HydraHead: From Head-Level Functional Heterogeneity to Specialized Attention Hybridization
Pith reviewed 2026-06-26 17:20 UTC · model grok-4.3
The pith
HydraHead replaces full attention with linear attention in most heads while keeping full attention only in a small set of retrieval-critical heads selected by interpretability analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
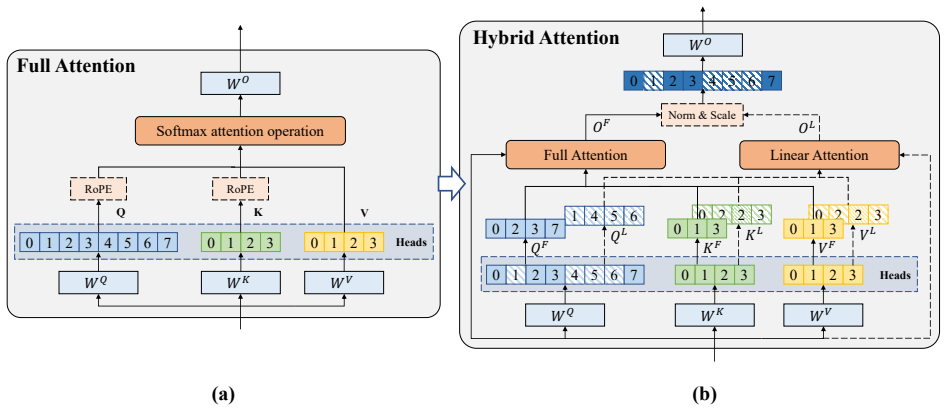
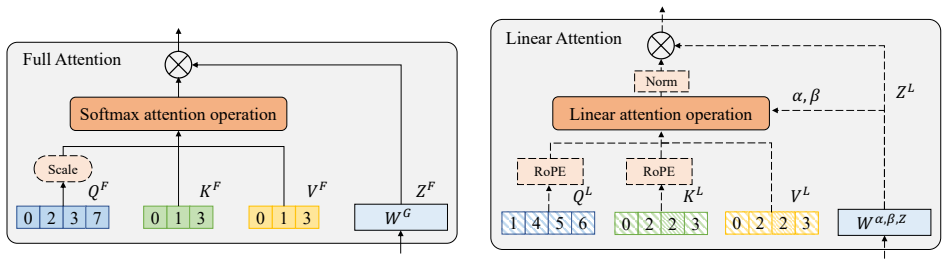
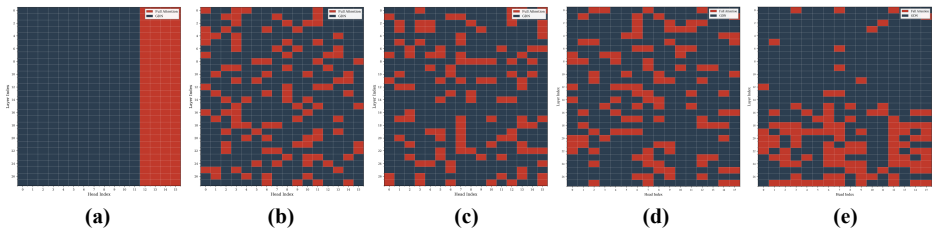
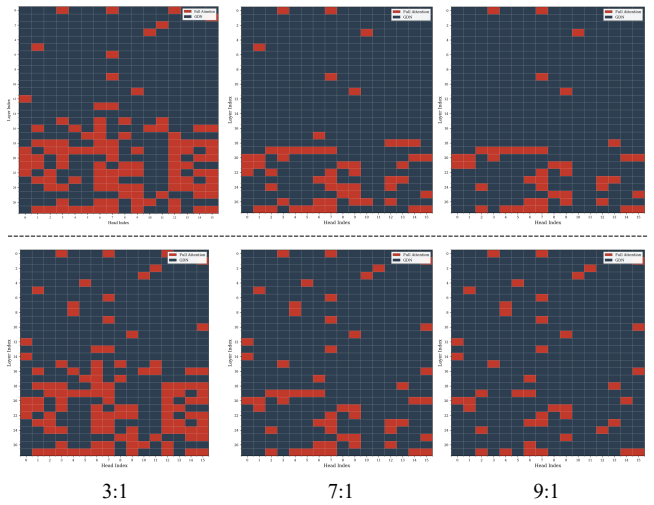
The paper claims that head-level functional heterogeneity supplies a natural granularity for attention hybridization. Interpretability analysis identifies a stable subset of retrieval-critical heads; full attention is retained only for those heads while linear attention is substituted for the remainder. A scale-normalized fusion module aligns the differing output distributions. The resulting HydraHead model, constructed via a three-stage transfer pipeline, matches the long-context performance of a 3:1 layer-wise hybrid at a 7:1 linear-to-full ratio and records more than 69 percent improvement over the baseline at 512K context after training on 15B tokens.
