Improving General Role-Playing Agents via Psychology-Grounded Reasoning and Role-Aware Policy Optimization
Pith reviewed 2026-06-26 04:52 UTC · model grok-4.3
The pith
Psychology-grounded chain-of-thought plus profile-token mutual information weighting lets models portray characters more faithfully from profiles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
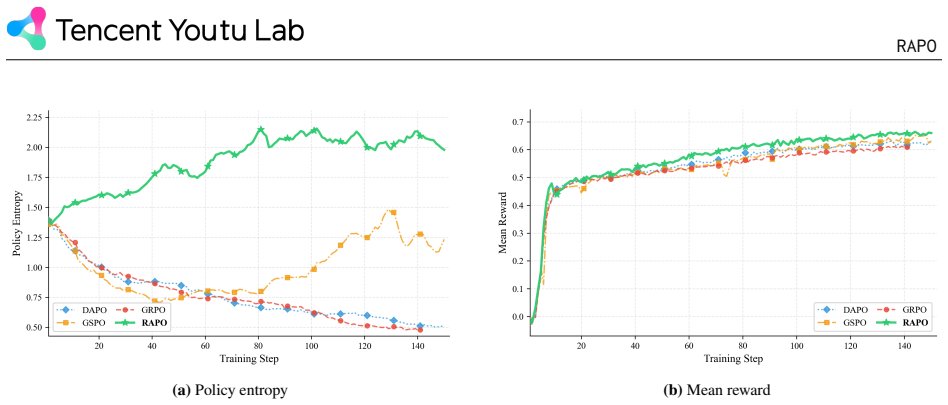
The paper establishes that structured three-step reasoning from psychology allows the model to think dynamically from the profile rather than mimic surface patterns, and that asymmetric gradient weighting via profile-token mutual information prevents both generic and role-specific phrases from receiving identical signals under LLM reward models, producing higher character fidelity on the three benchmarks.
What carries the argument
Psy-CoT's three role-specific reasoning steps and RAPO's profile-token mutual information used to weight gradients asymmetrically for role-specific tokens.
If this is right
- Agents should generalize better to out-of-distribution profiles because reasoning starts from the profile itself rather than learned mimicry.
- Reward hacking should decrease because role-specific tokens receive stronger positive and weaker negative updates than generic phrases.
- The gains should appear consistently across different model scales on the reported benchmarks.
- The separation of token types should reduce the accumulation of phrases that exploit the reward model without advancing character fidelity.
Where Pith is reading between the lines
- The mutual-information weighting approach could reduce reward hacking in other reinforcement-learning settings where reward models favor generic safe outputs.
- The three-step reasoning structure might transfer to tasks such as multi-turn dialogue or story continuation that also require profile or context consistency.
- Applying the same asymmetric weighting to other forms of preference optimization could test whether mutual information provides a general tool for distinguishing signal from noise in token-level updates.
Load-bearing premise
Profile-token mutual information reliably separates genuinely role-specific tokens from generic reward-hacking phrases without introducing new biases or requiring profile-specific tuning.
What would settle it
Train identical models with RAPO versus standard GRPO and measure the rate at which generic phrases versus profile-unique phrases appear in responses to held-out profiles; equal rates would show the weighting fails to create separation.
