Test-Time Deep Thinking to Explore Implicit Rules
Pith reviewed 2026-06-30 11:50 UTC · model grok-4.3
The pith
A thinker component infers hidden constraints from interaction history to guide agents past repetitive trial-and-error in implicit-rule environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
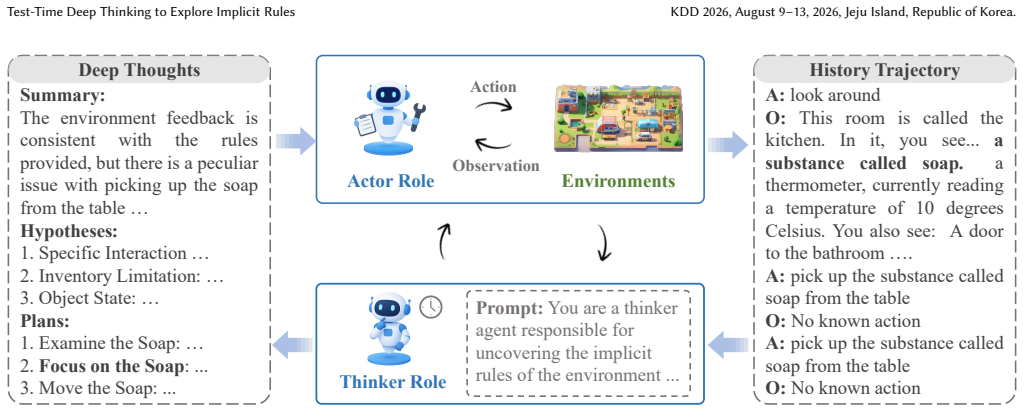
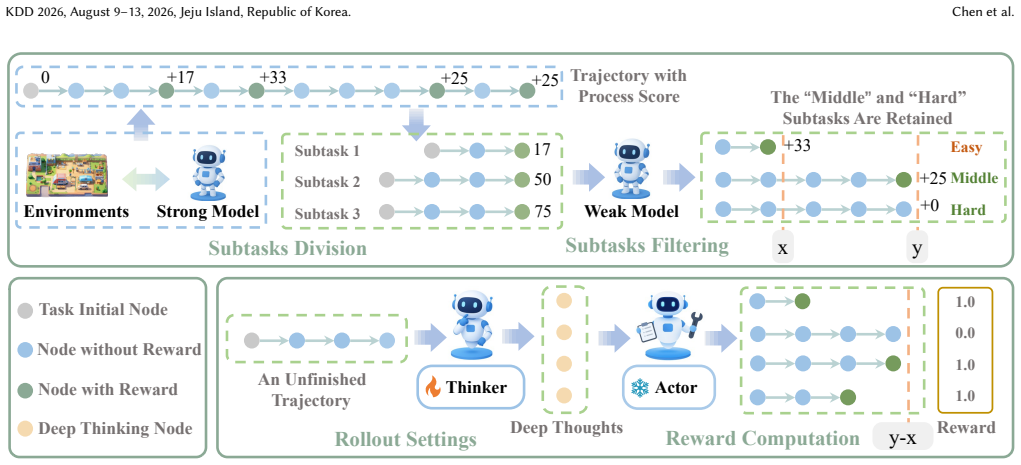
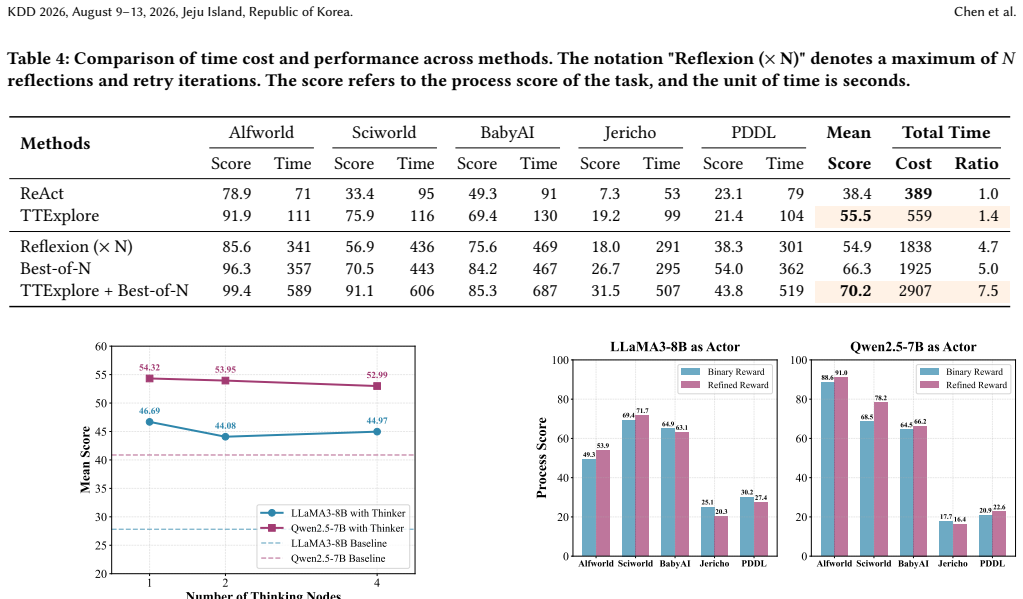
TTExplore equips an agent with a thinker that reads the full interaction history and outputs inferred implicit rules; these rules then condition the actor's policy so that the agent avoids unproductive actions. The thinker itself is trained by a reinforcement-learning pipeline that treats the binary task-completion outcome as the sole reward and collapses each trajectory to a single retained thinking node, thereby converting an otherwise sparse and unstable credit-assignment problem into a tractable optimization.
What carries the argument
The TTExplore loop pairing a history-reading thinker with a rule-conditioned actor, trained by single-node retention under task-level success rewards.
If this is right
- Agents become able to exit repetitive loops once the thinker supplies the missing constraint.
- The same single-node RL pipeline can be reused to train thinkers for any task whose success is observable at the end of an episode.
- Specialized 7B-scale models can be produced that outperform generic LLMs at rule inference inside embodied settings.
- The separation of thinker and actor makes it possible to swap either component without retraining the other.
Where Pith is reading between the lines
- The method could be tested in continuous-control or vision-based simulators to check whether text-only history remains sufficient when rules involve spatial or physical regularities.
