Learning Neural Deformation Representation for 4D Dynamic Shape Generation
Pith reviewed 2026-06-28 17:27 UTC · model grok-4.3
The pith
A neural deformation representation disentangles motion from shape for improved 4D dynamic shape generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
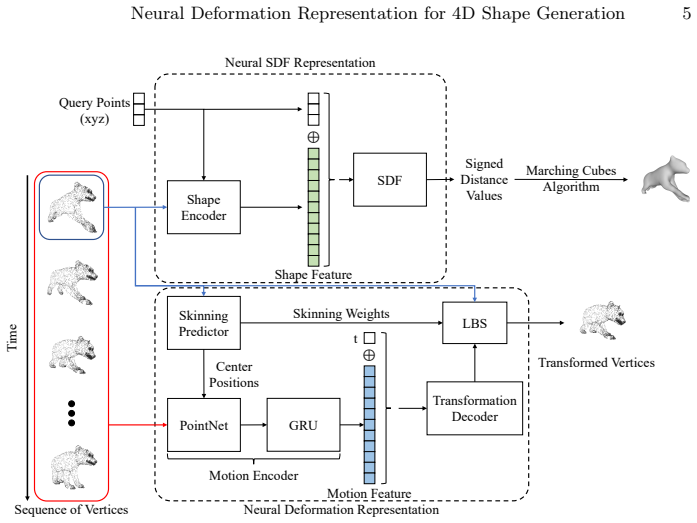
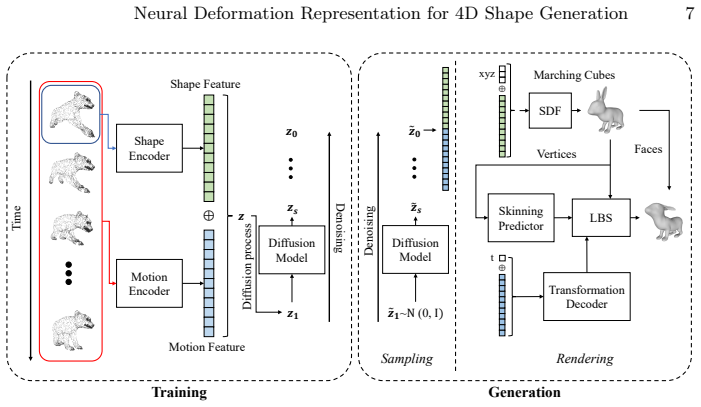
The central claim is that a 4D representation architecture with disentangled motion and shape latent spaces, built from a deformation representation that predicts skinning weights and rigid transformations for multiple parts together with conditional neural signed distance fields, combined with a diffusion model on the extracted features, produces higher-quality 4D dynamic shapes than prior methods that do not separate motion from shape.
What carries the argument
The neural deformation representation that predicts skinning weights and rigid transformations for multiple parts, which disentangles the motion latent space from the shape latent space when used with conditional neural signed distance fields.
