PhysEditWorld: A Large-Scale Dataset Toward Physics-Editable World Models
Pith reviewed 2026-06-26 05:44 UTC · model grok-4.3
The pith
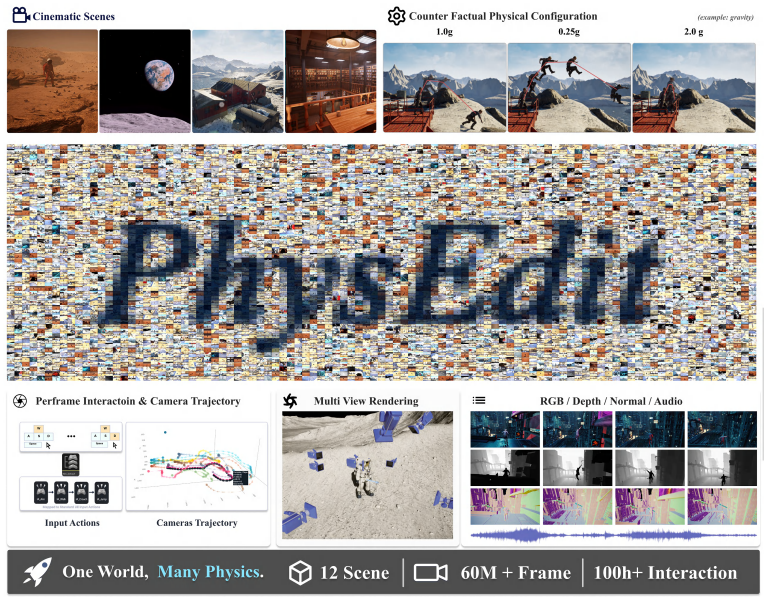
PhysEditWorld supplies over 60 million frames of identical actions replayed under multiple gravity settings to train world models on explicit rather than implicit physics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
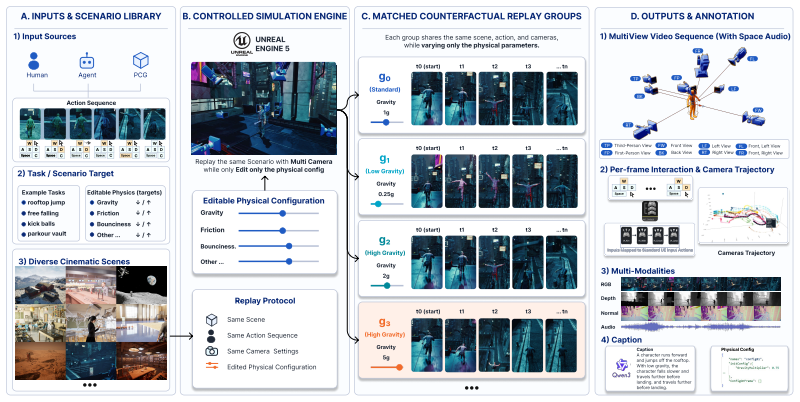
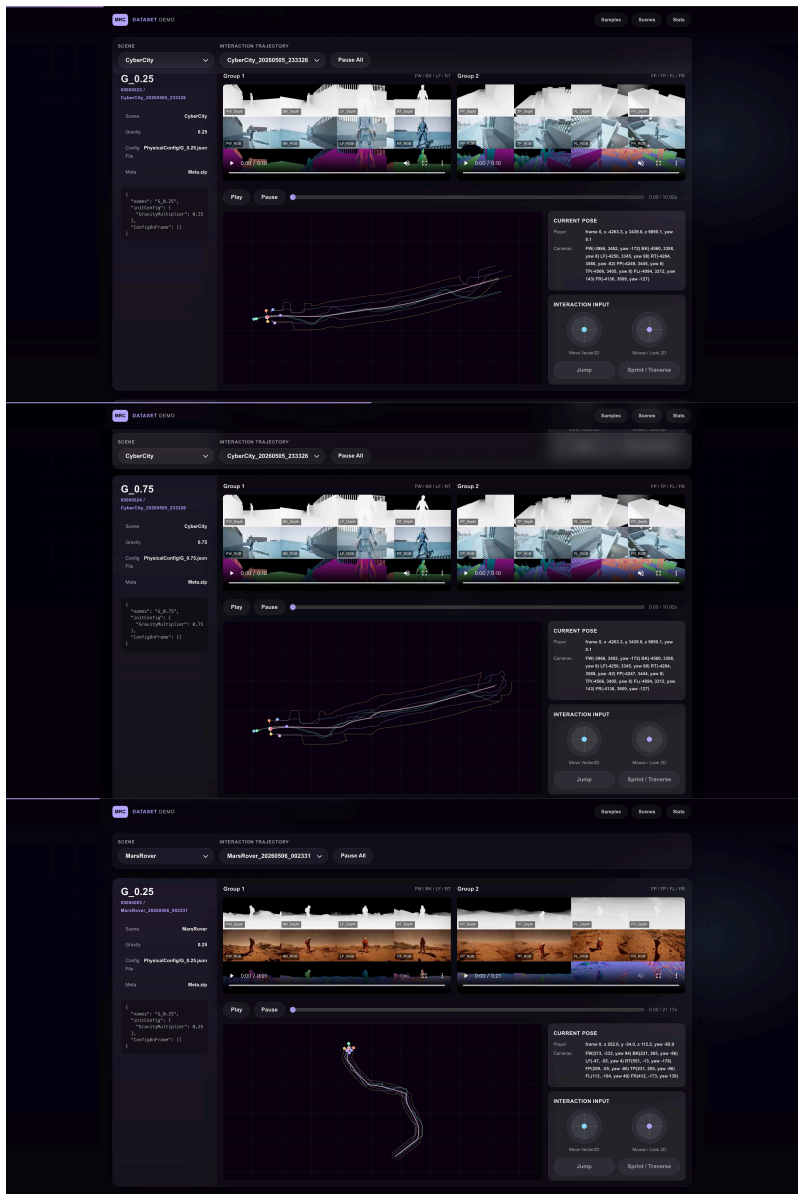
PhysEditWorld is constructed via a UE5 replay-and-rendering pipeline that fixes action traces, character controllers, and camera policies while varying only gravity across multiple configurations, thereby producing attributable physical changes across more than 100 hours of interaction and 60 million multimodal frames that include explicit gravity labels alongside RGB, depth, normals, audio, and semantic annotations.
What carries the argument
The replay paradigm that records a single normalized action trace and camera policy then replays the identical initial state under multiple gravity configurations inside the UE5 engine.
If this is right
- Generative video models achieve improved gravity-faithful dynamics.
- World understanding models exhibit greater consistency when physical parameters are edited.
- The dataset supplies a scalable base for research on controllable rather than purely predictive world models.
- Explicit gravity labels allow training regimes that treat physics parameters as inputs rather than latent correlations.
Where Pith is reading between the lines
- The replay structure could be reused for other parameters such as friction or bounciness once the gravity version demonstrates clean attribution.
- Mid-sequence gravity edits become testable because the dataset already isolates the effect of a single parameter change.
- If UE5 physics matches real-world behavior closely enough, models trained here could transfer to robotic or simulation tasks that require gravity-aware planning.
- The multimodal labels open the possibility of joint training on vision, audio, and state signals for more robust physics inference.
Load-bearing premise
Replaying fixed action traces and camera policies under changed gravity produces physical differences that can be attributed to gravity alone without engine-side side effects or rendering artifacts.
What would settle it
A model trained on PhysEditWorld predicts rollout frames under a held-out gravity value that deviate from the ground-truth UE5 simulation by the same margin as a model trained without gravity labels.
Figures







read the original abstract