What carries the argument
Head-level hybridization that preserves full attention exclusively for interpretability-selected retrieval-critical heads and fuses their outputs with linear-attention heads through a scale-normalized module.
If this is right
- HydraHead matches the long-context performance of a 3:1 layer-wise hybrid at a 7:1 linear-to-full attention ratio.
- The model records over 69 percent improvement over the baseline at 512K context length after training on only 15B tokens.
- General reasoning capability remains strong while long-context tasks improve relative to other hybrid designs.
- The three-stage transfer pipeline with parameter reuse and distillation produces competitive hybrids at low training cost.
Where Pith is reading between the lines
- If the same heads remain retrieval-critical across different model scales, the selection procedure could be reused with little re-analysis.
- The head-level split might combine with other efficiency methods such as sparse or windowed attention on the linear heads.
- Extending the interpretability scan to even longer contexts could reveal whether additional heads become critical beyond 512K.
Load-bearing premise
The interpretability analysis reliably identifies a stable set of retrieval-critical heads whose functional specialization justifies preserving full attention only for them while safely replacing the rest with linear attention.
What would settle it
An ablation that randomly assigns full attention to an equal number of heads instead of the interpretability-selected set and then measures whether 512K-context performance falls to the level of a standard layer-wise hybrid would falsify the necessity of the selection step.
Figures






read the original abstract
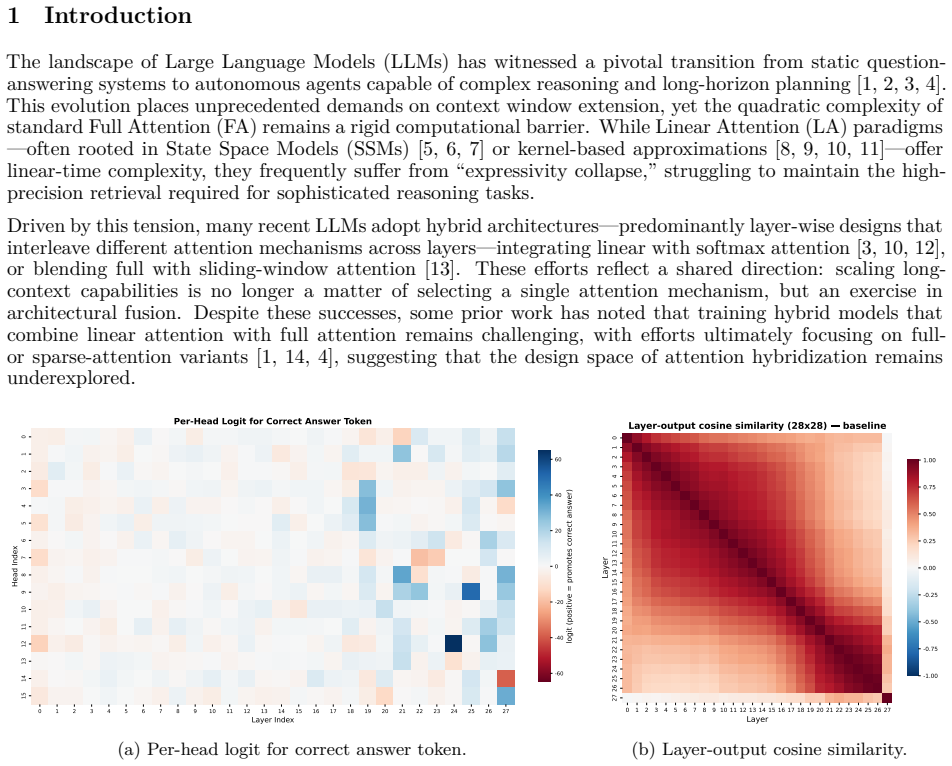
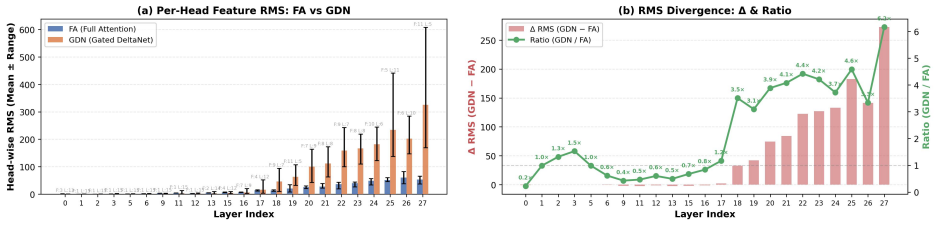
The quadratic complexity of attention poses a critical bottleneck for long-context processing, spurring interest in hybrid attention designs. Most open-source hybrid models adopt a layer-wise strategy. Yet, prior work has noted the inherent difficulty of integrating Linear Attention (LA) with Full Attention (FA), suggesting that the design space of attention hybridization remains underexplored. To probe this space, we conduct interpretability analysis and observe that layers exhibit block-wise functional similarity, while individual heads within the same layer display distinct functional specialization despite sharing input features. This head-level heterogeneity suggests that the head dimension provides a natural and principled granularity for fusing heterogeneous attention signals. Building on this insight, we introduce HydraHead, a novel architecture that hybridizes FA and LA along the head axis. HydraHead features two key innovations: (1) an interpretability-driven selection strategy that identifies retrieval-critical heads and preserves FA only for them, and (2) a scale-normalized fusion module that reconciles the distributional