Demystifying NVSHMEM: A System-Level Analysis on Symmetric Memory and Device-Initiated Operations in GPU Communication
Pith reviewed 2026-06-27 23:45 UTC · model grok-4.3
The pith
NVSHMEM pioneered a device-side symmetric-memory model that lets GPUs drive one-sided communication and approach hardware limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
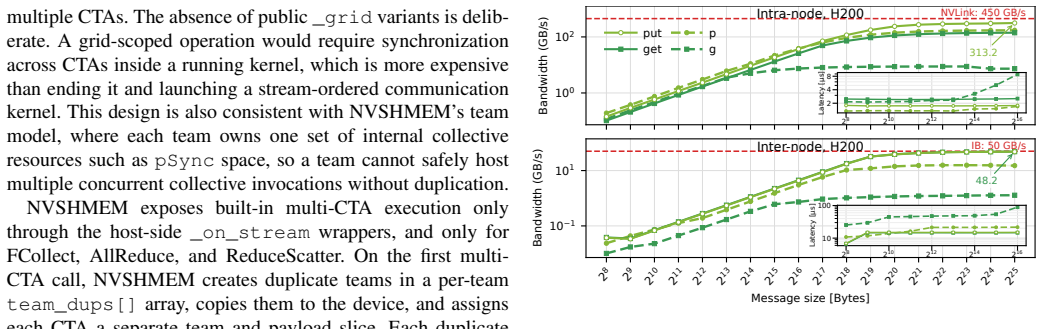
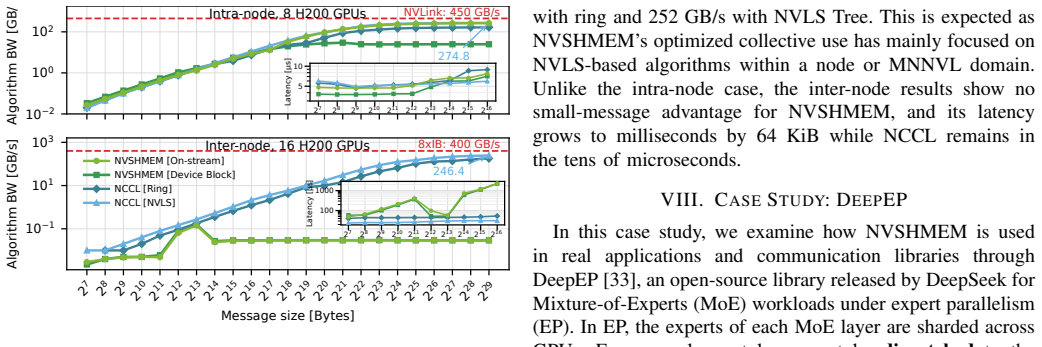
NVSHMEM pioneered a device-side symmetric-memory programming model that enables fine-grained GPU-driven communication and is important for approaching the hardware performance limit, as shown through its implementation of symmetric memory, one-sided operations, and collectives, with DeepEP illustrating its use in performance-critical workloads.
What carries the argument
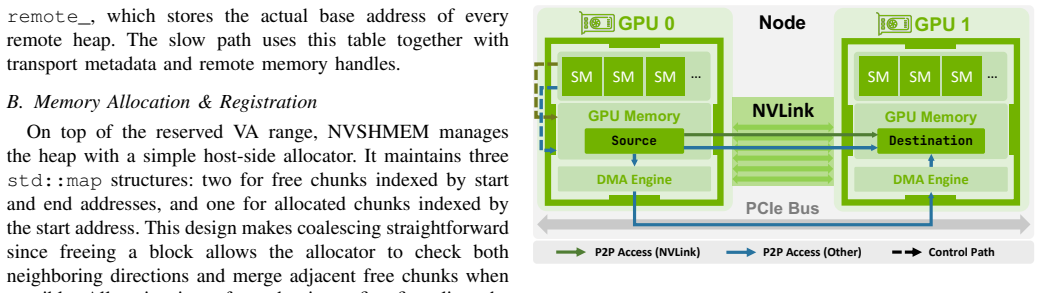
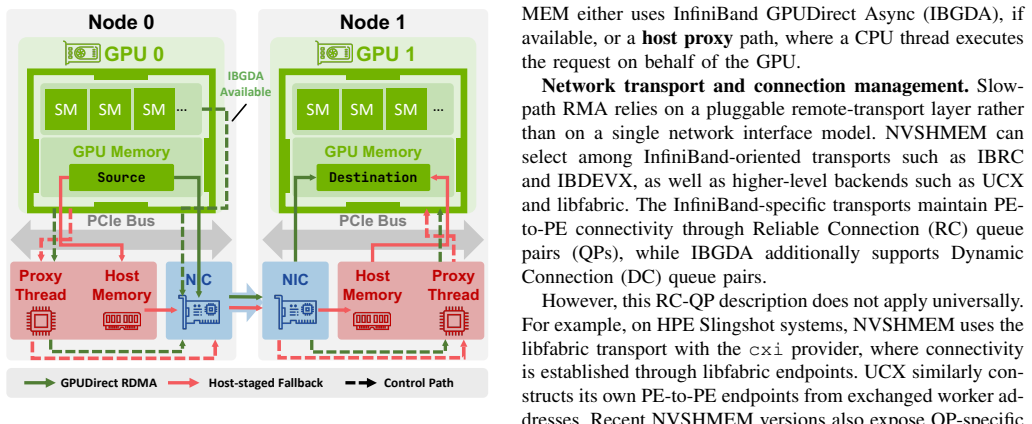
The device-side symmetric-memory programming model, which places identical memory regions on each GPU so that one-sided operations can be initiated directly from device code.