Recent game world models can synthesize visually plausible, action-conditioned rollouts. However, their interaction behaviors often remain limited to exploratory or wandering trajectories, and physical dynamics are typically learned as implicit correlations from data rather than as controllable variables. This limitation hinders their applicability to authored game environments, where physical rules are deliberately designed and require explicit manipulation. We introduce PhysEditWorld, a multimodal dataset with physical parameters, with a primary focus on gravity in this initial version. At its core, PhysEditWorld is built upon a replay paradigm implemented with a UE5 replay-and-rendering pipeline. Each scenario records a normalized action trace and replays the same initial state, character controller, action sequence, and camera policy under multiple gravity configurations, enabling controlled and attributable physical variation. PhysEditWorld contains 12 cinematic UE5 scenes, over 100 hours of gameplay interactions, and more than 60 million rendered rollout frames. Each sample provides synchronized multimodal signals, including RGB, depth, normals, audio, action traces, camera trajectory, engine states, semantic annotations, and explicit gravity labels. We further conduct initial utility studies on both generative video models and world understanding models, demonstrating that PhysEditWorld enables improved gravity-faithful dynamics modeling, enhances consistency under physical edits, and provides a scalable foundation for controllable world modeling research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PhysEditWorld, a multimodal dataset of over 100 hours of UE5 gameplay interactions (60M+ frames) across 12 cinematic scenes. It is constructed via a replay paradigm that records normalized action traces and camera policies from an initial state and replays them under multiple gravity configurations while providing synchronized RGB, depth, normals, audio, actions, camera trajectories, engine states, semantic annotations, and explicit gravity labels. The central claim is that this construction supplies clean, attributable physical variation, and that initial utility studies on generative video models and world-understanding models show the dataset enables improved gravity-faithful dynamics modeling and consistency under physical edits.
Significance. If the replay construction isolates gravity effects without confounding engine or rendering changes, the dataset would supply a scalable, labeled resource for training world models that treat physical parameters as explicit, editable variables rather than implicit correlations learned from exploratory trajectories.
major comments (2)
- [Abstract] Abstract: the claim that 'utility studies ... demonstrating that PhysEditWorld enables improved gravity-faithful dynamics modeling' is unsupported by any quantitative results, baselines, error metrics, or ablation tables; without these the central utility assertion cannot be evaluated.
