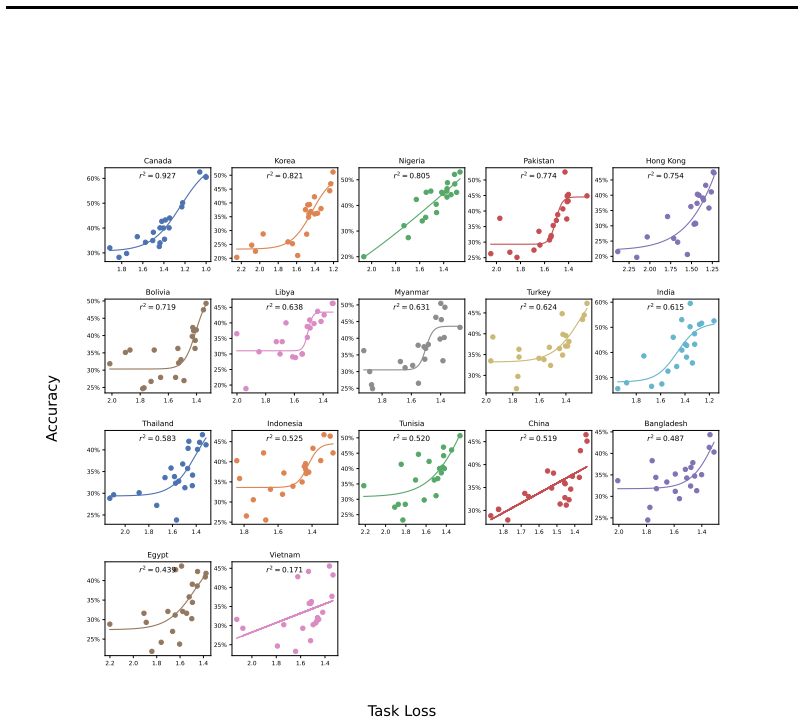
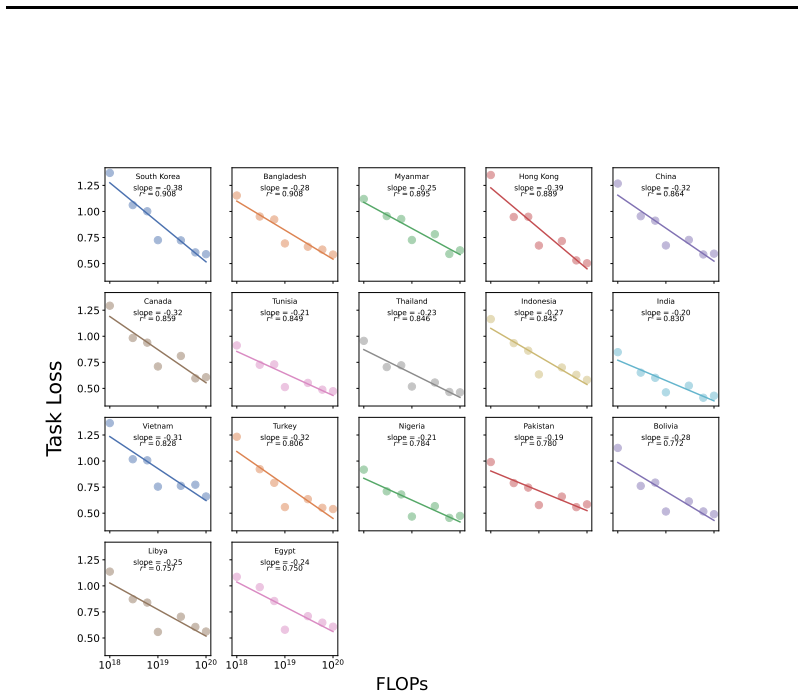
Reference graph
Works this paper leans on
-
[1]
Llm social simulations are a promising research method.arXiv preprint arXiv:2504.02234,
Jacy Reese Anthis, Ryan Liu, Sean M Richardson, Austin C Kozlowski, Bernard Koch, James Evans, Erik Brynjolfsson, and Michael Bernstein. Llm social simulations are a promising research method.arXiv preprint arXiv:2504.02234,
-
[2]
Revealing the structure of language model capabilities.arXiv preprint arXiv:2306.10062,
Ryan Burnell, Han Hao, Andrew RA Conway, and Jose Hernandez Orallo. Revealing the structure of language model capabilities.arXiv preprint arXiv:2306.10062,
-
[3]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evalu- ating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
LLM-in-the-loop: Leveraging large lan- guage models for thematic analysis
Shih-Chieh Dai, Aohan Xiong, and Lun-Wei Ku. LLM-in-the-loop: Leveraging large lan- guage models for thematic analysis. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,
2023
-
[7]
R Maria del Rio-Chanona, Marco Pangallo, and Cars Hommes. Can generative ai agents behave like humans? evidence from laboratory market experiments.arXiv preprint arXiv:2505.07457,
-
[8]
Take caution in using llms as human surrogates: Scylla ex machina.arXiv preprint arXiv:2410.19599,
Yuan Gao, Dokyun Lee, Gordon Burtch, and Sina Fazelpour. Take caution in using llms as human surrogates: Scylla ex machina.arXiv preprint arXiv:2410.19599,
-
[9]
Augusto Gonzalez-Bonorino, Monica Capra, and Emilio Pantoja. Llms model non-weird populations: Experiments with synthetic cultural agents.arXiv preprint arXiv:2501.06834,
-
[10]
URLhttps://arxiv.org/abs/2407.21783. Kobi Hackenburg, Ben M Tappin, Paul Röttger, Scott A Hale, Jonathan Bright, and Helen Margetts. Scaling language model size yields diminishing returns for single-message political persuasion.Proceedings of the National Academy of Sciences, 122(10):e2413443122,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Evaluating large language models in generating synthetic hci research data: a case study
Perttu Hämäläinen, Mikke Tavast, and Anton Kunnari. Evaluating large language models in generating synthetic hci research data: a case study. InProceedings of the 2023 CHI conference on human factors in computing systems, pp. 1–19,
2023
-
[12]
William Held, David Hall, Percy Liang, and Diyi Yang
Open Athena Blog. William Held, David Hall, Percy Liang, and Diyi Yang. Relative scaling laws for llms.arXiv preprint arXiv:2510.24626,
-
[13]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[14]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
House, Sarah A
James S. House, Sarah A. Burgard, Margaret T. Hicken, and Paula M. Lantz. Americans’ changing lives: Waves i–vi, 1986–2021,
1986
-
[17]
