Low Light Image Enhancement Challenge at NTIRE 2026
Pith reviewed 2026-05-19 18:18 UTC · model grok-4.3
The pith
The NTIRE 2026 Low Light Image Enhancement Challenge shows clear progress in restoring details from low-contrast and noisy images via 22 submitted networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that the submitted solutions in the NTIRE 2026 challenge achieve meaningful gains in producing clearer images from low-light inputs by learning representative visual cues to compensate for contrast loss and noise, as demonstrated through evaluation on the authors' new dataset.
What carries the argument
The novel low-light dataset paired with the 22 submitted neural networks that perform joint enhancement and denoising.
Load-bearing premise
The 22 submitted entries together with the novel dataset give a representative view of current capabilities in low-light enhancement.
What would settle it
New methods that clearly outperform all 22 entries when tested on the same dataset, or independent tests showing the dataset misses common real-world low-light degradations.
Figures


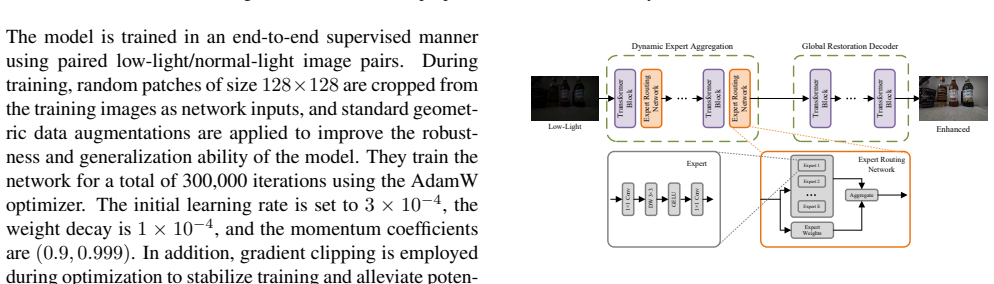





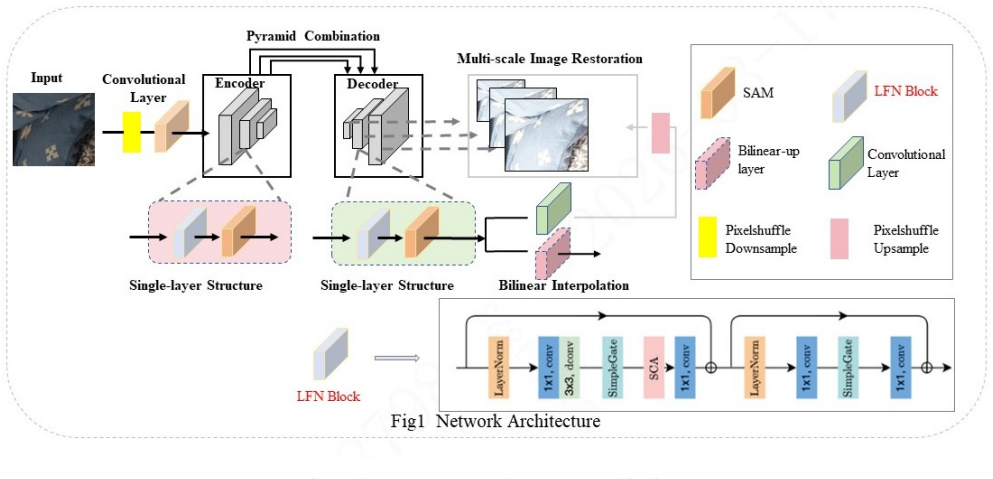







read the original abstract
This paper presents a comprehensive review of the NTIRE 2026 Low Light Image Enhancement Challenge, highlighting the proposed solutions and final results. The objective of this challenge is to identify effective networks capable of producing clearer and visually compelling images in diverse and challenging conditions by learning representative visual cues with the purpose of restoring information loss due to low-contrast and noisy images. A total of 195 participants registered for the first track and 153 for the second track of the competition, and 22 teams ultimately submitted valid entries. This paper thoroughly evaluates the state-of-the-art advances in (joint denoising and) low-light image enhancement, showcasing the significant progress in the field, while leveraging samples of our novel dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports on the NTIRE 2026 Low Light Image Enhancement Challenge, stating that 195 participants registered for track 1 and 153 for track 2, with 22 teams submitting valid entries. It claims to present a comprehensive review of proposed solutions and final results while thoroughly evaluating state-of-the-art advances in low-light (and joint denoising) image enhancement and demonstrating significant progress via a novel dataset.