If this is right
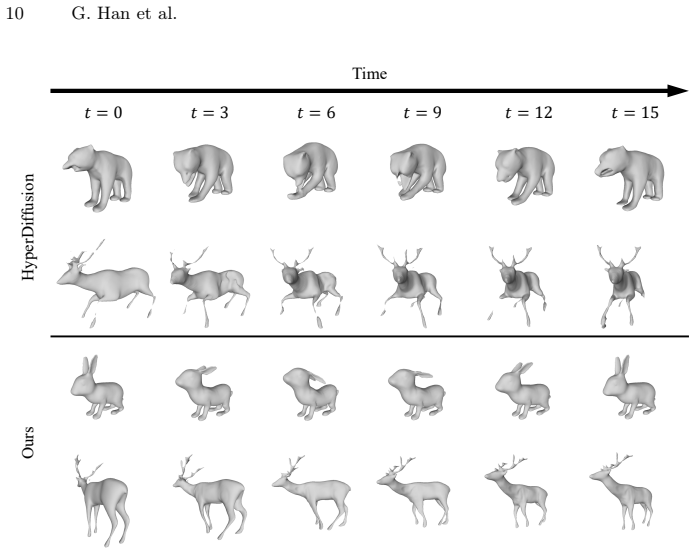
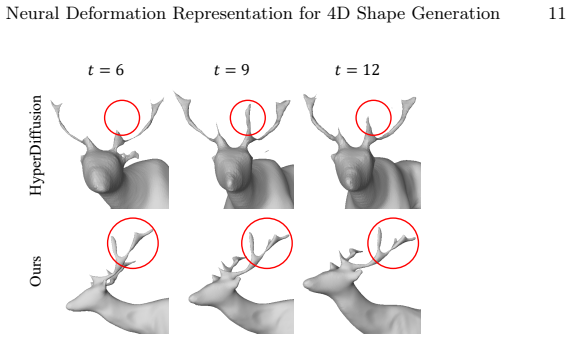
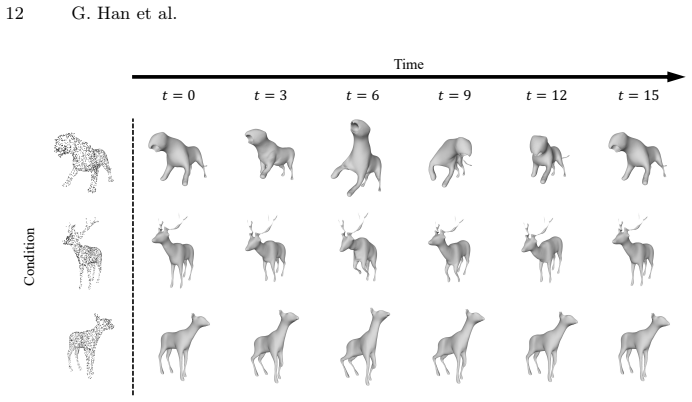
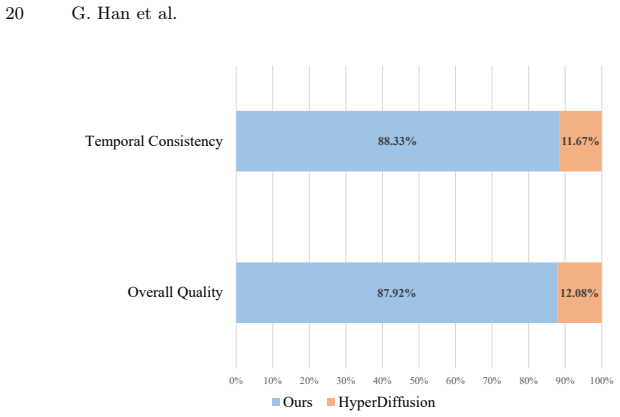
- Unconditional generation of 4D shapes achieves higher quality and temporal consistency than previous methods.
- Conditional generation tasks benefit from the separated motion and shape controls.
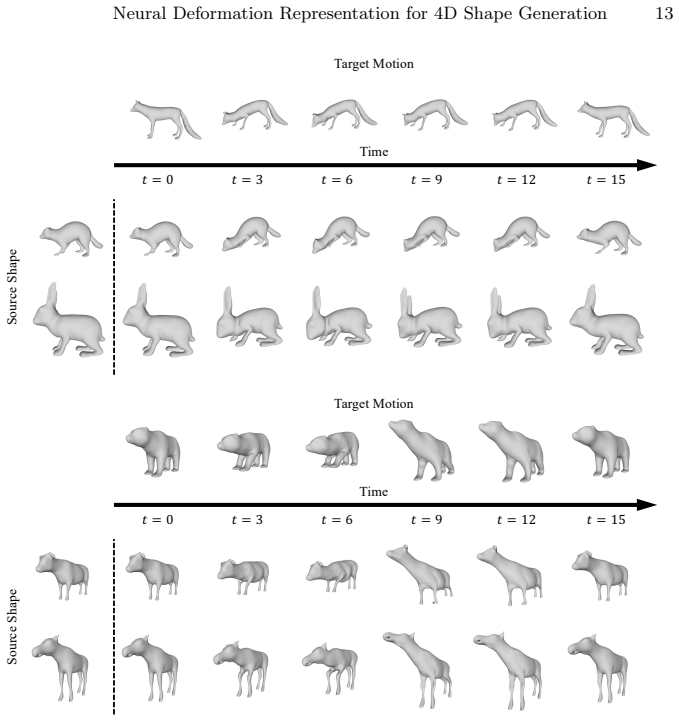
- Motion retargeting becomes feasible without retraining the full shape representation.