SimBench: Benchmarking the Ability of Large Language Models to Simulate Human Behaviors
Tiancheng Hu, Joachim Baumann, Lorenzo Lupo, Nigel Collier, Dirk Hovy, and Paul Röttger. Simbench: Benchmarking the ability of large language models to simulate human behaviors.arXiv preprint arXiv:2510.17516,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Shapeng Jiang, Lijia Wei, and Chen Zhang. Donald trumps in the virtual polls: Simulating and predicting public opinions in surveys using large language models.arXiv preprint arXiv:2411.01582,
-
[19]
AI-Augmented Surveys: Leveraging Large Language Models and Surveys for Opinion Prediction
Junsol Kim and Byungkyu Lee. Ai-augmented surveys: Leveraging large language models and surveys for opinion prediction.arXiv preprint arXiv:2305.09620,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Finetuning llms for human behavior prediction in social science experiments
Akaash Kolluri, Shengguang Wu, Joon Sung Park, and Michael S Bernstein. Finetuning llms for human behavior prediction in social science experiments. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 30084–30099,
2025
-
[21]
Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning.Advances in Neural Information Processing Systems, 35:1950–1965,
Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin A Raffel. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning.Advances in Neural Information Processing Systems, 35:1950–1965,
1950
-
[22]
Peterson, Ilia Sucholutsky, and Thomas L
Ryan Liu, Jiayi Geng, Joshua C Peterson, Ilia Sucholutsky, and Thomas L Griffiths. Large language models assume people are more rational than we really are.arXiv preprint arXiv:2406.17055,
-
[23]
T. Ludwig, M. Siegel, and E. Schulz. Human multi-task learning: The why and what. http://dx.doi.org/10.32470/CCN.2023.1528-0,
-
[24]
Ali Merali. Scaling laws for economic productivity: Experimental evidence in llm-assisted translation.arXiv preprint arXiv:2409.02391,
-
[25]
Xinyi Mou, Xuanwen Ding, Qi He, Liang Wang, Jingcong Liang, Xinnong Zhang, Libo Sun, Jiayu Lin, Jie Zhou, Xuanjing Huang, et al. From individual to society: A survey on social simulation driven by large language model-based agents.arXiv preprint arXiv:2412.03563,
-
[26]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals
Joon Sung Park, Carolyn Q Zou, Aaron Shaw, Benjamin Mako Hill, Carrie Cai, Mered- ith Ringel Morris, Robb Willer, Percy Liang, and Michael S Bernstein. Generative agent simulations of 1,000 people.arXiv preprint arXiv:2411.10109, 2024a. Peter S Park, Philipp Schoenegger, and Chongyang Zhu. Diminished diversity-of-thought in a standard large language model...
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Nikolay B Petrov, Gregory Serapio-García, and Jason Rentfrow. Limited ability of llms to simulate human psychological behaviours: a psychometric analysis.arXiv preprint arXiv:2405.07248,