If this is right
- NVSHMEM functions as a systems building block for GPU-cluster communication runtimes.
- Design tradeoffs in symmetric memory layout and device-side collectives must be weighed when building higher-level libraries.
- Opportunities exist to improve GPU communication runtimes by addressing the gaps and choices identified in the analysis.
- The model supports performance-critical sparse deep learning workloads such as those handled by DeepEP.
Where Pith is reading between the lines
- The same device-initiated symmetric-memory approach could be adopted by other PGAS or one-sided libraries targeting GPUs.
- Future interconnect hardware designs might be evaluated against the performance targets NVSHMEM aims to reach.
- Re-examining NVSHMEM source code against new GPU architectures could reveal whether the current implementation still approaches limits.
Load-bearing premise
Documentation, source code, and application experience together give a complete and representative picture of NVSHMEM's implementation and behavior.
What would settle it
A concrete counter-example in which an application using NVSHMEM symmetric memory and device-initiated operations falls measurably short of the hardware communication limit that the paper associates with the model.
Figures

read the original abstract
NVSHMEM is NVIDIA's OpenSHMEM-based PGAS communication library for GPU clusters, enabling GPU-initiated, one-sided communication through symmetric memory. Despite its growing adoption, a system-level understanding of its design and behavior remains scattered across documentation, source code, and application experience. This paper presents a concise study of NVSHMEM's programming model, implementation, and performance characteristics, focusing on symmetric memory, one-sided operations, and device-side collectives. We also examine DeepEP as a case study of NVSHMEM in performance-critical sparse deep learning workloads. Our analysis shows that NVSHMEM pioneered a device-side symmetric-memory programming model that enables fine-grained GPU-driven communication and is important for approaching the hardware performance limit. Overall, this work defines NVSHMEM's role as a systems building block, highlights its design tradeoffs, and identifies opportunities for improving GPU communication runtimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a system-level analysis of NVSHMEM, NVIDIA's OpenSHMEM-based PGAS library for GPU clusters. It examines the programming model (symmetric memory and device-initiated one-sided operations), implementation details, device-side collectives, and performance characteristics, using DeepEP as a case study in sparse deep learning workloads. The central claim is that NVSHMEM pioneered the device-side symmetric-memory model enabling fine-grained GPU-driven communication and is important for approaching hardware performance limits, while also highlighting design tradeoffs and opportunities for GPU communication runtimes.
Significance. If the analysis holds and the sources are representative, the work provides a useful consolidation of scattered information on NVSHMEM as a building block for GPU clusters, with practical insights from the DeepEP case study. This could aid developers and researchers working on performance-critical GPU communication, though the descriptive nature limits predictive or quantitative novelty.
major comments (2)
- [Abstract] Abstract and introduction: The conclusions regarding NVSHMEM pioneering the device-side symmetric-memory model and its necessity for approaching hardware limits are stated without any description of the analysis methodology, how source code and documentation were examined, what verification steps were taken, or how completeness of the sources was assessed. This directly affects evaluation of the central claim.
