A Shared Valence Axis Across Modern LLMs and Human EEG: The Saturation Regularity
Pith reviewed 2026-06-29 08:20 UTC · model grok-4.3
The pith
A valence direction from nine sentences in LLMs projects linearly onto EEG and is rediscovered by classifiers, yet alignment training distorts the saturated direction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
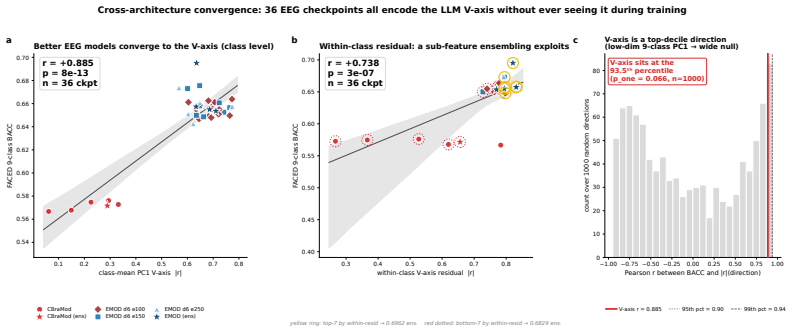
The V-axis is a stable one-dimensional direction extracted from LLMs with nine sentences that linearly tracks stimulus valence in EEG and is spontaneously recovered by EEG emotion classifiers; twenty-five alignment methods fail because task labels saturate the target direction, leaving the within-class residual as the source of further improvement through residual ensembling.
What carries the argument