-
[28]
Qwen Team, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao L...
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Jillian Ross, Yoon Kim, and Andrew W Lo. Llm economicus? mapping the behavioral biases of llms via utility theory.arXiv preprint arXiv:2408.02784,
-
[30]
URLhttps://arxiv.org/abs/2304.15004. Rylan Schaeffer, Hailey Schoelkopf, Brando Miranda, Gabriel Mukobi, Varun Madan, Adam Ibrahim, Herbie Bradley, Stella Biderman, and Sanmi Koyejo. Why Has Predicting Downstream Capabilities of Frontier AI Models with Scale Remained Elusive?,
-
[31]
Hannah Schroeder, Marine Aubin Le Quéré, Cristina Randazzo, David Mimno, and Sarita Schoenebeck
URL https://arxiv.org/abs/2406.04391. Hannah Schroeder, Marine Aubin Le Quéré, Cristina Randazzo, David Mimno, and Sarita Schoenebeck. Large language models in qualitative research: Uses, tensions, and inten- tions. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pp. 1–17,
-
[32]
Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting. InInternational Conference on Learning Representations, volume 2024, pp. 25055–25083,
2024
-
[33]
Chenglei Si, Zitong Yang, Yejin Choi, Emmanuel Candès, Diyi Yang, and Tatsunori Hashimoto
URLhttps://huggingface.co/blog/codelion/optimal-dataset-mixing/. Chenglei Si, Zitong Yang, Yejin Choi, Emmanuel Candès, Diyi Yang, and Tatsunori Hashimoto. Towards execution-grounded automated ai research.arXiv preprint arXiv:2601.14525,
-
[34]
Taylor Sorensen, Benjamin Newman, Jared Moore, Chan Park, Jillian Fisher, Niloofar Mireshghallah, Liwei Jiang, and Yejin Choi. Spectrum tuning: Post-training for distribu- tional coverage and in-context steerability.arXiv preprint arXiv:2510.06084,
-
[35]
Zayne Sprague, Xi Ye, Kaj Bostrom, Swarat Chaudhuri, and Greg Durrett. Musr: Testing the limits of chain-of-thought with multistep soft reasoning.arXiv preprint arXiv:2310.16049,
-
[36]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
URL http://www.incompleteideas.net/IncIdeas/ BitterLesson.html. Blog post. Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, , and Jason Wei. Challenging big-bench tasks and whether chain-of-thought can solve them.arXiv preprint arXiv:2210.09261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Systematic biases in llm simulations of debates
Amir Taubenfeld, Yaniv Dover, Roi Reichart, and Ariel Goldstein. Systematic biases in llm simulations of debates. InProceedings of the 2024 conference on empirical methods in natural language processing, pp. 251–267,
2024
-
[38]
Pengda Wang, Huiqi Zou, Zihan Yan, Feng Guo, Tianjun Sun, Ziang Xiao, and Bo Zhang. Not yet: Large language models cannot replace human respondents for psychometric research.OSF Preprint: https://doi. org/10.31219/osf. io/rwy9b, 2024a. 21 Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Z...
