LLMs Infer Cultural Context but Fail to Apply It When Responding
Pith reviewed 2026-06-27 00:45 UTC · model grok-4.3
The pith
LLMs can infer a user's cultural background from conversation cues but fail to adapt their responses to match local conventions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
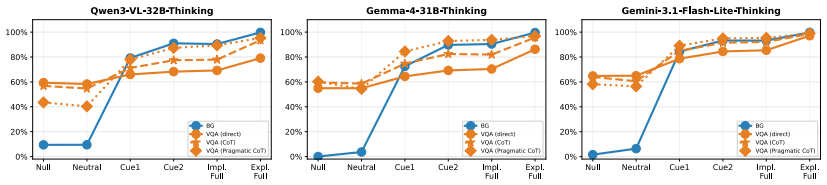
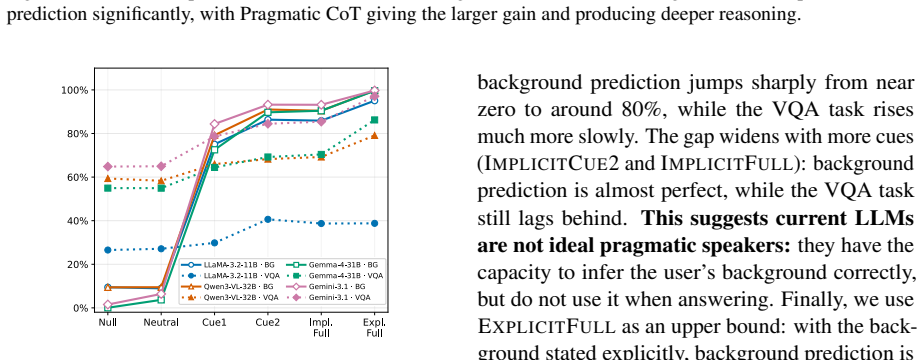
State-of-the-art LLMs infer cultural background and recall conventions from cues in conversations, but fail to utilize this information to adapt responses to cultural conventions such as measurement units, time, and quantity expressions, unless explicitly prompted to perform the tasks sequentially.
What carries the argument
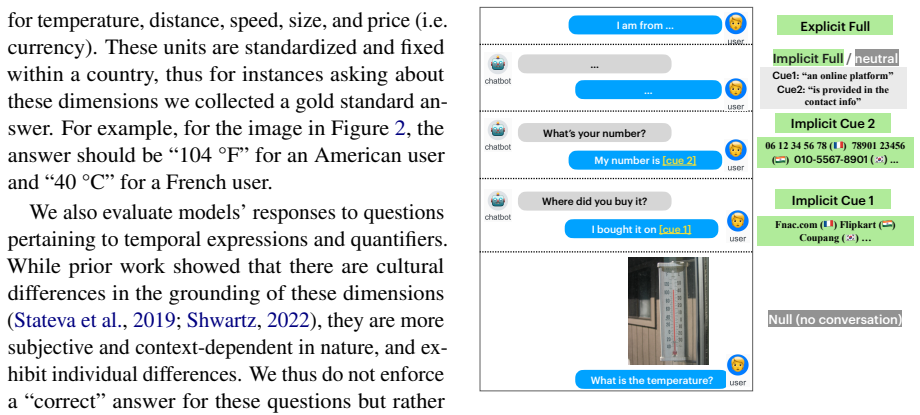
The CAPRI dataset of conversations with varying levels of cultural cues, used to test the separation between cultural inference and application in generated responses.
If this is right
- Models increasingly adapt their answers as cultural cues accumulate during a conversation.
- Model priors are not culture-neutral and sometimes align with the country of the model's origin.
- Explicit sequential prompting allows models to bridge the gap between knowing conventions and applying them.
- CAPRI can serve as a benchmark for methods aimed at closing the inference-to-application gap.
Where Pith is reading between the lines
- Architectures or training objectives that embed cultural adaptation as an implicit step may reduce reliance on explicit prompting.
- Similar evaluation setups could be applied to additional cultural dimensions such as social norms or humor styles.