The V-axis, a one-dimensional valence direction built from nine emotion-evocative sentences in LLMs, which acts as the shared structure that aligns with EEG features and is rediscovered by classifiers.
If this is right
- The V-axis transfers zero-shot to sentiment benchmarks and remains consistent across fourteen LLMs.
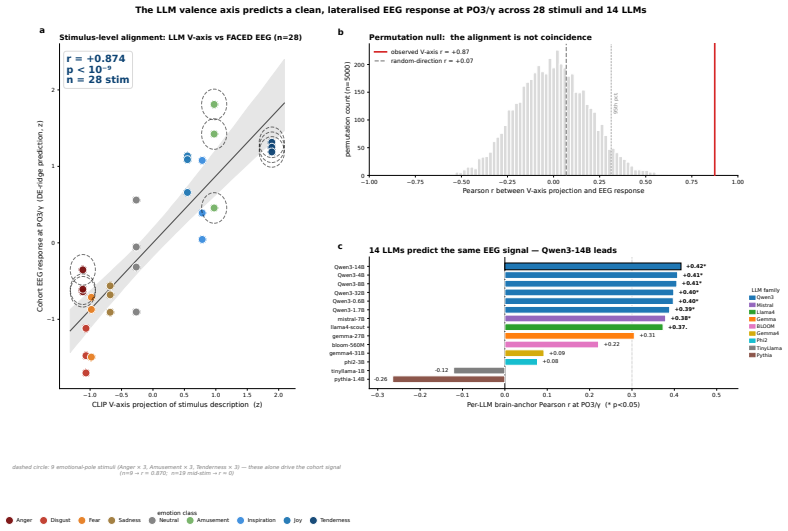
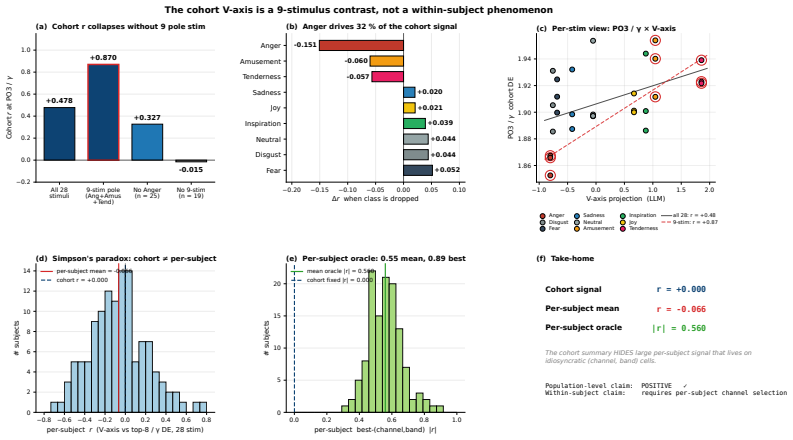
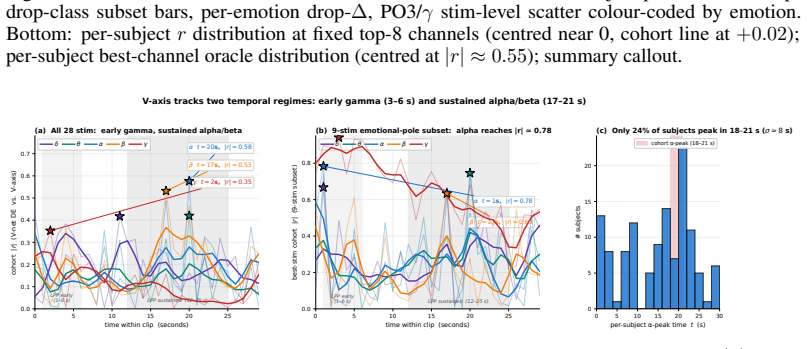
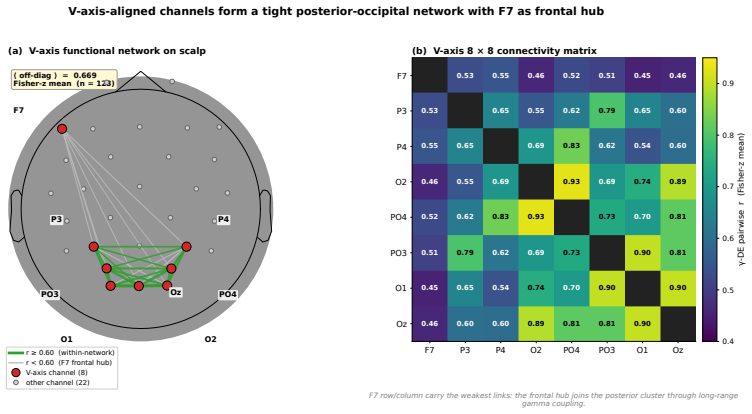
- A single linear projection of EEG features tracks the V-axis position of each affective stimulus.
- Thirty-six EEG emotion classifiers trained without reference to the V-axis rediscover the same direction in their internal representations.
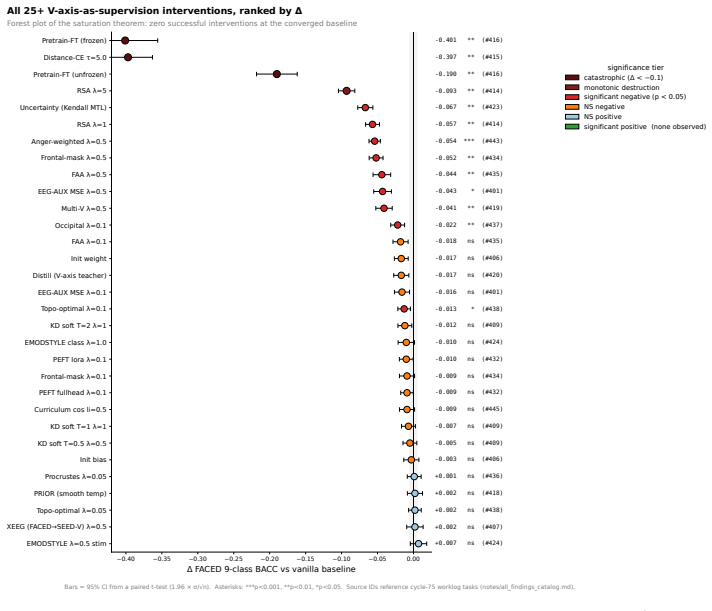
- Twenty-five alignment strategies including knowledge distillation, representational similarity, contrastive, and topographic losses fail to improve or actively reduce decoding accuracy.