- [Abstract] Abstract (replay paradigm paragraph): the assertion of 'controlled and attributable physical variation' rests on the assumption that only gravity changes across replays, yet the manuscript provides no verification that UE5 engine states, collision responses, animation state machines, or rendering pipelines remain invariant when gravity is altered; engine states are supplied but constancy is not demonstrated.
minor comments (1)
- The scale figures (12 scenes, >100 hours, >60M frames) are stated without breakdown by scene or gravity setting, making it difficult to assess coverage and balance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'utility studies ... demonstrating that PhysEditWorld enables improved gravity-faithful dynamics modeling' is unsupported by any quantitative results, baselines, error metrics, or ablation tables; without these the central utility assertion cannot be evaluated.
Authors: We agree that the abstract phrasing is too strong given the preliminary nature of the studies. Section 5 presents initial experiments on generative video models (with qualitative rollouts) and world-understanding models (with gravity classification accuracy), but these lack the full quantitative baselines, error metrics, and ablations the referee correctly notes are needed for a robust claim. We will revise the abstract to describe the studies as 'preliminary' and point explicitly to Section 5, and we will expand the experiments in revision with additional quantitative metrics and comparisons. revision: yes
-
Referee: [Abstract] Abstract (replay paradigm paragraph): the assertion of 'controlled and attributable physical variation' rests on the assumption that only gravity changes across replays, yet the manuscript provides no verification that UE5 engine states, collision responses, animation state machines, or rendering pipelines remain invariant when gravity is altered; engine states are supplied but constancy is not demonstrated.
Authors: The referee is correct that explicit verification of invariance is missing. The replay paradigm relies on UE5's deterministic replay system with fixed action traces and initial states, and engine states are recorded to enable post-hoc checks, but we did not include any comparative analysis confirming that non-gravity components (e.g., collision responses outside gravity effects or animation states) remain unchanged. We will add this verification—using the supplied engine state logs—to Section 3 or a new appendix in the revised manuscript. revision: yes
Circularity Check
No derivation chain present; dataset contribution is self-contained
full rationale
The paper introduces a multimodal dataset constructed via a UE5 replay paradigm that records and replays fixed action traces under varying gravity settings. No equations, fitted parameters, predictions, or first-principles derivations are described that could reduce to their own inputs by construction. Claims about enabling gravity-faithful modeling are presented as downstream utility studies rather than internal results forced by the dataset construction itself. The contribution is empirical data collection, not a closed-loop theoretical or predictive system, so no circularity patterns apply.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption UE5 physics simulation produces attributable changes when only gravity is modified while action traces and initial states remain identical.
Reference graph
Works this paper leans on
-
[1]
Jake Bruce, Michael Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Bechtle, Feryal Behbahani, Stephanie C. Y . Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando de Freitas, Sati...
2024
-
[2]
Diffusion for world modeling: Visual details matter in Atari
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and Francois Fleuret. Diffusion for world modeling: Visual details matter in Atari. InAdvances in Neural Information Processing Systems, 2024
2024
-
[3]
Diffusion models are real- time game engines
Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter. Diffusion models are real- time game engines. InInternational Conference on Learning Representations, 2025. URL https://arxiv.org/abs/2408.14837
Pith/arXiv arXiv 2025
-
[4]
Gamegen-x: Interactive open-world game video generation
Haoxuan Che, Xuanhua He, Quande Liu, Cheng Jin, and Hao Chen. Gamegen-x: Interactive open-world game video generation. InInternational Conference on Learning Representations, 2025
2025
-
[5]
Advancing open-source world models.arXiv preprint arXiv:2601.20540, 2026
Robbyant Team, Zelin Gao, Qiuyu Wang, Yanhong Zeng, Jiapeng Zhu, Ka Leong Cheng, Yixuan Li, Hanlin Wang, Yinghao Xu, Shuailei Ma, Yihang Chen, Jie Liu, Yansong Cheng, Yao Yao, Jiayi Zhu, Yihao Meng, Kecheng Zheng, Qingyan Bai, Jingye Chen, Zehong Shen, Yue Yu, Xing Zhu, Yujun Shen, and Hao Ouyang. Advancing open-source world models.arXiv preprint arXiv:26...
Pith/arXiv arXiv 2026
-
[6]
Zile Wang, Zexiang Liu, Jiaxing Li, Kaichen Huang, Baixin Xu, Fei Kang, Mengyin An, Peiyu Wang, Biao Jiang, Yichen Wei, Yidan Xietian, Jiangbo Pei, Liang Hu, Boyi Jiang, Hua Xue, Zidong Wang, Haofeng Sun, Wei Li, Wanli Ouyang, Xianglong He, Yang Liu, Yangguang Li, and Yahui Zhou. Matrix-game 3.0: Real-time and streaming interactive world model with long-h...