- The multi-part deformation module improves structural understanding of generated shapes.
- Rendering speed improves because motion is handled separately from the shape field.
Where Pith is reading between the lines
- Independent manipulation of motion sequences without changing the base shape becomes possible once the spaces are separated.
- The approach may extend naturally to editing or interpolating only the motion component in animation pipelines.
- The part-based decomposition could support transfer to objects with more complex articulations than those tested.
Load-bearing premise
Predicting skinning weights and rigid transformations for multiple parts will reliably disentangle motion from shape without introducing artifacts or requiring extensive post-processing.
What would settle it
Experiments that find no measurable gain in temporal consistency or generation quality metrics over HyperDiffusion would falsify the central performance claim.
Figures
read the original abstract
Recent developments in 3D shape representation opened new possibilities for generating detailed 3D shapes. Despite these advances, there are few studies dealing with the generation of 4D dynamic shapes that have the form of 3D objects deforming over time. To bridge this gap, we focus on generating 4D dynamic shapes with an emphasis on both generation quality and efficiency in this paper. HyperDiffusion, a previous work on 4D generation, proposed a method of directly generating the weight parameters of 4D occupancy fields but suffered from low temporal consistency and slow rendering speed due to motion representation that is not separated from the shape representation of 4D occupancy fields. Therefore, we propose a new neural deformation representation and combine it with conditional neural signed distance fields to design a 4D representation architecture in which the motion latent space is disentangled from the shape latent space. The proposed deformation representation, which works by predicting skinning weights and rigid transformations for multiple parts, also has advantages over the deformation modules of existing 4D representations in understanding the structure of shapes. In addition, we design a training process of a diffusion model that utilizes the shape and motion features that are extracted by our 4D representation as data points. The results of unconditional generation, conditional generation, and motion retargeting experiments demonstrate that our method not only shows better performance than previous works in 4D dynamic shape generation but also has various potential applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a 4D dynamic shape generation architecture that combines conditional neural signed distance fields with a new neural deformation representation. The deformation module predicts per-part skinning weights and rigid transformations to produce disentangled motion and shape latent spaces. Features extracted from this representation are used to train a diffusion model. The authors claim that this yields better results than prior work (e.g., HyperDiffusion) on unconditional generation, conditional generation, and motion retargeting, while also improving temporal consistency, rendering speed, and structural interpretability.
Significance. If the empirical claims are substantiated, the disentangled representation could meaningfully advance 4D generation by moving beyond entangled occupancy-field parameterizations. The part-based deformation approach may additionally provide reusable structure for retargeting and editing tasks. The diffusion-on-features strategy addresses a clear efficiency and consistency bottleneck identified in earlier methods.
major comments (2)
- [Abstract] Abstract: the central claim that the method 'shows better performance than previous works' is stated without any quantitative metrics, tables, error bars, or dataset details. Because the superiority assertion is the primary empirical contribution, this omission makes the load-bearing result impossible to evaluate from the provided summary.
- [Method (deformation module)] Deformation representation description: the claim that predicting skinning weights and rigid transformations for multiple parts reliably disentangles motion from shape without artifacts or extensive post-processing is presented as an advantage, yet no ablation, failure-case analysis, or quantitative measure of disentanglement quality (e.g., motion transfer error under shape variation) is referenced. This assumption underpins both the architectural novelty and the reported application results.
minor comments (2)
- [Abstract] The abstract would be strengthened by briefly naming the datasets, the number of parts used in the deformation module, and the primary evaluation metrics (e.g., CD, EMD, temporal consistency score).
- [Method] Notation for the latent spaces (shape vs. motion) and the diffusion conditioning mechanism should be introduced with explicit symbols early in the method section to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to improve clarity and substantiation of claims where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method 'shows better performance than previous works' is stated without any quantitative metrics, tables, error bars, or dataset details. Because the superiority assertion is the primary empirical contribution, this omission makes the load-bearing result impossible to evaluate from the provided summary.