- If the single retained node is chosen by highest final reward, the approach implicitly performs a form of self-distillation that might be compared against full-trajectory methods.
- The framework suggests that explicit rule extraction at test time may complement chain-of-thought prompting when the environment supplies delayed feedback.
Load-bearing premise
Task-completion scores supply an unbiased and sufficiently rich training signal for the thinker to learn correct implicit-rule inference.
What would settle it
Inspection of the thinker's outputs on held-out episodes reveals that the inferred rules are systematically incorrect yet the reported performance gains still appear.
Figures






read the original abstract
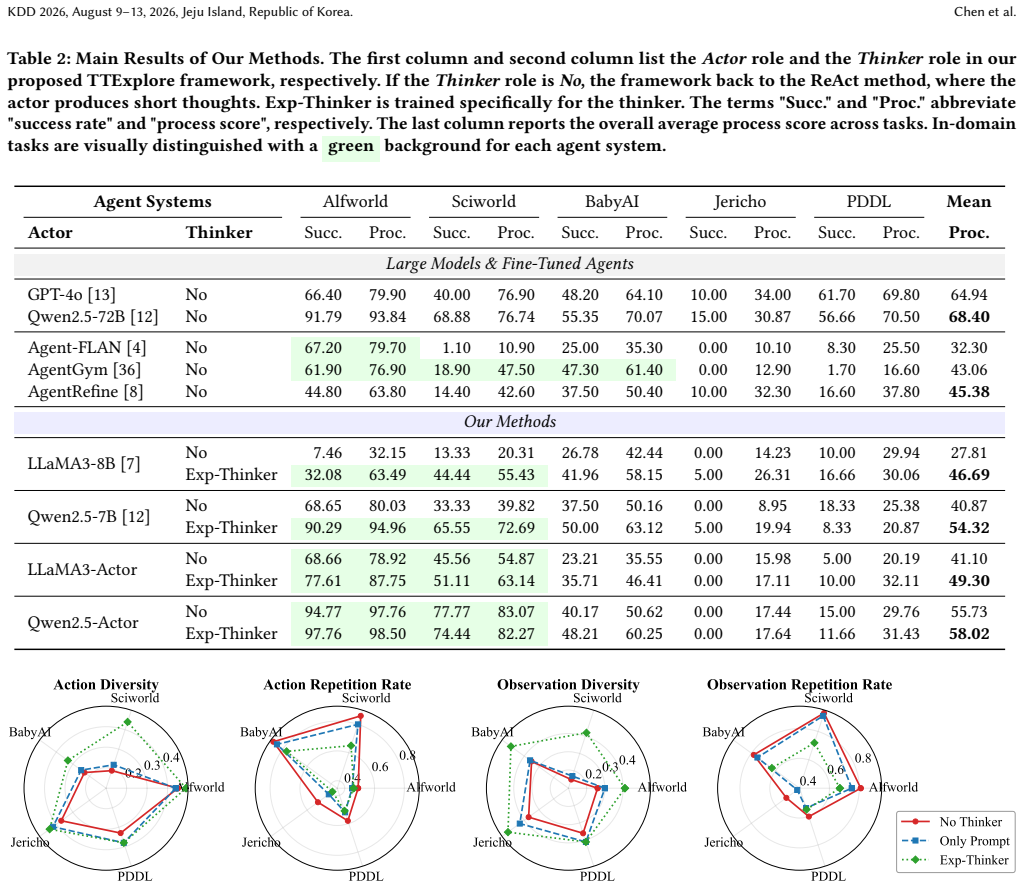
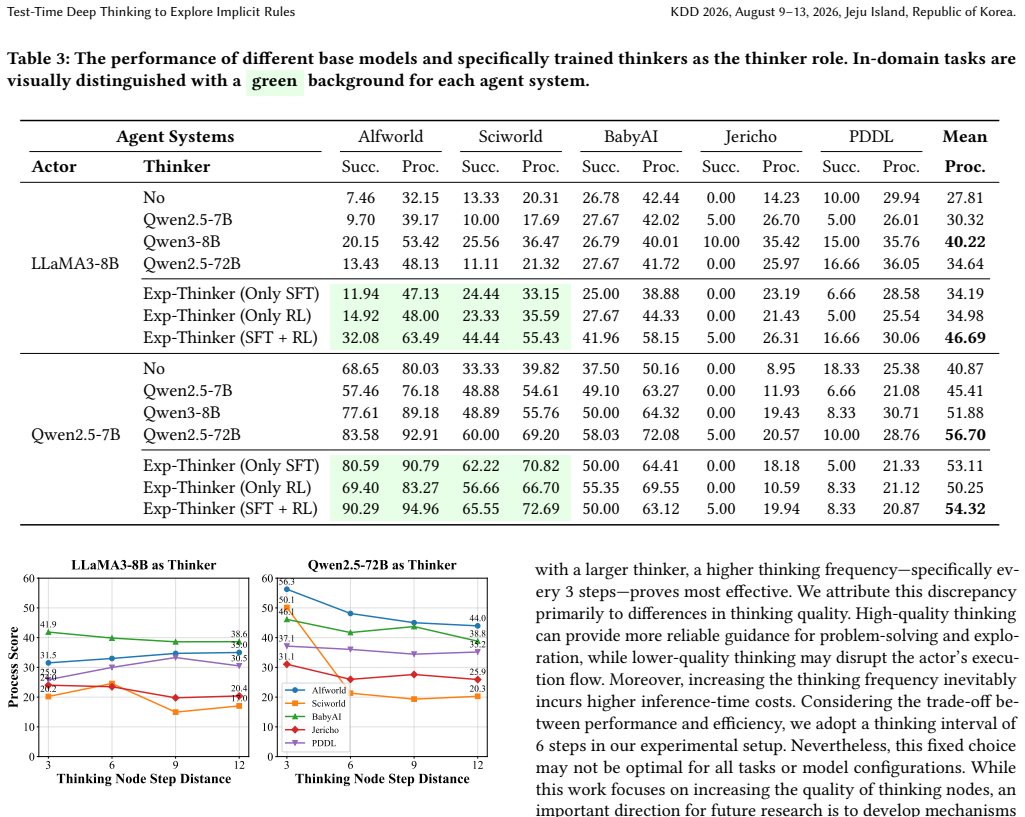
With the continuous advancement of Large Language Models (LLMs), intelligent agents are becoming increasingly vital. However, these agents often fail in environments governed by implicit rules--hidden constraints that cannot be observed directly and must be inferred through interaction. This causes agents to fall into repetitive trial-and-error loops, ultimately leading to task failure. To address this challenge, we propose Test-Time Exploration (TTExplore), a framework where a thinker component analyzes interaction history to infer these implicit rules and guide an actor. Effective exploration in this setting critically depends on the reasoning ability of the thinker. However, evaluating deep reasoning trajectories is inherently unstable and difficult, which poses a major obstacle to effective training. To overcome this