gap between FA and LA head outputs. By leveraging a three-stage transfer pipeline with parameter reuse and distillation, we achieve high-performance hybrid models with minimal training overhead. Under a unified training setup, HydraHead outperforms other hybrid designs in long-context tasks while maintaining strong general reasoning. With interpretability-driven head selection, it matches a 3:1 layer-wise hybrid's long-context performance at a 7:1 LA-to-FA ratio. Crucially, trained on only 15B tokens, HydraHead achieves over 69% improvement over the baseline at 512K context length, approaching Qwen3.5, a leading model of comparable size with a native context length of 256K. This highlights the significant scaling potential of head-level hybridization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that head-level functional heterogeneity (distinct specialization despite shared inputs, with block-wise layer similarity) justifies a head-axis hybrid of full attention (FA) and linear attention (LA). HydraHead uses an interpretability-driven strategy to preserve FA only on a small set of retrieval-critical heads (7:1 LA:FA ratio), a scale-normalized fusion module, and a three-stage transfer pipeline with reuse/distillation. Under unified training on 15B tokens it matches 3:1 layer-wise hybrids on long-context tasks, delivers >69% gain over baseline at 512K context, and approaches Qwen3.5 while preserving general reasoning.
Significance. If the interpretability pipeline reliably isolates a stable, generalizable subset of retrieval-critical heads, head-level hybridization would expand the design space beyond layer-wise hybrids and enable higher LA ratios with limited training cost, offering a practical route to longer-context models.
major comments (2)
- [Interpretability-driven selection strategy (abstract and associated sections)] The central empirical claims (matching 3:1 layer-wise performance at 7:1 ratio; 69% gain at 512K after 15B tokens) rest on the premise that interpretability analysis identifies a stable set of retrieval-critical heads whose specialization justifies keeping FA only for them. No method, quantitative criterion for 'retrieval-critical,' stability metrics across layers/seeds/models, or ablation against random/alternative selections is described; without this evidence the performance numbers cannot be evaluated as support for the head-level claim.
- [Scale-normalized fusion module] The scale-normalized fusion module is presented as reconciling the distributional gap between FA and LA outputs, yet no equations, ablation on normalization variants, or analysis of residual mismatch after fusion are supplied; this component is load-bearing for any claim that head-level mixing preserves performance.
minor comments (2)
- The abstract reports 'over 69% improvement' and 'approaching Qwen3.5' without specifying the exact baseline, metric, or context-length scaling curve; adding these details would improve readability.
