Not All Timesteps Matter Equally: Selective Alignment Knowledge Distillation for Spiking Neural Networks
Pith reviewed 2026-05-15 02:41 UTC · model grok-4.3
The pith
Spiking neural networks gain accuracy when distillation corrects only erroneous timesteps instead of aligning every one uniformly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
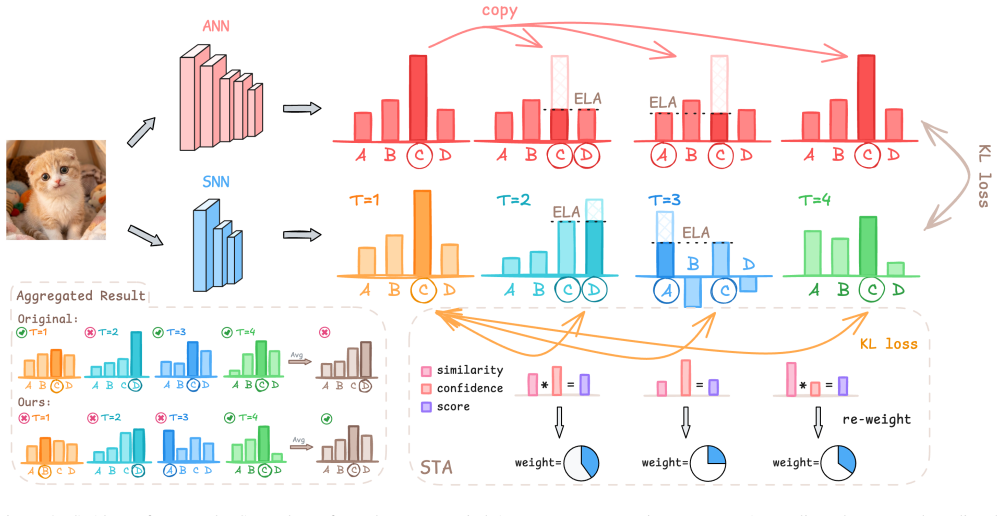
The central claim is that SNN predictions evolve over time and intermediate timesteps need not all be correct; therefore effective distillation must selectively align class-level and temporal knowledge by equalizing competing logits at erroneous timesteps and reweighting the alignment loss according to per-timestep confidence and inter-timestep similarity rather than enforcing uniform supervision across the entire sequence.
What carries the argument
Selective Alignment Knowledge Distillation (SeAl-KD), which identifies erroneous timesteps from the student's outputs, equalizes competing class logits there, and reweights temporal alignment by confidence and similarity.
If this is right
- SNNs reach higher final accuracy on both static-image and neuromorphic datasets while preserving their spike-based computation.
- Temporal dynamics learned by the student are no longer overridden at every step, so useful spike timing patterns survive training.
- The same selective logic can be inserted into other distillation pipelines that operate on sequential or recurrent models.
- No extra network modules or teacher modifications are required beyond the reweighting rule.
Where Pith is reading between the lines
- The reweighting rule based on confidence and similarity may also predict how many timesteps are actually needed for a given task.
- Because identification of errors relies on the student's current outputs, the method could be combined with self-training loops to further reduce dependence on a large teacher.
- If the approach generalizes, it suggests that timestep-wise error detection might improve training efficiency in other energy-constrained temporal architectures.
Load-bearing premise
Erroneous timesteps can be identified reliably from the student's own predictions without introducing new hyperparameters that require extensive retuning across datasets.
What would settle it
Run SeAl-KD on a dataset where random noise is injected so that every timestep's error rate is statistically identical; if accuracy gains disappear or reverse, the selective mechanism is not the source of improvement.
