Verifiable Secure Aggregation via Dual Servers with Linear Tags in Federated Learning
Pith reviewed 2026-06-30 16:31 UTC · model grok-4.3
The pith
A dual-server scheme with linear tags from pseudo-random functions performs verifiable secure aggregation in federated learning while cutting user and verification costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors construct a verifiable secure aggregation protocol that uses pseudo-random functions and a pair of non-colluding servers to produce linear tags. These tags enable mutual verification of the aggregated result, prevent reconstruction of individual updates, and block undetected tampering while preserving end-to-end security and constant tag size.
What carries the argument
Linear tags computed from pseudo-random functions across a non-colluding dual-server architecture, which carry the mutual verification and secure aggregation steps.
If this is right
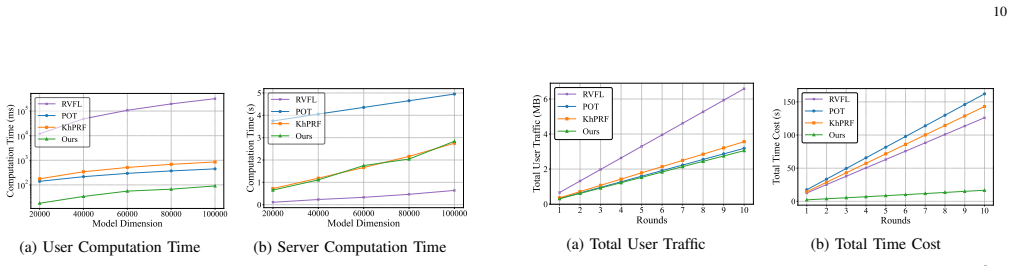
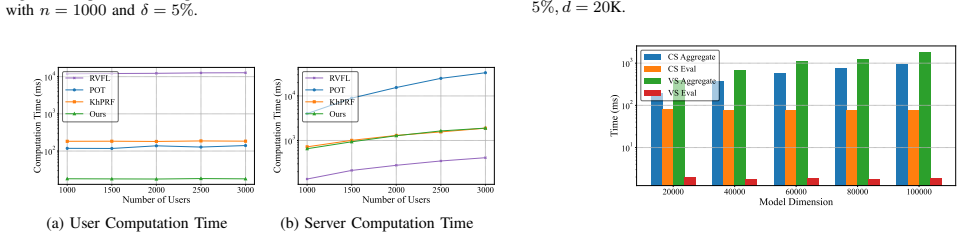
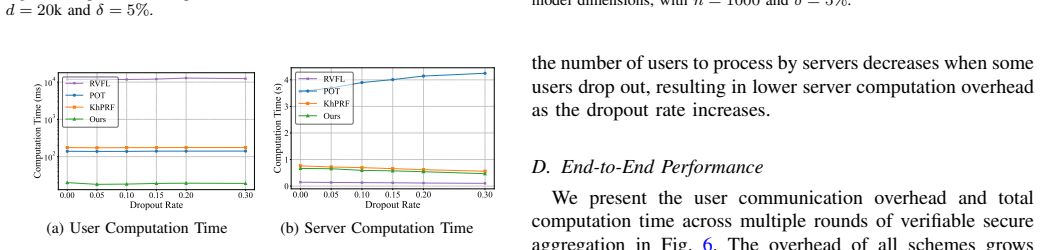
- For 20K-dimensional inputs, user computation falls to 18 ms, roughly seven times faster than OPSA.
- Verification time falls to 9.5 ms, about 2.4 times faster than OPSA.
- Communication cost stays comparable to plaintext aggregation.
- The scheme remains practical when the number of participants is large.
- User privacy is maintained and the aggregate result is verifiable end-to-end.
Where Pith is reading between the lines
- The same tag mechanism could be examined for use in other multi-party settings where two non-colluding authorities can be arranged.
- If the measured speedups hold on real hardware and datasets, the protocol might support aggregation rounds that were previously too slow.
- A direct test would measure whether gradient-inversion attacks succeed against the final verified aggregate.