- Ensembling across residual diversity improves balanced accuracy by 10.5 percent on FACED and replicates on SEED-V.
Where Pith is reading between the lines
- The saturation regularity suggests that once a target direction is reachable by labels alone, further multimodal supervision may systematically underperform compared with methods that preserve residual variation.
- Residual ensembling could be tested on other brain-decoding tasks where a low-dimensional target direction is already accessible from task labels.
- The within-class residual subspace may encode subject-specific or stimulus-specific emotional nuance that standard supervision overlooks.
Load-bearing premise
The V-axis built from nine specific sentences forms a stable valence representation whose linear projection onto EEG captures the same structure independent of sentence selection or model choice.
What would settle it
A replication in which a new set of nine sentences or a different group of LLMs yields a V-axis whose projection fails to track EEG stimulus valence or is not recovered inside the trained classifiers.
Figures







read the original abstract
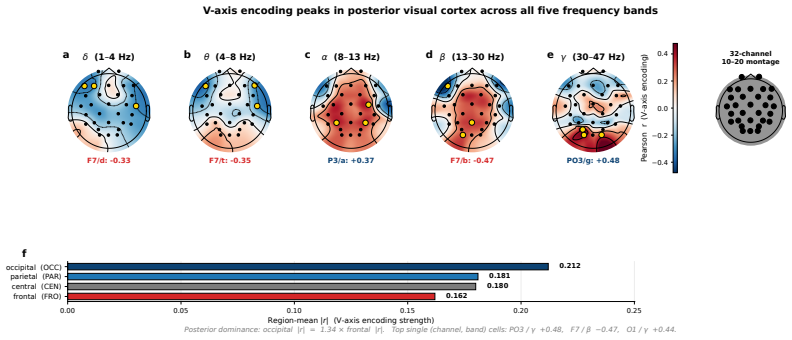
Large language models (LLMs) have emerged as powerful representation learners whose internal features increasingly align with human cognition. We study whether modern LLMs can serve as a lens for understanding neural representations in the human brain, focusing on emotional valence in EEG. We first build a one-dimensional valence direction, the V-axis, from modern LLMs using only nine emotion-evocative sentences. We validate it through zero-shot transfer to sentiment benchmarks and cross-model consistency across fourteen LLMs. We then show that this LLM-derived direction maps onto human neural activity. On a public EEG cohort of 123 subjects watching affective videos, a single linear projection on EEG features tracks the V-axis position of each stimulus. Moreover, 36 EEG emotion classifiers trained without exposure to the V-axis spontaneously rediscover the same direction in their internal representations, suggesting that the same valence structure emerges in both language models and human electrophysiology. Yet this convergence does not provide an effective training signal. We test twenty-five alignment strategies, including knowledge distillation, representational similarity, contrastive, and topographic losses; none improve decoding, and sixteen significantly reduce accuracy. We formalize this result as the saturation regularity: once task labels alone drive a brain-decoding network onto the target direction, additional supervision mainly distorts an already-saturated basin, while the load-bearing within-class residual receives little useful gradient. This regularity also indicates where improvement should come from: the residual subspace unreachable by supervision. Motivated by this insight, we ensemble across residual diversity rather than supervising the basin, improving balanced accuracy by 10.5% over the prior best on FACED, with the same effect replicated on SEED-V.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that a one-dimensional valence direction (V-axis) constructed from nine emotion-evocative sentences in LLMs shows zero-shot sentiment transfer and consistency across 14 LLMs; this direction linearly maps to EEG features from 123 subjects watching affective videos; 36 label-trained EEG classifiers spontaneously rediscover the same direction; 25 alignment strategies (distillation, similarity, contrastive, topographic) fail to improve and often reduce accuracy; this is formalized as the saturation regularity (task labels saturate the target direction while within-class residuals receive little gradient); ensembling across residual diversity yields a 10.5% balanced-accuracy gain over prior best on FACED, replicated on SEED-V.