-
[39]
Humans use directed and random exploration to solve the explore–exploit dilemma
Robert C Wilson, Andra Geana, John M White, Elliot A Ludvig, and Jonathan D Cohen. Humans use directed and random exploration to solve the explore–exploit dilemma. Journal of experimental psychology: General, 143(6):2074,
2074
-
[40]
World values survey wave 7 (2017–2022),
World Values Survey Association. World values survey wave 7 (2017–2022),
2017
-
[41]
Llm-based social simulations require a boundary.arXiv preprint arXiv:2506.19806,
Zengqing Wu, Run Peng, Takayuki Ito, Makoto Onizuka, and Chuan Xiao. Llm-based social simulations require a boundary.arXiv preprint arXiv:2506.19806,
-
[42]
URLhttps://arxiv.org/abs/2505.09388. Ziyi Yang, Zaibin Zhang, Zirui Zheng, Yuxian Jiang, Ziyue Gan, Zhiyu Wang, Zijian Ling, Jinsong Chen, Martz Ma, Bowen Dong, et al. Oasis: Open agent social interaction simulations with one million agents.arXiv preprint arXiv:2411.11581,
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
HellaSwag: Can a Machine Really Finish Your Sentence?
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence?arXiv preprint arXiv:1905.07830,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[44]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911,
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Mind the Sim2Real gap in user simulation for agentic tasks.arXiv preprint arXiv:2603.11245, 2026
Xuhui Zhou, Weiwei Sun, Qianou Ma, Yiqing Xie, Jiarui Liu, Weihua Du, Sean Welleck, Yiming Yang, Graham Neubig, Sherry Tongshuang Wu, et al. Mind the sim2real gap in user simulation for agentic tasks.arXiv preprint arXiv:2603.11245,
-
[46]
22 1.01.21.41.61.8 30% 40% 50% 60% r2 = 0.927 Canada 1.21.41.61.82.02.2 20% 25% 30% 35% 40% 45% 50% r2 = 0.821 Korea 1.41.61.82.0 20% 30% 40% 50% r2 = 0.805 Nigeria 1.41.61.82.0 25% 30% 35% 40% 45% 50% r2 = 0.774 Pakistan 1.251.501.752.002.25 20% 25% 30% 35% 40% 45% r2 = 0.754 Hong Kong 1.41.61.82.0 25% 30% 35% 40% 45% 50% r2 = 0.719 Bolivia 1.41.61.82.0 ...
2023
-
[47]
Baby Boomer (1946 -
B. Baby Boomer (1946 -
1946
-
[48]
Generation X (1965 -
C. Generation X (1965 -
1965
-
[49]
Millennial (1981 -
D. Millennial (1981 -
1981
-
[50]
Generation Z (1997 -
E. Generation Z (1997 -
1997
-
[51]
Generation Alpha (2013 -
F. Generation Alpha (2013 -
2013
-
[52]
N/A Response: D
G. N/A Response: D. Millennial (1981 -
1981
-
[53]
T", "Y",
Question: What is the highest educational level that you have attained? A. Primary education B. Lower secondary education C. Upper secondary education D. Post-secondary non-tertiary education E. Short-cycle tertiary education F. Bachelor or equivalent G. Master or equivalent H. Doctoral or equivalent I. N/A Response: A. Primary education Question: Which o...