Figures





read the original abstract
Building general-purpose role-playing agents that faithfully portray any character from a natural-language profile remains challenging. The dominant paradigm -- supervised fine-tuning -- encourages behavioral mimicry without deep, human-like internal thought processes, resulting in poor out-of-distribution generalization. Therefore, we propose \textbf{Psy-CoT}, a psychology-grounded chain-of-thought framework that decomposes pre-response reasoning into three role-specific steps -- \emph{Interaction Perception}, \emph{Psychological Empathy}, and \emph{Logical Construction} -- so that the model \emph{thinks dynamically} from the profile rather than merely mimicking surface patterns. While structured reasoning provides a foundation, it alone is insufficient; reinforcement learning is essential to further align the model with character fidelity. However, we observe that under LLM-based reward models, both generic phrases that hack the reward model and genuinely role-specific phrases receive identical gradient signals -- this hacking accumulates over training, misleading the model into treating both as equally optimal choices. To address this, we propose \textbf{Role-Aware Policy Optimization (RAPO)}, which uses profile--token mutual information to weight gradients asymmetrically -- amplifying role-specific tokens under positive advantage while attenuating them under negative advantage. Experiments on CoSER, CharacterBench, and CharacterEval demonstrate that Psy-CoT outperforms existing role-playing CoT methods, and RAPO consistently surpasses GRPO across multiple model scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Psy-CoT, a psychology-grounded chain-of-thought framework decomposing reasoning into Interaction Perception, Psychological Empathy, and Logical Construction steps, enables dynamic profile-based thinking and outperforms prior role-playing CoT methods. It further claims that RAPO, which applies profile-token mutual information to asymmetrically weight gradients (amplifying role-specific tokens under positive advantage and attenuating under negative), mitigates reward hacking in LLM-based rewards and consistently surpasses GRPO across model scales on CoSER, CharacterBench, and CharacterEval.
Significance. If the empirical claims hold with proper validation, the work offers a structured psychological reasoning approach and a targeted fix for reward-model exploitation in role-playing RL, potentially improving out-of-distribution fidelity for general agents. The multi-benchmark, multi-scale evaluation provides a reasonable testbed for the methods.
major comments (2)
- [RAPO formulation] The RAPO description (method section) provides no estimation procedure, sampling details (joint vs. marginal), or token count for computing profile-token mutual information. This is load-bearing for the central claim that RAPO surpasses GRPO, because the asymmetric weighting mechanism requires that MI scores cleanly separate role-specific tokens from generic reward-hacking phrases without introducing new biases or profile-specific retuning.
- [Experiments] No ablation studies, error bars, dataset statistics, or per-benchmark breakdowns are visible to support the headline result that RAPO consistently beats GRPO. Without these, the cross-scale and cross-benchmark superiority cannot be verified as robust rather than an artifact of the specific reward model or evaluation setup.
minor comments (1)
- [Method] Notation for mutual information and advantage weighting should be formalized with an equation to clarify the asymmetric update rule.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and will revise the manuscript to incorporate additional methodological details and empirical analyses.
read point-by-point responses
-
Referee: [RAPO formulation] The RAPO description (method section) provides no estimation procedure, sampling details (joint vs. marginal), or token count for computing profile-token mutual information. This is load-bearing for the central claim that RAPO surpasses GRPO, because the asymmetric weighting mechanism requires that MI scores cleanly separate role-specific tokens from generic reward-hacking phrases without introducing new biases or profile-specific retuning.
Authors: We agree the current description is high-level and lacks implementation specifics. In the revision we will add an explicit subsection detailing the MI estimator (including the use of Monte Carlo sampling over the policy distribution to approximate the joint p(profile, token) and marginals, the number of tokens sampled per profile, and any smoothing or thresholding applied). This will make the separation of role-specific versus generic tokens transparent and allow readers to assess potential biases. revision: yes
-
Referee: [Experiments] No ablation studies, error bars, dataset statistics, or per-benchmark breakdowns are visible to support the headline result that RAPO consistently beats GRPO. Without these, the cross-scale and cross-benchmark superiority cannot be verified as robust rather than an artifact of the specific reward model or evaluation setup.