Load-bearing premise
The two servers never collude with each other.
What would settle it
An experiment in which the two servers collude, reconstruct at least one individual update, or output a tampered aggregate that still passes verification would show the security claim fails.
Figures



read the original abstract
Federated learning (FL) enables collaborative model training by aggregating local updates without requiring raw data sharing. However, prior studies have shown that servers can exploit gradient inversion to compromise user privacy or manipulate aggregation results, undermining the utility of the global model. To address these concerns, we propose a secure and verifiable aggregation scheme with lightweight cryptographic primitives for FL. Our method leverages pseudo-random functions (PRFs) and a non-colluding dual-server architecture to achieve secure aggregation with mutual server verification, while maintaining communication overhead comparable to plaintext aggregation and a constant verification tag size. Crucially, it preserves user privacy and achieves end-to-end secure aggregation with verification. Moreover, our scheme significantly reduces both user computation and verification overhead, making it suitable for FL with a large number of participants. For instance, with an input dimension of 20K, user computation time is reduced to 18 ms, approximately 7$\times$ faster than OPSA, while verification time decreases to 9.5 ms, approximately 2.4$\times$ faster than OPSA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a verifiable secure aggregation scheme for federated learning using pseudo-random functions and a non-colluding dual-server architecture. It claims to achieve secure aggregation with mutual server verification, constant-size verification tags, communication overhead comparable to plaintext aggregation, and substantially reduced user computation and verification times (e.g., 18 ms user computation and 9.5 ms verification at 20K input dimension, stated as 7× and 2.4× faster than OPSA).
Significance. If the security claims hold under the stated model and the performance numbers are reproducible, the construction could provide a practical lightweight primitive for large-scale FL deployments that simultaneously address privacy against gradient inversion and integrity against aggregation manipulation. The constant tag size and dual-server mutual verification are potentially useful features if formally substantiated.
major comments (3)
- [Threat model] Threat model / security definitions: the end-to-end privacy and verifiability guarantees are conditioned on the two servers never colluding, yet the manuscript provides no mechanism for enforcing, detecting, or recovering from collusion; this assumption is load-bearing for all stated security properties.
- [Security analysis] Security analysis: no formal security model, game-based definitions, or reduction proofs appear for the claimed end-to-end secure aggregation with verification; the abstract and performance claims cannot be assessed without these.
- [Performance evaluation] Performance evaluation: the concrete timings (18 ms user computation, 9.5 ms verification at dimension 20K) and speedups versus OPSA are reported without implementation details, hardware platform, or experimental setup, rendering the quantitative claims unverifiable.
minor comments (2)
- [Abstract] The title refers to 'Linear Tags' but the abstract does not define or motivate the linear-tag construction or its role in achieving constant tag size.
- [Preliminaries] Notation for the PRF-based tags and how they are split across the two servers is introduced without a clear preliminary section or running example.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. We address each of the major comments below, providing clarifications and indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Threat model] Threat model / security definitions: the end-to-end privacy and verifiability guarantees are conditioned on the two servers never colluding, yet the manuscript provides no mechanism for enforcing, detecting, or recovering from collusion; this assumption is load-bearing for all stated security properties.
Authors: The non-colluding dual-server model is a standard assumption in the literature on secure two-party computation and secure aggregation protocols, where the servers are assumed to follow the protocol but not collude. Our scheme's security properties are proven under this model using the properties of PRFs and linear tags. We will expand the dedicated threat model section to explicitly articulate this assumption, discuss its practical implications (such as servers operated by independent entities), and note that mechanisms for collusion detection are beyond the scope of the current work as they would require additional infrastructure not related to the cryptographic construction. revision: partial
-
Referee: [Security analysis] Security analysis: no formal security model, game-based definitions, or reduction proofs appear for the claimed end-to-end secure aggregation with verification; the abstract and performance claims cannot be assessed without these.
