Reassessing High-Performing LLMs on Polish Medical Exams: True Competence or Bias-Driven Performance?
Pith reviewed 2026-06-27 09:34 UTC · model grok-4.3
The pith
Standard MCQA scores on medical exams overestimate LLMs' true clinical reasoning ability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Standard multiple-choice question answering on medical exams does not reliably measure LLMs' true clinical competence; when the same exams are altered with four structural modifications that reduce guessing and bias artifacts, the best model (Qwen3.5-122B) drops by 28.4 points on English exams and 31 points on Polish exams despite low evidence of contamination.
What carries the argument
An expanded Polish medical exam benchmark with four structural modifications that reduce MCQA-specific artifacts and shift the test toward reasoning.
If this is right
- Evaluation design choices can change reported LLM performance on medical tasks by 30 percentage points or more.
- Public benchmarks that include modified questions give a stricter signal of reasoning ability than unmodified MCQA.
- Low contamination does not guarantee that high MCQA scores reflect real medical competence.
- Releasing the expanded benchmark allows direct comparison of future models under the harder protocol.
Where Pith is reading between the lines
- The same structural modifications could be applied to exams in other professional domains to check for similar overestimation.
- Results suggest that open-ended clinical scenario testing may be needed to confirm competence beyond multiple-choice formats.
- Training data patterns that survive decontamination checks could still produce format-specific advantages on standard MCQA.
Load-bearing premise
The four structural modifications to the exam questions successfully reduce MCQA-specific artifacts and provide a better test of reasoning rather than guessing or bias.
What would settle it
If LLMs achieve nearly the same scores on the modified questions as on the original ones, or if the modifications are shown to change the required medical knowledge rather than just the format, the claim that standard scores overestimate competence would be falsified.
Figures





read the original abstract
Large language models (LLMs) in medicine are mainly evaluated using multiple-choice question answering (MCQA), which can overestimate real clinical ability due to guessing strategies and answer biases. To address these limitations, we introduce an expanded and more challenging benchmark based on Polish medical exams, adding over 15,000 questions, two new domains, and four structural modifications that reduce MCQA-specific artifacts and better test reasoning. We evaluate 21 LLMs and show that evaluation design strongly affects results. Under our harder setup, the best model (Qwen3.5-122B) drops by 28.4 and 31 pp on English and Polish exams, respectively. Despite low evidence of data contamination, standard MCQA scores do not reliably reflect true medical competence. To facilitate further research, we make our benchmark publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an expanded benchmark of over 15,000 Polish medical exam questions across two new domains, incorporating four structural modifications to standard MCQA items intended to suppress answer-position bias, option-order effects, and surface-form guessing. It evaluates 21 LLMs and reports that the best model (Qwen3.5-122B) drops 28.4 pp on English and 31 pp on Polish exams under the modified setup, while finding low evidence of data contamination; the central conclusion is that conventional MCQA scores do not reliably reflect true medical competence. The benchmark is released publicly.
Significance. If the modifications are shown to isolate reasoning demand rather than merely increasing unrelated difficulty, the reported performance drops would provide concrete evidence that current MCQA-based evaluations overestimate LLM medical competence and would strengthen the case for more robust benchmarks in the field. The public release of the expanded dataset is a clear positive contribution.
major comments (3)
- [Benchmark construction] Benchmark construction section: The four structural modifications are described as reducing MCQA-specific artifacts, yet the manuscript supplies no ablation (each modification removed individually), no expert rating of reasoning load on the modified items, and no correlation with any external measure of clinical competence. Without these, the 28–31 pp drops cannot be unambiguously attributed to suppressed guessing/bias rather than unintended difficulty increases.
- [Results] Results section (performance tables): The headline drops (e.g., Qwen3.5-122B) are presented without error bars, confidence intervals, or statistical tests, and without any human performance baseline on the modified questions. This leaves open whether the harder setup still measures medical knowledge or simply becomes harder for both models and humans.
