Cross-Resolution Semantic Transfer for Robust Text-to-Image Retrieval in Low-Resolution Surveillance
Pith reviewed 2026-06-30 06:49 UTC · model grok-4.3
The pith
CRST transfers semantic information across resolutions to fix reliability collapse and ranking drift in text-to-image person retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
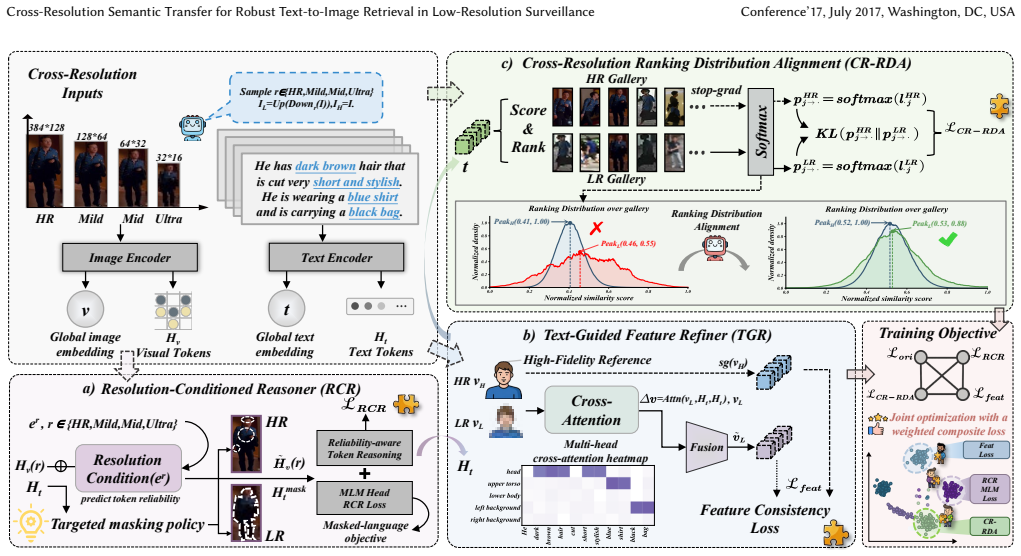
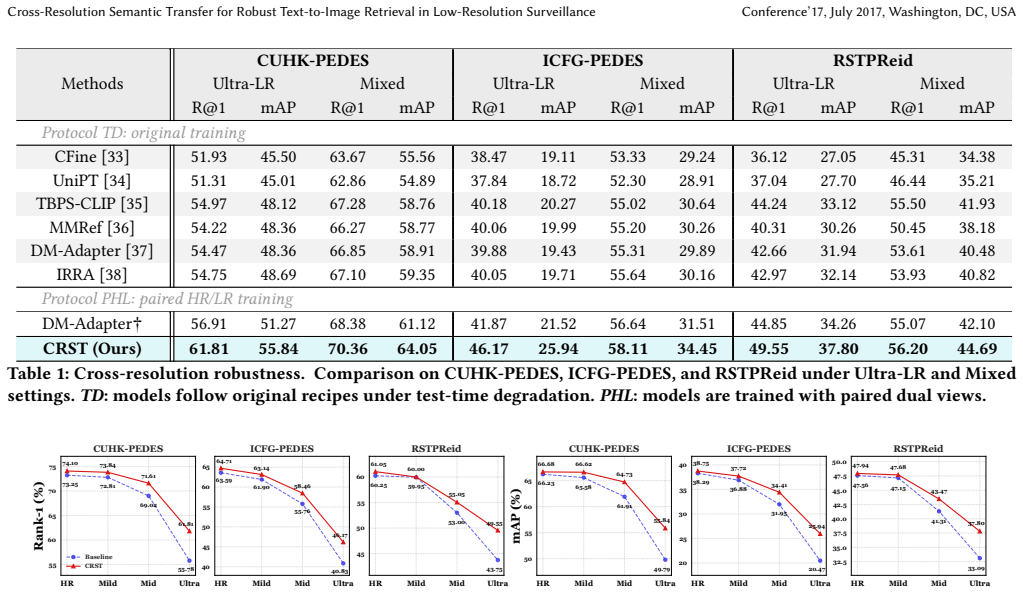
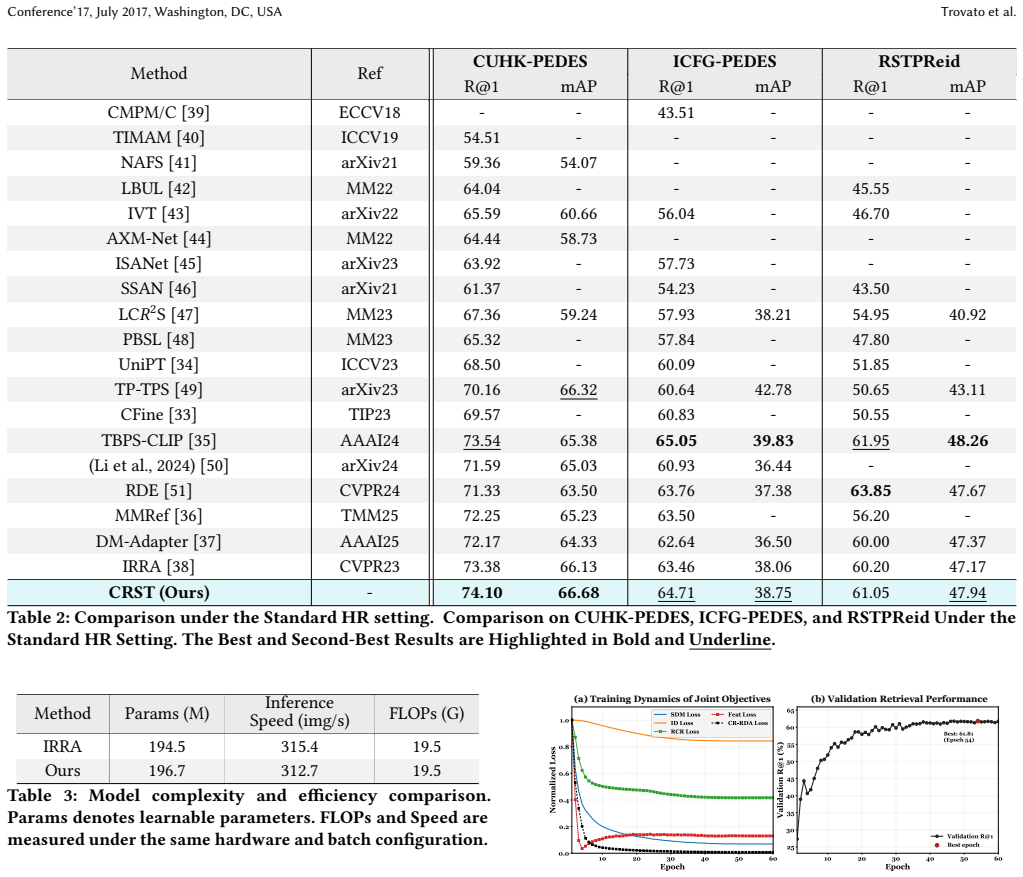