Significance. If the results hold, the work provides large-scale empirical evidence (14 LLMs, 123 subjects, 36 classifiers, 25 strategies, two datasets) for a shared valence structure between modern LLMs and human EEG, plus a practical insight that further supervision is ineffective once labels saturate the direction and that residual ensembling can improve decoding. The scale of the experiments is a clear strength.
major comments (3)
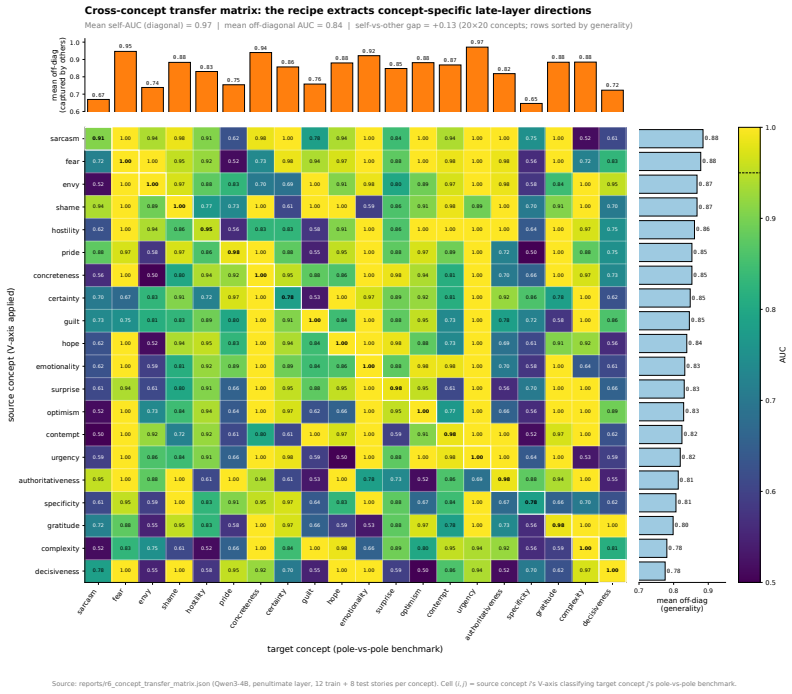
- [V-axis construction (Methods)] V-axis construction (Methods section describing sentence selection): The direction is derived from exactly nine specific emotion-evocative sentences with validation limited to zero-shot transfer and cross-model consistency across 14 LLMs. No ablation on sentence choice, synonym substitution, or alternative affective prompts is reported. This choice is load-bearing for the saturation regularity, the EEG linear-projection claim, and the 10.5% gain, because a different nine-sentence set could produce a less stable direction whose rediscovery by classifiers and resistance to alignment losses would not hold.
- [Results (EEG mapping and ensembling)] Statistical reporting (Results on EEG mapping, classifier rediscovery, and 10.5% gain): The manuscript reports consistent results across 123 subjects and 36 classifiers but provides no visible error bars, exact statistical tests (e.g., p-values or confidence intervals for the 10.5% improvement), or full subject exclusion criteria. This leaves the central saturation claim and the improvement only moderately supported.
- [Saturation regularity formalization] Formalization of saturation regularity (section introducing the regularity): The claim that task labels saturate the target direction and that additional supervision distorts an already-saturated basin while the within-class residual receives little gradient is presented as an empirical observation from the 25 alignment runs rather than derived from a specific equation or gradient analysis. A more precise definition tying the observation to the linear projection or loss landscape would be needed to make the regularity load-bearing rather than descriptive.
minor comments (1)
- [Methods] The linear projection weights from EEG features to the V-axis are listed among free parameters; a brief clarification of how they are obtained (e.g., via regression on stimulus V-axis positions) would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, proposing revisions where the points identify gaps in the current manuscript.
read point-by-point responses
-
Referee: [V-axis construction (Methods)] V-axis construction (Methods section describing sentence selection): The direction is derived from exactly nine specific emotion-evocative sentences with validation limited to zero-shot transfer and cross-model consistency across 14 LLMs. No ablation on sentence choice, synonym substitution, or alternative affective prompts is reported. This choice is load-bearing for the saturation regularity, the EEG linear-projection claim, and the 10.5% gain, because a different nine-sentence set could produce a less stable direction whose rediscovery by classifiers and resistance to alignment losses would not hold.