Significance. A well-documented challenge report with quantitative rankings, method summaries, and bias checks could usefully record community progress on low-light enhancement; the current text provides registration/submission counts but little evidence that the 22 entries or dataset yield a representative or unbiased assessment of capabilities.
major comments (2)
- Abstract: the assertion that the paper 'thoroughly evaluates the state-of-the-art advances ... showcasing the significant progress' is unsupported, as the text supplies only registration (195/153) and submission (22) counts without performance metrics, rankings, error analysis, or comparisons to prior challenges or external baselines on the same test set.
- Challenge setup / results sections: no quantitative verification of the evaluation protocol (e.g., overfitting checks, noise-distribution statistics, or cross-dataset transfer) is described, leaving the claim that the novel dataset plus self-selected entries give a representative picture of current capabilities untested.
minor comments (1)
- Abstract: the parenthetical '(joint denoising and)' is unclear; specify whether the two tracks are separate or joint and how this affects the reported progress.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript reporting the NTIRE 2026 Low Light Image Enhancement Challenge. We have revised the abstract for greater precision and strengthened the challenge setup and results sections with additional quantitative details on the evaluation protocol.
read point-by-point responses
-
Referee: Abstract: the assertion that the paper 'thoroughly evaluates the state-of-the-art advances ... showcasing the significant progress' is unsupported, as the text supplies only registration (195/153) and submission (22) counts without performance metrics, rankings, error analysis, or comparisons to prior challenges or external baselines on the same test set.
Authors: We acknowledge that the original abstract wording could overstate the scope of analysis provided. The manuscript includes a dedicated results section presenting quantitative rankings, PSNR and SSIM metrics for all 22 valid submissions, method summaries, and qualitative comparisons. To address the concern directly, we have revised the abstract to state that the paper presents the challenge outcomes and reviews participant solutions, highlighting progress observed in this setting. We have also added brief comparisons to prior low-light challenges in the introduction for context. revision: yes
-
Referee: Challenge setup / results sections: no quantitative verification of the evaluation protocol (e.g., overfitting checks, noise-distribution statistics, or cross-dataset transfer) is described, leaving the claim that the novel dataset plus self-selected entries give a representative picture of current capabilities untested.