Figures






read the original abstract
Spiking neural networks (SNNs), which are brain-inspired and spike-driven, achieve high energy efficiency. However, a performance gap between SNNs and artificial neural networks (ANNs) still remains. Knowledge distillation (KD) is commonly adopted to improve SNN performance, but existing methods typically enforce uniform alignment across all timesteps, either from a teacher network or through inter-temporal self-distillation, implicitly assuming that per-timestep predictions should be treated equally. In practice, SNN predictions vary and evolve over time, and intermediate timesteps need not all be individually correct even when the final aggregated output is correct. Under such conditions, effective distillation should not force every timestep toward the same supervision target, but instead provide corrective guidance to erroneous timesteps while preserving useful temporal dynamics. To address this issue, we propose Selective Alignment Knowledge Distillation (SeAl-KD), which selectively aligns class-level and temporal knowledge by equalizing competing logits at erroneous timesteps and reweighting temporal alignment based on confidence and inter-timestep similarity. Extensive experiments on static image and neuromorphic event-based datasets demonstrate consistent improvements over existing distillation methods. The code is available at https://github.com/KaiSUN1/SeAl
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing knowledge distillation methods for spiking neural networks enforce uniform alignment across all timesteps, which is suboptimal because SNN predictions evolve over time and intermediate timesteps may be erroneous even if the final output is correct. It proposes Selective Alignment Knowledge Distillation (SeAl-KD), which identifies erroneous timesteps from the student's logits to equalize competing classes and reweights temporal alignment using per-timestep confidence and inter-timestep similarity. Extensive experiments on static image and neuromorphic event-based datasets are reported to show consistent improvements over prior distillation approaches, with code released at the provided GitHub link.
Significance. If the selective alignment mechanism holds under scrutiny, the work could meaningfully advance SNN distillation by avoiding forced alignment on useful temporal dynamics while correcting errors, potentially improving accuracy without additional energy costs. The release of code is a positive factor for reproducibility. Significance is tempered by the need to confirm that the heuristics for timestep selection and reweighting are robust and not artifacts of unablated choices.
major comments (3)
- [§3.2] §3.2: The precise rules for declaring a timestep erroneous (including any thresholds on logit competition or conditions for equalizing classes) are not fully specified in the method definition; this is load-bearing because the central claim of selective rather than uniform alignment depends on reliable identification from the student's own outputs without circularity or new tunable parameters.
- [§3.3] §3.3, Eq. (X): The exact functional form of the reweighting scheme (combining confidence and inter-timestep similarity) and any associated hyperparameters or cutoffs are insufficiently detailed; without this, it is unclear whether the reported gains arise from the selective principle or from dataset-specific tuning of the reweighting function.
- [§4.2] §4.2 and Table 2: Ablation controls isolating the contribution of erroneous-timestep detection versus the reweighting components are missing or incomplete; this undermines the claim that selective alignment yields consistent gains, as the improvements could stem from the particular hyperparameter regime rather than the proposed mechanism.
minor comments (2)
- [§3.3] The notation for temporal similarity in the reweighting term could be clarified with an explicit equation reference to avoid ambiguity in implementation.
- [Figure 3] Figure 3 caption should explicitly state the datasets and baselines used for the visualized accuracy curves to improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We agree that greater precision in the method description and additional ablation studies will strengthen the paper. We will revise the manuscript to address each point below.
read point-by-point responses
-
Referee: [§3.2] §3.2: The precise rules for declaring a timestep erroneous (including any thresholds on logit competition or conditions for equalizing classes) are not fully specified in the method definition; this is load-bearing because the central claim of selective rather than uniform alignment depends on reliable identification from the student's own outputs without circularity or new tunable parameters.
Authors: We agree that the description of erroneous-timestep identification in §3.2 requires additional precision to avoid ambiguity. In the revised manuscript we will add an explicit mathematical definition: a timestep t is declared erroneous if the difference between the top two student logits satisfies max(l_t) - second_max(l_t) < 0.1, where the threshold 0.1 is fixed from validation-set statistics and applied uniformly. We will also include pseudocode showing that the decision uses only the student's own logits at t, with no dependence on the teacher or future timesteps, thereby eliminating circularity. No new tunable parameters are introduced beyond those already present in the baseline KD loss. revision: yes
-
Referee: [§3.3] §3.3, Eq. (X): The exact functional form of the reweighting scheme (combining confidence and inter-timestep similarity) and any associated hyperparameters or cutoffs are insufficiently detailed; without this, it is unclear whether the reported gains arise from the selective principle or from dataset-specific tuning of the reweighting function.