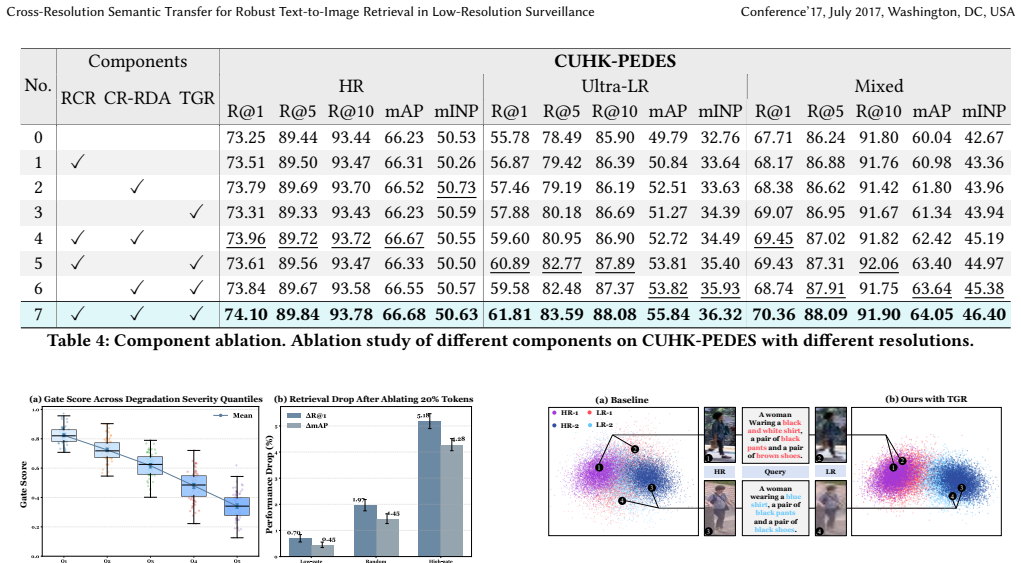
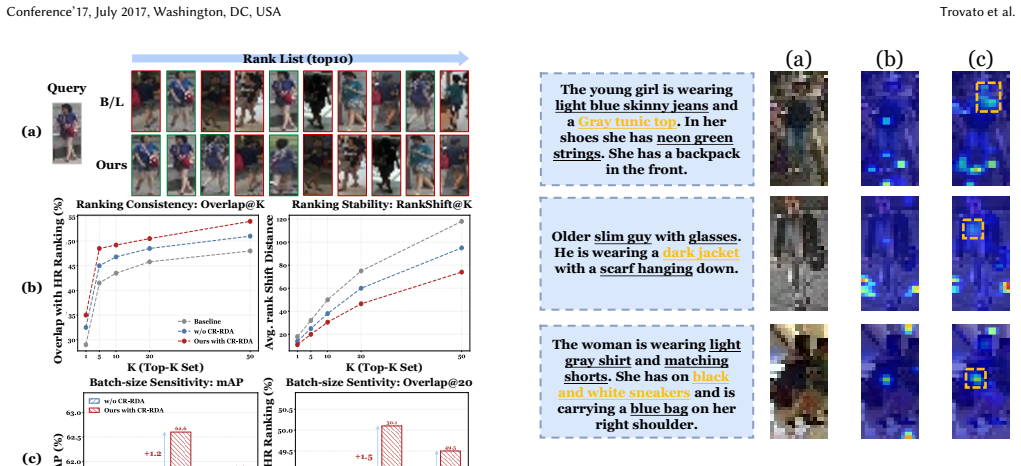
The central claim is that the CRST CLIP-style framework, built from resolution-conditioned reasoning to suppress unreliable tokens, text-guided refinement to inject semantic priors, and CR-RDA to transfer HR neighborhood geometry, mitigates evidence reliability collapse and ranking distribution drift, delivering 5.7 percent and 5.3 percent average gains in ultra-low-resolution Rank-1 and mAP on CUHK-PEDES, ICFG-PEDES, and RSTPReid while stabilizing mixed-resolution retrieval without loss on high-resolution data.
What carries the argument
Cross-Resolution Semantic Transfer (CRST) framework using resolution-conditioned reasoning, text-guided refinement, and CR-RDA to move semantic structure from high-resolution to low-resolution inputs.
If this is right
- Ultra-low-resolution Rank-1 rises 5.7 percent and mAP rises 5.3 percent on average across the three person re-identification benchmarks.
