G²TR: Generation-Guided Visual Token Reduction for Separate-Encoder Unified Multimodal Models
Pith reviewed 2026-05-19 16:49 UTC · model grok-4.3
The pith
Generation-guided selection from the VAE latent cuts visual tokens by 1.94x in separate-encoder unified multimodal models while preserving both reasoning accuracy and editing quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
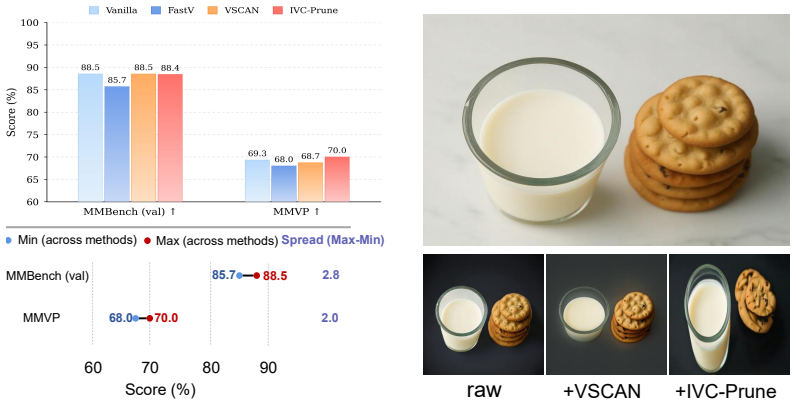
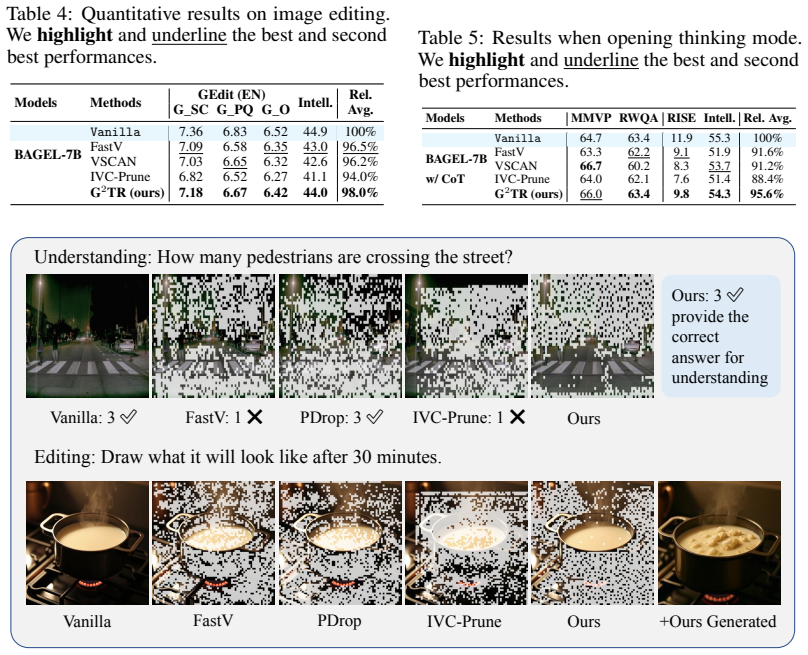
G²TR estimates token importance from consistency with VAE latent in the generation branch, performs balanced token selection, and merges redundant tokens into retained representatives. Applied only after the understanding encoding stage as a training-free step, the method reduces visual tokens and prefill computation by 1.94x on image understanding and editing benchmarks while maintaining reasoning accuracy and editing quality, outperforming attention-score and text-image similarity baselines on almost all tasks.
What carries the argument
Consistency with VAE latent from the generation branch, used to rank and select understanding-side visual tokens before balanced merging.
If this is right
- Visual token count and prefill compute drop by a measured factor of 1.94x.
- Reasoning accuracy on image-understanding benchmarks stays at full-token levels.
- Image-editing quality on corresponding benchmarks is preserved.
- The method beats attention-based and similarity-based baselines on nearly every reported task.
- No retraining or pipeline changes are required beyond the post-encoding selection step.
Where Pith is reading between the lines
- The same generation-consistency signal could be tested on video or 3-D inputs where token volume grows even faster.
- Interactive editing systems might adopt this reduction to reach real-time rates without separate lightweight models.
- If VAE consistency proves stable across fine-tuned checkpoints, the technique could become a default efficiency layer for any dual-branch multimodal architecture.