Authors: The manuscript already reports results on three benchmarks and multiple model scales, yet we concur that further disaggregation would strengthen the claims. We will add (i) an ablation isolating the MI-weighting component of RAPO, (ii) error bars computed over at least three random seeds where compute permits, (iii) basic dataset statistics (size, profile length distribution, etc.), and (iv) per-benchmark tables with mean and variance. These additions will be included in the revised experimental section. revision: yes
Circularity Check
No circularity; claims are proposals without self-referential derivations
full rationale
The abstract and description introduce Psy-CoT as a three-step reasoning framework and RAPO as an asymmetric gradient weighting scheme based on profile-token mutual information. No equations, derivations, or fitted-parameter renamings are present. No self-citation chains or uniqueness theorems are invoked to justify core choices. The improvements are framed as empirical outcomes on external benchmarks (CoSER, CharacterBench, CharacterEval) rather than reductions to inputs by construction. This is the expected honest non-finding for a methods paper whose central contributions are algorithmic proposals evaluated externally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026 , eprint=
Improving Search Agent with One Line of Code , author=. 2026 , eprint=
2026
-
[2]
The Bell system technical journal , volume=
A mathematical theory of communication , author=. The Bell system technical journal , volume=. 1948 , publisher=
1948
-
[3]
arXiv preprint arXiv:2506.13131 , year=
Alphaevolve: A coding agent for scientific and algorithmic discovery , author=. arXiv preprint arXiv:2506.13131 , year=
-
[4]
2026 , eprint=
Policy of Thoughts: Scaling LLM Reasoning via Test-time Policy Evolution , author=. 2026 , eprint=
2026
-
[5]
2026 , eprint=
ICPO: Illocution-Calibrated Policy Optimization for Multi-Turn Conversation , author=. 2026 , eprint=
2026
-
[9]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[12]
Gao, Zhenpeng and Xing, Xiaofen and Xu, Xiangmin , editor =. Findings of the. 2025 , pages =. doi:10.18653/v1/2025.findings-emnlp.288 , eventtitle =
-
[15]
doi:10.48550/ARXIV.2308.09597 , urldate =
Li, Cheng and Leng, Ziang and Yan, Chenxi and Shen, Junyi and Wang, Hao and Mi, Weishi and Fei, Yaying and Feng, Xiaoyang and Yan, Song and Wang, HaoSheng and Zhan, Linkang and Jia, Yaokai and Wu, Pingyu and Sun, Haozhen , year = 2023, journal =. doi:10.48550/ARXIV.2308.09597 , urldate =. arXiv , copyright =:2308.09597 , primaryclass =
-
[18]
Xintao Wang and Heng Wang and Yifei Zhang and Xinfeng Yuan and Rui Xu and Jen-tse Huang and Siyu Yuan and Haoran Guo and Jiangjie Chen and Shuchang Zhou and Wei Wang and Yanghua Xiao , booktitle=. Co. 2025 , url=
2025
-
[19]
HER: Human-like Reasoning and Reinforcement Learning for LLM Role-playing
Du, Chengyu and Wang, Xintao and Chen, Aili and Li, Weiyuan and Xu, Rui and Liu, Junteng and Huang, Zishan and Tian, Rong and Sun, Zijun and Li, Yuhao and Feng, Liheng and Ding, Deming and Zhao, Pengyu and Xiao, Yanghua , year = 2026, number =. doi:10.48550/arXiv.2601.21459 , urldate =. 2601.21459 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.21459 2026
-
[20]
2026 , eprint=
AdaMARP: An Adaptive Multi-Agent Interaction Framework for General Immersive Role-Playing , author=. 2026 , eprint=