issue, we introduce a novel and stable reinforcement learning pipeline. The core idea is to use accurate task-level scores as indirect rewards to bypass the difficulty of evaluating intermediate reasoning, and to retain only a single thinking node per trajectory to alleviate reward sparsity. Using this pipeline, we train a specialized 7B model, Exp-Thinker. Experiments on five text-based embodied tasks show that TTExplore equipped with Exp-Thinker improves baseline agent performance by an average of $14$-$19$ points, demonstrating the effectiveness of explicitly reasoning about implicit rules.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Test-Time Exploration (TTExplore), a framework for LLM-based agents operating in environments governed by implicit rules. A thinker component analyzes interaction history to infer hidden constraints and guide an actor component. Training the thinker uses a reinforcement learning pipeline that treats task-level success scores as indirect rewards and retains only a single thinking node per trajectory to mitigate reward sparsity. A specialized 7B Exp-Thinker model is trained with this pipeline. Experiments across five text-based embodied tasks report that TTExplore equipped with Exp-Thinker yields average performance gains of 14-19 points over baseline agents.
Significance. If the performance improvements arise from the thinker learning to perform accurate implicit-rule inference (rather than from selection effects in the training data), the work would demonstrate a viable route to training reasoning components for agents in sparse-feedback settings via indirect task-level signals. The indirect-reward design for stabilizing reasoning-trajectory training is a concrete methodological contribution that could be adopted more broadly.
major comments (1)
- [Abstract and method description] Abstract / RL pipeline description: The pipeline retains only a single thinking node per trajectory, chosen solely because the resulting trajectory succeeded. No direct supervision or verification is described that confirms the retained node performed correct implicit-rule inference rather than a partial or lucky guess. The manuscript supplies no ablation on multi-node retention, no metric of rule accuracy on retained versus discarded nodes, and no analysis of whether task success correlates with inference correctness. This selection step is load-bearing for the claim that gains reflect improved rule reasoning.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential methodological contribution of the indirect-reward design. We address the major comment on the RL pipeline below, proposing targeted revisions while maintaining that the core approach addresses a genuine challenge in sparse-feedback reasoning training.
read point-by-point responses
-
Referee: [Abstract and method description] Abstract / RL pipeline description: The pipeline retains only a single thinking node per trajectory, chosen solely because the resulting trajectory succeeded. No direct supervision or verification is described that confirms the retained node performed correct implicit-rule inference rather than a partial or lucky guess. The manuscript supplies no ablation on multi-node retention, no metric of rule accuracy on retained versus discarded nodes, and no analysis of whether task success correlates with inference correctness. This selection step is load-bearing for the claim that gains reflect improved rule reasoning.