- Notation for the three-stage transfer pipeline (parameter reuse, distillation) is introduced without a diagram or pseudocode; a figure would clarify the minimal-training-overhead claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional methodological detail will strengthen the manuscript. We address each major comment below and will incorporate the requested clarifications and supporting analyses in the revision.
read point-by-point responses
-
Referee: [Interpretability-driven selection strategy (abstract and associated sections)] The central empirical claims (matching 3:1 layer-wise performance at 7:1 ratio; 69% gain at 512K after 15B tokens) rest on the premise that interpretability analysis identifies a stable set of retrieval-critical heads whose specialization justifies keeping FA only for them. No method, quantitative criterion for 'retrieval-critical,' stability metrics across layers/seeds/models, or ablation against random/alternative selections is described; without this evidence the performance numbers cannot be evaluated as support for the head-level claim.
Authors: We agree that the current manuscript lacks sufficient detail on the interpretability pipeline. In the revision we will add: (i) the precise interpretability method and quantitative criterion used to label heads as retrieval-critical, (ii) stability metrics computed across layers, random seeds, and model scales, and (iii) ablations that compare the selected heads against random selection and alternative criteria. These additions will allow direct evaluation of whether the reported gains support the head-level hybridization claim. revision: yes
-
Referee: [Scale-normalized fusion module] The scale-normalized fusion module is presented as reconciling the distributional gap between FA and LA outputs, yet no equations, ablation on normalization variants, or analysis of residual mismatch after fusion are supplied; this component is load-bearing for any claim that head-level mixing preserves performance.
Authors: We concur that the fusion module requires fuller documentation. The revised manuscript will supply the explicit equations for scale normalization and fusion, ablations across multiple normalization variants, and quantitative analysis of any remaining distributional mismatch after fusion. These results will clarify the module's contribution to maintaining performance under head-level mixing. revision: yes
Circularity Check
No circularity: architecture justified by independent empirical observation, results from training
full rationale
The paper's chain proceeds from an interpretability analysis (observing head-level heterogeneity) to an architectural proposal (head-wise FA/LA split with selection strategy), then to a three-stage training pipeline and benchmark evaluation. No equations, fitted parameters, or self-citations are shown reducing the performance claims to inputs by construction. The selection strategy is presented as driven by the analysis rather than defined in terms of the final metrics, and the 69% improvement and 7:1 ratio are reported outcomes under a unified training setup, not tautological. This is a standard empirical architecture paper with no load-bearing self-citation or self-definitional steps in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Glm-5: from vibe coding to agentic engineering, 2026
GLM-5-Team, :, Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, Chenzheng Zhu, Congfeng Yin, Cunxiang Wang, Gengzheng Pan, Hao Zeng, Haoke Zhang, Haoran Wang, Huilong Chen, Jiajie Zhang, Jian Jiao, Jiaqi Guo, Jingsen Wang, Jingzhao Du, Jinzhu Wu, Kedong Wang, Lei Li, Lin Fan, Lucen Zho...
2026
-
[2]
Kimi Team, Yifan Bai, Yiping Bao, Y. Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, Kelin Fu, Bofei Gao, Chenxiao Gao, Hongcheng Gao, Peizhong Ga...
2026
-
[3]
Qwen3.5: Towards native multimodal agents
Qwen Team. Qwen3.5: Towards native multimodal agents. https://qwen.ai/blog, April 2026. Official Blog Post
2026
-
[4]
Deepseek-v4: Towards highly efficient million-token context intelligence
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence. https: //huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf , April 2026. Tech- nical Report
2026
-
[5]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752 , 2023
Pith/arXiv arXiv 2023
-
[6]
Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality
Tri Dao and Albert Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. In International Conference on Machine Learning (ICML) , 2024
2024
-
[7]
Li, Berlin Chen, Caitlin Wang, A viv Bick, J
Aakash Lahoti, Kevin Y. Li, Berlin Chen, Caitlin Wang, A viv Bick, J. Zico Kolter, Tri Dao, and Albert Gu. Mamba-3: Improved sequence modeling using state space principles, 2026
2026
-
[8]
Linear transformers are secretly fast weight programmers, 2021
Imanol Schlag, Kazuki Irie, and Jürgen Schmidhuber. Linear transformers are secretly fast weight programmers, 2021
2021
-
[9]
Gated delta networks: Improving mamba2 with delta rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule. In The Thirteenth International Conference on Learning Representations , 2025
2025
-
[10]
Kimi Team, Yu Zhang, Zongyu Lin, Xingcheng Yao, Jiaxi Hu, Fanqing Meng, Chengyin Liu, Xin Men, Songlin Yang, Zhiyuan Li, Wentao Li, Enzhe Lu, Weizhou Liu, Yanru Chen, Weixin Xu, Longhui Yu, Yejie Wang, Yu Fan, Longguang Zhong, Enming Yuan, Dehao Zhang, Yizhi Zhang, T. Y. Liu, Haiming Wang, Shengjun Fang, Weiran He, Shaowei Liu, Yiwei Li, Jianlin Su, Jiezh...