Authors: We agree that the abstract would benefit from explicit quantitative highlights to support the performance claims. The full manuscript contains comparative tables (e.g., against HyperDiffusion) with metrics on generation quality, temporal consistency, and retargeting across specific datasets. In revision we will condense key numerical results, error bars, and dataset names into the abstract. revision: yes
-
Referee: [Method (deformation module)] Deformation representation description: the claim that predicting skinning weights and rigid transformations for multiple parts reliably disentangles motion from shape without artifacts or extensive post-processing is presented as an advantage, yet no ablation, failure-case analysis, or quantitative measure of disentanglement quality (e.g., motion transfer error under shape variation) is referenced. This assumption underpins both the architectural novelty and the reported application results.
Authors: The motion retargeting experiments provide indirect evidence of disentanglement by successfully transferring motions across shape variations. However, we acknowledge the absence of a dedicated quantitative ablation (such as motion transfer error under controlled shape changes) or explicit failure-case analysis. We will add these in the revised manuscript, including an ablation table and selected failure examples. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces a neural deformation module that predicts per-part skinning weights and rigid transforms to achieve explicit disentanglement of motion and shape latent spaces, then trains a diffusion model on the resulting features. This is framed as an independent architectural design choice that improves on HyperDiffusion's direct weight generation. No equations or claims reduce a prediction to a fitted input by construction, no load-bearing self-citation chains appear, and no uniqueness theorems or ansatzes are smuggled in. Experiments (unconditional/conditional generation, retargeting) supply external empirical support rather than tautological validation. The method is therefore not equivalent to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Dy, J., Krause, A
Achlioptas, P., Diamanti, O., Mitliagkas, I., Guibas, L.: Learning representations and generative models for 3D point clouds. In: Dy, J., Krause, A. (eds.) Pro- ceedings of the 35th International Conference on Machine Learning. Proceed- ings of Machine Learning Research, vol. 80, pp. 40–49. PMLR (10–15 Jul 2018), https://proceedings.mlr.press/v80/achliopt...
2018
-
[2]
Bogo, F., Romero, J., Pons-Moll, G., Black, M.J.: Dynamic faust: Registering hu- man bodies in motion.In: Proceedingsof the IEEE Conferenceon Computer Vision and Pattern Recognition (CVPR) (July 2017)
2017
-
[3]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chan, E.R., Monteiro, M., Kellnhofer, P., Wu, J., Wetzstein, G.: Pi-gan: Periodic implicit generative adversarial networks for 3d-aware image synthesis. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5799–5809 (June 2021)
2021
-
[4]
In: Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R
Chen, R.T.Q., Rubanova, Y., Bettencourt, J., Duvenaud, D.K.: Neural ordinary differential equations. In: Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 31. Curran Associates, Inc. (2018),https://proceedings.neurips. cc / paper _ files / paper / 2018 / file ...
2018
-
[5]
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., Bengio, Y.: Learning phrase representations using rnn encoder-decoder for sta- tistical machine translation. arXiv preprint arXiv:1406.1078 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[6]
In: Proceedings of the IEEE/CVF International Confer- ence on Computer Vision (ICCV)
Chou, G., Bahat, Y., Heide, F.: Diffusion-sdf: Conditional generative modeling of signed distance functions. In: Proceedings of the IEEE/CVF International Confer- ence on Computer Vision (ICCV). pp. 2262–2272 (October 2023)
2023
-
[7]
In: Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S
Dupont, E., Kim, H., Eslami, S.M.A., Rezende, D.J., Rosenbaum, D.: From data to functa: Your data point is a function and you can treat it like one. In: Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S. (eds.) Proceedings of the 39th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 162, p...
2022
-
[8]
Erkoç, Z., Ma, F., Shan, Q., Nießner, M., Dai, A.: Hyperdiffusion: Generating implicitneuralfieldswithweight-spacediffusion.In:ProceedingsoftheIEEE/CVF International Conference on Computer Vision (ICCV). pp. 14300–14310 (October 2023)
2023
-
[9]
Fan, H., Su, H., Guibas, L.J.: A point set generation network for 3d object recon- structionfromasingleimage.In:ProceedingsoftheIEEEConferenceonComputer Vision and Pattern Recognition (CVPR) (July 2017)
2017
-
[10]
In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A
Gao,J.,Shen,T.,Wang,Z.,Chen,W.,Yin,K.,Li,D.,Litany,O.,Gojcic,Z.,Fidler, S.: Get3d: A generative model of high quality 3d textured shapes learned from im- ages. In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A. (eds.) Advances in Neural Information Processing Systems. vol. 35, pp. 31841–31854. Curran Associates, Inc. (2022),https://pr...