Authors: We acknowledge that the functional form and hyperparameters of the reweighting scheme in §3.3 need to be stated explicitly. In the revision we will replace the current high-level description with the exact equation w_t = α · conf_t + (1-α) · sim(t,t-1), where conf_t is the student's softmax probability of its predicted class at timestep t, sim(t,t-1) is the cosine similarity between the logit vectors at t and t-1, and α = 0.6 is the fixed mixing coefficient used in all experiments. We will also report the sensitivity analysis confirming that performance remains stable for α ∈ [0.4, 0.8]. revision: yes
-
Referee: [§4.2] §4.2 and Table 2: Ablation controls isolating the contribution of erroneous-timestep detection versus the reweighting components are missing or incomplete; this undermines the claim that selective alignment yields consistent gains, as the improvements could stem from the particular hyperparameter regime rather than the proposed mechanism.
Authors: We agree that the current ablation study in §4.2 is incomplete. In the revised version we will add a new table that reports four controlled variants on the same datasets: (i) full SeAl-KD, (ii) erroneous-timestep equalization only (reweighting disabled), (iii) reweighting only (uniform alignment), and (iv) neither. These results will isolate the contribution of each component and demonstrate that both are necessary for the observed gains. revision: yes
Circularity Check
No circularity: SeAl-KD defined procedurally from student logits without reduction to fitted inputs or self-citations
full rationale
The paper's central construction identifies erroneous timesteps directly from the student's logits and applies reweighting by confidence and inter-timestep similarity as an explicit algorithmic rule. This does not equate any prediction or derived quantity to a parameter fitted on the same data, nor does it rely on a self-citation chain for uniqueness or an ansatz smuggled from prior work. The derivation remains self-contained; gains are asserted via external experiments rather than by tautological redefinition of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SNN output at each timestep is produced by a standard integrate-and-fire or similar neuron model whose membrane potential is updated from input spikes.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SeAl-KD ... equalizing competing logits at erroneous timesteps and reweighting temporal alignment based on confidence and inter-timestep similarity
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction (8-tick period) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
T=4, T=6, T=10 inference timesteps on CIFAR/DVS-CIFAR10
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
[Bellecet al., 2018 ] Guillaume Bellec, Darjan Salaj, Anand Subramoney, Robert Legenstein, and Wolfgang Maass. Long short-term memory and learning-to-learn in net- works of spiking neurons.Advances in neural information processing systems, 31,
work page 2018
-
[2]
Imagenet: A large-scale hierarchical image database
[Denget al., 2009 ] Jia Deng, Wei Dong, Richard Socher, Li- Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee,
work page 2009
-
[3]
Temporal efficient training of spiking neural network via gradient re-weighting
[Denget al., 2022 ] Shikuang Deng, Yuhang Li, Shanghang Zhang, and Shi Gu. Temporal efficient training of spiking neural network via gradient re-weighting. InInternational Conference on Learning Representations,
work page 2022
-
[4]
[Duanet al., 2022 ] Chaoteng Duan, Jianhao Ding, Shiyan Chen, Zhaofei Yu, and Tiejun Huang. Temporal effective batch normalization in spiking neural networks.Advances in Neural Information Processing Systems, 35:34377– 34390,
work page 2022
-
[5]