- [DeepEP case study] Case study section on DeepEP: The performance claims and attribution of importance to NVSHMEM for hardware limits rest on application experience, but no explicit discussion addresses potential gaps in exposed implementation details, prior GPU PGAS efforts, or unexposed bottlenecks, making the exhaustiveness assumption load-bearing and unverified.
minor comments (1)
- [Introduction] The manuscript would benefit from a dedicated section or subsection explicitly outlining the sources consulted and any limitations of the analysis approach.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. The points raised identify opportunities to strengthen the manuscript by adding explicit methodological details and a more balanced discussion of limitations in the case study. We will revise accordingly to address both major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract and introduction: The conclusions regarding NVSHMEM pioneering the device-side symmetric-memory model and its necessity for approaching hardware limits are stated without any description of the analysis methodology, how source code and documentation were examined, what verification steps were taken, or how completeness of the sources was assessed. This directly affects evaluation of the central claim.
Authors: We agree that the abstract and introduction would benefit from an explicit description of our analysis methodology. In the revised manuscript we will add a short 'Analysis Methodology' subsection (approximately one paragraph) that outlines: (1) systematic review of the publicly available NVSHMEM source code on GitHub, (2) cross-referencing against NVIDIA's official documentation and release notes, (3) verification steps consisting of micro-benchmark reproduction on our test cluster and manual inspection of key internal functions, and (4) assessment of source completeness by noting which components remain closed-source. This addition will provide the necessary context for evaluating the central claims without altering the paper's descriptive nature. revision: yes
-
Referee: [DeepEP case study] Case study section on DeepEP: The performance claims and attribution of importance to NVSHMEM for hardware limits rest on application experience, but no explicit discussion addresses potential gaps in exposed implementation details, prior GPU PGAS efforts, or unexposed bottlenecks, making the exhaustiveness assumption load-bearing and unverified.
Authors: We accept that the case-study section would be improved by explicitly addressing these issues. The revised version will expand the DeepEP discussion with three short paragraphs: (1) a brief comparison to prior GPU PGAS approaches (CUDA-aware MPI one-sided operations and earlier prototype libraries), (2) acknowledgment of gaps in publicly exposed NVSHMEM implementation details (e.g., internal memory registration paths that remain proprietary), and (3) a limitations paragraph noting possible unexposed bottlenecks such as host-side runtime overheads or network topology effects not captured in the reported measurements. These additions will make the exhaustiveness assumptions transparent while preserving the practical insights from the case study. revision: yes
Circularity Check
No circularity in descriptive analysis paper
full rationale
This is a systems analysis paper with no equations, fitted parameters, predictive models, or derivation chains. The central claim that NVSHMEM pioneered a device-side symmetric-memory model is presented as a conclusion from reviewing documentation, source code, and application experience (DeepEP), not as a result derived from self-referential definitions or prior self-citations that reduce to the input. No load-bearing self-citation chains, ansatzes, or renamings of known results are present. The work is self-contained as an external review and receives the default non-finding for descriptive studies.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Demystifying parallel and distributed deep learning: An in-depth concurrency analysis,
T. Ben-Nun and T. Hoefler, “Demystifying parallel and distributed deep learning: An in-depth concurrency analysis,”ACM Comput. Surv., vol. 52, Aug. 2019
2019
-
[2]
Towards accelerating smoothed particle hydrodynamics simulations for free-surface flows on multi-gpu clusters,
D. Valdez-Balderas, J. M. Dom ´ınguez, B. D. Rogers, and A. J. Crespo, “Towards accelerating smoothed particle hydrodynamics simulations for free-surface flows on multi-gpu clusters,”Journal of Parallel and Distributed Computing, vol. 73, no. 11, pp. 1483–1493, 2013. Novel architectures for high-performance computing