2025
-
[11]
Gated deltanet-2: Decoupling erase and write in linear attention, 2026
Ali Hatamizadeh, Yejin Choi, and Jan Kautz. Gated deltanet-2: Decoupling erase and write in linear attention, 2026
2026
-
[12]
Minimax-m1: Scaling test-time compute efficiently with lightning attention, 2025
MiniMax, :, Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, Chengjun Xiao, Chengyu Du, Chi Zhang, Chu Qiao, Chun- hao Zhang, Chunhui Du, Congchao Guo, Da Chen, Deming Ding, Dianjun Sun, Dong Li, Enwei Jiao, Haigang Zhou, Haimo Zhang, Han Ding, Haohai Sun, Haoyu Feng, Huaiguang Cai, Haichao...
2025
-
[13]
Mimo-v2-flash technical report, 2026
Core Team, Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, Gang Xie, Hailin Zhang, Hanglong Lv, Hanyu Li, Heyu Chen, Hongshen Xu, Houbin Zhang, Huaqiu Liu, Jiangshan Duo, Jianyu Wei, Jiebao Xiao, Jinhao Dong, Jun Shi, Junhao Hu, Kainan Bao, Kang Zhou, Lei Li, Liang Zhao, Linghao Zhang,...
2026
-
[14]
The minimax-m2 series: Mini activations unleashing max real-world intelligence, 2026
MiniMax, :, Aili Chen, Aonian Li, Baichuan Zhou, Bangwei Gong, Binyang Jiang, Boji Dan, Changqing Yu, Chao Wang, Cheng Ma, Cheng Zhong, Cheng Zhu, Chengjun Xiao, Chengyi Yang, Chengyu Du, Chenyang Zhang, Chi Zhang, Chuangyi Huang, Chunhao Zhang, Chunhui Du, Chunyu Zhao, Congchao Guo, Da Chen, Deming Ding, Dianjun Sun, Dongyu Zhang, Enhui Yang, Fei Yu, Gua...
2026
-
[15]
A math- ematical framework for transformer circuits
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tristan Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Scott Laskin, Scott Lee, Duane Lindner, Matt Maskey, Parker Nicholson, Karina Nguyen, Ethan P...
2021
-
[16]
Interpretabil- ity in the wild: a circuit for indirect object identification in gpt-2 small, 2022
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretabil- ity in the wild: a circuit for indirect object identification in gpt-2 small, 2022
2022
-
[17]
Govande, Bowen Baker, and Dan Mossing
Leo Gao, Achyuta Rajaram, Jacob Coxon, Soham V. Govande, Bowen Baker, and Dan Mossing. Weight- sparse transformers have interpretable circuits. CoRR, abs/2511.13653, 2025
arXiv 2025
-
[18]
Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, et al. Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet. arXiv preprint arXiv:2605.29358 , 2026
Pith/arXiv arXiv 2026
-
[19]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders. In The Thirteenth International Conference on Learning Representations, ICLR 2025 . OpenReview.net, 2025. 27
2025
-
[20]
Dragan, Rohin Shah, and Neel Nanda
Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, János Kramár, Anca D. Dragan, Rohin Shah, and Neel Nanda. Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2. CoRR, abs/2408.05147, 2024
Pith/arXiv arXiv 2024
-
[21]
On the biology of a large language model
Jack Lindsey, Wes Gurnee, Emmanuel Ameisen, Brian Chen, Adam Pearce, Nicholas L Turner, and Joshua Batson. On the biology of a large language model. Transformer Circuits Thread, 2025
2025
-
[22]
Emergent introspective awareness in large language models
Jack Lindsey. Emergent introspective awareness in large language models. CoRR, abs/2601.01828, 2026
arXiv 2026
-
[23]
Emotion concepts and their function in a large language model
Nicholas Sofroniew, Isaac Kauvar, William Saunders, Runjin Chen, Tom Henighan, Sasha Hydrie, Craig Citro, Adam Pearce, Julius Tarng, Wes Gurnee, Joshua Batson, Sam Zimmerman, Kelley Rivoire, Kyle Fish, Chris Olah, and Jack Lindsey. Emotion concepts and their function in a large language model. CoRR, abs/2604.07729, 2026
Pith/arXiv arXiv 2026
-
[24]