Authors: We agree that a formal treatment would enhance the paper. The current manuscript includes a security argument relying on the pseudorandomness of the PRF and the linearity of the verification tags to argue privacy and verifiability. In the revision, we will add a formal security model section defining the games for privacy against the servers and verifiability of the aggregation result, along with sketches of reductions to the PRF security assumption. revision: yes
-
Referee: [Performance evaluation] Performance evaluation: the concrete timings (18 ms user computation, 9.5 ms verification at dimension 20K) and speedups versus OPSA are reported without implementation details, hardware platform, or experimental setup, rendering the quantitative claims unverifiable.
Authors: The performance numbers were measured using our Python-based prototype implementation. We will add a comprehensive experimental setup subsection detailing the hardware configuration (processor, memory, operating system), the cryptographic library used, the exact implementation of the PRF and tag generation, and the methodology for timing measurements to ensure the results are reproducible and the claims verifiable. revision: yes
Circularity Check
No significant circularity; scheme is a new construction on standard primitives and explicit assumptions
full rationale
The paper presents a cryptographic construction for verifiable secure aggregation using PRFs and a non-colluding dual-server model. No equations, derivations, or performance claims reduce by construction to fitted inputs, self-definitions, or self-citation chains. The dual-server assumption is stated explicitly as a precondition rather than derived from the scheme itself. Performance numbers (e.g., 18 ms user time) are reported from implementation measurements, not from any predictive model fitted to the same data. No load-bearing uniqueness theorems or ansatzes are smuggled via self-citation. This is a standard honest finding for a construction paper whose central claims rest on cryptographic assumptions rather than internal reductions.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Security properties of pseudo-random functions
- domain assumption Non-collusion between the two servers
Reference graph
Works this paper leans on
-
[1]
Advances and open problems in federated learning,
P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Bennis, A. N. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummingset al., “Advances and open problems in federated learning,”Foundations and trends® in machine learning, vol. 14, no. 1–2, pp. 1–210, 2021
2021
-
[2]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inArtificial intelligence and statistics. PMLR, 2017, pp. 1273– 1282
2017
-
[3]
Federated learning review: Fundamentals, enabling technologies, and future applications,
S. Banabilah, M. Aloqaily, E. Alsayed, N. Malik, and Y . Jararweh, “Federated learning review: Fundamentals, enabling technologies, and future applications,”Information processing & management, vol. 59, no. 6, p. 103061, 2022
2022
-
[4]
Deep leakage from gradients,
L. Zhu, Z. Liu, and S. Han, “Deep leakage from gradients,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[5]
Model inversion attacks that exploit confidence information and basic countermeasures,
M. Fredrikson, S. Jha, and T. Ristenpart, “Model inversion attacks that exploit confidence information and basic countermeasures,” in Proceedings of the 22nd ACM SIGSAC conference on computer and communications security, 2015, pp. 1322–1333
2015
-
[6]
Versa: Verifiable secure aggregation for cross-device federated learning,
C. Hahn, H. Kim, M. Kim, and J. Hur, “Versa: Verifiable secure aggregation for cross-device federated learning,”IEEE Transactions on Dependable and Secure Computing, vol. 20, no. 1, pp. 36–52, 2021
2021
-
[7]