- Mixed-resolution galleries produce stable similarity rankings instead of distorted neighborhoods.
- High-resolution retrieval accuracy stays the same.
- The approach works inside existing CLIP-style text-to-image pipelines for surveillance.
Where Pith is reading between the lines
- The same resolution-conditioned token weighting could be tested on video retrieval or multi-camera tracking where frame quality also varies.
- Combining CRST with separate super-resolution preprocessing might produce additive gains on the lowest-resolution inputs.
- Deployment on live camera feeds would reveal whether the neighborhood transfer remains stable under streaming resolution changes.
Load-bearing premise
The three modules actually correct evidence reliability collapse and ranking distribution drift on data outside the three evaluation sets rather than merely fitting those sets.
What would settle it
Running CRST on a new surveillance dataset with previously unseen resolution mixtures and finding no gain in ultra-low-resolution Rank-1 or persistent ranking instability after applying the modules would falsify the claim.
Figures

read the original abstract
Text-to-image person re-identification (TIPR) retrieves target persons using natural language descriptions. However, existing methods largely overlook resolution variance in real-world surveillance. They characterize cross-resolution TIPR through two coupled failure modes: Evidence Reliability Collapse (ERC), where degraded visual tokens become unreliable for grounding fine-grained text, and Ranking Distribution Drift (RDD), where mixed-resolution galleries distort similarity neighborhoods and destabilize retrieval rankings. To address this challenge, we propose Cross-Resolution Semantic Transfer (CRST), a CLIP-style framework with three modules: resolution-conditioned reasoning, text-guided refinement and CR-RDA. Resolution-conditioned reasoning estimates token reliability to suppress corrupted evidence. Text-guided refinement injects semantic priors to recover discriminative cues. CR-RDA transfers HR neighborhood geometry to stabilize LR ranking under mixed resolutions. Experiments on CUHK-PEDES, ICFG-PEDES, and RSTPReid show that CRST improves ultra-low-resolution Rank-1 and mAP on average by 5.7% and 5.3%, while stabilizing mixed-resolution retrieval without sacrificing high-resolution accuracy.The code will be made publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Cross-Resolution Semantic Transfer (CRST), a CLIP-style framework for text-to-image person re-identification that targets resolution variance in surveillance imagery. It defines two coupled failure modes—Evidence Reliability Collapse (ERC) and Ranking Distribution Drift (RDD)—and proposes three modules (resolution-conditioned reasoning to estimate token reliability, text-guided refinement to inject semantic priors, and CR-RDA to transfer HR neighborhood geometry) to mitigate them. Experiments on CUHK-PEDES, ICFG-PEDES, and RSTPReid report average gains of 5.7% Rank-1 and 5.3% mAP in ultra-low-resolution settings while preserving high-resolution accuracy and stabilizing mixed-resolution retrieval; code release is promised.
Significance. If the modules demonstrably reduce ERC and RDD on unseen data rather than fitting the three evaluation sets, the work would provide a practical advance for real-world TIPR under variable surveillance resolutions. The explicit modeling of token reliability and cross-resolution neighborhood transfer is a targeted contribution, and the promised public code supports reproducibility.
major comments (2)
- [Experiments] Experiments section: All quantitative results are confined to CUHK-PEDES, ICFG-PEDES, and RSTPReid with no cross-dataset transfer, held-out surveillance collection, or explicit ERC/RDD metrics (e.g., token reliability scores or ranking stability measures). This leaves the central claim—that the three modules suppress ERC and RDD rather than capitalize on dataset idiosyncrasies—unverified and load-bearing for the reported 5.7%/5.3% gains.