2026
-
[25]
Tang, Yihong and Chen, Kehai and Bai, Xuefeng and Wang, Benyou and Liu, Zeming and Wang, Haifeng and Zhang, Min , year = 2026, number =. Character-. doi:10.48550/arXiv.2601.04611 , urldate =. 2601.04611 , primaryclass =
-
[26]
Theory of Mind in Large Language Models: Assessment and Enhancement
Chen, Ruirui and Jiang, Weifeng and Qin, Chengwei and Tan, Cheston. Theory of Mind in Large Language Models: Assessment and Enhancement. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1522
-
[27]
1991 , publisher=
Emotion and adaptation , author=. 1991 , publisher=
1991
-
[28]
Review of general psychology , volume=
The emerging field of emotion regulation: An integrative review , author=. Review of general psychology , volume=. 1998 , publisher=
1998
-
[29]
, author=
Building a practically useful theory of goal setting and task motivation: A 35-year odyssey. , author=. American psychologist , volume=. 2002 , publisher=
2002
-
[30]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[31]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[32]
arXiv preprint arXiv:2507.18071 , year=
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
-
[33]
arXiv preprint arXiv:2503.14476 , year=
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
-
[35]
Zhou, Jinfeng and Huang, Yongkang and Wen, Bosi and Bi, Guanqun and Chen, Yuxuan and Ke, Pei and Chen, Zhuang and Xiao, Xiyao and Peng, Libiao and Tang, Kuntian and Zhang, Rongsheng and Zhang, Le and Lv, Tangjie and Hu, Zhipeng and Wang, Hongning and Huang, Minlie , year = 2025, eprint =. Proceedings of the. doi:10.1609/AAAI.V39I24.34806 , urldate =
-
[36]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[37]
2025 , month =
GPT-5 System Card , author =. 2025 , month =
2025
-
[38]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[39]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[40]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[41]
2024 , howpublished =
Doubao Large Language Models , author =. 2024 , howpublished =
2024
-
[42]
Chen, Chaoran and Yao, Bingsheng and Zou, Ruishi and Hua, Wenyue and Lyu, Weimin and Li, Toby Jia-Jun and Wang, Dakuo , editor =. Towards a. Findings of the. 2025 , pages =. doi:10.18653/v1/2025.findings-acl.938 , eventtitle =
-
[43]
Chen, Nuo and Wang, Yan and Deng, Yang and Li, Jia , date =. The. 2025 , eprint =. doi:10.48550/arXiv.2407.11484 , pubstate =
-
[44]
Chen, Jiangjie and Wang, Xintao and Xu, Rui and Yuan, Siyu and Zhang, Yikai and Shi, Wei and Xie, Jian and Li, Shuang and Yang, Ruihan and Zhu, Tinghui and Chen, Aili and Li, Nianqi and Chen, Lida and Hu, Caiyu and Wu, Siye and Ren, Scott and Fu, Ziquan and Xiao, Yanghua , date =. From. 2024 , journaltitle =. 2404.18231 , eprinttype =
arXiv 2024
-
[45]
Shanahan, Murray and McDonell, Kyle and Reynolds, Laria , date =. Role-. 2023 , eprint =. doi:10.48550/arXiv.2305.16367 , pubstate =
-
[46]
Tseng, Yu-Min and Huang, Yu-Chao and Hsiao, Teng-Yun and Chen, Wei-Lin and Huang, Chao-Wei and Meng, Yu and Chen, Yun-Nung , editor =. Two. Findings of the. 2024 , pages =. doi:10.18653/v1/2024.findings-emnlp.969 , eventtitle =
-
[47]
Tseng, Yu-Min and Huang, Yu-Chao and Hsiao, Teng-Yun and Chen, Wei-Lin and Huang, Chao-Wei and Meng, Yu and Chen, Yun-Nung , date =. Two. 2024 , eprint =. doi:10.48550/arXiv.2406.01171 , pubstate =
-
[48]