Load-bearing premise
That consistency with VAE latent supplies a task-agnostic signal sufficient to keep editing and generation capabilities intact even when selection occurs only on the understanding-side tokens.
What would settle it
Run the reduced-token model on a standard image-editing benchmark and observe whether metrics such as PSNR or FID degrade relative to the full-token baseline while reasoning accuracy on VQA-style tasks remains unchanged.
Figures




read the original abstract
The development of separate-encoder Unified multimodal models (UMMs) comes with a rapidly growing inference cost due to dense visual token processing. In this paper, we focus on understanding-side visual token reduction for improving the efficiency of separate-encoder UMMs. While this topic has been widely studied for MLLMs, existing methods typically rely on attention scores, text-image similarity and so on, implicitly assuming that the final objective is discriminative reasoning. This assumption does not hold for UMMs, where understanding-side visual tokens must also preserve the model's capabilities for editing images. We propose G$^2$TR, a generation-guided visual token reduction framework for separate-encoder UMMs. Our key insight is that the generation branch provides a task-agnostic signal for identifying understanding-side visual tokens that are not only semantically relevant but also important for latent-space image reconstruction and generation. G$^2$TR estimates token importance from consistency with VAE latent, performs balanced token selection, and merges redundant tokens into retained representatives to reduce information loss. The method is training-free, plug-and-play, and applied only after the understanding encoding stage, making it compatible with existing UMM inference pipelines. Experiments on image understanding and editing benchmarks show that G$^2$TR substantially reduces visual tokens and prefill computation by 1.94x while maintaining both reasoning accuracy and editing quality, outperforming baselines on almost all benchmarks. Code is at: https://github.com/lijunxian111/G2TR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents G²TR, a generation-guided visual token reduction framework for separate-encoder unified multimodal models (UMMs). It derives token importance from consistency between understanding-side tokens and VAE latents in the generation branch, then applies balanced selection and merging to reduce visual tokens. The method is training-free and plug-and-play after the understanding encoding stage. Experiments on image understanding and editing benchmarks report a 1.94x reduction in tokens and prefill computation while maintaining reasoning accuracy and editing quality, outperforming baselines.
Significance. If the performance claims hold, this provides a practical efficiency improvement for UMMs that must support both understanding and generation, unlike prior token reduction techniques focused solely on discriminative reasoning. Strengths include the training-free design, use of an external generation signal for task-agnostic importance, and public code release for reproducibility.
major comments (1)
- The central claim that editing quality is preserved with the 1.94x reduction (abstract and experiments) relies on the VAE consistency signal identifying tokens important beyond reconstruction. Since VAE latents optimize for faithful reconstruction, tokens redundant for reconstruction may still be critical for non-reconstructive edits such as attribute changes or object insertion. The experiments section should include targeted analysis or ablations demonstrating that the selected tokens maintain editability on such operations.
minor comments (3)
- The abstract and results summary provide no details on error bars, exact benchmark datasets, data exclusion rules, or the precise metrics and protocol used to quantify editing quality.
- The description of balanced token selection and merging would benefit from additional algorithmic detail or pseudocode to ensure full reproducibility.
- Clarify whether all baselines were evaluated at identical token reduction ratios for fair comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the major comment point by point below.
read point-by-point responses
-
Referee: The central claim that editing quality is preserved with the 1.94x reduction (abstract and experiments) relies on the VAE consistency signal identifying tokens important beyond reconstruction. Since VAE latents optimize for faithful reconstruction, tokens redundant for reconstruction may still be critical for non-reconstructive edits such as attribute changes or object insertion. The experiments section should include targeted analysis or ablations demonstrating that the selected tokens maintain editability on such operations.