- [Abstract] Abstract and Methods: No error bars, ablation controls, or dataset statistics are referenced, and the abstract provides no derivation details for how resolution-conditioned reasoning or CR-RDA are implemented or optimized. Without these, the soundness of the empirical gains cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address the major comments point-by-point below, indicating where revisions will be made to strengthen the manuscript while clarifying aspects already present in the work.
read point-by-point responses
-
Referee: [Experiments] Experiments section: All quantitative results are confined to CUHK-PEDES, ICFG-PEDES, and RSTPReid with no cross-dataset transfer, held-out surveillance collection, or explicit ERC/RDD metrics (e.g., token reliability scores or ranking stability measures). This leaves the central claim—that the three modules suppress ERC and RDD rather than capitalize on dataset idiosyncrasies—unverified and load-bearing for the reported 5.7%/5.3% gains.
Authors: The three datasets are the standard benchmarks for text-to-image person re-identification and already span multiple surveillance scenarios with varying resolution characteristics. Consistent gains across all three support that the improvements are not dataset-specific. We agree, however, that direct quantification of ERC and RDD would make the mechanistic claims more verifiable. In the revision we will add explicit metrics (token reliability scores before/after resolution-conditioned reasoning and ranking stability measures before/after CR-RDA) to the experiments section. Cross-dataset transfer and new held-out collections lie outside the current experimental scope; we will note this limitation explicitly. revision: partial
-
Referee: [Abstract] Abstract and Methods: No error bars, ablation controls, or dataset statistics are referenced, and the abstract provides no derivation details for how resolution-conditioned reasoning or CR-RDA are implemented or optimized. Without these, the soundness of the empirical gains cannot be assessed.
Authors: The abstract is a high-level summary; the methods section already contains the full mathematical formulations, optimization objectives, and architectural details for resolution-conditioned reasoning and CR-RDA. Ablation tables demonstrating module contributions are present in the experiments. We will add error bars to all reported results, include dataset statistics (image counts, resolution distributions), and ensure the abstract briefly references the core technical approach. These changes will be incorporated in the revised manuscript. revision: yes
- Addition of new held-out surveillance collections or full cross-dataset transfer experiments, which would require substantial new data acquisition and compute beyond the revision timeline.
Circularity Check
No circularity; derivation self-contained with no reductions to inputs
full rationale
The provided abstract and description introduce CRST as a CLIP-style framework with three additive modules (resolution-conditioned reasoning, text-guided refinement, CR-RDA) to mitigate ERC and RDD failure modes, reporting empirical gains on three standard datasets. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the text. The central claims rest on experimental results rather than any derivation that reduces by construction to its own inputs or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kai Niu, Yanyi Liu, Yuzhou Long, Yan Huang, Liang Wang, and Yanning Zhang
-
[2]
An overview of text-based person search: recent advances and future directions.IEEE Transactions on Circuits and Systems for Video Technology, 34, 9, 7803–7819
- [3]
-
[4]
Yukang Zhang and Hanzi Wang. 2023. Diverse embedding expansion net- work and low-light cross-modality benchmark for visible-infrared person re- identification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2153–2162