Bai, Ting and Kang, Jiazheng and Fan, Jiayang , date =. 2025 , eprint =. doi:10.48550/arXiv.2412.20024 , pubstate =
-
[49]
Cheng, Xilong and Qin, Yunxiao and Tan, Yuting and Li, Zhengnan and Wang, Ye and Xiao, Hongjiang and Zhang, Yuan , date =. 2025 , eprint =. doi:10.48550/arXiv.2505.12814 , pubstate =
-
[50]
Chen, Nuo and Wang, Yan and Jiang, Haiyun and Cai, Deng and Li, Yuhan and Chen, Ziyang and Wang, Longyue and Li, Jia , editor =. Large. Findings of the. 2023 , pages =. doi:10.18653/v1/2023.findings-emnlp.570 , eventtitle =
-
[51]
Chen, Weishu and Tang, Jinyi and Hou, Zhouhui and Han, Shihao and Zhan, Mingjie and Huang, Zhiyuan and Liu, Delong and Guo, Jiawei and Zhao, Zhicheng and Su, Fei , date =. 2025 , eprint =. doi:10.48550/arXiv.2509.11860 , pubstate =
-
[52]
Chen, Siyuan and Si, Qingyi and Yang, Chenxu and Liang, Yunzhi and Lin, Zheng and Liu, Huan and Wang, Weiping , date =. A. 2024 , eprint =. doi:10.48550/arXiv.2411.02457 , pubstate =
-
[53]
Cui, Christopher and Peng, Xiangyu and Riedl, Mark , date =. Thespian:. 2023 , eprint =. doi:10.48550/arXiv.2308.01872 , pubstate =
-
[54]
2025 , doi =
Fang, Feiteng and Lin, Ting-En and Wu, Yuchuan and Liu, Xiong and Huang, Xiang and Chen, Dingwei and Ye, Jing and Zhang, Haonan and Zhu, Liang and Alinejad-Rokny, Hamid and Yang, Min and Huang, Fei and Li, Yongbin , date =. 2025 , doi =
2025
-
[55]
He, Kai and Huang, Yucheng and Wang, Wenqing and Ran, Delong and Sheng, Dongming and Huang, Junxuan and Lin, Qika and Xu, Jiaxing and Liu, Wenqiang and Feng, Mengling , editor =. Crab:. Proceedings of the 63rd. 2025 , pages =. doi:10.18653/v1/2025.acl-long.731 , eventtitle =
-
[56]
Huang, Le and Lan, Hengzhi and Sun, Zijun and Shi, Chuan and Bai, Ting , date =. Emotional. Proceedings of the \. 2024 , eprint =. doi:10.1109/ICKG63256.2024.00023 , eventtitle =
-
[57]
Huang, Yuxuan , date =. Orca:. 2024 , eprint =. doi:10.48550/arXiv.2411.10006 , pubstate =
-
[58]
Ji, Ke and Lian, Yixin and Li, Linxu and Gao, Jingsheng and Li, Weiyuan and Dai, Bin , editor =. Enhancing. Findings of the. 2025 , pages =. doi:10.18653/v1/2025.findings-acl.1344 , eventtitle =
-
[59]
Kong, Aobo and Zhao, Shiwan and Chen, Hao and Li, Qicheng and Qin, Yong and Sun, Ruiqi and Zhou, Xin and Zhou, Jiaming and Sun, Haoqin , date =. Self-. 2024 , eprint =. doi:10.48550/arXiv.2407.08995 , pubstate =
-
[60]
Liang, Yuanzhi and Zhu, Linchao and Yang, Yi , date =. Tachikuma:. 2023 , eprint =. doi:10.48550/arXiv.2307.12573 , pubstate =
-
[61]
2023 , url =
Li, Cheng and Leng, Ziang and Yan, Chenxi and Shen, Junyi and Wang, Hao and Mi, Weishi and Fei, Yaying and Feng, Xiaoyang and Yan, Song and Wang, HaoSheng and Zhan, Linkang and Jia, Yaokai and Wu, Pingyu and Sun, Haozhen , date =. 2023 , url =
2023
-
[62]
Liu, Cheng and Lu, Yifei and Ye, Fanghua and Li, Jian and Chen, Xingyu and Ren, Feiliang and Tu, Zhaopeng and Li, Xiaolong , editor =. Proceedings of the 2025. 2025 , pages =. doi:10.18653/v1/2025.emnlp-main.1389 , eventtitle =
-
[63]
Liu, Wenhao and An, Siyu and Lu, Junru and Wu, Muling and Li, Tianlong and Wang, Xiaohua and Lv, Changze and Zheng, Xiaoqing and Yin, Di and Sun, Xing and Huang, Xuanjing , editor =. Tell. Findings of the. 2025 , pages =. doi:10.18653/v1/2025.findings-acl.311 , eventtitle =
-
[64]
Long, Weifan and Wen, Wen and Zhai, Peng and Zhang, Lihua , date =. Role. 2024 , eprint =. doi:10.48550/arXiv.2411.01166 , pubstate =
-
[65]