Backdoor attacks and defenses targeting multi-domain ai models: A comprehensive review,
S. Zhang, Y . Pan, Q. Liu, Z. Yan, K.-K. R. Choo, and G. Wang, “Backdoor attacks and defenses targeting multi-domain ai models: A comprehensive review,”ACM Computing Surveys, vol. 57, no. 4, pp. 1–35, 2024
2024
-
[8]
Beyond inferring class representatives: User-level privacy leakage from federated learning,
Z. Wang, M. Song, Z. Zhang, Y . Song, Q. Wang, and H. Qi, “Beyond inferring class representatives: User-level privacy leakage from federated learning,” inIEEE INFOCOM 2019-IEEE conference on computer communications. IEEE, 2019, pp. 2512–2520
2019
-
[9]
EVFLS: An effective and verifiable federated learning aggregation scheme,
R. Wang, J. Geng, and L. Xiong, “EVFLS: An effective and verifiable federated learning aggregation scheme,” inInternational Conference on Frontiers in Cyber Security. Springer, 2024, pp. 131–148
2024
-
[10]
VOSA: Verifiable and oblivious secure aggregation for privacy-preserving federated learning,
Y . Wang, A. Zhang, S. Wu, and S. Yu, “VOSA: Verifiable and oblivious secure aggregation for privacy-preserving federated learning,”IEEE Transactions on Dependable and Secure Computing, vol. 20, no. 5, pp. 3601–3616, 2022
2022
-
[11]
Effi- cient verifiable protocol for privacy-preserving aggregation in federated learning,
T. Eltaras, F. Sabry, W. Labda, K. Alzoubi, and Q. Ahmedeltaras, “Effi- cient verifiable protocol for privacy-preserving aggregation in federated learning,”IEEE Transactions on Information Forensics and Security, vol. 18, pp. 2977–2990, 2023
2023
-
[12]
Efficient and secure federated learning with verifiable weighted average aggregation,
Z. Yang, M. Zhou, H. Yu, R. O. Sinnott, and H. Liu, “Efficient and secure federated learning with verifiable weighted average aggregation,” IEEE Transactions on Network Science and Engineering, vol. 10, no. 1, pp. 205–222, 2022
2022
-
[13]
Veritas: Plaintext encoders for practical verifiable homomorphic en- cryption,
S. Chatel, C. Knabenhans, A. Pyrgelis, C. Troncoso, and J.-P. Hubaux, “Veritas: Plaintext encoders for practical verifiable homomorphic en- cryption,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 2024, pp. 2520–2534
2024
-
[14]
Homomorphic hash and blockchain based authentication key exchange protocol for strangers,
H. Yao, C. Wang, B. Hai, and S. Zhu, “Homomorphic hash and blockchain based authentication key exchange protocol for strangers,” in 2018 Sixth International Conference on Advanced Cloud and Big Data (CBD). IEEE, 2018, pp. 243–248
2018
-
[15]
A survey on homomorphic encryption schemes: Theory and implementation,
A. Acar, H. Aksu, A. S. Uluagac, and M. Conti, “A survey on homomorphic encryption schemes: Theory and implementation,”ACM Computing Surveys (Csur), vol. 51, no. 4, pp. 1–35, 2018
2018
-
[16]
OPSA: Efficient and verifiable one-pass secure aggregation with TEE for federated learning,
Z. Guan, Y . Zhao, Z. Wan, and J. Han, “OPSA: Efficient and verifiable one-pass secure aggregation with TEE for federated learning,”IEEE Transactions on Dependable and Secure Computing, 2025
2025
-
[17]
Attack of the tails: Yes, you really can backdoor federated learning,
H. Wang, K. Sreenivasan, S. Rajput, H. Vishwakarma, S. Agarwal, J.- y. Sohn, K. Lee, and D. Papailiopoulos, “Attack of the tails: Yes, you really can backdoor federated learning,”Advances in neural information processing systems, vol. 33, pp. 16 070–16 084, 2020
2020
-
[18]
VerifyNet: Secure and verifiable federated learning,
G. Xu, H. Li, S. Liu, K. Yang, and X. Lin, “VerifyNet: Secure and verifiable federated learning,”IEEE Transactions on Information Forensics and Security, vol. 15, pp. 911–926, 2019
2019
-
[19]
Vfl: A verifiable federated learning with privacy-preserving for big data in industrial IoT,