In- corporating learnable membrane time constant to enhance learning of spiking neural networks
[Fanget al., 2021 ] Wei Fang, Zhaofei Yu, Yanqi Chen, Tim- oth´ee Masquelier, Tiejun Huang, and Yonghong Tian. In- corporating learnable membrane time constant to enhance learning of spiking neural networks. InProceedings of the IEEE/CVF international conference on computer vision, pages 2661–2671,
work page 2021
-
[6]
Recdis-snn: Rectifying membrane potential distribution for directly training spiking neural networks
[Guoet al., 2022 ] Yufei Guo, Xinyi Tong, Yuanpei Chen, Liwen Zhang, Xiaode Liu, Zhe Ma, and Xuhui Huang. Recdis-snn: Rectifying membrane potential distribution for directly training spiking neural networks. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 326–335,
work page 2022
-
[7]
[Guoet al., 2023 ] Yufei Guo, Weihang Peng, Yuanpei Chen, Liwen Zhang, Xiaode Liu, Xuhui Huang, and Zhe Ma. Joint a-snn: Joint training of artificial and spiking neu- ral networks via self-distillation and weight factorization. Pattern Recognition, 142:109639,
work page 2023
-
[8]
[Hanet al., 2015 ] Song Han, Jeff Pool, John Tran, and William Dally. Learning both weights and connections for efficient neural network.Advances in neural information processing systems, 28,
work page 2015
-
[9]
[Honget al., 2025 ] Di Hong, Yu Qi, and Yueming Wang. Lasnn: Layer-wise ann-to-snn distillation for effective and efficient training in deep spiking neural networks.Neuro- computing, page 131351,
work page 2025
-
[10]
Learning multiple layers of features from tiny im- ages
[Krizhevskyet al., 2009 ] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny im- ages
work page 2009
-
[11]
Learn- able surrogate gradient for direct training spiking neural networks
[Lianet al., 2023 ] Shuang Lian, Jiangrong Shen, Qianhui Liu, Ziming Wang, Rui Yan, and Huajin Tang. Learn- able surrogate gradient for direct training spiking neural networks. InIJCAI, pages 3002–3010,
work page 2023
-
[12]
[Maass, 1997] Wolfgang Maass. Networks of spiking neu- rons: the third generation of neural network models.Neu- ral networks, 10(9):1659–1671,
work page 1997
-
[13]
Towards memory-and time-efficient backpropagation for training spiking neural networks
[Menget al., 2023 ] Qingyan Meng, Mingqing Xiao, Shen Yan, Yisen Wang, Zhouchen Lin, and Zhi-Quan Luo. Towards memory-and time-efficient backpropagation for training spiking neural networks. InProceedings of the IEEE/CVF international conference on computer vision, pages 6166–6176,
work page 2023
-
[14]
[Neftciet al., 2019 ] Emre O Neftci, Hesham Mostafa, and Friedemann Zenke. Surrogate gradient learning in spik- ing neural networks: Bringing the power of gradient-based optimization to spiking neural networks.IEEE Signal Pro- cessing Magazine, 36(6):51–63,
work page 2019
-
[15]
[Orchardet al., 2015 ] Garrick Orchard, Ajinkya Jayawant, Gregory K Cohen, and Nitish Thakor. Converting static image datasets to spiking neuromorphic datasets using sac- cades.Frontiers in neuroscience, 9:437,
work page 2015
-
[16]
Self-architectural knowledge dis- tillation for spiking neural networks.Neural Networks, 178:106475,
[Qiuet al., 2024 ] Haonan Qiu, Munan Ning, Zeyin Song, Wei Fang, Yanqi Chen, Tao Sun, Zhengyu Ma, Li Yuan, and Yonghong Tian. Self-architectural knowledge dis- tillation for spiking neural networks.Neural Networks, 178:106475,
work page 2024
-
[17]
Adaptive smoothing gradient learning for spiking neural networks
[Wanget al., 2023 ] Ziming Wang, Runhao Jiang, Shuang Lian, Rui Yan, and Huajin Tang. Adaptive smoothing gradient learning for spiking neural networks. InInter- national conference on machine learning, pages 35798– 35816. PMLR,
work page 2023
-
[18]