Authors: We agree that explicit verification details strengthen the paper. The revised manuscript now reports noise-distribution statistics computed on the dataset, describes the validation-set monitoring used during the challenge to check for overfitting, and includes consistency analysis across test subsets. Cross-dataset transfer experiments were outside the challenge scope, which focused on the new dataset; we have noted this limitation and its implications for broader generalizability. These additions better substantiate the evaluation protocol and the challenge's contribution to assessing current capabilities. revision: partial
Circularity Check
No circularity: standard challenge report with external submissions
full rationale
The paper is a competition summary that registers participant numbers (195/153), reports 22 valid external team submissions, and evaluates results on a novel dataset. No equations, derivations, fitted parameters, or predictions appear in the provided text. The central claim of 'significant progress' and 'thorough evaluation' rests on the independent submissions and dataset rather than any self-referential construction, self-citation chain, or renaming of prior results. This matches the expected non-finding for descriptive challenge papers without mathematical load-bearing steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The objective of this challenge is to identify effective networks capable of producing clearer and visually compelling images... leveraging samples of our novel dataset.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Loss Function: To balance reconstruction accuracy and perceptual quality, the team optimizes the model using a weighted multi-term loss function: L = L_char + 0.1 L_ssim + 0.15 L_edge
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Workshop and challenges website, 2026
Ntire 2026: New trends in image restoration and enhance- ment. Workshop and challenges website, 2026. 5
work page 2026
-
[2]
NT-HAZE: A Benchmark Dataset for Re- alistic Night-time Image Dehazing
Radu Ancuti, Codruta Ancuti, Radu Timofte, and Cos- min Ancuti. NT-HAZE: A Benchmark Dataset for Re- alistic Night-time Image Dehazing . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[3]
NTIRE 2026 Nighttime Image De- hazing Challenge Report
Radu Ancuti, Alexandru Brateanu, Florin Vasluianu, Raul Balmez, Ciprian Orhei, Codruta Ancuti, Radu Timofte, Cosmin Ancuti, et al. NTIRE 2026 Nighttime Image De- hazing Challenge Report . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[4]
Raul Balmez, Alexandru Brateanu, Ciprian Orhei, Co- druta O Ancuti, and Cosmin Ancuti. Depthlux: Employ- ing depthwise separable convolutions for low-light image enhancement.Sensors, 25(5):1530, 2025. 6
work page 2025
-
[5]
Raul Balmez, Alexandru Brateanu, Ciprian Orhei, Co- druta O Ancuti, and Cosmin Ancuti. Isalux: Illumination and semantics-aware transformer employing mixture of ex- perts for low light image enhancement. InProceedings of the IEEE/CVF Winter Conference on Applications of Com- puter Vision, pages 7862–7872, 2026. 6
work page 2026
-
[6]
Alexandru Brateanu, Raul Balmez, Ciprian Orhei, Co- druta Ancuti, and Cosmin Ancuti. Modalformer: Multi- modal transformer for low-light image enhancement.arXiv preprint arXiv:2507.20388, 2025. 6
-
[7]
NTIRE 2026 Challenge on Single Image Reflection Removal in the Wild: Datasets, Results, and Methods
Jie Cai, Kangning Yang, Zhiyuan Li, Florin Vasluianu, Radu Timofte, et al. NTIRE 2026 Challenge on Single Image Reflection Removal in the Wild: Datasets, Results, and Methods . InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[8]
Retinexformer: One-stage retinex-based transformer for low-light image enhance- ment
Yuanhao Cai, Hao Bian, Jing Lin, Haoqian Wang, Radu Timofte, and Yulun Zhang. Retinexformer: One-stage retinex-based transformer for low-light image enhance- ment. InProceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV), pages 12504–12513,
-
[9]
Pierre Charbonnier, Laure Blanc-F ´eraud, Gilles Aubert, and Michel Barlaud. Deterministic edge-preserving regu- larization in computed imaging.IEEE Transactions on im- age processing, 6(2):298–311, 1997. 17
work page 1997
-
[10]
Chen Chen, Qifeng Chen, Jia Xu, and Vladlen Koltun. Learning to see in the dark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3291–3300, 2018. 19
work page 2018
-
[11]
Simple baselines for image restoration
Liangyu Chen, Xiaojie Chu, Xiangyu Zhang, and Jian Sun. Simple baselines for image restoration. InECCV, 2022. 4
work page 2022
-
[12]
Simple baselines for image restoration
Liangyu Chen, Xiaojie Chu, Xiangyu Zhang, and Jian Sun. Simple baselines for image restoration. InEuropean con- ference on computer vision, pages 17–33. Springer, 2022. 8
work page 2022
-
[13]
Simple baselines for image restoration
Liangyu Chen, Xiaojie Chu, Xiangyu Zhang, and Jian Sun. Simple baselines for image restoration. InEuropean Con- ference on Computer Vision, 2022. 7
work page 2022
-
[14]
Learning A sparse transformer network for effective image deraining
Xiang Chen, Hao Li, Mingqiang Li, and Jinshan Pan. Learning A sparse transformer network for effective image deraining. InCVPR, pages 5896–5905. IEEE, 2023. 4
work page 2023
-
[15]
Zheng Chen, Kai Liu, Jingkai Wang, Xianglong Yan, Jianze Li, Ziqing Zhang, Jue Gong, Jiatong Li, Lei Sun, Xiaoyang Liu, Radu Timofte, Yulun Zhang, et al. The Fourth Chal- lenge on Image Super-Resolution (×4) at NTIRE 2026: Benchmark Results and Method Overview . InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) W...