2023
-
[5]
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev
-
[6]
InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2818–2829
Reproducible scaling laws for contrastive language-image learning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2818–2829
-
[9]
Byoungjip Kim, Sungik Choi, Dasol Hwang, Moontae Lee, and Honglak Lee
-
[10]
Transferring pre-trained multimodal representations with cross-modal similarity matching.Advances in Neural Information Processing Systems, 35, 30826–30839
-
[11]
Xiaohan Xu, Ming Li, Chongyang Tao, Tao Shen, Reynold Cheng, Jinyang Li, Can Xu, Dacheng Tao, and Tianyi Zhou. 2024. A survey on knowledge distillation of large language models.arXiv preprint arXiv:2402.13116
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Zongzong Wu, Xiangchun Yu, Donglin Zhu, Qingwei Pang, Shitao Shen, Teng Ma, and Jian Zheng. 2022. Sr-dsff and fenet-reid: a two-stage approach for cross resolution person re-identification.Computational Intelligence and Neuroscience, 2022, 1, 4398727
2022
-
[13]
Shuanglin Yan, Jun Liu, Neng Dong, Liyan Zhang, and Jinhui Tang. 2025. Cross- modal collaborative representation learning for text-to-image person retrieval. InProceedings of the thirty-fourth international joint conference on artificial intelligence (IJCAI-25)
2025
-
[14]
Bin Yang, Jun Chen, Cuiqun Chen, and Mang Ye. 2023. Dual consistency- constrained learning for unsupervised visible-infrared person re-identification. IEEE Transactions on Information Forensics and Security
2023
-
[15]
Wentan Tan, Changxing Ding, Jiayu Jiang, Fei Wang, Yibing Zhan, and Dapeng Tao. 2024. Harnessing the power of mllms for transferable text-to-image person reid. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 17127–17137
2024
-
[16]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: boot- strapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning. PMLR, 19730– 19742
2023
-
[17]
Zhangyi Hu, Bin Yang, and Mang Ye. [n. d.] Empowering visible-infrared person re-identification with large foundation models. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems
-
[18]
Bin Yang, Jun Chen, Xianzheng Ma, and Mang Ye. 2023. Translation, associa- tion and augmentation: learning cross-modality re-identification from single- modality annotation.IEEE Transactions on Image Processing
2023
-
[19]
Lin Yuanbo Wu, Lingqiao Liu, Yang Wang, Zheng Zhang, Farid Boussaid, Mohammed Bennamoun, and Xianghua Xie. 2023. Learning resolution-adaptive representations for cross-resolution person re-identification.IEEE Transactions on Image Processing, 32, 4800–4811
2023
-
[20]
Yukang Zhang, Yan Yan, Yang Lu, and Hanzi Wang. 2021. Towards a uni- fied middle modality learning for visible-infrared person re-identification. In Proceedings of the 29th ACM International Conference on Multimedia, 788–796
2021
-
[21]
Delong Liu, Haiwen Li, Zhicheng Zhao, and Yuan Dong. 2025. Text-guided image restoration and semantic enhancement for text-to-image person retrieval. Neural Networks, 184, 107028
2025
-
[22]
Zhiqi Pang, Lingling Zhao, and Chunyu Wang. 2024. Dual-resolution fusion modeling for unsupervised cross-resolution person re-identification. InPro- ceedings of the 32nd ACM international conference on multimedia, 4063–4072
2024
-
[23]
Yukang Zhang, Yan Yan, Jie Li, and Hanzi Wang. 2023. Mrcn: a novel modality restitution and compensation network for visible-infrared person re-identification. InProceedings of the AAAI Conference on Artificial Intelligencenumber 3. Vol. 37, 3498–3506
2023
-
[24]
Fanzhi Jiang, Su Yang, Mark W Jones, and Liumei Zhang. 2025. From at- tributes to natural language: a survey and foresight on text-based person re-identification.Information Fusion, 118, 102879
2025
-
[25]