Authors: We agree that the absence of direct verification of inference correctness is a limitation of the current presentation. Because the test environments provide no explicit ground-truth labels for the implicit rules, computing quantitative rule-accuracy metrics on retained versus discarded nodes would require new human annotation that is outside the scope of the original experiments. The indirect-reward design was introduced precisely because direct evaluation of reasoning trajectories is unstable, as noted in the manuscript. In the revision we will (1) add an ablation on retaining the top-k nodes per trajectory (where k>1) on at least two of the five tasks, (2) include a qualitative analysis of a random sample of retained thinking traces with manual assessment of rule-inference plausibility, and (3) report the empirical correlation between final task success and the presence of explicit rule statements in the thinker output. These additions will clarify the extent to which performance gains can be attributed to improved rule reasoning rather than selection effects. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical RL-based training pipeline for a thinker model using task-level success scores as rewards and single-node retention per trajectory, followed by experimental evaluation on embodied tasks. No equations, mathematical derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described method. The performance gains are reported as direct experimental outcomes from trained models, not reductions by construction to inputs or prior self-referential results. The approach is self-contained against external task benchmarks with no load-bearing steps that collapse to definitions or fits.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ma Chang, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhen- zhong Lan, Lingpeng Kong, and Junxian He. 2024. Agentboard: An analytical evaluation board of multi-turn llm agents.Advances in neural information pro- cessing systems37 (2024), 74325–74362
2024
- [2]
-
[3]
Mingyang Chen, Linzhuang Sun, Tianpeng Li, Haoze Sun, Chenzheng Zhu, Haofen Wang, Jeff Pan, Wen Zhang, Huajun Chen, Fan Yang, et al. 2026. Learning to reason with search for llms via reinforcement learning.Advances in Neural Information Processing Systems38 (2026), 85287–85307
2026
-
[4]
Zehui Chen, Kuikun Liu, Qiuchen Wang, Wenwei Zhang, Jiangning Liu, Dahua Lin, Kai Chen, and Feng Zhao. 2024. Agent-flan: Designing data and methods of effective agent tuning for large language models. (2024), 9354–9366
2024
- [5]
-
[6]
Marc-Alexandre Côté, Akos Kádár, Xingdi Yuan, Ben Kybartas, Tavian Barnes, Emery Fine, James Moore, Matthew Hausknecht, Layla El Asri, Mahmoud Adada, et al. 2018. Textworld: A learning environment for text-based games. InWorkshop on Computer Games. Springer, 41–75
2018
-
[7]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv e-prints(2024), arXiv–2407
2024
- [8]
-
[9]
Matthew Hausknecht, Prithviraj Ammanabrolu, Marc-Alexandre Côté, and Xingdi Yuan. 2020. Interactive fiction games: A colossal adventure. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 7903–7910
2020
-
[10]
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. 2024. Cogagent: A visual language model for gui agents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14281–14290. KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. Chen et al
2024
-
[11]
Mengkang Hu, Pu Zhao, Can Xu, Qingfeng Sun, Jian-Guang Lou, Qingwei Lin, Ping Luo, and Saravan Rajmohan. 2025. Agentgen: Enhancing planning abilities for large language model based agent via environment and task generation. (2025), 496–507
2025
-
[12]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Daniel Kahneman. 2011. Thinking, fast and slow.Farrar, Straus and Giroux (2011)
2011
-
[16]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Mem- ory Management for Large Language Model Serving with PagedAttention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
2023
-
[17]
Bill Yuchen Lin, Yicheng Fu, Karina Yang, Faeze Brahman, Shiyu Huang, Chandra Bhagavatula, Prithviraj Ammanabrolu, Yejin Choi, and Xiang Ren. 2023. Swift- sage: A generative agent with fast and slow thinking for complex interactive tasks.Advances in Neural Information Processing Systems36 (2023), 23813–23825
2023
-
[18]
Jun Liu, Zhenglun Kong, Peiyan Dong, Changdi Yang, Tianqi Li, Hao Tang, Geng Yuan, Wei Niu, Wenbin Zhang, Pu Zhao, et al. 2025. Structured Agent Distillation for Large Language Model.arXiv preprint arXiv:2505.13820(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. 2024. Agentbench: Evaluating llms as agents. 2024 (2024), 52989–53046
2024
-
[20]