work page 2026
-
[16]
High FPS Video Frame Inter- polation Challenge at NTIRE 2026
George Ciubotariu, Zhuyun Zhou, Yeying Jin, Zongwei Wu, Radu Timofte, et al. High FPS Video Frame Inter- polation Challenge at NTIRE 2026 . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[17]
Efficient image restoration via latent consistency flow matching
Elad Cohen, Idan Achituve, Idit Diamant, Arnon Netzer, and Hai Victor Habi. Efficient image restoration via latent consistency flow matching. InBMVC, 2025. 5
work page 2025
-
[18]
Scalable high-resolution pixel-space image synthesis with hourglass diffusion transformers
Katherine Crowson, Stefan Andreas Baumann, Alex Birch, Tanishq Mathew Abraham, Daniel Z Kaplan, and En- rico Shippole. Scalable high-resolution pixel-space image synthesis with hourglass diffusion transformers. InPro- ceedings of the 41st International Conference on Machine Learning, pages 9550–9575. PMLR, 2024. 5, 18
work page 2024
-
[19]
W. Dong, Y . Min, H. Zhou, and J. Chen. Towards scale- aware low-light enhancement via structure-guided trans- former design. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), pages 1459–1468, Nashville, TN, USA, 2025. 8
work page 2025
-
[20]
NTIRE 2026 Rip Current Detection and Segmentation (RipDet- Seg) Challenge Report
Andrei Dumitriu, Aakash Ralhan, Florin Miron, Florin Ta- tui, Radu Tudor Ionescu, Radu Timofte, et al. NTIRE 2026 Rip Current Detection and Segmentation (RipDet- Seg) Challenge Report . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[21]
Conde, Zongwei Wu, Yeying Jin, Radu Timofte, et al
Omar Elezabi, Marcos V . Conde, Zongwei Wu, Yeying Jin, Radu Timofte, et al. Photography Retouching Trans- fer, NTIRE 2026 Challenge: Report . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[22]
Stefan Elfwing, Eiji Uchibe, and Kenji Doya. Sigmoid- weighted linear units for neural network function approx- imation in reinforcement learning.Neural networks, 107: 3–11, 2018. 4
work page 2018
-
[23]
Darkir: Robust low-light image restoration
Daniel Feijoo, Juan C Benito, Alvaro Garcia, and Marcos V Conde. Darkir: Robust low-light image restoration. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 10879–10889, 2025. 2
work page 2025
-
[24]
Darkir: Robust low-light image restoration
Daniel Feijoo, Juan C Benito, Alvaro Garcia, and Marcos V Conde. Darkir: Robust low-light image restoration. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 10879–10889, 2025. 7
work page 2025
-
[25]
Bochen Guan, Jinlong Li, Kangning Yang, Chuang Ke, Jie Cai, Florin Vasluianu, Radu Timofte, et al. NTIRE 2026 Challenge on End-to-End Financial Receipt Restoration and Reasoning from Degraded Images: Datasets, Methods and Results . InProceedings of the IEEE/CVF Confer- 9 ence on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[26]
NTIRE 2026 The 3rd Restore Any Image Model (RAIM) Challenge: AI Flash Portrait (Track 3)
Ya-nan Guan, Shaonan Zhang, Hang Guo, Yawen Wang, Xinying Fan, Jie Liang, Hui Zeng, Guanyi Qin, Lishen Qu, Tao Dai, Shu-Tao Xia, Lei Zhang, Radu Timofte, et al. NTIRE 2026 The 3rd Restore Any Image Model (RAIM) Challenge: AI Flash Portrait (Track 3) . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[27]
NTIRE 2026 Challenge on Robust AI- Generated Image Detection in the Wild
Aleksandr Gushchin, Khaled Abud, Ekaterina Shu- mitskaya, Artem Filippov, Georgii Bychkov, Sergey Lavrushkin, Mikhail Erofeev, Anastasia Antsiferova, Changsheng Chen, Shunquan Tan, Radu Timofte, Dmitriy Vatolin, et al. NTIRE 2026 Challenge on Robust AI- Generated Image Detection in the Wild . InProceedings of the IEEE/CVF Conference on Computer Vision and...