Lu, Keming and Yu, Bowen and Zhou, Chang and Zhou, Jingren , date =. Large. Proceedings of the 62nd. 2024 , pages =. doi:10.18653/v1/2024.acl-long.423 , eventtitle =
-
[66]
Park, Jeiyoon and Park, Chanjun and Lim, Heuiseok , editor =. Proceedings of the 2025. 2025 , pages =. doi:10.18653/v1/2025.naacl-industry.24 , eventtitle =
-
[67]
Park, Jeiyoon and Han, Yongshin and Kim, Minseop and Yang, Kisu , date =. Dynamic. 2025 , eprint =. doi:10.48550/arXiv.2508.02016 , pubstate =
-
[68]
Codifying
Peng, Letian and Shang, Jingbo , date =. Codifying. 2025 , url =
2025
-
[69]
Qin, Haiming and Zhang, Jiwei and Zhang, Wei and Lu, KeZhong and Zhou, Mingyang and Liao, Hao and Mao, Rui , editor =. R-. Proceedings of the 2025. 2025 , pages =. doi:10.18653/v1/2025.emnlp-main.1372 , eventtitle =
-
[70]
Ran, Yiting and Wang, Xintao and Xu, Rui and Yuan, Xinfeng and Liang, Jiaqing and Xiao, Yanghua and Yang, Deqing , editor =. Capturing. Findings of the. 2024 , pages =. doi:10.18653/v1/2024.findings-emnlp.853 , eventtitle =
-
[71]
Ruangtanusak, Saksorn and Taveekitworachai, Pittawat and Pipatanakul, Kunat , date =. Talk. 2025 , eprint =. doi:10.48550/arXiv.2509.00482 , pubstate =
-
[72]
Rupprecht, Timothy and Nan, Enfu and Akbari, Arash and Akbari, Arman and Lu, Lei and Maan, Priyanka and Duffy, Sean and Zhao, Pu and He, Yumei and Kaeli, David and Wang, Yanzhi , date =. 2025 , eprint =. doi:10.48550/arXiv.2509.12168 , pubstate =
-
[73]
Character-
Shao, Yunfan and Li, Linyang and Dai, Junqi and Qiu, Xipeng , editor =. Character-. Proceedings of the 2023. 2023 , pages =
2023
-
[74]
Sun, Libo and Wang, Siyuan and Huang, Xuanjing and Wei, Zhongyu , date =. Identity-. 2024 , eprint =. doi:10.48550/arXiv.2407.19412 , pubstate =
-
[75]
Tang, Yihong and Ou, Jiao and Liu, Che and Zhang, Fuzheng and Zhang, Di and Gai, Kun , date =. 2024 , eprint =. doi:10.48550/arXiv.2409.14710 , pubstate =
-
[76]
Tang, Yihong and Chen, Kehai and Yang, Muyun and Niu, Zhengyu and Li, Jing and Zhao, Tiejun and Zhang, Min , date =. Thinking in. 2025 , eprint =. doi:10.48550/arXiv.2506.01748 , pubstate =
-
[77]
Proceedings of the 1st
Tao, Meiling and Xuechen, Liang and Shi, Tianyu and Yu, Lei and Xie, Yiting , editor =. Proceedings of the 1st. 2024 , pages =
2024
-
[78]
Tu, Quan and Chen, Chuanqi and Li, Jinpeng and Li, Yanran and Shang, Shuo and Zhao, Dongyan and Wang, Ran and Yan, Rui , date =. 2023 , eprint =. doi:10.48550/arXiv.2308.10278 , pubstate =
-
[79]
Wang, Xintao and Wang, Heng and Zhang, Yifei and Yuan, Xinfeng and Xu, Rui and Huang, Jen-tse and Yuan, Siyu and Guo, Haoran and Chen, Jiangjie and Zhou, Shuchang and Wang, Wei and Xiao, Yanghua , date =. 2025 , eprint =. doi:10.48550/arXiv.2502.09082 , pubstate =
-
[80]
Wang, Xiaoyang and Zhang, Hongming and Ge, Tao and Yu, Wenhao and Yu, Dian and Yu, Dong , date =. 2025 , eprint =. doi:10.48550/arXiv.2501.15427 , pubstate =
-
[81]
2025 , url =
Wang, Zongsheng and Sun, Kaili and Wu, Bowen and Yu, Qun and Li, Ying and Wang, Baoxun , date =. 2025 , url =
2025
-
[82]
Wang, Noah and Peng, Z.y. and Que, Haoran and Liu, Jiaheng and Zhou, Wangchunshu and Wu, Yuhan and Guo, Hongcheng and Gan, Ruitong and Ni, Zehao and Yang, Jian and Zhang, Man and Zhang, Zhaoxiang and Ouyang, Wanli and Xu, Ke and Huang, Wenhao and Fu, Jie and Peng, Junran , editor =. Findings of the. 2024 , pages =. doi:10.18653/v1/2024.findings-acl.878 , ...