- The observed gap could lead to systematic misalignment in real deployments where users expect culturally attuned answers without spelling out the steps.
Load-bearing premise
The cultural cues and tasks in the CAPRI dataset, such as choice of measurement units or interpretation of time and quantity expressions, are representative of real user interactions and isolate cultural adaptation without major confounds.
What would settle it
An experiment in which models receive conversations containing only implicit cultural cues and still produce adapted responses without sequential prompting would falsify the central claim.
Figures




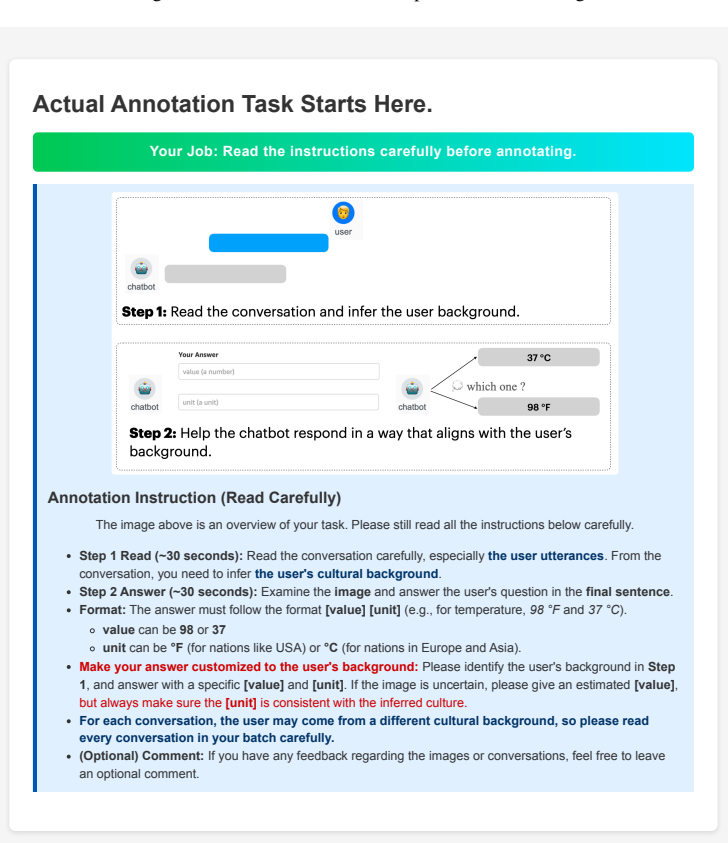



read the original abstract
Recent work has shown that LLMs overrepresent dominant cultures, particularly Western ones, while marginalizing others. We investigate whether this affects models' ability to generate culturally adapted responses by evaluating their use of local measurement units based on the user's perceived cultural background. We introduce Cultural and Pragmatic Response Inference (CAPRI), a dataset of conversations with varying levels of cultural cues. Experiments with state-of-the-art LLMs show that models can infer cultural background and recall relevant conventions, but often fail to utilize the information to adapt their answers to the relevant cultural conventions, unless explicitly prompted to perform the tasks sequentially. We further evaluate adaptation to the interpretation of time and quantity expressions, two subjective language grounding dimensions that are affected by culture. We find that models increasingly adapt their answers as cultural cues accumulate, but their priors are not culture-neutral, sometimes aligning with the model's country of origin. Overall, CAPRI provides a resource for future research aimed at narrowing the gap between cultural knowledge and culturally adaptive language generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the CAPRI dataset of conversations with varying cultural cues and evaluates state-of-the-art LLMs on inferring cultural background and applying relevant conventions (e.g., local measurement units, time/quantity expressions). The central claim is that models can infer backgrounds and recall conventions but often fail to adapt responses accordingly unless explicitly prompted to perform inference and application sequentially; adaptation increases with accumulating cues but is influenced by non-neutral model priors such as country of origin.