work page 2026
-
[28]
Zur theorie der orthogonalen funktionensys- teme.Mathematische Annalen, 71(1):38–53, 1911
Alfred Haar. Zur theorie der orthogonalen funktionensys- teme.Mathematische Annalen, 71(1):38–53, 1911. 8
work page 1911
-
[29]
R2rnet: Low-light image enhancement via real-low to real-normal network
Jiang Hai, Zhu Xuan, Ren Yang, Yutong Hao, Fengzhu Zou, Fang Lin, and Songchen Han. R2rnet: Low-light image enhancement via real-low to real-normal network. Journal of Visual Communication and Image Representa- tion, 90:103712, 2023. 1
work page 2023
-
[30]
Robust Deepfake De- tection, NTIRE 2026 Challenge: Report
Benedikt Hopf, Radu Timofte, et al. Robust Deepfake De- tection, NTIRE 2026 Challenge: Report . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[31]
Squeeze-and-excitation networks
Jie Hu, Li Shen, Samuel Albanie, Gang Sun, and Enhua Wu. Squeeze-and-excitation networks. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7132–7141, 2017. 7
work page 2017
-
[32]
Squeeze-and-excitation networks
Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7132–7141, 2018. 5
work page 2018
-
[33]
Focal frequency loss for image reconstruction and synthe- sis
Liming Jiang, Bo Dai, Wayne Wu, and Chen Change Loy. Focal frequency loss for image reconstruction and synthe- sis. In2021 IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 13899–13909, 2021. 7
work page 2021
-
[34]
Perceptual losses for real-time style transfer and super-resolution
Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In European conference on computer vision, pages 694–711. Springer, 2016. 17
work page 2016
-
[35]
Perceptual Losses for Real-Time Style Transfer and Super-Resolution
Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Percep- tual losses for real-time style transfer and super-resolution. ArXiv, abs/1603.08155, 2016. 7
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[36]
Junoh Kang, Donghun Ryou, and Bohyung Han. Icm- sr: Image-conditioned manifold regularization for image super-resolution.arXiv preprint arXiv:2511.22048, 2025. 4, 18
-
[37]
NTIRE 2026 Low-light Enhancement: Twilight Cowboy Challenge
Aleksei Khalin, Egor Ershov, Artem Panshin, Sergey Kor- chagin, Georgiy Lobarev, Arseniy Terekhin, Sofiia Doro- gova, Amir Shamsutdinov, Yasin Mamedov, Bakhtiyar Khalfin, Bogdan Sheludko, Emil Zilyaev, Nikola Bani ´c, Georgy Perevozchikov, Radu Timofte, et al. NTIRE 2026 Low-light Enhancement: Twilight Cowboy Challenge . In Proceedings of the IEEE/CVF Con...
