TIDE: Task-Isolated Diffusion for Unified Video Editing and Generation
Pith reviewed 2026-06-27 19:51 UTC · model grok-4.3
The pith
TIDE shows a single diffusion model can handle instruction-based video editing, reference-guided editing, and multi-reference generation together.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
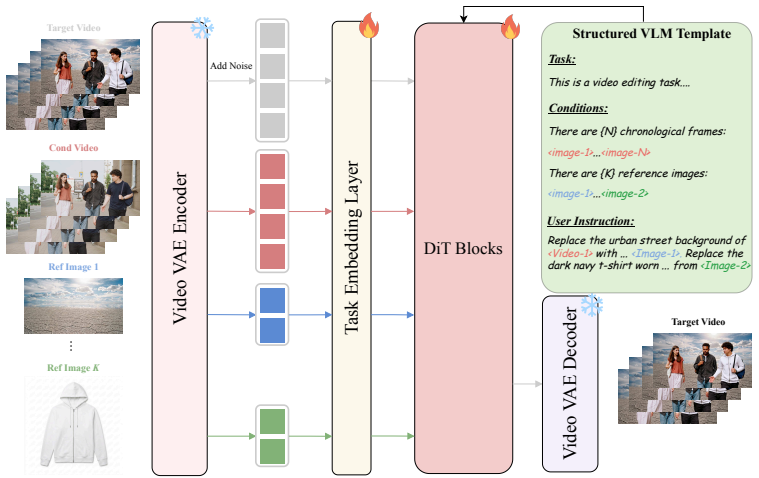
TIDE integrates instruction-based editing, reference-guided editing, and multi-reference generation in one model. Per-token task embeddings assign each input token a task-specific identifier to disambiguate heterogeneous conditions. The dual-path conditioning scheme couples a vision-language model with a VAE latent path for complementary signals. A multi-task progressive training strategy incrementally introduces tasks of increasing complexity.
What carries the argument
Per-token task embeddings that assign each input token a task-specific identifier, paired with a dual-path conditioning scheme that couples a vision-language model and a VAE latent path.
Load-bearing premise
Per-token task embeddings plus the dual VLM-VAE conditioning path are sufficient to disambiguate heterogeneous visual conditions without dedicated auxiliary encoders, even when the number and type of conditions vary across tasks.
What would settle it
A benchmark run that adds an unseen combination of reference types or increases the number of conditions beyond the training distribution and measures whether performance falls below specialized per-task models.
Figures











read the original abstract
Recent advances in Diffusion Transformers have driven rapid progress in video generation and editing, yet these capabilities are still handled by separate, task-specific models. Building a unified framework that supports diverse video tasks remains an open challenge: existing unified attempts either require dedicated auxiliary encoders or lack explicit mechanisms to distinguish heterogeneous conditioning tokens, struggling when the number and type of visual conditions vary across tasks. We propose TIDE, a unified framework that integrates instruction-based editing, reference-guided editing, and multi-reference generation. At its core, we introduce per-token task embeddings that assign each input token a task-specific identifier, enabling the model to explicitly disambiguate target, source, and reference tokens. To simultaneously capture high-level semantic understanding and fine-grained structural fidelity, we design a dual-path conditioning scheme that couples a vision-language model with a VAE latent path for complementary signals. We further devise a multi-task progressive training strategy that incrementally introduces tasks of increasing complexity, effectively harmonizing diverse objectives and enabling smooth generalization across heterogeneous task distributions. Extensive experiments on multiple video editing and generation benchmarks demonstrate that TIDE achieves state-of-the-art performance across all evaluated tasks. Our project page is available at https://LittleWork123.github.io/tide.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TIDE, a unified Diffusion Transformer framework supporting instruction-based video editing, reference-guided editing, and multi-reference generation. It proposes per-token task embeddings to explicitly disambiguate target/source/reference tokens, a dual-path conditioning scheme coupling a vision-language model with VAE latents, and a multi-task progressive training strategy that incrementally adds tasks of increasing complexity. The paper claims these components enable a single model to achieve state-of-the-art performance across all evaluated tasks without dedicated auxiliary encoders.