Bin Yang, Jun Chen, and Mang Ye. 2023. Towards grand unified representation learning for unsupervised visible-infrared person re-identification. InProceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV). (Oct. 2023), 11069–11079
2023
-
[26]
Bin Yang, Mang Ye, Jun Chen, and Zesen Wu. 2022. Augmented dual-contrastive aggregation learning for unsupervised visible-infrared person re-identification. InACM MM, 2843–2851
2022
-
[27]
Yunyao Mao, Wengang Zhou, Zhenbo Lu, Jiajun Deng, and Houqiang Li. 2022. Cmd: self-supervised 3d action representation learning with cross-modal mu- tual distillation. InEuropean Conference on Computer Vision. Springer, 734– 752
2022
-
[28]
Zhenyu Cui, Jiahuan Zhou, and Yuxin Peng. 2024. Dma: dual modality-aware alignment for visible-infrared person re-identification.IEEE Transactions on Information Forensics and Security, 19, 2696–2708
2024
-
[29]
Alexey Dosovitskiy. 2020. An image is worth 16x16 words: transformers for image recognition at scale.arXiv preprint arXiv:2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[30]
Chuanguang Yang, Zhulin An, Libo Huang, Junyu Bi, Xinqiang Yu, Han Yang, Boyu Diao, and Yongjun Xu. 2024. Clip-kd: an empirical study of clip model distillation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 15952–15962
2024
-
[31]
Xiao Wang, Lekai Liu, Bin Yang, Mang Ye, Zheng Wang, and Xin Xu. 2025. To- kenmatcher: diverse tokens matching for unsupervised visible-infrared person re-identification. InProceedings of the AAAI Conference on Artificial Intelligence number 8. Vol. 39, 7934–7942
2025
-
[32]
Bin Yang, Jun Chen, and Mang Ye. 2024. Shallow-deep collaborative learning for unsupervised visible-infrared person re-identification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 16870–16879
2024
-
[33]
Yukang Zhang, Xinwen Fan, Yujun Yang, Yang Lu, and Hanzi Wang. 2025. Image-attribute and frequency-spatial dual collaborative learning for pedes- trian attribute recognition.IEEE Transactions on Information Forensics and Security, 20, 11715–11727
2025
-
[34]
Kanchana Vaishnavi Gandikota and Paramanand Chandramouli. 2024. Text- guided explorable image super-resolution. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, 25900–25911
2024
-
[35]
Youbo Lei, Feifei He, Chen Chen, Yingbin Mo, Sijia Li, Defeng Xie, and Haonan Lu. 2024. Mcad: multi-teacher cross-modal alignment distillation for efficient image-text retrieval. InFindings of the Association for Computational Linguistics: NAACL 2024, 1491–1503
2024
-
[36]
Shuping Hui, Min Wang, Hui Wu, Wengang Zhou, and Houqiang Li. 2025. Csd: cross-modal similarity distillation for zero-shot composed image retrieval. In Proceedings of the 6th Workshop on Intelligent Cross-Data Analysis and Retrieval, 1–8
2025
-
[37]
Shuanglin Yan, Neng Dong, Liyan Zhang, and Jinhui Tang. 2023. Clip-driven fine-grained text-image person re-identification.IEEE Transactions on Image Processing, 32, 6032–6046
2023
-
[38]
Zhiyin Shao, Xinyu Zhang, Changxing Ding, Jian Wang, and Jingdong Wang
-
[39]
InProceedings of the IEEE/CVF international conference on com- puter vision, 11174–11184
Unified pre-training with pseudo texts for text-to-image person re- identification. InProceedings of the IEEE/CVF international conference on com- puter vision, 11174–11184
-
[40]
Min Cao, Yang Bai, Ziyin Zeng, Mang Ye, and Min Zhang. 2024. An empirical study of clip for text-based person search. InProceedings of the AAAI Conference on Artificial Intelligence. Vol. 38, 465–473
2024
-
[41]
Zehong Ma, Hao Chen, Wei Zeng, Limin Su, and Shiliang Zhang. 2025. Multi- modal reference learning for fine-grained text-to-image retrieval.IEEE Trans- actions on Multimedia
2025
-
[42]
Yating Liu, Zimo Liu, Xiangyuan Lan, Wenming Yang, Yaowei Li, and Qingmin Liao. 2025. Dm-adapter: domain-aware mixture-of-adapters for text-based person retrieval. InProceedings of the AAAI Conference on Artificial Intelligence number 6. Vol. 39, 5703–5711. Conference’17, July 2017, Washington, DC, USA Trovato et al