work page 2026
-
[38]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Retinexdualv2: Physically- grounded dual retinex for generalized uhd image restora- tion, 2026
Mohab Kishawy and Jun Chen. Retinexdualv2: Physically- grounded dual retinex for generalized uhd image restora- tion, 2026. 8
work page 2026
-
[40]
Mohab Kishawy, Ali Abdellatif Hussein, and Jun Chen. Retinexdual: Retinex-based dual nature approach for gen- eralized ultra-high-definition image restoration, 2025. 8
work page 2025
-
[41]
Imagenet classification with deep convolutional neural net- works
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural net- works. InAdvances in Neural Information Processing Sys- tems. Curran Associates, Inc., 2012. 23
work page 2012
-
[42]
FLUX.2: Frontier Visual Intelligence
Black Forest Labs. FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/flux-2, 2025. 8
work page 2025
-
[43]
Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks
Wei-Sheng Lai, Jia-Bin Huang, Narendra Ahuja, and Ming- Hsuan Yang. Fast and accurate image super-resolution with deep laplacian pyramid networks.CoRR, abs/1710.01992,
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Wei-Sheng Lai, Jia-Bin Huang, Narendra Ahuja, and Ming- Hsuan Yang. Fast and accurate image super-resolution with deep laplacian pyramid networks.IEEE transactions on pattern analysis and machine intelligence, 41(11):2599– 2613, 2018. 3
work page 2018
-
[45]
Jiatong Li, Zheng Chen, Kai Liu, Jingkai Wang, Zihan Zhou, Xiaoyang Liu, Libo Zhu, Radu Timofte, Yulun Zhang, et al. The First Challenge on Mobile Real- World Image Super-Resolution at NTIRE 2026: Bench- mark Results and Method Overview . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[46]
Xin Li, Jiachao Gong, Xijun Wang, Shiyao Xiong, Bingchen Li, Suhang Yao, Chao Zhou, Zhibo Chen, Radu Timofte, et al. NTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Mod- els: Datasets, Methods and Results . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[47]
Xin Li, Yeying Jin, Suhang Yao, Beibei Lin, Zhaoxin Fan, Wending Yan, Xin Jin, Zongwei Wu, Bingchen Li, Peishu Shi, Yufei Yang, Yu Li, Zhibo Chen, Bihan Wen, Robby Tan, Radu Timofte, et al. NTIRE 2026 The Second Challenge on Day and Night Raindrop Removal for Dual- Focused Images: Methods and Results . InProceedings of the IEEE/CVF Conference on Computer ...
work page 2026
-
[48]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maxi- milian Nickel, and Matt Le. Flow matching for generative modeling. InThe Thirteenth International Conference on Learning Representations, 2023. 5, 19
work page 2023
-
[49]
Kai Liu, Haoyang Yue, Zeli Lin, Zheng Chen, Jingkai Wang, Jue Gong, Radu Timofte, Yulun Zhang, et al. The First Challenge on Remote Sensing Infrared Image Super-Resolution at NTIRE 2026: Benchmark Results and Method Overview . InProceedings of the IEEE/CVF 10 Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[50]
Multi-level wavelet-cnn for image restora- tion
Pengju Liu, Hongzhi Zhang, Kai Zhang, Liang Lin, and Wangmeng Zuo. Multi-level wavelet-cnn for image restora- tion. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 773–782,
-
[51]
Shuhong Liu, Ziteng Cui, Chenyu Bao, Xuangeng Chu, Lin Gu, Bin Ren, Radu Timofte, Marcos V . Conde, et al. 3D Restoration and Reconstruction in Adverse Conditions: Re- alX3D Challenge Results . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[52]
Flow straight and fast: Learning to generate and transfer data with rectified flow, 2022
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow, 2022. 8, 22
work page 2022
-
[53]
NTIRE 2026 X- AIGC Quality Assessment Challenge: Methods and Results
Xiaohong Liu, Xiongkuo Min, Guangtao Zhai, Qiang Hu, Jiezhang Cao, Yu Zhou, Wei Sun, Farong Wen, Zitong Xu, Yingjie Zhou, Huiyu Duan, Lu Liu, Jiarui Wang, Siqi Luo, Chunyi Li, Li Xu, Zicheng Zhang, Yue Shi, Yubo Wang, Minghong Zhang, Chunchao Guo, Zhichao Hu, Mingtao Chen, Xiele Wu, Xin Ma, Zhaohe Lv, Yuanhao Xue, Jiaqi Wang, Xinxing Sha, Radu Timofte, et...