2022
-
[11]
In: Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. In: Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K. (eds.) Advances in Neural Information Processing Systems. vol. 27. Curran Associates, Inc. (2014),https : / / proceedings . neurips . cc / paper...
2014
-
[12]
(eds.) Advances in Neu- ral Information Processing Systems
Ho,J.,Jain,A.,Abbeel,P.:Denoisingdiffusionprobabilisticmodels.In:Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H. (eds.) Advances in Neu- ral Information Processing Systems. vol. 33, pp. 6840–6851. Curran Associates, Inc. (2020),https://proceedings.neurips.cc/paper_files/paper/2020/file/ 4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf
2020
-
[13]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[14]
In: SIGGRAPH Asia 2022 Conference Papers
Hui, K.H., Li, R., Hu, J., Fu, C.W.: Neural wavelet-domain diffusion for 3d shape generation. In: SIGGRAPH Asia 2022 Conference Papers. pp. 1–9 (2022)
2022
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Jiang, B., Zhang, Y., Wei, X., Xue, X., Fu, Y.: Learning compositional representa- tion for 4d captures with neural ode. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5340–5350 (June 2021)
2021
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Jiang, B., Zhang, Y., Wei, X., Xue, X., Fu, Y.: H4d: Human 4d modeling by learning neural compositional representation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 19355– 19365 (June 2022)
2022
-
[17]
ACM SIGGRAPH Courses4(2014)
Kavan, L.: Direct skinning methods and deformation primitives. ACM SIGGRAPH Courses4(2014)
2014
-
[18]
Kavan, L., Collins, S., Žára, J., O’Sullivan, C.: Geometric skinning with approx- imate dual quaternion blending. ACM Trans. Graph.27(4) (nov 2008).https: //doi.org/10.1145/1409625.1409627,https://doi.org/10.1145/1409625. 1409627
-
[19]
ACM Transactions on Graphics42(4) (2023)
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics42(4) (2023)
2023
-
[20]
arXiv preprint arXiv:2002.00349 (2020)
Kleineberg, M., Fey, M., Weichert, F.: Adversarial generation of continuous implicit shape representations. arXiv preprint arXiv:2002.00349 (2020)
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Lei, J., Daniilidis, K.: Cadex: Learning canonical deformation coordinate space for dynamic surface representation via neural homeomorphism. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6624–6634 (June 2022)
2022
-
[22]
ACM Trans
Li, T., Bolkart, T., Black, M.J., Li, H., Romero, J.: Learning a model of facial shape and expression from 4d scans. ACM Trans. Graph.36(6), 194–1 (2017)
2017
-
[23]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Li, Y., Takehara, H., Taketomi, T., Zheng, B., Nießner, M.: 4dcomplete: Non- rigid motion estimation beyond the observable surface. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 12706– 12716 (October 2021)
2021
-
[24]
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: Smpl: a skinned multi-person linear model. ACM Trans. Graph.34(6) (oct 2015).https://doi. org/10.1145/2816795.2818013,https://doi.org/10.1145/2816795.2818013
-
[25]
Lorensen, W.E., Cline, H.E.: Marching cubes: A high resolution 3d surface con- struction algorithm. In: Proceedings of the 14th Annual Conference on Computer Graphics and Interactive Techniques. p. 163–169. SIGGRAPH ’87, Association for Computing Machinery, New York, NY, USA (1987).https://doi.org/10.1145/ 37401.37422,https://doi.org/10.1145/37401.37422 N...