Authors: The manuscript does not report ablations on sentence selection or synonym substitution. The nine sentences were chosen to span a valence range using established affective norms, with robustness evidenced by zero-shot sentiment transfer and consistency across 14 LLMs. We will add a supplementary note discussing the rationale for sentence choice and explicitly acknowledging the lack of ablation studies as a limitation, but new experiments on alternative sets are not feasible within the current scope. revision: partial
-
Referee: [Results (EEG mapping and ensembling)] Statistical reporting (Results on EEG mapping, classifier rediscovery, and 10.5% gain): The manuscript reports consistent results across 123 subjects and 36 classifiers but provides no visible error bars, exact statistical tests (e.g., p-values or confidence intervals for the 10.5% improvement), or full subject exclusion criteria. This leaves the central saturation claim and the improvement only moderately supported.
Authors: We agree that the current statistical reporting is insufficient. The revision will add error bars to all figures, report exact p-values and confidence intervals for the 10.5% gain and other key metrics, and expand the Methods section with full subject exclusion criteria and preprocessing details. revision: yes
-
Referee: [Saturation regularity formalization] Formalization of saturation regularity (section introducing the regularity): The claim that task labels saturate the target direction and that additional supervision distorts an already-saturated basin while the within-class residual receives little gradient is presented as an empirical observation from the 25 alignment runs rather than derived from a specific equation or gradient analysis. A more precise definition tying the observation to the linear projection or loss landscape would be needed to make the regularity load-bearing rather than descriptive.
Authors: The saturation regularity is presented as an empirical observation from the alignment experiments. In revision we will add a more precise definition, including a brief mathematical characterization that ties the saturation effect to the linear projection geometry and the gradient dynamics under task-label supervision. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper constructs the V-axis empirically from nine LLM sentences, validates it via zero-shot transfer and cross-model checks on independent data, then reports separate empirical observations on an EEG cohort (linear projection tracking, 36 classifiers rediscovering the direction without exposure to V-axis, and 25 alignment strategies failing to improve decoding). The saturation regularity is formalized directly from these test outcomes rather than any equation that defines it by construction from fitted parameters or prior self-citations. The residual-ensemble improvement is a downstream method motivated by the observations but not equivalent to them. No load-bearing self-citation, ansatz smuggling, or renaming of known results appears in the derivation; the chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Selection of nine emotion-evocative sentences
- Linear projection weights from EEG features to V-axis
axioms (2)
- domain assumption Emotional valence is adequately captured by a single linear axis in both LLM embeddings and EEG signals.
- domain assumption Task-label supervision alone is sufficient to reach the valence direction without additional alignment losses.
invented entities (2)
-
V-axis
no independent evidence
-
Saturation regularity
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model
arXiv:2306.03341. Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin Raffel. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. InAdvances in Neural Information Processing Systems, 2022a. arXiv:2205.05638. Wei Liu, Jie-Lin Qiu, Wei-Long Zheng, and Bao-Liang Lu. Comparing recogni...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/tcds.2021.3071170 2021
-
[2]
Saturation (FACED-9, EMOD backbone, V-axis target)
URLhttps://transformer-circuits.pub/2026/emotions/index.html. Shobhita Sundaram, Stephanie Fu, Lukas Muttenthaler, Netanel Y Tamir, Lucy Chai, Simon Kornblith, Trevor Darrell, and Phillip Isola. When does perceptual alignment benefit vision representations? InAdvances in Neural Information Processing Systems, 2024. arXiv:2410.10817. Yonglong Tian, Dilip K...
-
[3]
Institutional review board (IRB) approvals or equivalent for research with human subjects 20 Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country ...