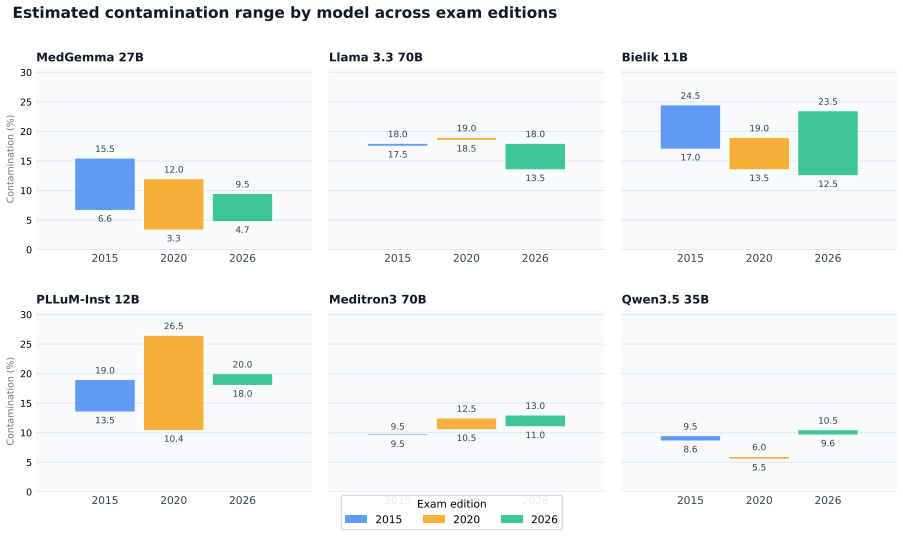
- [Contamination analysis] Contamination analysis: The claim of 'low evidence of data contamination' is asserted in the abstract and conclusion, but the methods used to detect contamination (exact string matching, n-gram overlap, etc.) and the quantitative thresholds applied are not detailed, weakening the supporting argument that the observed drops are not artifacts of training-data leakage.
minor comments (2)
- [Abstract] The abstract states that 'evaluation design strongly affects results' but does not quantify how much of the variance is explained by the four modifications versus domain or language shifts.
- [Tables/Figures] Table captions and figure legends should explicitly state the number of questions per condition and whether the same items were used across original and modified versions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: Benchmark construction section: The four structural modifications are described as reducing MCQA-specific artifacts, yet the manuscript supplies no ablation (each modification removed individually), no expert rating of reasoning load on the modified items, and no correlation with any external measure of clinical competence. Without these, the 28–31 pp drops cannot be unambiguously attributed to suppressed guessing/bias rather than unintended difficulty increases.
Authors: We agree that the absence of ablations, expert ratings, and external correlations leaves the attribution of the performance drops open to alternative interpretations. The modifications were chosen to target documented MCQA artifacts (position bias, order effects, and surface-form cues), but without the requested controls the causal link remains suggestive. In revision we will expand the benchmark construction section with a more explicit rationale for each modification (citing relevant prior work on MCQA bias), add a limitations paragraph discussing possible unrelated difficulty increases, and note the lack of ablations as an area for future work. Full individual ablations are not feasible within the current experimental budget but could be added if additional compute is obtained. revision: partial
-
Referee: Results section (performance tables): The headline drops (e.g., Qwen3.5-122B) are presented without error bars, confidence intervals, or statistical tests, and without any human performance baseline on the modified questions. This leaves open whether the harder setup still measures medical knowledge or simply becomes harder for both models and humans.
Authors: We accept this criticism. The revised results section will include error bars, 95% confidence intervals, and statistical tests (paired comparisons between standard and modified conditions) for all reported drops. A human performance baseline on the full modified set is not available and would require substantial new expert annotation effort beyond the scope of this study; the original Polish exams are already validated against human medical-student performance. We will add an explicit discussion of this limitation while noting that the modifications preserve the underlying medical content and were designed only to alter surface features. revision: partial
-
Referee: Contamination analysis: The claim of 'low evidence of data contamination' is asserted in the abstract and conclusion, but the methods used to detect contamination (exact string matching, n-gram overlap, etc.) and the quantitative thresholds applied are not detailed, weakening the supporting argument that the observed drops are not artifacts of training-data leakage.