Pith/arXiv arXiv 2026
-
[7]
Yume: An interactive world generation model.arXiv preprint arXiv:2507.17744, 2025
Xiaofeng Mao, Shaoheng Lin, Zhen Li, Chuanhao Li, Wenshuo Peng, Tong He, Jiangmiao Pang, Mingmin Chi, Yu Qiao, and Kaipeng Zhang. Yume: An interactive world generation model.arXiv preprint arXiv:2507.17744, 2025
arXiv 2025
-
[8]
Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling
Marc G. Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents.Journal of Artificial Intelligence Research, 47:253–279, 2013
2013
-
[9]
Leveraging procedural generation to benchmark reinforcement learning
Karl Cobbe, Christopher Hesse, Jacob Hilton, and John Schulman. Leveraging procedural generation to benchmark reinforcement learning. InInternational Conference on Machine Learning, 2020
2020
-
[10]
Guss, Brandon Houghton, Nicholay Topin, Phillip Wang, Cayden Codel, Manuela Veloso, and Ruslan Salakhutdinov
William H. Guss, Brandon Houghton, Nicholay Topin, Phillip Wang, Cayden Codel, Manuela Veloso, and Ruslan Salakhutdinov. MineRL: A large-scale dataset of Minecraft demonstrations. InInternational Joint Conference on Artificial Intelligence, 2019. 10
2019
-
[11]
CARLA: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. CARLA: An open urban driving simulator. InConference on Robot Learning, 2017
2017
-
[12]
Sekai: A video dataset towards world exploration
Zhen Li, Chuanhao Li, Xiaofeng Mao, Shaoheng Lin, Ming Li, Shitian Zhao, Zhaopan Xu, Xinyue Li, Yukang Feng, Jianwen Sun, et al. Sekai: A video dataset towards world exploration. InAdvances in Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[13]
PHYRE: A new benchmark for physical reasoning
Anton Bakhtin, Laurens van der Maaten, Justin Johnson, Laura Gustafson, and Ross Gir- shick. PHYRE: A new benchmark for physical reasoning. InAdvances in Neural Information Processing Systems, 2019
2019
-
[14]
Tenenbaum
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B. Tenenbaum. CLEVRER: Collision events for video representation and reasoning. InInterna- tional Conference on Learning Representations, 2020
2020
-
[15]
Bear, Elias Wang, Damian Mrowca, Felix J
Daniel M. Bear, Elias Wang, Damian Mrowca, Felix J. Binder, et al. Physion: Evaluating physical prediction from vision in humans and machines. InAdvances in Neural Information Processing Systems Datasets and Benchmarks Track, 2021
2021
-
[16]
VBench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, et al. VBench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[17]
VideoPhy: Evaluating physical commonsense for video generation
Hritik Bansal, Zongyu Lin, Tianyi Xie, Zeshun Zong, Michal Yarom, Yonatan Bitton, Chenfanfu Jiang, Yizhou Sun, Kai-Wei Chang, and Aditya Grover. VideoPhy: Evaluating physical commonsense for video generation. InInternational Conference on Learning Representations, 2025
2025
-
[18]
Towards world simulator: Crafting physical commonsense- based benchmark for video generation
Fanqing Meng, Jiaqi Liao, Xinyu Tan, Wenqi Shao, Quanfeng Lu, Kaipeng Zhang, Yu Cheng, Dianqi Li, Yu Qiao, and Ping Luo. Towards world simulator: Crafting physical commonsense- based benchmark for video generation. InInternational Conference on Machine Learning, 2025
2025
-
[19]
Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do gen- erative video models understand physical principles? InProceedings of the IEEE/CVF Win- ter Conference on Applications of Computer Vision, pages 948–958, March 2026. URL https://arxiv.org/abs/2501.09038
Pith/arXiv arXiv 2026
-
[20]
Physinone: Visual physics learning and reasoning in one suite.arXiv preprint arXiv:2604.09415, 2026
Siyuan Zhou, Hejun Wang, Hu Cheng, Jinxi Li, Dongsheng Wang, Junwei Jiang, Yixiao Jin, Jiayue Huang, Shiwei Mao, Shangjia Liu, et al. Physinone: Visual physics learning and reasoning in one suite.arXiv preprint arXiv:2604.09415, 2026
Pith/arXiv arXiv 2026
-
[21]
Learning to simulate dynamic environments with GameGAN
Seung Wook Kim, Yuhao Zhou, Jonah Philion, Antonio Torralba, and Sanja Fidler. Learning to simulate dynamic environments with GameGAN. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020
2020
-
[22]
Playable video generation
Willi Menapace, Stephane Lathuiliere, Sergey Tulyakov, Aliaksandr Siarohin, and Elisa Ricci. Playable video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021
2021
-
[23]
Playable environments: Video manipula- tion in space and time
Willi Menapace, Stéphane Lathuilière, Aliaksandr Siarohin, Christian Theobalt, Sergey Tulyakov, Vladislav Golyanik, and Elisa Ricci. Playable environments: Video manipula- tion in space and time. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3584–3593, 2022. URL https://arxiv.org/abs/2203.01914