Analyzing multi-head self- attention: Specialized heads do the heavy lifting, the rest can be pruned, 2019
Elena Voita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. Analyzing multi-head self- attention: Specialized heads do the heavy lifting, the rest can be pruned, 2019
2019
-
[25]
Are sixteen heads really better than one?, 2019
Paul Michel, Omer Levy, and Graham Neubig. Are sixteen heads really better than one?, 2019
2019
-
[26]
Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. What does bert look at? an analysis of bert’s attention, 2019
2019
-
[27]
Interpreting and improving large language models in arithmetic calculation, 2024
Wei Zhang, Chaoqun Wan, Yonggang Zhang, Yiu ming Cheung, Xinmei Tian, Xu Shen, and Jieping Ye. Interpreting and improving large language models in arithmetic calculation, 2024
2024
-
[28]
From yes-men to truth-tellers: Addressing sycophancy in large language models with pinpoint tuning, 2025
Wei Chen, Zhen Huang, Liang Xie, Binbin Lin, Houqiang Li, Le Lu, Xinmei Tian, Deng Cai, Yonggang Zhang, Wenxiao Wang, Xu Shen, and Jieping Ye. From yes-men to truth-tellers: Addressing sycophancy in large language models with pinpoint tuning, 2025
2025
-
[29]
Dissecting recall of factual asso- ciations in auto-regressive language models
Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. Dissecting recall of factual asso- ciations in auto-regressive language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023 , pages 12216–12235. Assoc...
2023
-
[30]
Similarity of neural network representations revisited, 2019
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited, 2019
2019
-
[31]
Do vision transformers see like convolutional neural networks?, 2022
Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, and Alexey Dosovitskiy. Do vision transformers see like convolutional neural networks?, 2022
2022
-
[32]
Still: Selecting tokens for intra-layer hybrid attention to linearize llms, 2026
Weikang Meng, Liangyu Huo, Yadan Luo, Jiawen Guan, Jingyi Zhang, Yingjian Li, and Zheng Zhang. Still: Selecting tokens for intra-layer hybrid attention to linearize llms, 2026
2026
-
[33]
Norm×direction: Restoring the missing query norm in vision linear attention, 2026
Weikang Meng, Yadan Luo, Liangyu Huo, Yingjian Li, Yaowei Wang, Xin Li, and Zheng Zhang. Norm×direction: Restoring the missing query norm in vision linear attention, 2026
2026
-
[34]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
2025
-
[35]
How to use and interpret activation patching, 2024
Stefan Heimersheim and Neel Nanda. How to use and interpret activation patching, 2024
2024
-
[36]
Locating and editing factual associa- tions in gpt, 2023
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associa- tions in gpt, 2023
2023
-
[37]
Transformers are rnns: Fast autoregressive transformers with linear attention, 2020
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention, 2020. 28
2020
-
[38]
Nemotron-flash: Towards latency-optimal hybrid small language models
Yonggan Fu, Xin Dong, Shizhe Diao, Matthijs Van Keirsbilck, Hanrong Ye, Wonmin Byeon, Yashaswi Karnati, Lucas Liebenwein, Han Zhang, Nikolaus Binder, Maksim Khadkevich, Alexander Keller, Jan Kautz, Yingyan Lin, and Pavlo Molchanov. Nemotron-flash: Towards latency-optimal hybrid small language models. ArXiv, abs/2511.18890, 2025
arXiv 2025
-
[39]
NVIDIA, :, Aakshita Chandiramani, Aaron Blakeman, Abdullahi Olaoye, Abhibha Gupta, Abhilash Somasamudramath, Abhinav Khattar, Adeola Adesoba, Adi Renduchintala, Adil Asif, Aditya Agrawal, Aditya Vavre, Ahmad Kiswani, Aishwarya Padmakumar, Ajay Hotchandani, Akanksha Shukla, Akhiad Bercovich, Aleksander Ficek, Aleksandr Shaposhnikov, Alex Gronskiy, Alex Kon...