Authors: We appreciate the referee's insightful point on the distinction between reconstruction-focused signals and editability requirements. Our generation-guided importance derives from consistency between understanding tokens and VAE latents in the generation branch, which UMMs employ for both reconstruction and editing operations. The editing benchmarks reported in the manuscript encompass a variety of tasks, including attribute changes and object insertions, where we show that editing quality is preserved at the 1.94x reduction. We agree, however, that dedicated ablations isolating these non-reconstructive edit types would provide stronger evidence. In the revised manuscript we will add targeted analysis and ablations evaluating editability specifically on attribute modification and object insertion tasks. revision: yes
Circularity Check
No circularity: method is training-free with external VAE signal and empirical validation
full rationale
The paper defines G²TR as a plug-and-play, training-free procedure that computes token importance via consistency between understanding-encoder outputs and VAE latents from the separate generation branch, followed by explicit balanced selection and merging rules. No parameters are fitted to the target benchmarks; the selection criterion is stated directly from the VAE reconstruction objective rather than being derived from or equivalent to the final accuracy or editing-quality metrics. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the core steps. Experimental results are presented as post-hoc measurements on standard benchmarks, not as predictions forced by the method's own construction. The derivation chain therefore contains independent content and does not reduce to its inputs by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Consistency with VAE latent identifies tokens important for both semantic understanding and latent-space image reconstruction/generation.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Improving image generation with better captions
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions. Computer Science. https://cdn.openai.com/papers/dall-e-3.pdf, 2023
work page 2023
-
[3]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InECCV, 2024
work page 2024
-
[4]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Diffusion models in vision: A survey.TPAMI, 2023
Florinel-Alin Croitoru, Vlad Hondru, Radu Tudor Ionescu, and Mubarak Shah. Diffusion models in vision: A survey.TPAMI, 2023
work page 2023
-
[6]
Flashattention: Fast and memory-efficient exact attention with io-awareness
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. InNeurIPS, 2022
work page 2022
-
[7]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Mme: A comprehensive evaluation benchmark for multimodal large language models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models. InNeurIPS Datasets and Benchmarks Track, 2025
work page 2025
-
[9]
Gemini 3 pro image (nano banana pro)
Google. Gemini 3 pro image (nano banana pro). https://aistudio.google.com/models/ gemini-3-pro-image, 2025
work page 2025
-
[10]
Shwai He, Chaorui Deng, Ang Li, and Shen Yan. Understanding and harnessing sparsity in unified multimodal models.arXiv preprint arXiv:2512.02351, 2025
-
[11]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
work page 2024
-
[12]
PlanViz: Evaluating Planning-Oriented Image Generation and Editing for Computer-Use Tasks
Junxian Li, Kai Liu, Leyang Chen, Weida Wang, Zhixin Wang, Jiaqi Xu, Fan Li, Renjing Pei, Linghe Kong, and Yulun Zhang. Planviz: Evaluating planning-oriented image generation and editing for computer-use tasks.arXiv preprint arXiv:2602.06663, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Dual diffusion for unified image generation and understanding
Zijie Li, Henry Li, Yichun Shi, Amir Barati Farimani, Yuval Kluger, Linjie Yang, and Peng Wang. Dual diffusion for unified image generation and understanding. InCVPR, 2025
work page 2025
-
[14]
Yongyuan Liang, Wei Chow, Feng Li, Ziqiao Ma, Xiyao Wang, Jiageng Mao, Jiuhai Chen, Jiatao Gu, Yue Wang, and Furong Huang. Rover: Benchmarking reciprocal cross-modal reasoning for omnimodal generation.arXiv preprint arXiv:2511.01163, 2025
-
[15]
Visual instruction tuning.NeurIPS, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.NeurIPS, 2023
work page 2023
-
[16]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chunrui Han, et al. Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Mmbench: Is your multi-modal model an all-around player? InECCV, 2024
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InECCV, 2024
work page 2024
-
[18]
Weijia Mao, Zhenheng Yang, and Mike Zheng Shou. Unimod: Efficient unified multimodal transformers with mixture-of-depths.arXiv preprint arXiv:2502.06474, 2025
-
[19]
Introducing our latest image generation model in the api
OpenAI. Introducing our latest image generation model in the api. https://openai.com/ index/image-generation-api/, 2025
work page 2025
-
[20]
Wiseedit: Benchmarking cognition-and creativity-informed image editing