A. Fu, X. Zhang, N. Xiong, Y . Gao, H. Wang, and J. Zhang, “Vfl: A verifiable federated learning with privacy-preserving for big data in industrial IoT,”IEEE Transactions on Industrial Informatics, vol. 18, no. 5, pp. 3316–3326, 2020
2020
-
[20]
Comments on “VERSA: Verifiable secure aggregation for cross-device federated learning
F. Luo, H. Wang, and X. Yan, “Comments on “VERSA: Verifiable secure aggregation for cross-device federated learning”,”IEEE Transactions on Dependable and Secure Computing, vol. 21, no. 1, pp. 499–500, 2023
2023
-
[21]
Verifl: Communication-efficient and fast verifiable aggregation for federated learning,
X. Guo, Z. Liu, J. Li, J. Gao, B. Hou, C. Dong, and T. Baker, “Verifl: Communication-efficient and fast verifiable aggregation for federated learning,”IEEE Transactions on Information Forensics and Security, vol. 16, pp. 1736–1751, 2020
2020
-
[22]
OVP-FL: outsourced verifiable privacy- preserving federated learning,
S. Li, X. Wei, and H. Wang, “OVP-FL: outsourced verifiable privacy- preserving federated learning,”IEEE Transactions on Network Science and Engineering, 2025
2025
-
[23]
RVFL: Rational verifiable federated learning secure aggregation protocol,
X. Mu, Y . Tian, Z. Zhou, S. Wang, and J. Xiong, “RVFL: Rational verifiable federated learning secure aggregation protocol,”IEEE Internet of Things Journal, 2024
2024
-
[24]
On the security of verifiable and oblivious secure aggregation for privacy-preserving federated learning,
J. Wu and W. Zhang, “On the security of verifiable and oblivious secure aggregation for privacy-preserving federated learning,”IEEE Transactions on Dependable and Secure Computing, vol. 21, no. 5, pp. 4324–4326, 2024
2024
-
[25]
BatchCrypt: Efficient homomorphic encryption for Cross-Silo federated learning,
C. Zhang, S. Li, J. Xia, W. Wang, F. Yan, and Y . Liu, “BatchCrypt: Efficient homomorphic encryption for Cross-Silo federated learning,” in 12 2020 USENIX annual technical conference (USENIX ATC 20), 2020, pp. 493–506
2020
-
[26]
Katz and Y
J. Katz and Y . Lindell,Introduction to modern cryptography: principles and protocols. Chapman and hall/CRC, 2007
2007
-
[27]
Oppliger,SSL and TLS: Theory and Practice
R. Oppliger,SSL and TLS: Theory and Practice. Artech House, 2023
2023
-
[28]
Prio: Private, robust, and scalable computation of aggregate statistics,
H. Corrigan-Gibbs and D. Boneh, “Prio: Private, robust, and scalable computation of aggregate statistics,” in14th USENIX symposium on networked systems design and implementation (NSDI 17), 2017, pp. 259–282
2017
-
[29]
Lightweight techniques for private heavy hitters,
D. Boneh, E. Boyle, H. Corrigan-Gibbs, N. Gilboa, and Y . Ishai, “Lightweight techniques for private heavy hitters,” in2021 IEEE Sym- posium on Security and Privacy (SP). IEEE, 2021, pp. 762–776
2021
-
[30]
CSHER: A system for compact storage with HE-Retrieval,
A. Akavia, N. Oren, B. Sapir, and M. Vald, “CSHER: A system for compact storage with HE-Retrieval,” in32nd USENIX Security Symposium (USENIX Security 23), 2023, pp. 4751–4768
2023
-
[31]
Elsa: Secure aggregation for federated learning with malicious actors,
M. Rathee, C. Shen, S. Wagh, and R. A. Popa, “Elsa: Secure aggregation for federated learning with malicious actors,” in2023 IEEE Symposium on Security and Privacy (SP). IEEE, 2023, pp. 1961–1979
2023
-
[32]
Buchmann,Introduction to cryptography
J. Buchmann,Introduction to cryptography. Springer, 2004, vol. 335
2004
-
[33]
How to simulate it–a tutorial on the simulation proof technique,
Y . Lindell, “How to simulate it–a tutorial on the simulation proof technique,”Tutorials on the Foundations of Cryptography: Dedicated to Oded Goldreich, pp. 277–346, 2017
2017
-
[34]
Gradient-based learning applied to document recognition,
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 2002
2002
-
[35]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” University of Toronto, Toronto, Tech. Rep. TR-2009, 2009
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.