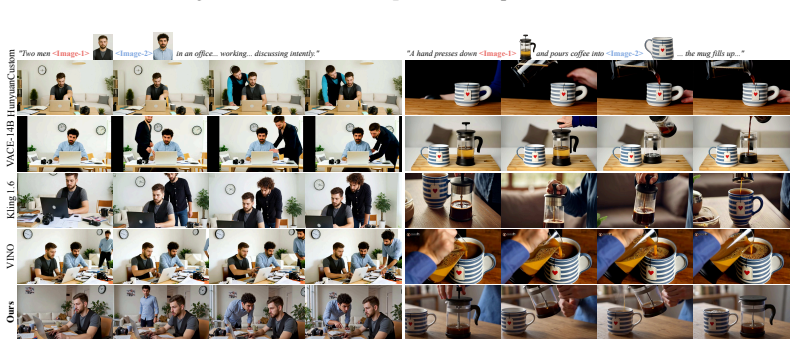
Significance. If the experimental claims hold, the work would represent a meaningful step toward unified video models by addressing the challenge of handling heterogeneous conditioning signals with varying cardinality. The per-token task embedding mechanism and progressive training strategy are potentially reusable ideas for multi-task diffusion systems. No machine-checked proofs or parameter-free derivations are present, but the project page link suggests reproducibility resources may be available.
major comments (3)
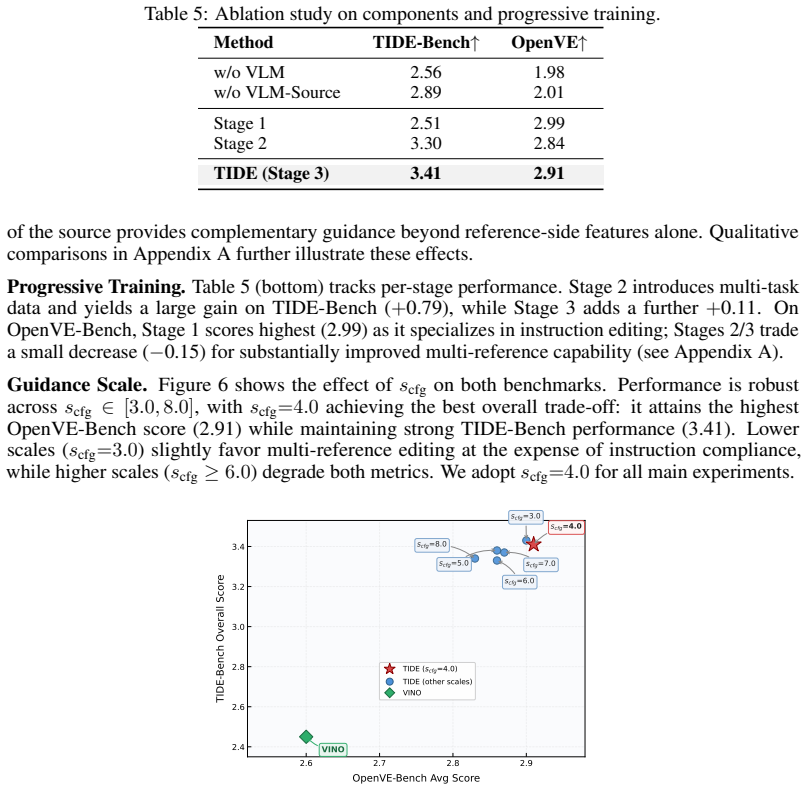
- [Abstract and §3] Abstract and §3 (method): The central claim that per-token task embeddings plus the dual VLM-VAE path suffice to disambiguate tokens when the number and type of visual conditions vary (without auxiliary encoders) is load-bearing for the unified-architecture contribution. No ablation is described that isolates this mechanism under changing condition cardinality, leaving the skeptic concern unaddressed by direct evidence.
- [Abstract] Abstract: The SOTA claim across all three tasks is stated without any quantitative metrics, dataset names, baselines, or error bars. This prevents assessment of whether the data actually support the performance assertions.