-
[83]
Wang, Yongjie and Leung, Jonathan and Shen, Zhiqi , date =. 2025 , eprint =. doi:10.48550/arXiv.2505.18541 , pubstate =
-
[84]
MECoT: Markov emotional chain-of-thought for personality-consistent role-playing,
Wei, Yangbo and Huang, Zhen and Zhao, Fangzhou and Feng, Qi and Xing, Wei W. , editor =. Findings of the. 2025 , pages =. doi:10.18653/v1/2025.findings-acl.435 , eventtitle =
-
[85]
Weir, Nathaniel and Thomas, Ryan and family=Amore, given=Randolph, prefix=d', useprefix=true and Hill, Kellie and Van Durme, Benjamin and Jhamtani, Harsh , editor =. Ontologically. Proceedings of the 2024. 2024 , pages =. doi:10.18653/v1/2024.emnlp-main.520 , eventtitle =
-
[86]
Yang, Bohao and Liu, Dong and Xiao, Chenghao and Zhao, Kun and Tang, Chen and Li, Chao and Yuan, Lin and Guang, Yang and Lin, Chenghua , editor =. Crafting. Findings of the. 2025 , pages =. doi:10.18653/v1/2025.findings-emnlp.1100 , eventtitle =
-
[87]
Yang, Shihao and Lu, Zhicong and Yang, Yong and Lv, Bo and Shen, Yang and Liu, Nayu , date =. 2025 , eprint =. doi:10.48550/arXiv.2511.08017 , pubstate =
-
[88]
Yang, Tao and Zhu, Yuhua and Quan, Xiaojun and Liu, Cong and Wang, Qifan , date =. 2025 , eprint =. doi:10.48550/arXiv.2502.03821 , pubstate =
-
[89]
2025 , url =
Yao, Bingsheng and Sun, Bo and Dong, Yuanzhe and Lu, Yuxuan and Wang, Dakuo , date =. 2025 , url =
2025
-
[90]
Ye, Jing and Wang, Rui and Wu, Yuchuan and Ma, Victor and Fang, Feiteng and Huang, Fei and Li, Yongbin , editor =. Findings of the. 2025 , pages =. doi:10.18653/v1/2025.findings-emnlp.18 , eventtitle =
-
[91]
Yin, Xuyan and Yang, Xinran and Li, Zihao and Zou, Lixin and Li, Chenliang , editor =. Findings of the. 2025 , pages =. doi:10.18653/v1/2025.findings-emnlp.323 , eventtitle =
-
[92]
Yu, Yeyong and Yu, Runsheng and Wei, Haojie and Zhang, Zhanqiu and Qian, Quan , editor =. Beyond. Proceedings of the 63rd. 2025 , pages =. doi:10.18653/v1/2025.acl-long.586 , eventtitle =
-
[93]
Yu, Xiaoyan and Luo, Tongxu and Wei, Yifan and Lei, Fangyu and Huang, Yiming and Peng, Hao and Zhu, Liehuang , editor =. Neeko:. Proceedings of the 2024. 2024 , pages =. doi:10.18653/v1/2024.emnlp-main.697 , eventtitle =
-
[94]
Proceedings of the 18th
Zhao, Runcong and Zhang, Wenjia and Li, Jiazheng and Zhu, Lixing and Li, Yanran and He, Yulan and Gui, Lin , editor =. Proceedings of the 18th. 2024 , pages =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.