Shuofei Qiao, Runnan Fang, Ningyu Zhang, Yuqi Zhu, Xiang Chen, Shumin Deng, Yong Jiang, Pengjun Xie, Fei Huang, and Huajun Chen. 2024. Agent planning with world knowledge model.Advances in Neural Information Processing Systems 37 (2024), 114843–114871
2024
-
[21]
Shuofei Qiao, Zhisong Qiu, Baochang Ren, Xiaobin Wang, Xiangyuan Ru, Ningyu Zhang, Xiang Chen, Yong Jiang, Pengjun Xie, Fei Huang, et al . 2025. Agentic knowledgeable self-awareness. (2025), 12601–12625
2025
-
[22]
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. 2025. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2024. HybridFlow: A Flexible and Efficient RLHF Framework.arXiv preprint arXiv: 2409.19256(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems36 (2023), 8634–8652
2023
-
[26]
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. 2020. Alfworld: Aligning text and em- bodied environments for interactive learning.arXiv preprint arXiv:2010.03768 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[27]
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. 2025. R1-searcher: Incentivizing the search capability in llms via reinforcement learning.arXiv preprint arXiv:2503.05592 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Huatong Song, Jinhao Jiang, Wenqing Tian, Zhipeng Chen, Yuhuan Wu, Jiahao Zhao, Yingqian Min, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. 2025. R1- Searcher++: Incentivizing the Dynamic Knowledge Acquisition of LLMs via Reinforcement Learning.arXiv preprint arXiv:2505.17005(2025)
-
[29]
Yifan Song, Weimin Xiong, Xiutian Zhao, Dawei Zhu, Wenhao Wu, Ke Wang, Cheng Li, Wei Peng, and Sujian Li. 2024. Agentbank: Towards generalized llm agents via fine-tuning on 50000+ interaction trajectories. (2024), 2124–2141
2024
- [30]
-
[31]
Mauro Vallati, Lukas Chrpa, Marek Grześ, Thomas Leo McCluskey, Mark Roberts, Scott Sanner, et al. 2015. The 2014 international planning competition: Progress and trends.Ai Magazine36, 3 (2015), 90–98
2015
-
[32]
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tris- tan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gal- louédec. 2020. TRL: Transformer Reinforcement Learning. https://github.com/ huggingface/trl
2020
-
[33]
Ruoyao Wang, Peter Jansen, Marc-Alexandre Côté, and Prithviraj Ammanabrolu
-
[34]
Scienceworld: Is your agent smarter than a 5th grader? (2022), 11279–11298
2022
-
[35]
Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Xing Jin, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, et al. 2025. Ragen: Understanding self-evolution in llm agents via multi-turn reinforcement learning. arXiv preprint arXiv:2504.20073(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al. 2024. Os-atlas: A foundation action model for generalist GUI agents.arXiv preprint arXiv:2410.23218 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [37]
-
[38]
Yu Xia, Jingru Fan, Weize Chen, Siyu Yan, Xin Cong, Zhong Zhang, Yaxi Lu, Yankai Lin, Zhiyuan Liu, and Maosong Sun. 2025. Agentrm: Enhancing agent generalization with reward modeling. (2025), 19277–19290
2025
-
[39]
Jiannan Xiang, Tianhua Tao, Yi Gu, Tianmin Shu, Zirui Wang, Zichao Yang, and Zhiting Hu. 2023. Language models meet world models: Embodied experiences enhance language models.Advances in neural information processing systems36 (2023), 75392–75412
2023
- [40]
-
[41]
Yuhao Yang, Yue Wang, Dongxu Li, Ziyang Luo, Bei Chen, Chao Huang, and Junnan Li. 2025. Aria-ui: Visual grounding for gui instructions. (2025), 22418– 22433
2025
-
[42]
Yijun Yang, Tianyi Zhou, Kanxue Li, Dapeng Tao, Lusong Li, Li Shen, Xiaodong He, Jing Jiang, and Yuhui Shi. 2024. Embodied multi-modal agent trained by an llm from a parallel textworld. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 26275–26285
2024
-
[43]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR)
2023
-
[44]
Da Yin, Faeze Brahman, Abhilasha Ravichander, Khyathi Chandu, Kai-Wei Chang, Yejin Choi, and Bill Yuchen Lin. 2024. Agent lumos: Unified and modular training for open-source language agents. (2024), 12380–12403
2024
-
[45]
Aohan Zeng, Mingdao Liu, Rui Lu, Bowen Wang, Xiao Liu, Yuxiao Dong, and Jie Tang. 2024. Agenttuning: Enabling generalized agent abilities for llms. (2024), 3053–3077
2024
- [46]
-
[47]
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. 2024. Expel: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 19632–19642
2024
-
[48]
Yuqi Zhu, Shuofei Qiao, Yixin Ou, Shumin Deng, Shiwei Lyu, Yue Shen, Lei Liang, Jinjie Gu, Huajun Chen, and Ningyu Zhang. 2025. Knowagent: Knowledge- augmented planning for llm-based agents. (2025), 3709–3732. A Method Details A.1 Prompts and Output Formats We show our prompts for the actor role and the thinker role in our framework, as shown in Figure 8 ...