work page 2026
-
[54]
KAN: Kolmogorov-Arnold Networks
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljacic, Thomas Y . Hou, and Max Tegmark. Kan: Kolmogorov-arnold networks.ArXiv, abs/2404.19756, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983, 2016. 16
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[56]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 17, 23
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[57]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learn- ing Representations (ICLR), 2019. Poster. 19
work page 2019
-
[58]
MBLLEN: low-light image/video enhancement using cnns
Feifan Lv, Feng Lu, Jianhua Wu, and Chongsoon Lim. MBLLEN: low-light image/video enhancement using cnns. InBMVC, page 220. BMV A Press, 2018. 7
work page 2018
-
[59]
Stephane G Mallat. A theory for multiresolution signal de- composition: the wavelet representation.IEEE transactions on pattern analysis and machine intelligence, 11(7):674– 693, 2002. 8
work page 2002
-
[60]
NTIRE 2026 Challenge on Video Saliency Prediction: Methods and Results
Andrey Moskalenko, Alexey Bryncev, Ivan Kosmynin, Kira Shilovskaya, Mikhail Erofeev, Dmitry Vatolin, Radu Timofte, et al. NTIRE 2026 Challenge on Video Saliency Prediction: Methods and Results . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[61]
Posterior-mean rectified flow: Towards minimum MSE photo-realistic image restoration
Guy Ohayon, Tomer Michaeli, and Michael Elad. Posterior-mean rectified flow: Towards minimum MSE photo-realistic image restoration. InThe Thirteenth Inter- national Conference on Learning Representations, 2025. 5
work page 2025
-
[62]
NTIRE 2026 Challenge on Efficient Burst HDR and Restoration: Datasets, Methods, and Results
Hyunhee Park, Eunpil Park, Sangmin Lee, Radu Timofte, et al. NTIRE 2026 Challenge on Efficient Burst HDR and Restoration: Datasets, Methods, and Results . InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[63]
NTIRE 2026 Challenge on Learned Smartphone ISP with Unpaired Data: Methods and Results
Georgy Perevozchikov, Daniil Vladimirov, Radu Timofte, et al. NTIRE 2026 Challenge on Learned Smartphone ISP with Unpaired Data: Methods and Results . InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[64]
FiLM: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm de Vries, Vincent Du- moulin, and Aaron Courville. FiLM: Visual reasoning with a general conditioning layer. InProceedings of the AAAI Conference on Artificial Intelligence, 2018. 6
work page 2018
-
[65]
Guanyi Qin, Jie Liang, Bingbing Zhang, Lishen Qu, Ya-nan Guan, Hui Zeng, Lei Zhang, Radu Timofte, et al. NTIRE 2026 The 3rd Restore Any Image Model (RAIM) Chal- lenge: Professional Image Quality Assessment (Track 1) . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[66]
The Second Challenge on Cross-Domain Few-Shot Object Detection at NTIRE 2026: Methods and Results
Xingyu Qiu, Yuqian Fu, Jiawei Geng, Bin Ren, Jiancheng Pan, Zongwei Wu, Hao Tang, Yanwei Fu, Radu Timo- fte, Nicu Sebe, Mohamed Elhoseiny, et al. The Second Challenge on Cross-Domain Few-Shot Object Detection at NTIRE 2026: Methods and Results . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[67]
Lishen Qu, Yao Liu, Jie Liang, Hui Zeng, Wen Dai, Ya-nan Guan, Guanyi Qin, Shihao Zhou, Jufeng Yang, Lei Zhang, Radu Timofte, et al. NTIRE 2026 The 3rd Restore Any Image Model (RAIM) Challenge: Multi-Exposure Image Fusion in Dynamic Scenes (Track2) . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[68]
The Eleventh NTIRE 2026 Efficient Super- Resolution Challenge Report