- [§4] §4 (experiments): The multi-task progressive training strategy is presented as harmonizing objectives, yet no analysis is supplied showing how task ordering or incremental introduction affects generalization when condition counts differ across tasks.
minor comments (2)
- [§3] Notation for the per-token task embeddings is introduced without an explicit equation or diagram showing how the identifier is added to the token sequence.
- [§3] The dual-path conditioning description would benefit from a figure illustrating the VLM and VAE signal fusion inside the Diffusion Transformer blocks.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and constructive suggestions. We address each major comment below, providing clarifications from the manuscript and committing to revisions where the concerns identify gaps in evidence or presentation.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): The central claim that per-token task embeddings plus the dual VLM-VAE path suffice to disambiguate tokens when the number and type of visual conditions vary (without auxiliary encoders) is load-bearing for the unified-architecture contribution. No ablation is described that isolates this mechanism under changing condition cardinality, leaving the skeptic concern unaddressed by direct evidence.
Authors: We agree that an explicit ablation isolating per-token task embeddings under varying condition cardinality would provide stronger direct evidence for the claim. While §4 reports consistent SOTA results across tasks with differing numbers of conditions (instruction editing with 1-2 visuals, reference-guided with 2, multi-reference generation with 3+), and the method section details how the embeddings explicitly tag target/source/reference tokens to enable disambiguation without auxiliary encoders, we did not include a controlled cardinality sweep. In the revision we will add such an ablation (e.g., performance with/without task embeddings at 1, 2, and 4+ conditions) to directly address this concern. revision: yes
-
Referee: [Abstract] Abstract: The SOTA claim across all three tasks is stated without any quantitative metrics, dataset names, baselines, or error bars. This prevents assessment of whether the data actually support the performance assertions.
Authors: The abstract is intentionally concise and high-level, as is conventional; the quantitative support—including specific metrics, dataset names (e.g., the video editing and generation benchmarks referenced in §4), baselines, and error bars—is fully detailed in the experimental section and tables. To improve immediate readability we will revise the abstract to include one or two key quantitative highlights (e.g., average improvement margins) while remaining within length limits. revision: yes
-
Referee: [§4] §4 (experiments): The multi-task progressive training strategy is presented as harmonizing objectives, yet no analysis is supplied showing how task ordering or incremental introduction affects generalization when condition counts differ across tasks.
Authors: The manuscript describes the progressive schedule in §3 and demonstrates its effectiveness through the final multi-task results in §4, but we acknowledge the absence of an explicit sensitivity analysis on ordering or incremental steps under varying condition cardinalities. In the revision we will add a short analysis or supplementary experiment examining performance when tasks are introduced in different orders or with different condition-count progressions, to quantify the contribution of the incremental strategy. revision: yes
Circularity Check
No circularity; claims rest on experimental benchmarks, not derivations or self-referential fits
full rationale
The manuscript presents an architectural proposal (per-token task embeddings, dual VLM-VAE path, progressive training) whose performance claims are supported solely by empirical results on external benchmarks. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or method description. The central assertion that the proposed conditioning suffices is an empirical hypothesis tested experimentally rather than a quantity defined in terms of itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127. Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh
-
[2]
Video generation models as world simulators. https://openai.com/index/ video-generation-models-as-world-simulators/. Yuanhao Cai, He Zhang, Xi Chen, Jinbo Xing, Yiwei Hu, Yuqian Zhou, Kai Zhang, Zhifei Zhang, Soo Ye Kim, Tianyu Wang, Yulun Zhang, Xiaokang Yang, Zhe Lin, and Alan Yuille. 2025. Omnivcus: Feedforward subject-driven video customization with m...
arXiv 2025
-
[3]
: Reference images defining what should be added, replaced, or used as background
[Reference Image-1], [Reference Image-2], . . .: Reference images defining what should be added, replaced, or used as background. 3.[Edited Video]: The result after applying the editing operations. Editing instruction:{instruction} Edit type:{edit_type_desc} Evaluate on five dimensions, each on a 1 – 5 integer scale: Edit Completeness (Prompt Compliance) ...