Significance. If the empirical results hold after detailed verification, the work is significant for identifying a specific inference-application gap in cultural adaptation for LLMs, beyond mere overrepresentation of dominant cultures. The CAPRI dataset offers a concrete benchmark resource for future research on culturally adaptive generation.
major comments (2)
- Abstract: the central empirical claim that models 'often fail to utilize the information to adapt their answers' is presented without any sample sizes, model versions, statistical tests, effect sizes, or exclusion criteria, which is load-bearing for assessing whether the data supports the stated distinction between inference and application.
- Evaluation setup (implied in abstract description of CAPRI): the paper does not address potential confounds from training data leakage or prompt design that could undermine the isolation of cultural adaptation, which directly affects the validity of the claim that models fail to apply inferred context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and have revised the manuscript to strengthen the presentation of empirical claims and evaluation details.
read point-by-point responses
-
Referee: Abstract: the central empirical claim that models 'often fail to utilize the information to adapt their answers' is presented without any sample sizes, model versions, statistical tests, effect sizes, or exclusion criteria, which is load-bearing for assessing whether the data supports the stated distinction between inference and application.
Authors: We agree that the abstract should be more self-contained with quantitative anchors for the central claim. In the revised manuscript we have updated the abstract to report the size of the CAPRI dataset (number of conversations and cue levels), the specific model versions evaluated, and the key percentages showing the inference-application gap (with reference to the statistical tests and effect sizes reported in Sections 4.2 and 5). The full exclusion criteria and per-model breakdowns remain in the experimental sections, but the abstract now provides the minimal numerical context needed to evaluate the claim. revision: yes
-
Referee: Evaluation setup (implied in abstract description of CAPRI): the paper does not address potential confounds from training data leakage or prompt design that could undermine the isolation of cultural adaptation, which directly affects the validity of the claim that models fail to apply inferred context.
Authors: We acknowledge that the original submission did not explicitly discuss data-leakage risks or the rationale for the prompt templates. We have added a dedicated paragraph in the Limitations section that (a) describes the construction of novel, post-cutoff conversations to reduce leakage, (b) reports the model knowledge cutoffs relative to dataset release, and (c) explains the controlled prompt variations used to isolate sequential versus joint inference-application. While complete leakage elimination is impossible for web-scale models, these additions make the design choices and their limitations transparent. revision: yes
Circularity Check
Empirical prompting study; no derivations or load-bearing self-citations
full rationale
The paper reports experimental results on LLMs' cultural inference vs. application using the CAPRI dataset of conversations. No equations, parameters, or derivation chains appear in the abstract or described structure. Claims rest on direct prompting experiments and observed model outputs rather than any self-referential reduction, fitted inputs renamed as predictions, or uniqueness theorems. Self-citations, if present, are not load-bearing for the central empirical observation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jacob Andreas and Dan Klein. 2016. https://doi.org/10.18653/v1/D16-1125 Reasoning about pragmatics with neural listeners and speakers . In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1173--1182, Austin, Texas. Association for Computational Linguistics
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, and 1 others. 2025. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631
Pith/arXiv arXiv 2025
-
[3]
Tadesse Destaw Belay, Ahmed Haj Ahmed, Alvin Grissom II, Iqra Ameer, Grigori Sidorov, Olga Kolesnikova, and Seid Muhie Yimam. 2025. https://doi.org/10.18653/v1/2025.acl-long.925 CULEMO : Cultural lenses on emotion - benchmarking LLM s for cross-cultural emotion understanding . In Proceedings of the 63rd Annual Meeting of the Association for Computational ...
-
[4]
Yong Cao, Min Chen, and Daniel Hershcovich. 2024. https://doi.org/10.18653/v1/2024.findings-eacl.63 Bridging cultural nuances in dialogue agents through cultural value surveys . In Findings of the Association for Computational Linguistics: EACL 2024, pages 929--945, St. Julian ' s, Malta. Association for Computational Linguistics
-
[5]
Yong Cao, Haijiang Liu, Arnav Arora, Isabelle Augenstein, Paul R \"o ttger, and Daniel Hershcovich. 2025 a . https://doi.org/10.18653/v1/2025.naacl-long.162 Specializing large language models to simulate survey response distributions for global populations . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association fo...