arXiv 2022
-
[24]
Promptable game models: Text-guided game simulation via masked diffusion models.ACM Transactions on Graphics, 2024
Willi Menapace, Aliaksandr Siarohin, Stephane Lathuiliere, Panos Achlioptas, Vladislav Golyanik, Sergey Tulyakov, and Elisa Ricci. Promptable game models: Text-guided game simulation via masked diffusion models.ACM Transactions on Graphics, 2024
2024
-
[25]
Oasis: A universe in a transformer
Decart, Julian Quevedo, Quinn McIntyre, Spruce Campbell, Xinlei Chen, and Robert Wachen. Oasis: A universe in a transformer. Project page, 2024. URLhttps://oasis-model.github. io/. 11
2024
-
[26]
Gamefactory: Creating new games with generative interactive videos
Jiwen Yu, Yiran Qin, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Gamefactory: Creating new games with generative interactive videos. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[27]
Junliang Guo, Yang Ye, Tianyu He, Haoyu Wu, Yushu Jiang, Tim Pearce, and Jiang Bian. Mineworld: A real-time and open-source interactive world model on Minecraft.arXiv preprint arXiv:2504.08388, 2025
arXiv 2025
-
[28]
Learning world models for interactive video generation.arXiv preprint arXiv:2505.21996, 2025
Taiye Chen, Xun Hu, Zihan Ding, and Chi Jin. Learning world models for interactive video generation.arXiv preprint arXiv:2505.21996, 2025
Pith/arXiv arXiv 2025
-
[29]
Identity-consistent video generation under large facial-angle variations,
Bin Hu, Zipeng Qi, Guoxi Huang, Zunnan Xu, Ruicheng Zhang, Chongjie Ye, Jun Zhou, Xiu Li, and Jingdong Wang. Identity-consistent video generation under large facial-angle variations,
-
[30]
URLhttps://arxiv.org/abs/2603.21299
-
[31]
Video pretraining (VPT): Learning to act by watching unlabeled online videos
Bowen Baker, Ilge Akkaya, Peter Zhokhov, Joost Huizinga, Jie Tang, Adrien Ecoffet, Brandon Houghton, Raul Sampedro, and Jeff Clune. Video pretraining (VPT): Learning to act by watching unlabeled online videos. InAdvances in Neural Information Processing Systems, 2022. URLhttps://arxiv.org/abs/2206.11795
arXiv 2022
-
[32]
MineDojo: Building open-ended embodied agents with internet-scale knowledge
Linxi Fan, Guanzhi Wang, Yunfan Jiang, Ajay Mandlekar, Yuncong Yang, Haoyi Zhu, Andrew Tang, De-An Huang, Yuke Zhu, and Anima Anandkumar. MineDojo: Building open-ended embodied agents with internet-scale knowledge. InAdvances in Neural Information Processing Systems Datasets and Benchmarks Track, 2022. URL https://openreview.net/forum? id=rc8o_j8I8PX
2022
-
[33]
Zhen Li, Zian Meng, Shuwei Shi, Wenshuo Peng, Yuwei Wu, Bo Zheng, Chuanhao Li, and Kaipeng Zhang. Wildworld: A large-scale dataset for dynamic world modeling with actions and explicit state toward generative ARPG.arXiv preprint arXiv:2603.23497, 2026. URL https://arxiv.org/abs/2603.23497
arXiv 2026
-
[34]
Haoyu Wu, Jiwen Yu, Yingtian Zou, and Xihui Liu. Multiworld: Scalable multi-agent multi- view video world models.arXiv preprint arXiv:2604.18564, 2026
Pith/arXiv arXiv 2026
-
[35]
Precise action-to-video generation through visual action prompts
Yuang Wang, Chao Wen, Haoyu Guo, Sida Peng, Minghan Qin, Hujun Bao, Xiaowei Zhou, and Ruizhen Hu. Precise action-to-video generation through visual action prompts. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025. URL https://arxiv. org/abs/2508.13104
arXiv 2025
-
[36]
CLIP meets GamePhysics: Towards bug identification in gameplay videos using zero-shot transfer learning
Mohammad Reza Taesiri, Finlay Macklon, and Cor-Paul Bezemer. CLIP meets GamePhysics: Towards bug identification in gameplay videos using zero-shot transfer learning. In2022 IEEE/ACM 19th International Conference on Mining Software Repositories, pages 270–281,
-
[37]
URLhttps://arxiv.org/abs/2203.11096
doi:10.1145/3524842.3528438. URLhttps://arxiv.org/abs/2203.11096
-
[38]
Fuchs, Ingmar Posner, and Andrea Vedaldi
Oliver Groth, Fabian B. Fuchs, Ingmar Posner, and Andrea Vedaldi. ShapeStacks: Learning vision-based physical intuition for generalised object stacking. InEuropean Conference on Computer Vision, 2018. URLhttps://arxiv.org/abs/1804.08018
Pith/arXiv arXiv 2018
-
[39]
Smith, Lingjie Mei, Shunyu Yao, Jiajun Wu, Elizabeth S
Kevin A. Smith, Lingjie Mei, Shunyu Yao, Jiajun Wu, Elizabeth S. Spelke, Joshua B. Tenenbaum, and Tomer D. Ullman. Modeling expectation violation in intuitive physics with coarse probabilistic object representations. InAdvances in Neural Information Pro- cessing Systems, 2019. URL https://proceedings.neurips.cc/paper/2019/hash/ e88f243bf341ded9b4ced444795...