[Xuet al., 2023 ] Qi Xu, Yaxin Li, Jiangrong Shen, Jian K Liu, Huajin Tang, and Gang Pan. Constructing deep spik- ing neural networks from artificial neural networks with knowledge distillation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7886–7895,
work page 2023
-
[19]
[Xuet al., 2024 ] Zekai Xu, Kang You, Qinghai Guo, Xiang Wang, and Zhezhi He. Bkdsnn: Enhancing the perfor- mance of learning-based spiking neural networks training with blurred knowledge distillation. InEuropean Confer- ence on Computer Vision, pages 106–123. Springer,
work page 2024
-
[20]
[Yanget al., 2025 ] Shu Yang, Chengting Yu, Lei Liu, Hanzhi Ma, Aili Wang, and Erping Li. Efficient ann- guided distillation: Aligning rate-based features of spiking neural networks through hybrid block-wise replacement. InProceedings of the Computer Vision and Pattern Recog- nition Conference, pages 10025–10035,
work page 2025
-
[21]
[Yaoet al., 2022 ] Xingting Yao, Fanrong Li, Zitao Mo, and Jian Cheng. Glif: A unified gated leaky integrate-and-fire neuron for spiking neural networks.Advances in Neural Information Processing Systems, 35:32160–32171,
work page 2022
-
[22]
Spike- driven transformer.Advances in neural information pro- cessing systems, 36:64043–64058,
[Yaoet al., 2023 ] Man Yao, Jiakui Hu, Zhaokun Zhou, Li Yuan, Yonghong Tian, Bo Xu, and Guoqi Li. Spike- driven transformer.Advances in neural information pro- cessing systems, 36:64043–64058,
work page 2023
-
[23]
[Yuet al., 2024 ] Chengting Yu, Lei Liu, Gaoang Wang, Er- ping Li, and Aili Wang. Advancing training efficiency of deep spiking neural networks through rate-based back- propagation.Advances in Neural Information Processing Systems, 37:115786–115815,
work page 2024
-
[24]
[Zhanget al., 2025 ] Tianqing Zhang, Zixin Zhu, Kairong Yu, and Hongwei Wang. Head-tail-aware kl divergence in knowledge distillation for spiking neural networks.arXiv preprint arXiv:2504.20445,
-
[25]
[Zhaoet al., 2025 ] Dongcheng Zhao, Guobin Shen, Yiting Dong, Yang Li, and Yi Zeng. Improving stability and per- formance of spiking neural networks through enhancing temporal consistency.Pattern Recognition, 159:111094,
work page 2025
-
[26]
Going deeper with directly-trained larger spiking neural networks
[Zhenget al., 2021 ] Hanle Zheng, Yujie Wu, Lei Deng, Yi- fan Hu, and Guoqi Li. Going deeper with directly-trained larger spiking neural networks. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 11062–11070,
work page 2021
-
[27]
Spikformer: When spiking neural network meets transformer
[Zhouet al., 2023 ] Zhaokun Zhou, Yuesheng Zhu, Chao He, Yaowei Wang, Shuicheng Y AN, Yonghong Tian, and Li Yuan. Spikformer: When spiking neural network meets transformer. InThe Eleventh International Conference on Learning Representations,
work page 2023
-
[28]
[Zuoet al., 2024 ] Lin Zuo, Yongqi Ding, Mengmeng Jing, Kunshan Yang, and Yunqian Yu. Self-distillation learning based on temporal-spatial consistency for spiking neural networks.arXiv preprint arXiv:2406.07862,
-
[29]
Statistics are computed from five randomly selected samples and reported as mean±std
Figure 7: Layer-wise statistics over all timesteps for the three propositions: (a) the fraction of the ELA update assigned to the ground-truth class and the dominant false class at erroneous timesteps; (b) the cosine similarity between the STA update and the direction that reduces the gap to reliability-weighted temporal references at weak timesteps; (c) ...
work page 2009
-
[30]
E Energy Consumption Analysis To quantify the computational energy cost of SNNs, we fol- low a commonly adopted evaluation protocol in neuromor- phic computing, which characterizes energy consumption in terms of synaptic operations [Zhouet al., 2023 ]. Specifically, the overall synaptic operation power (SOP) is modeled as the weighted sum of accumulation ...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.