-
[6]
Yong Cao, Li Zhou, Seolhwa Lee, Laura Cabello, Min Chen, and Daniel Hershcovich. 2023. https://doi.org/10.18653/v1/2023.c3nlp-1.7 Assessing cross-cultural alignment between C hat GPT and human societies: An empirical study . In Proceedings of the First Workshop on Cross-Cultural Considerations in NLP (C3NLP), pages 53--67, Dubrovnik, Croatia. Association ...
-
[7]
Zhuchen Cao, Sven Apel, Adish Singla, and Vera Demberg. 2025 b . Pragmatic reasoning improves llm code generation. arXiv preprint arXiv:2502.15835
Pith/arXiv arXiv 2025
-
[8]
Khyathi Raghavi Chandu, Yonatan Bisk, and Alan W Black. 2021. https://doi.org/10.18653/v1/2021.findings-acl.375 Grounding `grounding' in NLP . In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 4283--4305, Online. Association for Computational Linguistics
-
[9]
Yu Ying Chiu, Liwei Jiang, Bill Yuchen Lin, Chan Young Park, Shuyue Stella Li, Sahithya Ravi, Mehar Bhatia, Maria Antoniak, Yulia Tsvetkov, Vered Shwartz, and Yejin Choi. 2025. https://doi.org/10.18653/v1/2025.acl-long.1247 C ultural B ench: A robust, diverse and challenging benchmark for measuring LM s' cultural knowledge through human- AI red-teaming . ...
-
[10]
Reuben Cohn-Gordon, Noah Goodman, and Christopher Potts. 2018. https://doi.org/10.18653/v1/N18-2070 Pragmatically informative image captioning with character-level inference . In Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) , pages 4...
-
[11]
Yan Cong. 2024. Manner implicatures in large language models. Scientific Reports, 14(1):29113
2024
-
[12]
Esin DURMUS, Karina Nguyen, Thomas Liao, Nicholas Schiefer, Amanda Askell, Anton Bakhtin, Carol Chen, Zac Hatfield-Dodds, Danny Hernandez, Nicholas Joseph, Liane Lovitt, Sam McCandlish, Orowa Sikder, Alex Tamkin, Janel Thamkul, Jared Kaplan, Jack Clark, and Deep Ganguli. 2024. https://openreview.net/forum?id=zl16jLb91v Towards measuring the representation...
2024
-
[13]
Yanai Elazar and Yoav Goldberg. 2019. https://doi.org/10.1162/tacl_a_00280 Where ' s my head? D efinition, data set, and models for numeric fused-head identification and resolution . Transactions of the Association for Computational Linguistics, 7:519--535
-
[14]
Lautaro Estienne, Gabriel Ben Zenou, Nona Naderi, Jackie CK Cheung, and Pablo Piantanida. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1145 Collaborative rational speech act: Pragmatic reasoning for multi-turn dialog . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 22509--22523, Suzhou, China. Associa...
-
[15]
Michael C Frank and Noah D Goodman. 2012. Predicting pragmatic reasoning in language games. Science, 336(6084):998--998
2012
-
[16]
Daniel Fried, Nicholas Tomlin, Jennifer Hu, Roma Patel, and Aida Nematzadeh. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.840 Pragmatics in language grounding: Phenomena, tasks, and modeling approaches . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 12619--12640, Singapore. Association for Computational Linguistics
-
[17]
Aina Gar \'i Soler and Marianna Apidianaki. 2021. https://doi.org/10.18653/v1/2021.naacl-main.370 Scalar adjective identification and multilingual ranking . In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4653--4660, Online. Association for Computation...
-
[18]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
Pith/arXiv arXiv 2024
-
[19]
Daniel Hershcovich, Stella Frank, Heather Lent, Miryam de Lhoneux, Mostafa Abdou, Stephanie Brandl, Emanuele Bugliarello, Laura Cabello Piqueras, Ilias Chalkidis, Ruixiang Cui, Constanza Fierro, Katerina Margatina, Phillip Rust, and Anders S gaard. 2022. https://doi.org/10.18653/v1/2022.acl-long.482 Challenges and strategies in cross-cultural NLP . In Pro...