1989
-
[54]
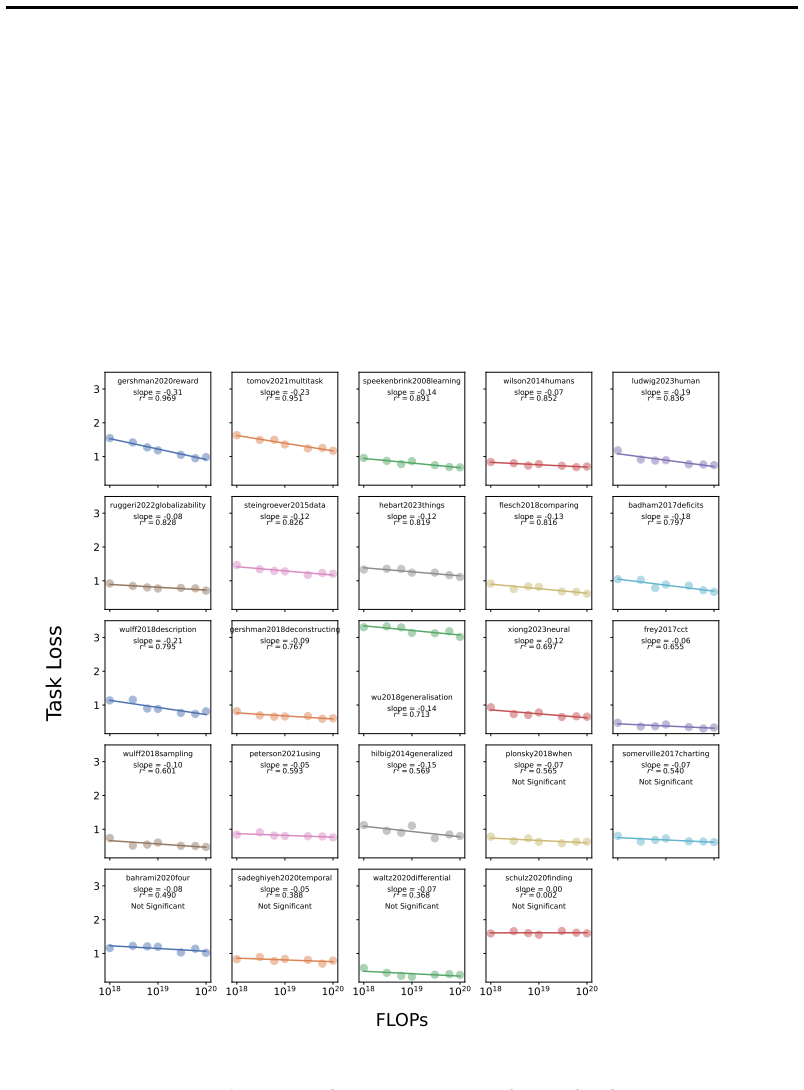
However, the slope is not significant with p< 0.05 forPlonsky et al
from 1018 to 1020 FLOPs. However, the slope is not significant with p< 0.05 forPlonsky et al. (2018), somerville2017charting, bahrami2020four, Sadeghiyeh et al. (2020), Waltz et al. (2020), andSchulz et al. (2020). 28 Subtask Category Sloper 2 rp-value Hilbig & Moshagen (2014) Decision-Making -0.03 0.72 0.85 0.00 Gershman (2020) Reward Maximization -0.03 ...
2018
-
[55]
In Figure 4, we correlate the log frequency of city terms in the DCLM with the observational scaling law fit. We find a Spearman correlation ofρ= 0.8 and a Pearson correlation ofr= 0.7 between observational fit and pre-training term frequency (p< 0.05), which supports our conclusions distributional imbalances in LLM pre-training data explain observational...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.