2019
-
[40]
I-PHYRE: Interactive physical reasoning
Shiqian Li, Kewen Wu, Chi Zhang, and Yixin Zhu. I-PHYRE: Interactive physical reasoning. InInternational Conference on Learning Representations, 2024. URL https://openreview. net/forum?id=1bbPQShCT2
2024
-
[41]
IntPhys 2019: A benchmark for visual intuitive physics understanding.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(9):5016– 5025, 2022
Ronan Riochet, Mario Ynocente Castro, Mathieu Bernard, Adam Lerer, Rob Fergus, Veronique Izard, and Emmanuel Dupoux. IntPhys 2019: A benchmark for visual intuitive physics understanding.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(9):5016– 5025, 2022. 12
2019
-
[42]
Kao, Adina Williams, Michael Rabbat, and Em- manuel Dupoux
Florian Bordes, Quentin Garrido, Justine T. Kao, Adina Williams, Michael Rabbat, and Em- manuel Dupoux. IntPhys 2: Benchmarking intuitive physics understanding in complex synthetic environments.arXiv preprint arXiv:2506.09849, 2025. URL https://arxiv.org/abs/ 2506.09849
arXiv 2025
-
[43]
CATER: A diagnostic dataset for compositional actions and TEmporal reasoning
Rohit Girdhar and Deva Ramanan. CATER: A diagnostic dataset for compositional actions and TEmporal reasoning. InInternational Conference on Learning Representations, 2020. URL https://arxiv.org/abs/1910.04744
arXiv 2020
-
[44]
CoPhy: Counter- factual learning of physical dynamics
Fabien Baradel, Natalia Neverova, Julien Mille, Greg Mori, and Christian Wolf. CoPhy: Counter- factual learning of physical dynamics. InInternational Conference on Learning Representations,
-
[45]
URLhttps://openreview.net/forum?id=SkeyppEFvS
-
[46]
Tenenbaum, and Chuang Gan
Zhenfang Chen, Kexin Yi, Yunzhu Li, Mingyu Ding, Antonio Torralba, Joshua B. Tenenbaum, and Chuang Gan. ComPhy: Compositional physical reasoning of objects and events from videos. InInternational Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=PgNEYaIc81Q
2022
-
[47]
Maitreya Patel, Tejas Gokhale, Chitta Baral, and Yezhou Yang. CRIPP-VQA: Counterfac- tual reasoning about implicit physical properties via video question answering. InProceed- ings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9856–9870, Abu Dhabi, United Arab Emirates, 2022. Association for Computational Lin- guistics....
-
[48]
Tenenbaum, and Chuang Gan
Zhicheng Zheng, Xin Yan, Zhenfang Chen, Jingzhou Wang, Qin Zhi Eddie Lim, Joshua B. Tenenbaum, and Chuang Gan. ContPhy: Continuum physical concept learning and reasoning from videos. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 61526–61558. PMLR, 2024. URL https://proc...