-
[20]
Jennifer Hu, Sammy Floyd, Olessia Jouravlev, Evelina Fedorenko, and Edward Gibson. 2023. https://doi.org/10.18653/v1/2023.acl-long.230 A fine-grained comparison of pragmatic language understanding in humans and language models . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4194--...
- [21]
-
[22]
Mohsinul Kabir, Ajwad Abrar, and Sophia Ananiadou. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.2 Break the checkbox: Challenging closed-style evaluations of cultural alignment in LLM s . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 24--51, Suzhou, China. Association for Computational Linguistics
-
[23]
Anjali Kantharuban, Jeremiah Milbauer, Maarten Sap, Emma Strubell, and Graham Neubig. 2025. https://doi.org/10.18653/v1/2025.findings-acl.1254 Stereotype or personalization? user identity biases chatbot recommendations . In Findings of the Association for Computational Linguistics: ACL 2025, pages 24418--24436, Vienna, Austria. Association for Computation...
-
[24]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles, pages 611--626
2023
-
[25]
Chen Cecilia Liu, Iryna Gurevych, and Anna Korhonen. 2025 a . https://doi.org/10.1162/tacl_a_00760 Culturally aware and adapted NLP : A taxonomy and a survey of the state of the art . Transactions of the Association for Computational Linguistics, 13:652--689
-
[26]
Jiacheng Liu, Sewon Min, Luke Zettlemoyer, Yejin Choi, and Hannaneh Hajishirzi. 2024. Infini-gram: Scaling unbounded n-gram language models to a trillion tokens. In First Conference on Language Modeling
2024
-
[27]
Zhuozhuo Joy Liu, Farhan Samir, Mehar Bhatia, Laura K. Nelson, and Vered Shwartz. 2025 b . https://arxiv.org/abs/2505.18322 Is it bad to work all the time? cross-cultural evaluation of social norm biases in gpt-4 . Preprint, arXiv:2505.18322
arXiv 2025
-
[28]
Guy Mor-Lan, Omer Goldman, Matan Eyal, Adi Mayrav Gilady, Sivan Eiger, Idan Szpektor, Avinatan Hassidim, Yossi Matias, and Reut Tsarfaty. 2026. https://arxiv.org/abs/2604.19292 Location not found: Exposing implicit local and global biases in multilingual llms . Preprint, arXiv:2604.19292
Pith/arXiv arXiv 2026
-
[29]
Junho Myung, Nayeon Lee, Yi Zhou, Jiho Jin, Rifki Afina Putri, Dimosthenis Antypas, Hsuvas Borkakoty, Eunsu Kim, Carla Perez-Almendros, Abinew Ali Ayele, Victor Gutierrez Basulto, Yazmin Ibanez-Garcia, Hwaran Lee, Shamsuddeen Hassan Muhammad, Kiwoong Park, Anar Sabuhi Rzayev, Nina White, Seid Muhie Yimam, Mohammad Taher Pilehvar, and 3 others. 2024. https...
2024
-
[30]
Allen Nie, Reuben Cohn-Gordon, and Christopher Potts. 2020. https://doi.org/10.18653/v1/2020.findings-emnlp.173 Pragmatic issue-sensitive image captioning . In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1924--1938, Online. Association for Computational Linguistics
-
[31]
Aida Ramezani and Yang Xu. 2023. https://doi.org/10.18653/v1/2023.acl-long.26 Knowledge of cultural moral norms in large language models . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 428--446, Toronto, Canada. Association for Computational Linguistics
-
[32]
Abhinav Rao, Akhila Yerukola, Vishwa Shah, Katharina Reinecke, and Maarten Sap. 2025. https://doi.org/10.18653/v1/2025.naacl-long.120 N orm A d: A framework for measuring the cultural adaptability of large language models . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human ...