2025
-
[49]
You MUST provide your thought (one or two lines) before taking action
-
[50]
Use the following format: <think> put your thought here </think> <answer> put your action here </answer> Please provide your response to the task following the format strictly
You MUST issue only ONE action in each interaction stage. Use the following format: <think> put your thought here </think> <answer> put your action here </answer> Please provide your response to the task following the format strictly. Figure 8: The prompt for the actor role. Thinker Prompt You are a Thinker Agent responsible for uncovering the implicit ru...
-
[51]
If you think all the feedback in the history trajectory is reasonable, summarize the subgoals you have completed and provide your next plan
-
[52]
Do not assume the environment is erroneous; instead, consider what hidden rules could explain the observations
If you find the environment’s feedback in the latest steps confusing, think carefully about possible reasons. Do not assume the environment is erroneous; instead, consider what hidden rules could explain the observations
-
[53]
go to outside
For any uncertainties, try to formulate hypotheses and design plans to verify them. Use the following format for your response: <deepthink> put your thought here </deepthink> Figure 9: The prompt for the thinker role. A.2 The Training Pipeline for the Thinker Role In this section, we present our approach for training a professional thinker model based on ...
-
[54]
The command might need to be phrased differently
-
[55]
There might be a specific action required to move to the outside, such as opening a door or using a different command
-
[56]
Given the initial observation, the only door men- tioned is to the hallway, which is open
The environment might require a more detailed command, such as specifying a door or a path to the outside. Given the initial observation, the only door men- tioned is to the hallway, which is open. This might be a clue that the hallway is the next logical step to reach the outside. However, the task specifies that the animals are in the “outside” location...
-
[57]
Go to the door to the hallway
-
[58]
Open the door if it is not already open
-
[59]
KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea
Look around to see if the outside is accessible from the hallway. KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. Chen et al
2026
-
[60]
If the outside is accessible, proceed to find the animals and focus on the one with the longest life span, then the one with the shortest life span. Action to take: - go to the door to the hallway - open the door to the hallway - go to the hallway - look around Figure 10: An example of the deep thinking results produced by our professional thinker Exp-Thi...
-
[61]
Take plate 1 from cabinet 1
-
[62]
Next plan:
Put plate 1 in/on countertop 1. Next plan:
-
[63]
Clean plate 1 with sinkbasin 1
-
[64]
The feedback in the history trajectory is reason- able
Put the clean plate 1 in/on countertop 1. The feedback in the history trajectory is reason- able. The environment has provided clear and expected responses to the actions taken. There are no confusing elements in the feedback, and the actions align with the logical steps required to complete the task. The next step is to clean the plate, which I will do a...
-
[65]
Cabinet 3 has a cloth 2
Cabinet 2 has a candle 2 and toiletpaper 1. Cabinet 3 has a cloth 2. Table 6: The results of our framework on different models. ThinkerAlfworld Sciworld BabyAI Jericho PDDLMean GPT-4o-mini as Actor No 47.63 86.23 67.23 20.72 44.65 53.29 GPT-4o-mini 50.74 83.87 71.17 25.38 51.30 56.49 Qwen2.5-72B 64.80 82.80 72.99 30.30 51.5260.48 LLaMA3-8B as Actor No 32....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.