2024
-
[49]
Aaron Foss, Chloe Evans, Sasha Mitts, Koustuv Sinha, Ammar Rizvi, and Justine T. Kao. CausalVQA: A physically grounded causal reasoning benchmark for video models.arXiv preprint arXiv:2506.09943, 2025
arXiv 2025
-
[50]
Puyin Li, Tiange Xiang, Ella Mao, Shirley Wei, Xinye Chen, Adnan Masood, Li Fei-Fei, and Ehsan Adeli. QuantiPhy: A quantitative benchmark evaluating physical reasoning abilities of vision-language models.arXiv preprint arXiv:2512.19526, 2025
arXiv 2025
-
[51]
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, Yu Qiao, and Ziwei Liu. VBench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025. URLhttps://arxiv.org/abs/2503.21755
Pith/arXiv arXiv 2025
-
[52]
Worldscore: A unified evaluation benchmark for world generation
Haoyi Duan, Hong-Xing Yu, Sirui Chen, Li Fei-Fei, and Jiajun Wu. Worldscore: A unified evaluation benchmark for world generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[53]
Minh-Quan Le, Yuanzhi Zhu, Vicky Kalogeiton, and Dimitris Samaras. What about gravity in video generation? post-training newton’s laws with verifiable rewards.arXiv preprint arXiv:2512.00425, 2025
arXiv 2025
-
[54]
Mind-v: Hierarchical world model for long-horizon robotic manipulation with rl-based physical alignment, 2026
Ruicheng Zhang, Mingyang Zhang, Jun Zhou, Xiaofan Liu, Zunnan Xu, Zhizhou Zhong, Puxin Yan, Haocheng Luo, and Xiu Li. Mind-v: Hierarchical world model for long-horizon robotic manipulation with rl-based physical alignment, 2026. URL https://arxiv.org/abs/2512. 06628
2026
-
[55]
Robostereo: Dual-tower 4d embodied world models for unified policy optimization, 2026
Ruicheng Zhang, Guangyu Chen, Zunnan Xu, Zihao Liu, Zhizhou Zhong, Mingyang Zhang, Jun Zhou, and Xiu Li. Robostereo: Dual-tower 4d embodied world models for unified policy optimization, 2026. URLhttps://arxiv.org/abs/2603.12639
Pith/arXiv arXiv 2026
-
[56]
PhysGen: Rigid-body physics-grounded image-to-video generation
Shaowei Liu, Zhongzheng Ren, Saurabh Gupta, and Shenlong Wang. PhysGen: Rigid-body physics-grounded image-to-video generation. InEuropean Conference on Computer Vision,
-
[57]
URLhttps://arxiv.org/abs/2409.18964
doi:10.1007/978-3-031-73007-8_21. URLhttps://arxiv.org/abs/2409.18964. 13
-
[58]
Force prompting: Video generation models can learn and generalize physics-based control signals
Nate Gillman, Charles Herrmann, Michael Freeman, Daksh Aggarwal, Evan Luo, Deqing Sun, and Chen Sun. Force prompting: Video generation models can learn and generalize physics-based control signals. InAdvances in Neural Information Processing Systems, 2025. URLhttps://arxiv.org/abs/2505.19386
arXiv 2025
-
[59]
Chen Wang, Chuhao Chen, Yiming Huang, Zhiyang Dou, Yuan Liu, Jiatao Gu, and Lingjie Liu. PhysCtrl: Generative physics for controllable and physics-grounded video generation.arXiv preprint arXiv:2509.20358, 2025
arXiv 2025
-
[60]
PhysChoreo: Physics-controllable video generation with part-aware semantic grounding
Haoze Zhang, Tianyu Huang, Zichen Wan, Xiaowei Jin, Hongzhi Zhang, Hui Li, and Wangmeng Zuo. PhysChoreo: Physics-controllable video generation with part-aware semantic grounding. arXiv preprint arXiv:2511.20562, 2025
arXiv 2025
-
[61]
Yu Yuan, Xijun Wang, Tharindu Wickremasinghe, Zeeshan Nadir, Bole Ma, and Stanley H. Chan. NewtonGen: Physics-consistent and controllable text-to-video generation via neural newtonian dynamics. InInternational Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=rJ6N6sunaU
2026
-
[62]
Phyco: Learning controllable physical priors for generative motion, 2026
Sriram Narayanan, Ziyu Jiang, Srinivasa Narasimhan, and Manmohan Chandraker. Phyco: Learning controllable physical priors for generative motion, 2026. URLhttps://arxiv.org/ abs/2604.28169
Pith/arXiv arXiv 2026
-
[63]
PISA experiments: Exploring physics post-training for video diffusion models by watching stuff drop
Chenyu Li, Oscar Michel, Xichen Pan, Sainan Liu, Mike Roberts, and Saining Xie. PISA experiments: Exploring physics post-training for video diffusion models by watching stuff drop. InInternational Conference on Machine Learning, 2025. URL https://arxiv.org/abs/ 2503.09595
arXiv 2025
-
[64]
AI2-THOR: An interactive 3d environment for visual AI.arXiv preprint arXiv:1712.05474, 2017
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, et al. AI2-THOR: An interactive 3d environment for visual AI.arXiv preprint arXiv:1712.05474, 2017
Pith/arXiv arXiv 2017
-
[65]
RoboTHOR: An open simulation-to-real embodied AI platform
Matt Deitke, Winson Han, Alvaro Herrasti, Aniruddha Kembhavi, Eric Kolve, Roozbeh Mot- taghi, Jordi Salvador, Dustin Schwenk, Eli VanderBilt, Matthew Wallingford, Luca Weihs, Mark Yatskar, and Ali Farhadi. RoboTHOR: An open simulation-to-real embodied AI platform. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020. ...
arXiv 2020
-
[66]
ProcTHOR: Large-scale embodied AI using procedural generation
Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Jordi Salvador, Kiana Ehsani, Win- son Han, Eric Kolve, Ali Farhadi, Aniruddha Kembhavi, and Roozbeh Mottaghi. ProcTHOR: Large-scale embodied AI using procedural generation. InAdvances in Neural Information Pro- cessing Systems, 2022. URL https://proceedings.neurips.cc/paper_files/paper/ 2022/hash/...