-
[4]
Theta-gamma cross-frequency coupling does not mediate the V-axis(Section 7, Ap- pendix S9): Tort modulation indexρ(PAC,Vr) = +0.082,p= 0.667
-
[5]
linear p= 0.020
Mutual-information control is not significant(Section 6): MI p= 0.115 vs. linear p= 0.020. The V-axis-EEG relationship is essentially linear. 39
-
[6]
Within-class residual ( r= +0.74 , p= 0.014) is the statistically robust signal
Random-direction null on cross-arch correlation(Section 4): r= +0.885 at the 93.5th percentile of a 1000-direction null, pone = 0.066 . Within-class residual ( r= +0.74 , p= 0.014) is the statistically robust signal
-
[7]
Per-subject V-axis adaptation does not transfer.The per-subject best-channel oracle reaches |r|= 0.62 , but no clean estimator transfers more than+0.001 over the cohort top-K
-
[8]
cross-arch0.6791(n.s.)
Cross-architecture ensembling does not add diversity.Mixing d∈ {4,6,8,10} check- points gives within-arch0.6798vs. cross-arch0.6791(n.s.)
-
[9]
Mega-ensembles plateau at 10 checkpoints.15-, 20-, 25-checkpoint pools all hit BACC ≤0.6948(Appendix S13)
-
[10]
Stimulus-aggregation re-ranking does not help.Operating at the 28-stimulus level instead of trial level gives BACC=1.0 by construction (label leak); the corresponding trial-level head does not transfer
-
[11]
Averaging predictions over augmented test trials does not preserve the V-axis residual structure
Test-time augmentation at K=5 does not improve the ensemble( 0.6753→0.6720 ). Averaging predictions over augmented test trials does not preserve the V-axis residual structure
-
[12]
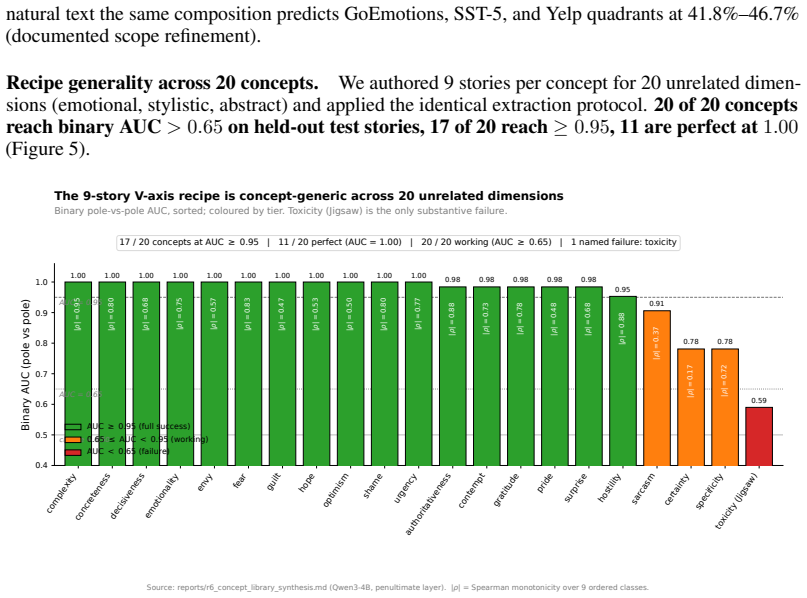
Toxicity: recipe scope.The 9-prompt PCA recipe attains AUC 0.59 on Jigsaw toxic comments, below the 17/20 working concepts in our library (Appendix S4); toxicity appears to be encoded in a higher-rank subspace than the late-layer PC1
-
[13]
Arousal asymmetry: vision yes, text and brain no.OASIS arousal r= 0.803 in vision; ≤13% NRC arousal recovery in text; r∈[0.18,0.41] brain alignment across LLMs (Appendix S6)
-
[14]
KD provides architectural regularisation; its semantic content is below our resolution
LLM-content of KD is irrelevant at this scale.Replacing the 9-D LLM-derived class prototypes with random orthonormal 9-D directions changes BACC by ≤0.003 . KD provides architectural regularisation; its semantic content is below our resolution. S19 Reproducibility Release commitment.Code, configs, model checkpoints, and figure-generation scripts will be r...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.