2013
-
[3]
Multi-gpu and multi-cpu accelerated fdtd scheme for vibroacoustic applications,
J. Franc ´es, B. Otero, S. Bleda, S. Gallego, C. Neipp, A. M ´arquez, and A. Bel ´endez, “Multi-gpu and multi-cpu accelerated fdtd scheme for vibroacoustic applications,”Computer Physics Communications, vol. 191, pp. 43–51, 2015
2015
-
[4]
Multi-gpu fast fourier transforms in matlab (for large-scale phase-field crystal simulations),
M. Punke and M. Salvalaglio, “Multi-gpu fast fourier transforms in matlab (for large-scale phase-field crystal simulations),” 2026
2026
-
[5]
Demystifying nccl: An in-depth analysis of gpu communication protocols and algorithms,
Z. Hu, S. Shen, T. Bonato, S. Jeaugey, C. Alexander, E. Spada, J. Dinan, J. Hammond, and T. Hoefler, “Demystifying nccl: An in-depth analysis of gpu communication protocols and algorithms,” 2026
2026
-
[6]
Pytorch: An imperative style, high- performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. K ¨opf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “Pytorch: An imperative style, high- performance deep learning library,” 2019
2019
-
[7]
Megatron-lm: Training multi-billion parameter language models using model parallelism,
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catan- zaro, “Megatron-lm: Training multi-billion parameter language models using model parallelism,” 2020
2020
-
[8]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” 2023
2023
-
[9]
NVSHMEM APIs,
NVIDIA, “NVSHMEM APIs,” 2025. Documentation verified against version 3.5.19
2025
-
[10]
Scaling scientific computing with nvshmem,
N. Maruyama, B. V . Essen, J. Ciesko, J. Wilke, C. Trott, C.-H. Hsu, N. Imam, J. Dinan, A. Langer, C. Newburn, and S. Potluri, “Scaling scientific computing with nvshmem,” Aug. 2020. NVIDIA Developer Blog
2020
-
[11]
Gpu-initiated networking for nccl,
K. Hamidouche, J. Bachan, P. Markthub, P.-J. Gootzen, E. Agostini, S. Jeaugey, A. Shafi, G. Theodorakis, and M. G. Venkata, “Gpu-initiated networking for nccl,” 2025
2025
-
[12]
Improving Network Performance of HPC Systems Using NVIDIA Magnum IO NVSHMEM and GPUDirect Async,
P. Markthub, J. Dinan, S. Potluri, and S. Howell, “Improving Network Performance of HPC Systems Using NVIDIA Magnum IO NVSHMEM and GPUDirect Async,” 2022. Section: InfiniBand GPUDirect Async
2022
-
[13]
GPU-Centric Communication on NVIDIA GPU Clusters with InfiniBand: A Case Study with OpenSHMEM,
S. Potluri, A. Goswami, D. Rossetti, C. J. Newburn, M. G. Venkata, and N. Imam, “GPU-Centric Communication on NVIDIA GPU Clusters with InfiniBand: A Case Study with OpenSHMEM,” in2017 IEEE 24th International Conference on High Performance Computing (HiPC), pp. 253–262, 2017
2017
-
[14]
GPUDirect RDMA Documentation,
NVIDIA Corporation, “GPUDirect RDMA Documentation,” 2026. Ac- cessed: 2026-04-22
2026
-
[15]
DOCA GPUNetIO Documentation (v3.2.2),
NVIDIA Corporation, “DOCA GPUNetIO Documentation (v3.2.2),”
-
[16]
Last updated: March 23, 2026; Accessed: 2026-04-22
2026
-
[17]
A Theory of Partitioned Global Address Spaces,
G. Calin, E. Derevenetc, R. Majumdar, and R. Meyer, “A Theory of Partitioned Global Address Spaces,”Leibniz International Proceedings in Informatics, vol. 24, 2013
2013
-
[18]
Introducing openshmem: Shmem for the pgas community,
B. Chapman, T. Curtis, S. Pophale, S. Poole, J. Kuehn, C. Koelbel, and L. Smith, “Introducing openshmem: Shmem for the pgas community,” inProceedings of the F ourth Conference on Partitioned Global Address Space Programming Model, PGAS ’10, (New York, NY , USA), Asso- ciation for Computing Machinery, 2010
2010
-
[19]
Remote memory access programming in mpi-3,
T. Hoefler, J. Dinan, R. Thakur, B. Barrett, P. Balaji, W. Gropp, and K. Underwood, “Remote memory access programming in mpi-3,”ACM Trans. Parallel Comput., vol. 2, June 2015
2015
-
[20]
An introduction to cuda-aware mpi,
J. Kraus and J. Kraus, “An introduction to cuda-aware mpi,”NVIDIA Technical Blog, July 2025
2025
-
[21]
MPI: A Message-Passing Interface Standard, Version 5.0,
Message Passing Interface Forum, “MPI: A Message-Passing Interface Standard, Version 5.0,” 2025
2025
-
[22]
UPC++ Wiki
CLaSS Group at Lawrence Berkeley National Laboratory, “UPC++ Wiki.”
-
[23]
GASNet-EX: A High-Performance, Portable Communication Library for Exascale,
D. Bonachea and P. H. Hargrove, “GASNet-EX: A High-Performance, Portable Communication Library for Exascale,” inLanguages and Compilers for Parallel Computing (LCPC’18), Springer, 2018. Lawrence Berkeley National Laboratory Technical Report LBNL-2001174
2018
-
[24]
rocSHMEM - ROCm OpenSHMEM GPU library
Advanced Micro Devices, Inc., “rocSHMEM - ROCm OpenSHMEM GPU library.”