2026
-
[40]
Smith, Hannaneh Hajishirzi, and Ashish Sabharwal
William Merrill, Yanhong Li, Tyler Romero, Anej Svete, Caia Costello, Pradeep Dasigi, Dirk Groeneveld, David Heineman, Bailey Kuehl, Nathan Lambert, Chuan Li, Kyle Lo, Saumya Malik, DJ Matusz, Benjamin Minixhofer, Jacob Morrison, Luca Soldaini, Finbarr Timbers, Pete Walsh, Noah A. Smith, Hannaneh Hajishirzi, and Ashish Sabharwal. Olmo hybrid: From theory ...
2026
-
[41]
Native hybrid attention for efficient sequence modeling, 2026
Jusen Du, Jiaxi Hu, Tao Zhang, Weigao Sun, and Yu Cheng. Native hybrid attention for efficient sequence modeling, 2026
2026
-
[42]
Switch attention: Towards dynamic and fine-grained hybrid transformers, 2026
Yusheng Zhao, Hourun Li, Bohan Wu, Yichun Yin, Lifeng Shang, Jingyang Yuan, Meng Zhang, and Ming Zhang. Switch attention: Towards dynamic and fine-grained hybrid transformers, 2026
2026
-
[43]
Liger: Linearizing large language models to gated recurrent structures
Disen Lan, Weigao Sun, Jiaxi Hu, Jusen Du, and Yu Cheng. Liger: Linearizing large language models to gated recurrent structures. In Proceedings of the International Conference on Machine Learning (ICML). PMLR, 2025
2025
-
[44]
Duoattention: Efficient long-context llm inference with retrieval and streaming heads, 2024
Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, Junxian Guo, Shang Yang, Haotian Tang, Yao Fu, and Song Han. Duoattention: Efficient long-context llm inference with retrieval and streaming heads, 2024
2024
-
[45]
Elastic attention: Test-time adaptive sparsity ratios for efficient transformers, 2026
Zecheng Tang, Quantong Qiu, Yi Yang, Zhiyi Hong, Haiya Xiang, Kebin Liu, Qingqing Dang, Juntao Li, and Min Zhang. Elastic attention: Test-time adaptive sparsity ratios for efficient transformers, 2026
2026
-
[46]
Hymba: A hybrid-head architecture for small language models, 2024
Xin Dong, Yonggan Fu, Shizhe Diao, Wonmin Byeon, Zijia Chen, Ameya Sunil Mahabaleshwarkar, Shih-Yang Liu, Matthijs Van Keirsbilck, Min-Hung Chen, Yoshi Suhara, Yingyan Lin, Jan Kautz, and Pavlo Molchanov. Hymba: A hybrid-head architecture for small language models, 2024. 30
2024
-
[47]
Jungo Kasai, Hao Peng, Yizhe Zhang, Dani Yogatama, Gabriel Ilharco, Nikolaos Pappas, Yi Mao, Weizhu Chen, and Noah A. Smith. Finetuning pretrained transformers into rnns, 2021
2021
-
[48]
Radlads: Rapid attention distillation to linear attention decoders at scale, 2026
Daniel Goldstein, Eric Alcaide, Janna Lu, and Eugene Cheah. Radlads: Rapid attention distillation to linear attention decoders at scale, 2026
2026
-
[49]
Li, Eric P
A viv Bick, Kevin Y. Li, Eric P. Xing, J. Zico Kolter, and Albert Gu. Transformers to ssms: Distilling quadratic knowledge to subquadratic models, 2025
2025
-
[50]
Lolcats: On low-rank linearizing of large language models, 2025
Michael Zhang, Simran Arora, Rahul Chalamala, Alan Wu, Benjamin Spector, Aaryan Singhal, Krithik Ramesh, and Christopher Ré. Lolcats: On low-rank linearizing of large language models, 2025
2025
-
[51]
Attention to mamba: A recipe for cross-architecture distillation, 2026
Abhinav Moudgil, Ningyuan Huang, Eeshan Gunesh Dhekane, Pau Rodríguez, Luca Zappella, and Federico Danieli. Attention to mamba: A recipe for cross-architecture distillation, 2026
2026
-
[52]
Distilling to hybrid attention models via kl-guided layer selection, 2025
Yanhong Li, Songlin Yang, Shawn Tan, Mayank Mishra, Rameswar Panda, Jiawei Zhou, and Yoon Kim. Distilling to hybrid attention models via kl-guided layer selection, 2025
2025
-
[53]
Hybrid linear attention done right: Efficient distillation and effective archi- tectures for extremely long contexts, 2026
Yingfa Chen, Zhen Leng Thai, Zihan Zhou, Zhu Zhang, Xingyu Shen, Shuo Wang, Chaojun Xiao, Xu Han, and Zhiyuan Liu. Hybrid linear attention done right: Efficient distillation and effective archi- tectures for extremely long contexts, 2026
2026
-
[54]
Gqa: Training generalized multi-query transformer models from multi-head checkpoints, 2023
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints, 2023
2023
-
[55]
Towards best practices of activation patching in language models: Metrics and methods, 2024