-
[4]
First-Frame Extraction.We extract the first frame from both the source video and the target video, producing a source frame and a target frame that capture the visual difference introduced by the edit
-
[5]
The generated prompt describes the visual element that should be isolated as the reference (e.g., the added object, the replacement subject, or the target style)
Reference Prompt Generation.A VLM (Gemini DeepMind (2026)) takes the source frame, target frame, and the original editing instruction as input to generate a descriptive prompt for extracting a clean reference image. The generated prompt describes the visual element that should be isolated as the reference (e.g., the added object, the replacement subject, ...
2026
-
[6]
(2025a) to extract a clean, isolated reference image
Reference Image Extraction.The source frame, target frame, and the generated reference prompt are fed into Qwen Image Edit Wu et al. (2025a) to extract a clean, isolated reference image. This produces a reference image that depicts the target visual element without extraneous background or context, completing the quadruplet (source video, target video, re...
-
[7]
Samples falling below quality thresh- olds are removed
Quality Filtering.A VLM-based filter (Gemini) evaluates each quadruplet on reference image clarity, reference-edit consistency, and instruction accuracy. Samples falling below quality thresh- olds are removed. This yields ∼700K single-reference editing quadruplets spanning diverse edit types including addition, replacement, background change, removal, and...
-
[8]
Second-Round Instruction Editing.Given a single-reference quadruplet (source video Vs, target video Vt, reference image I1, instruction c1), we apply a new instruction-based edit to Vt, producing a further-edited videoV t′ with a new editing instructionc 2
-
[9]
Second Reference Extraction.The newly edited video Vt′ and the previous target video Vt now form a new (source, target) pair. We apply the same single-reference extraction pipeline described above (first-frame extraction, Gemini-based reference prompt generation, and Qwen Image Edit-based reference extraction) to obtain a second reference imageI 2
-
[10]
Multi-Reference Assembly.This produces a multi-reference editing sample: (source video Vs, final target videoV t′, reference images{I 1, I2}, composite instruction)
-
[11]
This produces∼30K multi-reference video editing samples
Quality Filtering.A VLM-based quality filter removes samples with artifacts, inconsistent references, or conflicting edits. This produces∼30K multi-reference video editing samples. F Subject-to-Video Data Construction We construct subject-to-video (S2V) training data from large-scale internal video collections through an automated subject detection, clust...
-
[12]
Frame Sampling.We uniformly sample 10+ keyframes from each video clip in the source collection (∼1M clips)
-
[13]
(2025b) performs open-vocabulary subject detection on each sampled frame, producing bounding boxes and confidence scores for all detected subjects (persons, animals, objects)
Per-Frame Subject Detection.Qwen3-VL-8B Bai et al. (2025b) performs open-vocabulary subject detection on each sampled frame, producing bounding boxes and confidence scores for all detected subjects (persons, animals, objects). Low-confidence detections (<0.09) are discarded
-
[14]
(2025), a fine-grained visual encoder optimized for subject identity representation
Subject Cropping & Embedding.Each detected subject is cropped from its frame and encoded into a 768-dimensional identity embedding using FG-CLIP Xie et al. (2025), a fine-grained visual encoder optimized for subject identity representation
2025
-
[15]
An additional Qwen-VL-based identity verification step filters false positives from the clusters
Cross-Video Identity Clustering.Subject embeddings are clustered using K-means with cosine similarity to group instances of the same identity across different video clips. An additional Qwen-VL-based identity verification step filters false positives from the clusters. 20
-
[16]
Only subjects passing all quality gates are retained
Quality Filtering.We apply multi-dimensional filtering to remove low-quality subject images: blur detection (Laplacian variance and learned blur scores), text overlay detection, occlusion detection, face/body consistency checks, and aesthetic scoring. Only subjects passing all quality gates are retained
-
[17]
Based on the [subject] in Image-1, generate a video where. . . ,
Caption Generation & Formatting.For each valid subject-video pair, a VLM (Gemini / Qwen- VL) generates a subject-driven caption in the format “Based on the [subject] in Image-1, generate a video where. . . ,” explicitly referencing the subject image. The final output is formatted as (reference image, target video, subject-conditioned caption) training tup...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.