Authors: We apologize for the missing methodological detail. The contamination analysis employed exact string matching on question stems and options, n-gram overlap checks against known training-data indicators, and a set of quantitative thresholds (overlap ratios below X% classified as low evidence). In the revised manuscript we will expand the methods subsection to describe these procedures, the exact thresholds, and the quantitative outcomes that support the “low evidence” statement. revision: yes
Circularity Check
No circularity: direct empirical measurements on explicitly described benchmark modifications
full rationale
The paper reports observed accuracy drops (28.4 pp and 31 pp) under a harder MCQA setup constructed via four structural modifications to exam questions. These modifications are presented as design choices whose effects are measured directly; the results are not obtained by fitting parameters to the target data, by renaming known patterns, or by any self-citation chain that would make the headline claim equivalent to its inputs by construction. No equations, fitted predictions, or load-bearing uniqueness theorems appear. The evaluation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MCQA overestimates real clinical ability due to guessing strategies and answer biases
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.18234
The illusion of readiness: Stress testing large frontier models on multimodal medical benchmarks. arXiv preprint arXiv:2509.18234. Krzysztof Jassem, Michał Ciesiółka, Filip Grali ´nski, Piotr Jabło´nski, Jakub Pokrywka, Marek Kubis, Monika Jabło ´nska, and Ryszard Staruch. 2025. Llmzsz {\L}: a comprehensive llm benchmark for polish.arXiv preprint arXiv:25...
-
[2]
https://huggingface.co/aaditya/ Llama3-OpenBioLLM-70B
aaditya/llama3-openbiollm-70b. https://huggingface.co/aaditya/ Llama3-OpenBioLLM-70B. Open source biomed- ical LLM fine-tuned from LLaMA-3 with 70B parameters. Ankit Pal, Logesh Kumar Umapathi, and Malaikan- nan Sankarasubbu. 2022. Medmcqa: A large-scale multi-subject multi-choice dataset for medical do- main question answering. InConference on health, in...
-
[3]
InHealthcare, volume 12, page 1637
Assessment study of chatgpt-3.5’s perfor- mance on the final polish medical examination: Ac- curacy in answering 980 questions. InHealthcare, volume 12, page 1637. MDPI. Shrutika Singh, Anton Alyakin, Daniel Alexander Al- ber, Jaden Stryker, Ai Phuong S Tong, Karl Sangwon, Nicolas Goff, Mathew De La Paz, Miguel Hernandez- Rovira, Ki Yun Park, and 1 others...
-
[6]
The correct answer is: A
the G-CSF prophylaxis is recommended only in radical and palliative treatment. The correct answer is: A. 1,2 B. all of the above C. 1,3 D. 2 only E. 3 only Correct answer: A Modified question Indicate true statements regarding complica- tions associated with using chemotherapy in cancer treatment:
-
[7]
the most frequent haematological compli- cation is neutropenia (found in 60–88% of the patients treated)
-
[8]
10–50% of patients treated for solid tumours and in over 80% of patients treated for haema- tological malignancies
neutropenic fever is found in ca. 10–50% of patients treated for solid tumours and in over 80% of patients treated for haema- tological malignancies
-
[9]
prawdziwe sa odpowiedzi
the G-CSF prophylaxis is recommended only in radical and palliative treatment. Correct answer: 1, 2 F.2 Multiple Answers (MA) Original question Which of the following activities are character- istic of six-month-old infants? A. supporting their body on extended arms with partly or fully opened hands B. bringing a toy from one hand to the other C. dropping...
2025
-
[10]
B Valid alternative interpre- tation of the question
Output engages with the issue indicated by the official correct answer.and2) Output includes additional content beyond that issue.and3) The additional content features ≥ 1 defect that could influence the evaluator’s decision. B Valid alternative interpre- tation of the question
-
[11]
C Underspecified expected detail
Output addresses a valid interpretation of the open-ended question.and2) This interpretation differs from the issue ex- pressed by the official correct answer. C Underspecified expected detail
-
[12]
D Non-existent medical terms
Output addresses the expected issue expressed by the official correct answer.and2) Output addresses this issue with lower specificity or completeness than the official correct answer. D Non-existent medical terms
-
[13]
E Misuse of existing medi- cal terms
Output contains a term absent from Polish, English, or Latin medical nomenclature.or2) Output contains a non-standard hybrid medical term defined as an expression created by com- bining Polish, English, or Latin elements into a form that is not itself recognised in medical nomenclature. E Misuse of existing medi- cal terms
-
[14]
F Incorrect spelling or nota- tion of medical terms
Output contains an existing Polish, English or Latin medical term.and2) Output uses this term inconsistently with its ac- cepted meaning. F Incorrect spelling or nota- tion of medical terms
-
[15]
Table 20: Criteria used for applying discrepancy patterns to LLM answers
Output contains an existing Polish, English or Latin medical term.and2) Spelling, notation, inflection or abbreviation of this term is incorrect. Table 20: Criteria used for applying discrepancy patterns to LLM answers. Discrepancy pattern Answers assigned pattern, n (%) Positive human assessments, n (%) Negative human assessments, n (%) A Defects in redu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.