Kaihang Pan, Weile Chen, Haiyi Qiu, Qifan Yu, Wendong Bu, Zehan Wang, Yun Zhu, Juncheng Li, and Siliang Tang. Wiseedit: Benchmarking cognition-and creativity-informed image editing. arXiv preprint arXiv:2512.00387, 2025
-
[21]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
work page 2022
-
[22]
Holitom: Holistic token merging for fast video large language models
Kele Shao, TAO Keda, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Holitom: Holistic token merging for fast video large language models. InNeurIPS, 2025
work page 2025
-
[23]
A survey of token compression for efficient multimodal large language models.TMLR, 2025
Kele Shao, TAO Keda, Kejia Zhang, Sicheng Feng, Mu Cai, Yuzhang Shang, Haoxuan You, Can Qin, Yang Sui, and Huan Wang. A survey of token compression for efficient multimodal large language models.TMLR, 2025
work page 2025
-
[24]
Less is more: A simple yet effective token reduction method for efficient multi-modal llms
Dingjie Song, Wenjun Wang, Shunian Chen, Xidong Wang, Michael X Guan, and Benyou Wang. Less is more: A simple yet effective token reduction method for efficient multi-modal llms. InCOLING, 2025
work page 2025
-
[25]
Zhichao Sun, Yidong Ma, Gang Liu, Yibo Chen, Xu Tang, Yao Hu, and Yongchao Xu. Ivc- prune: Revealing the implicit visual coordinates in lvlms for vision token pruning.arXiv preprint arXiv:2602.03060, 2026
-
[26]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Changyao Tian, Danni Yang, Guanzhou Chen, Erfei Cui, Zhaokai Wang, Yuchen Duan, Penghao Yin, Sitao Chen, Ganlin Yang, Mingxin Liu, et al. Internvl-u: Democratizing unified multimodal models for understanding, reasoning, generation and editing.arXiv preprint arXiv:2603.09877, 2026
-
[29]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InCVPR, 2024
work page 2024
-
[30]
VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, and Wenhu Chen. Vl- rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning. arXiv preprint arXiv:2504.08837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
RationalRewards: Reasoning Rewards Scale Visual Generation Both Training and Test Time
Haozhe Wang, Cong Wei, Weiming Ren, Jiaming Liu, Fangzhen Lin, and Wenhu Chen. Ra- tionalrewards: Reasoning rewards scale visual generation both training and test time.arXiv preprint arXiv:2604.11626, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Haozhe Wang, Qixin Xu, Che Liu, Junhong Wu, Fangzhen Lin, and Wenhu Chen. Emergent hierarchical reasoning in llms through reinforcement learning.arXiv preprint arXiv:2509.03646, 2025
-
[33]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Zichen Wen, Yifeng Gao, Weijia Li, Conghui He, and Linfeng Zhang. Token pruning in multimodal large language models: Are we solving the right problem? InACL Findings, 2025. 11
work page 2025
-
[35]
Janus: Decoupling visual encoding for unified multimodal understanding and generation
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, et al. Janus: Decoupling visual encoding for unified multimodal understanding and generation. InCVPR, 2025
work page 2025
-
[36]
Kris-bench: Benchmarking next-level intelligent image editing models
Yongliang Wu, Zonghui Li, Xinting Hu, Xinyu Ye, Xianfang Zeng, Gang YU, Wenbo Zhu, Bernt Schiele, Ming-Hsuan Yang, and Xu Yang. Kris-bench: Benchmarking next-level intelligent image editing models. InNeurIPS Datasets and Benchmarks Track, 2025
work page 2025
-
[37]
Announcing grok-1.5.https://x.ai/news/grok-1.5, 2024
xAI. Announcing grok-1.5.https://x.ai/news/grok-1.5, 2024
work page 2024
-
[38]
Show-o: One single transformer to unify multimodal understanding and generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation. InICLR, 2025
work page 2025
-
[39]
Show-o2: Improved native unified multimodal models
Jinheng Xie, Zhenheng Yang, and Mike Zheng Shou. Show-o2: Improved native unified multimodal models. InNeurIPS, 2025
work page 2025
-
[40]
Conical visual concentration for efficient large vision-language models
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, et al. Conical visual concentration for efficient large vision-language models. InCVPR, 2025
work page 2025
-
[41]
Rethinking visual token reduction in lvlms under cross-modal misalignment
Rui Xu, Yunke Wang, Yong Luo, and Bo Du. Rethinking visual token reduction in lvlms under cross-modal misalignment. InAAAI, 2026
work page 2026
-
[42]
Vscan: Rethinking visual token reduction for efficient large vision-language models.TMLR, 2026
Ce Zhang, Kaixin Ma, Tianqing Fang, Wenhao Yu, Hongming Zhang, Zhisong Zhang, Haitao Mi, and Dong Yu. Vscan: Rethinking visual token reduction for efficient large vision-language models.TMLR, 2026
work page 2026
-
[43]
Envisioning beyond the pixels: Bench- marking reasoning-informed visual editing
Xiangyu Zhao, Peiyuan Zhang, Kexian Tang, Xiaorong Zhu, Hao Li, Wenhao Chai, Zicheng Zhang, Renqiu Xia, Guangtao Zhai, Junchi Yan, et al. Envisioning beyond the pixels: Bench- marking reasoning-informed visual editing. InNeurIPS Datasets and Benchmarks Track, 2025
work page 2025
-
[44]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 12 A Relationship among Generation, Editing and Understanding-side Visual Tokens Image generation (...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.