Fred Zhang and Neel Nanda. Towards best practices of activation patching in language models: Metrics and methods, 2024
2024
-
[56]
Attribution patching: Activation patching at industrial scale
Neel Nanda. Attribution patching: Activation patching at industrial scale. https://www.neelnanda. io/mechanistic-interpretability/attribution-patching , 2023. Blog post
2023
-
[57]
Extending the context of pretrained llms by dropping their positional embeddings, 2025
Yoav Gelberg, Koshi Eguchi, Takuya Akiba, and Edoardo Cetin. Extending the context of pretrained llms by dropping their positional embeddings, 2025
2025
-
[58]
Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free, 2025
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free, 2025
2025
-
[59]
Efficient streaming language models with attention sinks, 2024
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks, 2024
2024
-
[60]
The fineweb datasets: Decanting the web for the finest text data at scale, 2024
Guilherme Penedo, Hynek Kydlíček, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale, 2024
2024
-
[61]
Ruler: What’s the real context size of your long-context language models?, 2024
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?, 2024
2024
-
[62]
Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018
2018
-
[63]
Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Compu- tational Linguistics , 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Compu- tational Linguistics , 2019
2019
-
[64]
Winogrande: An adversarial winograd schema challenge at scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. arXiv preprint arXiv:1907.10641 , 2019
Pith/arXiv arXiv 1907
-
[65]
Piqa: Reasoning about physical commonsense in natural language, 2019
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language, 2019
2019
-
[66]
The lambada dataset: Word prediction requiring a broad discourse context, 2016
Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The lambada dataset: Word prediction requiring a broad discourse context, 2016. 31
2016
-
[67]
Measuring massive multitask language understanding, 2021
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding, 2021
2021
-
[68]
Train- ing verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Train- ing verifiers to solve math word problems, 2021
2021
-
[69]
Program synthesis with large language models, 2021
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models, 2021
2021
-
[70]
Le, Ed H
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V. Le, Ed H. Chi, Denny Zhou, and Jason Wei. Challenging big-bench tasks and whether chain-of-thought can solve them, 2022
2022
-
[71]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, A viya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The langua...
2024
-
[72]
Various lengths, constant speed: Efficient language modeling with lightning attention, 2024
Zhen Qin, Weigao Sun, Dong Li, Xuyang Shen, Weixuan Sun, and Yiran Zhong. Various lengths, constant speed: Efficient language modeling with lightning attention, 2024
2024
-
[73]
Mixed precision train- ing, 2018
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu. Mixed precision train- ing, 2018
2018
-
[74]
Minicpm: Unveiling the potential of small language models with scalable training strategies, 2024
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, Xinrong Zhang, Zheng Leng Thai, Kaihuo Zhang, Chongyi Wang, Yuan Yao, Chenyang Zhao, Jie Zhou, Jie Cai, Zhongwu Zhai, Ning Ding, Chao Jia, Guoyang Zeng, Dahai Li, Zhiyuan Liu, and Maosong Sun. Minicpm: Unveiling the potential of small langu...
2024
-
[75]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Bey...
2025
-
[76]
Jet-nemotron: Efficient language model with post neural architecture search
Yuxian Gu, Qinghao Hu, Shang Yang, Haocheng Xi, Junyu Chen, Song Han, and Han Cai. Jet-nemotron: Efficient language model with post neural architecture search. arXiv preprint arXiv:2508.15884 , 2025. 33 A More Details of Various Hybrid Architectures To comprehensively evaluate the efficacy of different hybridization strategies, we construct and compare thre...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.