2025
-
[43]
Ding Jiang and Mang Ye. 2023. Cross-modal implicit relation reasoning and aligning for text-to-image person retrieval. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2787–2797
2023
-
[44]
Ying Zhang and Huchuan Lu. 2018. Deep cross-modal projection learning for image-text matching. InProceedings of the European conference on computer vision (ECCV), 686–701
2018
-
[45]
Nikolaos Sarafianos, Xiang Xu, and Ioannis A Kakadiaris. 2019. Adversarial rep- resentation learning for text-to-image matching. InProceedings of the IEEE/CVF international conference on computer vision, 5814–5824
2019
- [46]
-
[47]
Zijie Wang, Aichun Zhu, Jingyi Xue, Xili Wan, Chao Liu, Tian Wang, and Yifeng Li. 2022. Look before you leap: improving text-based person retrieval by learning a consistent cross-modal common manifold. InProceedings of the 30th ACM international conference on multimedia, 1984–1992
2022
-
[48]
Xiujun Shu, Wei Wen, Haoqian Wu, Keyu Chen, Yiran Song, Ruizhi Qiao, Bo Ren, and Xiao Wang. 2022. See finer, see more: implicit modality alignment for text-based person retrieval. InEuropean Conference on Computer Vision. Springer, 624–641
2022
-
[49]
Ammarah Farooq, Muhammad Awais, Josef Kittler, and Syed Safwan Khalid
-
[50]
InProceedings of the AAAI conference on artificial intelligence
Axm-net: implicit cross-modal feature alignment for person re-identification. InProceedings of the AAAI conference on artificial intelligence. Vol. 36, 4477– 4485
-
[51]
Shuanglin Yan, Hao Tang, Liyan Zhang, and Jinhui Tang. 2023. Image-specific information suppression and implicit local alignment for text-based person search.IEEE transactions on neural networks and learning systems
2023
- [52]
-
[53]
Shuanglin Yan, Neng Dong, Jun Liu, Liyan Zhang, and Jinhui Tang. 2023. Learning comprehensive representations with richer self for text-to-image person re-identification. InProceedings of the 31st ACM international conference on multimedia, 6202–6211
2023
-
[54]
Fei Shen, Xiangbo Shu, Xiaoyu Du, and Jinhui Tang. 2023. Pedestrian-specific bipartite-aware similarity learning for text-based person retrieval. InProceed- ings of the 31st ACM International Conference on Multimedia, 8922–8931
2023
- [55]
- [56]
-
[57]
Yang Qin, Yingke Chen, Dezhong Peng, Xi Peng, Joey Tianyi Zhou, and Peng Hu
-
[58]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 27197–27206
Noisy-correspondence learning for text-to-image person re-identification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 27197–27206
-
[59]
Shuang Li, Tong Xiao, Hongsheng Li, Bolei Zhou, Dayu Yue, and Xiaogang Wang. 2017. Person search with natural language description. InProceedings of the IEEE conference on computer vision and pattern recognition, 1970–1979
2017
-
[60]
Liang Zheng, Liyue Shen, Lu Tian, Shengjin Wang, Jingdong Wang, and Qi Tian. 2015. Scalable person re-identification: a benchmark. InProceedings of the IEEE international conference on computer vision, 1116–1124
2015
-
[61]
Xiying Zheng, Yukang Zhang, Yang Lu, and Hanzi Wang. 2024. Semi-supervised visible-infrared person re-identification via modality unification and confi- dence guidance. InProceedings of the 32nd ACM International Conference on Multimedia, 5761–5770
2024
-
[62]
Yukang Zhang, Yan Yan, Yang Lu, and Hanzi Wang. 2024. Adaptive middle modality alignment learning for visible-infrared person re-identification.Inter- national Journal of Computer Vision, 1–21
2024
-
[63]
Mang Ye, Jianbing Shen, Gaojie Lin, Tao Xiang, Ling Shao, and Steven CH Hoi
-
[64]
Deep learning for person re-identification: a survey and outlook.IEEE transactions on pattern analysis and machine intelligence, 44, 6, 2872–2893
- [65]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.