Bin Ren, Hang Guo, Yan Shu, Jiaqi Ma, Ziteng Cui, Shuhong Liu, Guofeng Mei, Lei Sun, Zongwei Wu, Fa- had Shahbaz Khan, Salman Khan, Radu Timofte, Yawei Li, et al. The Eleventh NTIRE 2026 Efficient Super- Resolution Challenge Report . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[69]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 5, 18
work page 2022
-
[70]
Donghun Ryou, Inju Ha, Sanghyeok Chu, and Bohyung Han. Beyond the ground truth: Enhanced supervision for image restoration.arXiv preprint arXiv:2512.03932, 2025. 4, 18
-
[71]
Conde, Jeffrey Chen, Zhuyun Zhou, Zongwei Wu, Radu Timofte, et al
Tim Seizinger, Florin-Alexandru Vasluianu, Marcos V . Conde, Jeffrey Chen, Zhuyun Zhou, Zongwei Wu, Radu Timofte, et al. The First Controllable Bokeh Render- ing Challenge at NTIRE 2026 . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2 11
work page 2026
-
[72]
Illumi- nating darkness: Learning to enhance low-light images in- the-wild
SMA Sharif, Abdur Rehman, Zain Ul Abidin, Fayaz Ali Dharejo, Radu Timofte, and Rizwan Ali Naqvi. Illumi- nating darkness: Learning to enhance low-light images in- the-wild. InProceedings of the IEEE/CVF Winter Con- ference on Applications of Computer Vision, pages 2263– 2272, 2026. 1, 2, 5, 8, 18, 19, 23
work page 2026
-
[73]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V . Le, Geoffrey E. Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely- gated mixture-of-experts layer. InProceedings of the 5th International Conference on Learning Representations (ICLR), 2017. 5
work page 2017
-
[74]
Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang
Wenzhe Shi, Jose Caballero, Ferenc Husz ´ar, Johannes Totz, Andrew P. Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1874–1883, 2016. 7
work page 2016
-
[75]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014. 3
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[76]
Very deep convolutional networks for large-scale image recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. InInternational Conference on Learning Representations (ICLR), 2015. 19
work page 2015
-
[77]
The Third Challenge on Image Denoising at NTIRE 2026: Methods and Results
Lei Sun, Hang Guo, Bin Ren, Shaolin Su, Xian Wang, Danda Pani Paudel, Luc Van Gool, Radu Timofte, Yawei Li, et al. The Third Challenge on Image Denoising at NTIRE 2026: Methods and Results . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[78]
The Second Challenge on Event-Based Image Deblurring at NTIRE 2026: Methods and Results
Lei Sun, Weilun Li, Xian Wang, Zhendong Li, Letian Shi, Dannong Xu, Deheng Zhang, Mengshun Hu, Shuang Guo, Shaolin Su, Radu Timofte, Danda Pani Paudel, Luc Van Gool, et al. The Second Challenge on Event-Based Image Deblurring at NTIRE 2026: Methods and Results . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Wor...
work page 2026
-
[79]
NTIRE 2026 The First Challenge on Blind Computational Aberration Correction: Methods and Results
Lei Sun, Xiaolong Qian, Qi Jiang, Xian Wang, Yao Gao, Kailun Yang, Kaiwei Wang, Radu Timofte, Danda Pani Paudel, Luc Van Gool, et al. NTIRE 2026 The First Challenge on Blind Computational Aberration Correction: Methods and Results . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2
work page 2026
-
[80]
Restoring images in adverse weather con- ditions via histogram transformer
Shangquan Sun, Wenqi Ren, Xinwei Gao, Rui Wang, and Xiaochun Cao. Restoring images in adverse weather con- ditions via histogram transformer. InECCV (22), pages 111–129. Springer, 2024. 4
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.