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Luo, S., Hu, W.: Diffusion probabilistic models for 3d point cloud generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2837–2845 (June 2021)
2021
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
Ma, Q., Yang, J., Ranjan, A., Pujades, S., Pons-Moll, G., Tang, S., Black, M.J.: Learning to dress 3d people in generative clothing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
2020
-
[28]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Mehta, I., Gharbi, M., Barnes, C., Shechtman, E., Ramamoorthi, R., Chandraker, M.: Modulated periodic activations for generalizable local functional representa- tions. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 14214–14223 (October 2021)
2021
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., Geiger, A.: Occupancy networks: Learning 3d reconstruction in function space. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
2019
-
[30]
In: Eu- ropean Conference on Computer Vision
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. In: Eu- ropean Conference on Computer Vision. pp. 405–421. Springer (2020)
2020
-
[31]
In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV) (October 2019)
Niemeyer, M., Mescheder, L., Oechsle, M., Geiger, A.: Occupancy flow: 4d recon- struction by learning particle dynamics. In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV) (October 2019)
2019
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
Park,J.J.,Florence,P.,Straub,J.,Newcombe,R.,Lovegrove,S.:Deepsdf:Learning continuous signed distance functions for shape representation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
2019
-
[33]
Peng, S., Niemeyer, M., Mescheder, L., Pollefeys, M., Geiger, A.: Convolutional occupancynetworks.In:ComputerVision–ECCV2020:16thEuropeanConference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16. pp. 523–540. Springer (2020)
2020
-
[34]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (July 2017)
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: Deep learning on point sets for 3d classification and segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (July 2017)
2017
-
[35]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text- conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 1(2), 3 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10684– 10695 (June 2022)
2022
-
[37]
ACM Transactions on Graphics, (Proc
Romero, J., Tzionas, D., Black, M.J.: Embodied hands: Modeling and capturing hands and bodies together. ACM Transactions on Graphics, (Proc. SIGGRAPH Asia)36(6) (Nov 2017)
2017
-
[38]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2019)
Shu, D.W., Park, S.W., Kwon, J.: 3d point cloud generative adversarial network based on tree structured graph convolutions. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2019)
2019
-
[39]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[40]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Tang, J., Xu, D., Jia, K., Zhang, L.: Learning parallel dense correspondence from spatio-temporal descriptors for efficient and robust 4d reconstruction. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6022–6031 (June 2021) 18 G. Han et al
2021
-
[41]
In: International Conference on Learning Representations (2019),https://openreview.net/forum?id=SJeXSo09FQ
Valsesia, D., Fracastoro, G., Magli, E.: Learning localized generative models for 3d point clouds via graph convolution. In: International Conference on Learning Representations (2019),https://openreview.net/forum?id=SJeXSo09FQ
2019
-
[42]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2019)
Yang, G., Huang, X., Hao, Z., Liu, M.Y., Belongie, S., Hariharan, B.: Pointflow: 3d point cloud generation with continuous normalizing flows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2019)
2019
-
[43]
In: Advances in Neural Information Processing Systems (2022) Neural Deformation Representation for 4D Shape Generation 19 Fig
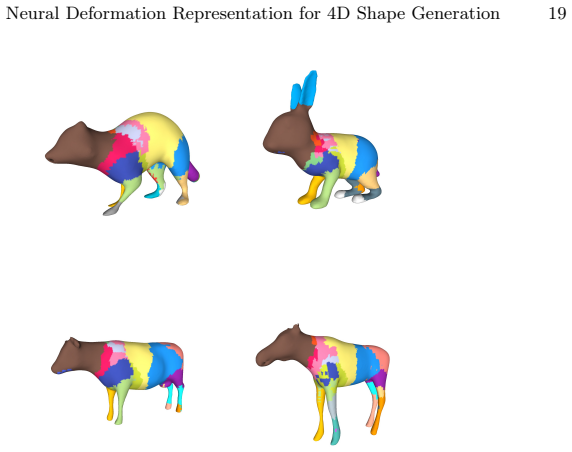
Zeng, X., Vahdat, A., Williams, F., Gojcic, Z., Litany, O., Fidler, S., Kreis, K.: Lion: Latent point diffusion models for 3d shape generation. In: Advances in Neural Information Processing Systems (2022) Neural Deformation Representation for 4D Shape Generation 19 Fig. 7:Skinning weights predicted by the skinning predictor module of our deformation repre...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.