2022
-
[67]
Habitat: A platform for embodied AI research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied AI research. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2019
2019
-
[68]
Zamir, Zhiyang He, Alexander Sax, Jitendra Malik, and Silvio Savarese
Fei Xia, Amir R. Zamir, Zhiyang He, Alexander Sax, Jitendra Malik, and Silvio Savarese. Gib- son env: Real-world perception for embodied agents. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018. URL https://openaccess.thecvf.com/ content_cvpr_2018/html/Xia_Gibson_Env_Real-World_CVPR_2018_paper.html
2018
-
[69]
iGibson 2.0: Object-centric simulation for robot learning of everyday household tasks
Chengshu Li, Fei Xia, Roberto Martín-Martín, Michael Lingelbach, Sanjana Srivastava, Bokui Shen, Kent Elliott Vainio, Cem Gokmen, Gokul Dharan, Tanish Jain, Andrey Kurenkov, Karen Liu, Hyowon Gweon, Jiajun Wu, Li Fei-Fei, and Silvio Savarese. iGibson 2.0: Object-centric simulation for robot learning of everyday household tasks. InProceedings of the 5th Co...
2022
-
[70]
ThreeDWorld: A platform for interactive multi-modal physical simulation
Chuang Gan, Jeremy Schwartz, Seth Alter, Damian Mrowca, Martin Schrimpf, James Traer, Julian De Freitas, Jonas Kubilius, Abhishek Bhandwaldar, Nick Haber, et al. ThreeDWorld: A platform for interactive multi-modal physical simulation. InAdvances in Neural Information Processing Systems Datasets and Benchmarks Track, 2021
2021
-
[71]
Fleet, Daniel Gnanapragasam, Florian Golemo, Charles Herrmann, et al
Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J. Fleet, Daniel Gnanapragasam, Florian Golemo, Charles Herrmann, et al. Kubric: A scalable dataset generator. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[72]
VirtualHome: Simulating household activities via programs
Xavier Puig, Kevin Ra, Marko Boben, Jiaman Li, Tingwu Wang, Sanja Fidler, and Antonio Torralba. VirtualHome: Simulating household activities via programs. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8494–8502, 2018. URLhttps://arxiv.org/abs/1806.07011
Pith/arXiv arXiv 2018
-
[73]
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Martín- Martín, Chen Wang, Gabrael Levine, Wensi Ai, Benjamin Martinez, et al. BEHA VIOR-1k: A human-centered, embodied AI benchmark with 1,000 everyday activities and realistic simulation. arXiv preprint arXiv:2403.09227, 2024
Pith/arXiv arXiv 2024
-
[74]
Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, Li Yi, Angel X. Chang, Leonidas J. Guibas, and Hao Su. SAPIEN: A simulated part-based interactive environment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020. URL https://arxiv.org/ abs/2003.08515
arXiv 2020
-
[75]
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J. Davison. RLBench: The robot learning benchmark and learning environment.IEEE Robotics and Automation Letters, 5 (2):3019–3026, 2020. URLhttps://arxiv.org/abs/1909.12271
arXiv 2020
-
[76]
ManiSkill2: A unified benchmark for generalizable manipulation skills
Jiayuan Gu, Fanbo Xiang, Xuanlin Li, Zhan Ling, Xiqiang Liu, Tongzhou Mu, Yihe Tang, Stone Tao, Xinyue Wei, Yunchao Yao, Xiaodi Yuan, Pengwei Xie, Zhiao Huang, Rui Chen, and Hao Su. ManiSkill2: A unified benchmark for generalizable manipulation skills. In International Conference on Learning Representations, 2023. URL https://arxiv.org/ abs/2302.04659
arXiv 2023
-
[77]
Isaac Gym: High performance GPU-based physics simulation for robot learning
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, and Gavriel State. Isaac Gym: High performance GPU-based physics simulation for robot learning. InAdvances in Neural Information Processing Systems Datasets and Benchmarks Track, 2021. URL https://arxiv.or...
Pith/arXiv arXiv 2021
-
[78]
UnrealCV: Connecting computer vision to unreal engine.arXiv preprint arXiv:1609.01326, 2016
Weichao Qiu and Alan Yuille. UnrealCV: Connecting computer vision to unreal engine.arXiv preprint arXiv:1609.01326, 2016. URLhttps://arxiv.org/abs/1609.01326
Pith/arXiv arXiv 2016
-
[79]
UnrealZoo: Enriching photo-realistic virtual worlds for embodied AI
Fangwei Zhong, Kui Wu, Churan Wang, Hao Chen, Hai Ci, Zhoujun Li, and Yizhou Wang. UnrealZoo: Enriching photo-realistic virtual worlds for embodied AI. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025. URL https://arxiv.org/ abs/2412.20977. Highlight
arXiv 2025
-
[80]
Qwen3-VL technical report, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.