-
[25]
Intel(R) SHMEM: GPU-initiated OpenSHMEM using SYCL,
A. Brooks, P. Marshall, D. Ozog, M. W. ur Rahman, L. Stewart, and R. Tom, “Intel(R) SHMEM: GPU-initiated OpenSHMEM using SYCL,” 2024
2024
-
[26]
GICC: A high-performance runtime for gpu-initiated communication and coordination in modern HPC systems,
B. Shan, M. Araya-Polo, and B. Chapman, “GICC: A high-performance runtime for gpu-initiated communication and coordination in modern HPC systems,” Apr. 2026
2026
-
[27]
Introducing Low-Level GPU Virtual Memory Management,
C. Perry and N. Sakharnykh, “Introducing Low-Level GPU Virtual Memory Management,” 2020
2020
-
[28]
Dynamic symmetric heap allocation in nvshmem,
A. Langer, S. Howell, S. Potluri, J. Dinan, and J. Kraus, “Dynamic symmetric heap allocation in nvshmem,” inOpenSHMEM and Related Technologies. OpenSHMEM in the Era of Exascale and Smart Networks (S. Poole, O. Hernandez, M. Baker, and T. Curtis, eds.), (Cham), pp. 187–198, Springer International Publishing, 2022
2022
-
[29]
NCCL Tests,
NVIDIA, “NCCL Tests,” 2026. Accessed: 2026-05-08
2026
-
[30]
Recent improvement to open mpi allreduce and the impact to application performance,
J. Tang, L. Robison, M. Koop, and W. Wang, “Recent improvement to open mpi allreduce and the impact to application performance,” Sept. 2024
2024
-
[31]
Hear: Homomorphically encrypted allreduce,
M. Chrapek, M. Khalilov, and T. Hoefler, “Hear: Homomorphically encrypted allreduce,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’23, (New York, NY , USA), Association for Computing Machinery,
-
[32]
https://doi.org/10.1145/3581784.3607099
-
[33]
xccl: A survey of industry-led collective communication libraries for deep learning,
A. Weingram, Y . Li, H. Qi, D. Ng, L. Dai, and X. Lu, “xccl: A survey of industry-led collective communication libraries for deep learning,”J. Comput. Sci. Technol., vol. 38, p. 166–195, Mar. 2023. https://doi.org/10.1007/s11390-023-2894-6
-
[34]
Revisiting the time cost model of allreduce,
D. Xiong, L. Chen, Y . Jiang, D. Li, S. Wang, and S. Wang, “Revisiting the time cost model of allreduce,” 2024
2024
-
[35]
Deepep: an efficient expert-parallel communication library,
C. Zhao, S. Zhou, L. Zhang, C. Deng, Z. Xu, Y . Liu, K. Yu, J. Li, and L. Zhao, “Deepep: an efficient expert-parallel communication library,” 2025
2025
-
[36]
An initial assessment of nvshmem for high performance computing,
C.-H. Hsu, N. Imam, A. Langer, S. Potluri, and C. J. Newburn, “An initial assessment of nvshmem for high performance computing,” in2020 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), pp. 1–10, 2020
2020
-
[37]
Redesign- ing gromacs halo exchange: Improving strong scaling with gpu-initiated nvshmem,
M. Doijade, A. Alekseenko, A. Brown, A. Gray, and S. P ´all, “Redesign- ing gromacs halo exchange: Improving strong scaling with gpu-initiated nvshmem,” inProceedings of the SC ’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC Workshops ’25, (New York, NY , USA), p. 1314–1329, Association fo...
2025
-
[38]
Charming: A scalable gpu- resident runtime system,
J. Choi, D. F. Richards, and L. V . Kale, “Charming: A scalable gpu- resident runtime system,” inProceedings of the 30th International Symposium on High-Performance Parallel and Distributed Computing, HPDC ’21, (New York, NY , USA), p. 261–262, Association for Com- puting Machinery, 2021
2021
-
[39]
Gpu initiated openshmem: correct and efficient intra-kernel networking for dgpus,
K. Hamidouche and M. LeBeane, “Gpu initiated openshmem: correct and efficient intra-kernel networking for dgpus,” inProceedings of the 25th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, PPoPP ’20, (New York, NY , USA), p. 336–347, Association for Computing Machinery, 2020
2020
-
[40]
The landscape of gpu-centric communication,
D. Unat, I. Turimbetov, M. K. T. Issa, D. Sa ˘gbili, F. Vella, D. D. Sensi, and I. Ismayilov, “The landscape of gpu-centric communication,” 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.