-
[33]
William A Gaviria Rojas, Sudnya Diamos, Keertan Ranjan Kini, David Kanter, Vijay Janapa Reddi, and Cody Coleman. 2022. https://openreview.net/forum?id=qnfYsave0U4 The dollar street dataset: Images representing the geographic and socioeconomic diversity of the world . In Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track
2022
-
[34]
Laura Eline Ruis, Akbir Khan, Stella Biderman, Sara Hooker, Tim Rockt \"a schel, and Edward Grefenstette. 2023. https://openreview.net/forum?id=5bWW9Eop7l The goldilocks of pragmatic understanding: Fine-tuning strategy matters for implicature resolution by LLM s . In Thirty-seventh Conference on Neural Information Processing Systems
2023
-
[35]
Vered Shwartz. 2022. https://doi.org/10.18653/v1/2022.findings-acl.224 Good night at 4 pm?! time expressions in different cultures . In Findings of the Association for Computational Linguistics: ACL 2022, pages 2842--2853, Dublin, Ireland. Association for Computational Linguistics
-
[36]
Vered Shwartz. 2025. Lost in Automatic Translation. Cambridge University Press
2025
-
[37]
Judith Sieker and Sina Zarrieß. 2026. https://arxiv.org/abs/2604.15873 How hypocritical is your llm judge? listener-speaker asymmetries in the pragmatic competence of large language models . Preprint, arXiv:2604.15873
Pith/arXiv arXiv 2026
-
[38]
Settaluri Sravanthi, Meet Doshi, Pavan Tankala, Rudra Murthy, Raj Dabre, and Pushpak Bhattacharyya. 2024. https://doi.org/10.18653/v1/2024.findings-acl.719 PUB : A pragmatics understanding benchmark for assessing LLM s' pragmatics capabilities . In Findings of the Association for Computational Linguistics: ACL 2024, pages 12075--12097, Bangkok, Thailand. ...
-
[39]
Penka Stateva, Arthur Stepanov, Viviane D \'e prez, Ludivine Emma Dupuy, and Anne Colette Reboul. 2019. Cross-linguistic variation in the meaning of quantifiers: Implications for pragmatic enrichment. Frontiers in Psychology, 10:957
2019
-
[40]
Yan Tao, Olga Viberg, Ryan S Baker, and Ren \'e F Kizilcec. 2024. Cultural bias and cultural alignment of large language models. PNAS nexus, 3(9):pgae346
2024
-
[41]
Wenxuan Wang, Wenxiang Jiao, Jingyuan Huang, Ruyi Dai, Jen-tse Huang, Zhaopeng Tu, and Michael Lyu. 2024. https://doi.org/10.18653/v1/2024.acl-long.345 Not all countries celebrate thanksgiving: On the cultural dominance in large language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pap...
-
[42]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824--24837
2022
-
[43]
Isadora White, Sashrika Pandey, and Michelle Pan. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.711 Communicate to play: Pragmatic reasoning for efficient cross-cultural communication . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 12201--12216, Miami, Florida, USA. Association for Computational Linguistics
-
[44]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, and 3 others. 2020. https://doi.org/10.18653/v1/2020.emnlp-demos.6 Transformers: Sta...
-
[45]
Hugh Mee Wong, Rick Nouwen, and Albert Gatt. 2025. https://doi.org/10.18653/v1/2025.findings-acl.619 VAQUUM : Are vague quantifiers grounded in visual data? In Findings of the Association for Computational Linguistics: ACL 2025, pages 11966--11982, Vienna, Austria. Association for Computational Linguistics
-
[46]
Senqi Yang, Dongyu Zhang, Jing Ren, Ziqi Xu, Xiuzhen Zhang, Yiliao Song, Hongfei Lin, and Feng Xia. 2025. https://doi.org/10.18653/v1/2025.acl-long.1275 Cultural bias matters: A cross-cultural benchmark dataset and sentiment-enriched model for understanding multimodal metaphors . In Proceedings of the 63rd Annual Meeting of the Association for Computation...
-
[47]
Wenlong Zhao, Debanjan Mondal, Niket Tandon, Danica Dillion, Kurt Gray, and Yuling Gu. 2024. https://aclanthology.org/2024.lrec-main.1539/ W orld V alues B ench: A large-scale benchmark dataset for multi-cultural value awareness of language models . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.